Thinking out loud
Where we share the insights, questions, and observations that shape our approach.
6 strategies for OEMs to improve Electric Vehicle (EV) range
Electric vehicles (EVs) play an important role in fighting climate change and making transportation less dependent on fossil fuels. With the support of a growing number of governments, the global EV market has expanded quickly and has already reached more than $1 trillion in sales . 73 million electric vehicles are estimated to be sold globally by 2040, according to predictions made by Goldman Sachs Research , making up 61% of all new car sales globally.
Despite their booming popularity, the EV market still faces challenges. These include the scarcity of charging stations, concerns about vehicle performance, a limited selection of EV models available, and high prices. These factors, coupled with the “range anxiety” phenomenon, can impact EV adoption rates. Range anxiety is the fear or concern that an EV driver may experience due to the limited distance an EV can travel before needing to recharge.
In this article, we will discuss the need for electric vehicle manufacturers to cater to different challenges and expectations to bridge the gap between early EV adopters and the broader consumer market.
Challenges to EV range optimization
The parameters influencing the range of electric vehicles (EVs) can be categorized into external and internal factors.
Internal Factors :
- Motor efficiency : The more efficient the motor, the less energy it needs to operate, which means more energy can be used to power the vehicle and increase its range.
- Battery : Higher battery capacity, better chemistry, and a higher charge state can enhance range.
- Infotainments and comfort features : Energy-intensive features, such as large infotainment displays and power-hungry HVAC systems, can consume significant amounts of energy from the battery.
External Factors :
- Vehicle weight : Heavier vehicles require more energy, which influences their range.
- Traffic conditions : Stop-and-go traffic and congestion can impact energy consumption.
- Driver's behavior: Aggressive driving, excessive speeding, and rapid acceleration influence energy levels.
- In addition, there are challenges associated with charging infrastructure for electric vehicles (EVs)
The "charge anxiety" becomes even more noticeable than the range anxiety in this context. It's a feeling of unease or stress that EV drivers may feel regarding the availability and accessibility of charging infrastructure. It encompasses concerns about the knowledge regarding charging points' locations and their reliability.
Possible solutions – what can OEMs do to improve EV range
Smart energy management
OEMs (original equipment manufacturers) can play a vital role in advancing intelligent systems for managing EV charging demands through various means, such as the development of communication protocols, the implementation of load management strategies, the enablement of V2G (vehicle-to-grid) technology, the incorporation of renewable energy integration, and the provision of data analytics and insights.
For example, one of the important aspects of smart energy management for EVs is load management , which involves off-peak charging to take advantage of lower electricity rates, prioritizing charging when renewable energy sources are abundant. Another example is the vehicle-to-Grid (V2G) technology that allows EVs to act as energy storage systems, providing benefits such as grid stabilization and potentially extended range by replenishing stored energy during low-demand periods. OEMs can use V2G technology to transfer electricity between the EV battery and the power grid, allowing owners to sell excess energy back to the grid during peak hours.
Smart charging
Smart charging is a cloud-based technology that adapts electric vehicle (EV) energy usage based on the present status of the energy grid and the cost of charging events. It can also use the energy stored in EV batteries to address sudden spikes in grid demand. Smart charging is designed to make EV charging easier, less expensive, and more efficient in various ways:
- While the optimal geographic distribution of CSs can reduce travel and queuing time for EV owners, infrastructure development is neither cheap nor simple. Therefore, developing intelligent charging scheduling schemes can improve owners’ satisfaction.
- Power constraints influence the smart charging schedule , which is set to avoid power grid overload and interruptions. The system reduces congestion by using smart charging, and EVs can be charged off-peak.
- Smart charging prioritizes . Driving distance, EV charging capacity, State of Charging (SOC), charging cost, and other variables can all have an impact on optimal CS allocation for personal EVs. However, commercial EV scheduling strategies should prioritize maximizing on-road service hours and driving cycles with continuous driving to avoid service profit and daily net revenue losses. Smart charging can help implement such priorities.
EV OEMs can drive the advancement of smart charging technology through various means. This could involve integrating EV and charging infrastructure solutions, potentially through proprietary charging systems or collaborations with charging infrastructure providers, to enable seamless communication and coordination between stations. Integrated solutions can optimize charging based on factors such as power limits, pricing, and priority, leading to faster charging and enhanced energy storage capabilities.
OEMs may also optimize charging with AI and data analytics and equip vehicles with user-friendly app interfaces that allow EV owners to schedule and manage charging according to their preferences. Examples include intuitive scheduling, real-time pricing, and charging status updates.
Optimizing aerodynamics
Aerodynamics improves the range of electric cars (EVs). At high speeds, aerodynamic drag - air resistance - consumes energy. By reducing aerodynamic drag, EVs enhance efficiency and range. Optimizing aerodynamics can increase EV range in several ways:
- Sleek, aerodynamic design : EV manufacturers may build vehicles with little drag. Sloped rooflines, streamlined body shapes, and smooth underbody panels are examples. Minimizing aerodynamic drag minimizes the energy needed to overcome air resistance, allowing the EV to travel further on a single charge.
- Wheel design : Wheel design affects aerodynamics. Aerodynamic coverings and spoke patterns can reduce turbulence around EV wheels, which reduces drag and increases range.
- Sealing and gap management : In the case of electric vehicles, reducing air resistance is crucial to increasing their range and efficiency. EV makers can achieve this by sealing and managing gaps in body panels, doors, and other exterior components.
- Windscreen and window design : Curved windscreens and flush-mounted window frames reduce airflow turbulence and drag. This also improves aerodynamics and range.
Battery technology
Electric vehicle battery monitoring and analysis is an important aspect of EV battery management. A battery management system (BMS) controls the battery electronics and monitors its parameters such as voltage, state of charge (SOC), temperature, and charge and discharge. Using an algorithm, the BMS also evaluates the battery's health, percentage, and overall operational state. Fitting an EV with a BMS can improve safety and ensure the battery functions optimally.
High-capacity batteries that can extend EV range
OEMs are continually working to improve EV batteries, with the goal of achieving high energy density and rapid charging rates. Researchers from the Pohang University of Science and Technology (POSTECH) have invented a new battery technology that might increase the range of electric vehicles by up to 10 times. The technology involves a layering-charged, polymer-based stable high-capacity anode material. According to the research team, the new technology could be commercialized within five years, which would have significant consequences for OEMs, who will need to keep up with the rapidly evolving battery optimization techniques.
Battery power optimization
COVESA (Connected Vehicle System Alliance) is currently working on a project aiming to optimize power consumption in electric vehicles by limiting the power usage of auxiliary loads and optimizing battery utilization over time. The underlining assumption of this project is that the optimization scenarios for different loads, such as displays, speakers, and windows, can be identified for various situations.
The ultimate goal would be to optimize system load and vehicle usage scenarios at critical SoC conditions (like 20%, 15%, and 10%) to best use battery power and increase the travel range. The State of Charge (SoC) is a crucial metric for measuring the remaining power in a battery, often represented as a percentage of the total capacity. Accurate estimation of SoC is essential for protecting the battery, preventing over-discharge, improving battery lifespan, and implementing rational control strategies to save energy. It plays a critical role in optimizing battery performance and ensuring efficient energy management.
There are already some attempts at system load optimization. For example, ZF has developed a heated seat belt that provides warmth to occupants in cold temperatures and can help improve energy efficiency in electric vehicles without sacrificing the comfort of HVAC services. The heating conductors are integrated into the seat belt structure, providing close-to-body warmth immediately after the driving starts.
Estimating EV range and supporting efficient EV routing
Improving range and efficiency with OTA
Range estimation and efficient routing support through Over-the-Air (OTA) updates can significantly improve the use and convenience of electric vehicles. EVs can accurately predict their remaining range and design the best route using real-time data and advanced algorithms that take into account the battery’s state of charge, road conditions, traffic, and availability of charging stations. OTA updates can provide timely map updates, traffic statistics, and charging station details, allowing EVs to dynamically change their routes for the most practical and effective charging stations.
Examples:
In 2021, Volvo announced that it would introduce its over-the-air (OTA) software upgrade to its all-electric vehicles to enhance range in various ways. These include smart battery management and features, such as a timer and an assistant app to aid drivers in achieving optimal energy efficiency. One of the highlights - the Range Assistant - is specifically designed for EVs and provides valuable insights to drivers in two key areas. Firstly, it helps drivers understand the factors impacting the range of their EVs and to what extent they affect them. Secondly, it includes an optimization tool that can automatically adjust an electric vehicle's climate system to increase its range.
EV Mapbox . The system can foretell the vehicle's range using advanced algorithms and suggest convenient charging outlets en route. It accurately predicts the vehicle's charge level at the destination based on criteria including the charge depletion curve, ambient temperature, speed, and route slope. It takes into account all charging stations, preferred driver charging networks, and personalized settings. This allows the system to recommend detours and ensure optimal route planning.
Ford's Intelligent Range is a solution that keeps tabs on the driver's routine, the car's status, traffic reports, weather forecasts, geographical and climatic data, and more. The data is then processed by sophisticated algorithms to give the driver up-to-the-minute information on their remaining battery life.
Optimizing routing by collecting infrastructure data
COVESA is currently engaged in a project that examines how OEMs utilize data from third parties collected at charging points . This information is often fragmented and fails to provide adequate benefits to customers who encounter issues such as broken chargers or charger occupancy. In order to promote efficiency and growth in EV charging, data standardization and sharing are crucial. The project aims to develop a solution that grants access to a standardized data model or database hosted in the cloud, which includes anonymized car data on charge events. This data encompasses precise charger location, maximum power, time to reach 80% State of Charge, and other advanced data points to enhance the overall EV charging experience.
Addressing range anxiety directly
All the above solutions aim to give EV adoption an additional push and reduce consumer anxiety. Another way to achieve this goal is by educating potential EV owners about the range of capabilities of different models and how to plan trips accordingly. Advertising and offering EV trial rides can help dispel misconceptions and alleviate range anxiety. Still, more options are available, for example, fueling station locators or charging station search tools. Potential customers can also access dedicated reports with answers to common questions about electric vehicles and plug-in hybrids that help them choose the right EV for their needs.
Conclusion
As the demand for EVs continues to grow, extending the range of these vehicles is crucial to address the concerns of potential buyers and enhance their overall usability. OEMs can take several steps to improve EV range, making them more attractive to consumers and accelerating the transition to a sustainable transportation future .


Vehicle data platform: How to connect OEMs and third-party service providers
As the automotive industry continues to evolve, the demand for connectivity and data-driven solutions is on the rise. A vehicle data platform serves as a crucial link between Original Equipment Manufacturers and Third-Party Service Providers, granting access to real-time information on cars' performance, drivers' behavior, and other valuable insights. In this article, we will answer the question of how to use vehicle data platforms in order to improve customer experience.
Why do OEMs use TPSPs instead of creating their own applications?
Until recently, car manufacturers designed their own applications and services to enrich the driver's experience. Today, however, OEMs are increasingly being replaced by companies and programmers not directly related to the automotive industry . These parties follow their own business goals and build independent databases.
The relationship between TPSPs and OEMs resembles a kind of symbiosis. The former gain access to valuable data on cars' performance and drivers' behavior, which allows them to design and sell innovative solutions for the automotive industry. The latter, on the other hand, receive ready-made products, thanks to which they can constantly improve their customers' experience.
It is worth considering, however, why OEMs gave up producing their own applications in favor of third-party services:
- Expertise — TPSPs are often specialized in a particular area, such as telematics, fleet management, or connected car services. By working with TPSPs, OEMs can leverage their expertise and access to cutting-edge technologies without having to develop them in-house.
- Time to market — developing a new application from scratch can be time-consuming and costly. By working with TPSPs, OEMs can reduce development time and get their products to market faster.
- Cost — building and maintaining an application requires significant investment in resources, including development, infrastructure, and ongoing management. Working with TPSPs can be more cost-effective, as OEMs can pay for the services they need on a subscription or per-use basis.
- Flexibility — OEMs can choose from a range of third-party services to meet customers' specific needs without being tied to a single solution. This provides the ability to adapt to changing market conditions.
- Scalability — as the number of connected vehicles and the amount of data they generate continue to grow, OEMs may struggle to scale their own applications to handle the volume. TPSPs, on the other hand, often have the infrastructure and resources to meet the market's demand.
How can OEMs improve customer experience with third-party services?
Access to third-party services gives OEMs great opportunities to improve their offerings. By providing detailed data on how cars are used and benefiting from the solutions produced on this basis, you can respond to the needs of today's consumers more and more precisely.
The most important benefits that you can offer your clients thanks to TPSPs include the following benefits:
- Increased convenience — by integrating third-party services into their products, OEMs can provide a more convenient and streamlined experience for their customers. As a car manufacturer, you can, for example, include a parking app in your infotainment system, allowing your clients to easily find and reserve parking spots.
- Enhanced value — third-party services can add value to the OEM's products by providing additional features and capabilities that customers may find useful. For example, as an automotive manufacturer, you can partner with a music streaming service to offer a personalized music experience through the car's infotainment system.
- Differentiation — OEMs can differentiate their products from competitors by offering unique third-party services. You could, for example, partner with a food delivery service to offer on-the-go meal options for drivers.
- New revenue streams — third-party services can bring you more income. For example, you could partner with a car-sharing service and earn a commission for every rental.
Overall, by integrating third-party services into your products, you can provide a more convenient, valuable, and personalized experience for your customers while generating new revenue streams.
Car data platforms — an easy way to connect with TPSPs
Cooperation between OEMs and TPSPs may turn out to be very fruitful for both parties. For this purpose, however, a common platform will be necessary. It will allow them to exchange crucial information. This is how vehicle data platforms work.
Car data platforms are digital tools that collect, store, and analyze data generated by vehicles . These services use a combination of hardware and software to capture information from various sensors and systems in the car, such as the engine, transmission, brakes, and infotainment system. The data is then transmitted to the platform through a variety of methods, such as cellular or Wi-Fi connections.
Once the data is collected, it is processed and analyzed using algorithms and machine learning models to extract valuable insights . This can include identifying patterns in driver behavior, predicting maintenance needs, optimizing vehicle performance, and more.
Vehicle data platforms often provide APIs (application programming interfaces) that allow third-party developers to build advanced applications and services. For example, a fleet management company could use the information to optimize routes and reduce fuel consumption, while an insurance company could offer personalized policies based on driving behavior.
The resulting third-party services are evaluated and approved for use by the platforms. As a car manufacturer, you have convenient access to these products, while the marketplaces protect your interests and help you negotiate individual contracts. Every financial transaction goes through the platform, which translates into safety and transparency.
How to build and use a vehicle data platform
Now that you know how car data platforms work, it is worth considering how to make good use of them. You have at your disposal marketplaces already functioning on the market, but nothing stands in the way of creating your own platform. As the automotive company owner or manager, you should take the following steps:
- Identify the purpose and goals — first, you need to identify what kind of data you want to collect and analyze, and what insights you hope to gain from it. You should also determine what products you are interested in and what features you plan to offer to your customers.
- Choose the data sources — these can include vehicle sensors, telematics devices, GPS systems, and other sources of data.
- Connect your vehicles — develop and integrate the necessary hardware and software to connect your vehicles to the platform. This includes selecting the appropriate communication technologies, sensors, and data management systems.
- Store and manage data — you need to find a solution to handle large volumes of data. Depending on the amount of information you are collecting, you may want to use cloud-based solutions, such as Amazon Web Services or Microsoft Azure.
- Develop analytics and visualization capabilities — once you have the data, you need to analyze it and derive insights. You should develop analytics and visualization technologies to help users make sense of the collected information.
- Define APIs — set application programming interfaces that enable Third-Party Service Providers to access the data generated by your vehicles. Ensure that these APIs are well-documented and easy to use.
- Partner with TPSPs — find and team up with entities that can provide a range of value-added services to your customers. This includes services such as predictive maintenance, telematics, and infotainment.
- Ensure security and compliance — you need to ensure that your vehicle data platform is safe and compliant with applicable laws and regulations. This translates into protecting data privacy and ensuring its accuracy.
- Test and iterate — you need to verify if the platform meets the needs of your users. You should gather feedback and use it to improve the platform over time.
- Monetize your data — identify opportunities to generate income by selling data to third-party service providers or using it to create new revenue streams.
Remember that creating a vehicle data platform requires a team of skilled professionals with expertise in different areas. You should partner up with an experienced software house or automotive engineering company to get the help you need.
Vehicle data platform — summary
Using car data platforms and gaining access to third-party services can bring you numerous benefits in the form of customer satisfaction, increased sales, optimized costs or improved business flexibility. It is up to you exactly what facilities you will offer and how you will monetize the collected information. One thing is certain — to start benefiting from connectivity and data-driven solutions , you need to begin by creating a functional car data marketplace.
How to Use Associative Knowledge Graphs to Build Efficient Knowledge Models
In this article, I will present how associative data structures such as ASA-Graphs, Multi-Associative Graph Data Structures, or Associative Neural Graphs can be used to build efficient knowledge models and how such models help rapidly derive insights from data.
Moving from raw data to knowledge is a difficult and essential challenge in the modern world, overwhelmed by a huge amount of information. Many approaches have been developed so far, including various machine learning techniques, but still, they do not address all the challenges. With the greater complexity of contemporary data models, a big problem of energy consumption and increasing costs has arisen. Additionally, the market expectations regarding model performance and capabilities are continuously growing, which imposes new requirements on them.
These challenges may be addressed with appropriate data structures which efficiently store data in a compressed and interconnected form. Together with dedicated algorithms i.e. associative classification, associative regression, associative clustering, patterns mining, or associative recommendations, they enable building scalable and high-performance solutions that meet the demands of the contemporary Big Data world.
The article is divided into three sections. The first section concerns knowledge in general and knowledge discovering techniques. The second section shows technical details of selected associative data structures and associative algorithms. The last section explains how associative knowledge models can be applied practically.
From data to wisdom
The human brain can process 11 million bits of information per second. But only about 40 to 50 bits of information per second reach consciousness. Let us consider the complexity of the tasks we solve every second. For example, the ability to recognize another person’s emotions in a particular context (e.g., someone’s past, weather, a relationship with the analyzed person, etc.) is admirable, to say the least. It involves several subtasks, such as facial expression recognition, voice analysis, or semantic and episodic memory association.
The overall process can be simplified into two main components: dividing the problem into simpler subtasks and reducing the amount of information using the existing knowledge. The emotional recognition mentioned earlier may be an excellent specific example of this rule. It is done by reducing a stream of millions of bits per second to a label representing someone’s emotional state. Let us assume that, at least to some extent, it is possible to reconstruct this process in a modern computer.
This process can be presented in the form of a pyramid. The DIKW pyramid, also known as the DIKW hierarchy, represents the relationships between data (D), information (I), knowledge (K), and wisdom (W). The picture below shows an example of a DIKW pyramid representing data flow from a perspective of a driver or autonomous car who noticed a traffic light turned to red.
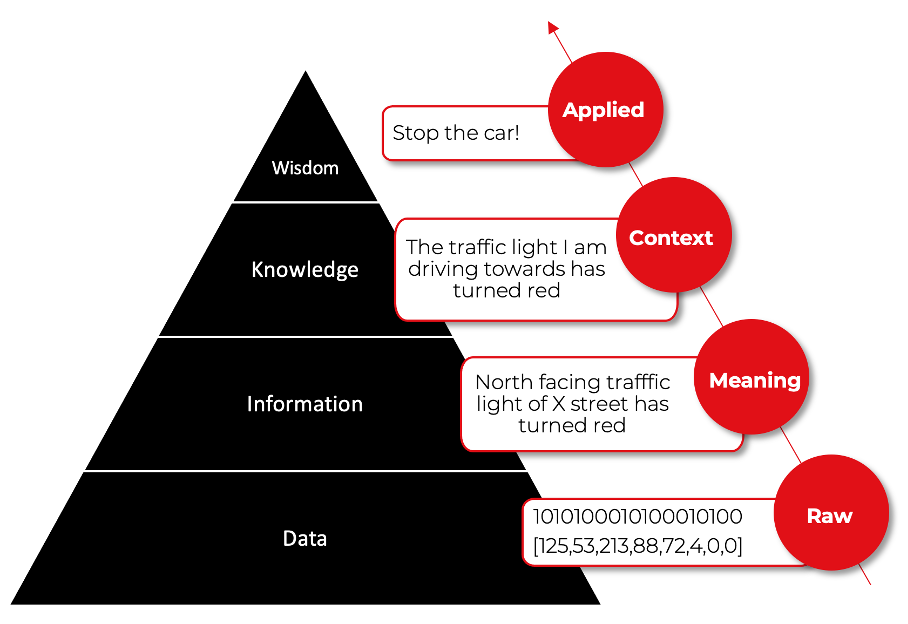
In principle, the pyramid demonstrates how the understanding of the subject emerges hierarchically – each higher step is defined in terms of the lower step and adds value to the prior step. The input layer (data) handles the vast number of stimuli, and the consecutive layers are responsible for filtering, generalizing, associating, and compressing such data to develop an understanding of the problem. Consider how many of the AI (Artificial Intelligence) products you are familiar with are organized hierarchically, allowing them to develop knowledge and wisdom.
Let’s move through all the stages and explain each of them in simple words. It is worth realizing that many non-complementary definitions of data, information, knowledge, and wisdom exist. In this article, I use the definitions which are helpful from the perspective of making software that runs associative knowledge graphs, so let’s pretend for a moment that life is simpler than it is.
Data – know nothing

Many approaches try to define and explain data at the lowest level. Though it is very interesting, I won’t elaborate on that because I think one definition is enough to grasp the main idea. Imagine data as facts or observations that are unprocessed and therefore have no meaning or value because of a lack of context and interpretation. In practice, data is represented as signals or symbols produced by sensors. For a human, it can be sensory readings of light, sound, smell, taste, and touch in the form of electric stimuli in the nervous system.
In the case of computers, data may be recorded as sequences of numbers representing measures, words, sounds, or images. Look at the example demonstrating how the red number five on an apricot background can be defined by 45 numbers i.e., a 3-dimensional array of floating-point numbers 3x5x3, where the width is 3, the height is 5, and the third dimension is for RGB color encoding.
In the case of the example from the picture, the data layer simply stores everything received by the driver or autonomous car without any reasoning about it.
Information – know what
Information is defined as data that are endowed with meaning and purpose. In other words, information is inferred from data. Data is being processed and reorganized to have relevance for a specific context – it becomes meaningful to someone or something. We need someone or something holding its own context to interpret raw data. This is the crucial part, the very first stage, where information selection and aggregation start.
How can we now know what data can be cut off, classified as noise, and filtered? It is impossible without an agent that holds an internal state, predefined or evolving. It means considering conditions such as genes, memory, or environment for humans. For software, however, we have more freedom. The context may be a rigid set of rules, for example, Kalman filter for visual data, or something really complicated and “alive” like an associative neural system.
Going back to the traffic example presented above, the information layer could be responsible for an object detection task and extracting valuable information from the driver’s perspective. The occipital cortex in the human brain or a convolutional neural network (CNN) in a driverless vehicle can deal with this. By the way, CNN architecture is inspired by the occipital cortex structure and function.
Knowledge – know who and when
The boundaries of knowledge in the DIKW hierarchy are blurred, and many definitions are imprecise, at least for me. For the purpose of the associative knowledge graph, let us assume that knowledge provides a framework for evaluating and incorporating new information by making relationships to enrich existing knowledge. To become a “knower”, an agent’s state must be able to extend in response to incoming data.
In other words, it must be able to adapt to new data because the incoming information may change the way further information would be handled. An associative system at this level must be dynamic to some extent. It does not necessarily have to change the internal rules in response to external stimuli but should be able to at least take them into account in further actions. To sum up, knowledge is a synthesis of multiple sources of information over time.
At the intersection with traffic lights, the knowledge may be manifested by an experienced driver who can recognize that the traffic light he or she is driving towards has turned red. They know that they are driving the car and that the distance to the traffic light decreases when the car speed is higher than zero. These actions and thoughts require existing relationships between various types of information. For an autonomous car, the explanation could be very similar at this level of abstraction.
Wisdom – know why
As you may expect, the meaning of wisdom is even more unclear than the meaning of knowledge in the DIKW diagram. People may intuitively feel what wisdom is, but it can be difficult to define it precisely and make it useful. I personally like the short definition stating that wisdom is an evaluated understanding.
The definition may seem to be metaphysical, but it doesn’t have to be. If we assume understanding as a solid knowledge about a given aspect of reality that comes from the past, then evaluated may mean a checked, self-improved way of doing things the best way in the future. There is no magic here; imagine a software system that measures the outcome of its predictions or actions and imposes on itself some algorithms that mutate its internal state to improve that measure.
Going back to our example, the wisdom level may be manifested by the ability of a driver or an autonomous car to travel from point A to point B safely. This couldn’t be done without a sufficient level of self-awareness.
Associative knowledge graphs
Omnis ars nature imitatio est . Many excellent biologically inspired algorithms and data structures have been developed in computer science. Associative Graph Data Structures and Associative Algorithms are also the fruits of this fascinating and still surprising approach. This is because the human brain can be decently modeled using graphs.
Graphs are an especially important concept in machine learning. A feed-forward neural network is usually a directed acyclic graph (DAG). A recurrent neural network (RNN) is a cyclic graph. A decision tree is a DAG. K-nearest neighbor classifier or k-means clustering algorithm can be very effectively implemented using graphs. Graph neural network was in the top 4 machine learning-related keywords 2022 in submitted research papers at ICLR 2022 ( source ).
For each level of the DIKW pyramid, the associative approach offers appropriate associative data structures and related algorithms.
At the data level, specific graphs called sensory fields were developed. They fetch raw signals from the environment and store them in the appropriate form of sensory neurons. The sensory neurons connect to the other neurons representing frequent patterns that form more and more abstract layers of the graph that will be discussed later in this article. The figure below demonstrates how the sensory fields may connect with the other graph structures.
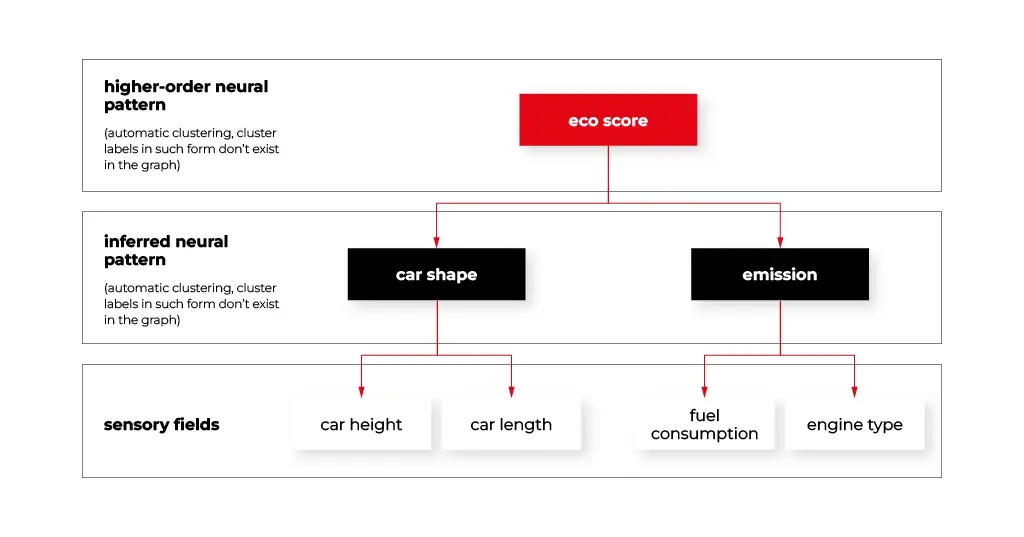
The information level can be managed by static (it does not change its internal structure) or dynamic (it may change its internal structure) associative graph data structures. A hybrid approach is also very useful here. For instance, CNN may be used as a feature extractor combined with associative graphs, as it happens in the human brain (assuming that CNN reflects the parietal cortex).
The knowledge level may be represented by a set of dynamic or static graphs from the previous paragraph connected to each other with many various relationships creating an associative knowledge graph.
The wisdom level is the most exotic. In the case of the associative approach, it may be represented by an associative system with various associative neural networks cooperating with other structures and algorithms to solve complex problems.
Having that short introduction let’s dive deeper into the technical details of associative graphical approach elements.
Sensory field
Many graph data structures can act as a sensory field. But we will focus on a special structure designed for that purpose.
ASA-graph is a dedicated data structure for handling numbers and their derivatives associatively. Although it acts like a sensory field, it can replace conventional data structures like B-tree, RB-tree, AVL-tree, and WAVL-tree in practical applications such as database indexing since it is fast and memory-efficient.
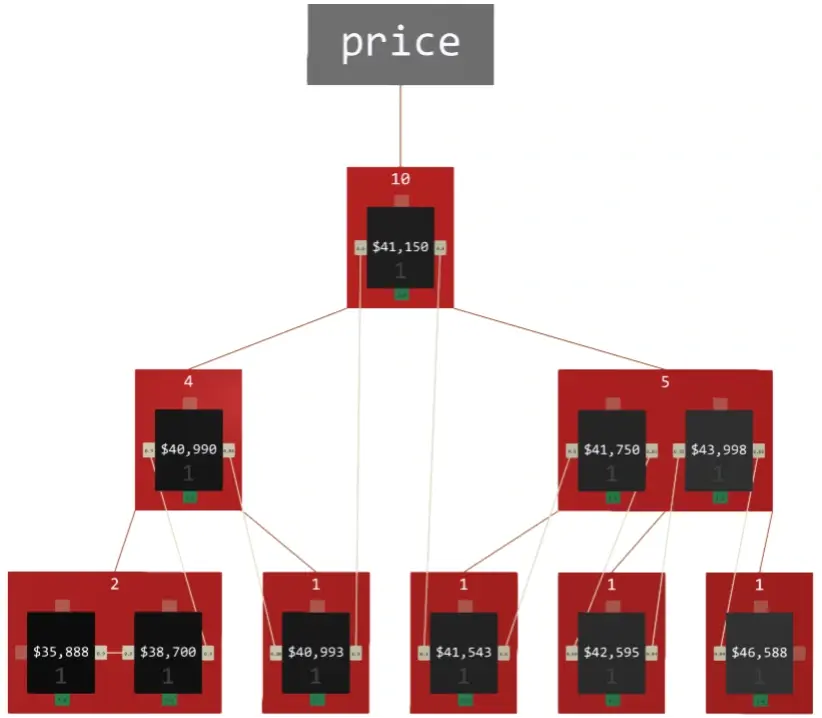
ASA-graphs are complex structures, especially in terms of algorithms. You can find a detailed explanation in this paper . From the associative perspective, the structure has several features which make it perfect for the following applications:

- elements aggregation – keeps the graph small and devoted only to representing valuable relationships between data,
- elements counting – is useful for calculating connection weights for some associative algorithms e.g., frequent patterns mining,
- access to adjacent elements – the presence of dedicated, weighted connections to adjacent elements in the sensory field, which represents vertical relationship within the sensor, enables fuzzy search and fuzzy activation,
- the search tree is constructed in an analogous way to DAG like B-tree, allowing fast data lookup. Its elements act like neurons (in biology, a sensory cell is often the outermost part of the neural system) independent from the search tree and become a part of the associative knowledge graph.
Efficient raw data representation in the associative knowledge graph is one of the most important requirements. Once data is loaded into sensory fields, no further data processing steps are needed. Moreover, ASA-graph automatically handles missing or unnormalized (e.g., a vector in a single cell) data. Symbolic or categorical data types like strings are equally possible as any numerical format. It suggests that one-hot encoding or other comparable techniques are not needed at all. And since we can manipulate symbolic data, associative patterns mining can be performed without any pre-processing.
It may significantly reduce the effort required to adjust a dataset to a model, as is the case with many modern approaches. And all the algorithms may run in place without any additional effort. I will demonstrate associative algorithms in detail later in the series. For now, I can say that nearly every typical machine learning task, like classification, regression, pattern mining, sequence analysis, or clustering, is feasible.
Associative knowledge graph
In general, a knowledge graph is a type of database that stores the relationships between entities in a graph. The graph comprises nodes, which may represent entities, objects, traits, or patterns, and edges modeling the relationships between those nodes.
There are many implementations of knowledge graphs available out there. In this article, I would like to bring your attention to the particular associative type inspired by excellent scientific papers which are under active development in our R&D department. This self-sufficient associative graph data structure connects various sensory fields with nodes representing the entities available in data.
Associative knowledge graphs are capable of representing complex, multi-relational data thanks to several types of relationships that may exist between the nodes. For example, an associative knowledge graph can represent the fact that two people live together, are in love, and have a joint loan, but only one person repays it.
It is easy to introduce uncertainty and ambiguity to an associative knowledge graph. Every edge is weighted, and many kinds of connections help to reflect complex types of relations between entities. This feature is vital for the flexible representation of knowledge and allows the modeling of environments that are not well-defined or may be subject to change.
If there weren't specific types of relations and associative algorithms devoted to these structures, there wouldn't be anything particularly fascinating about it.
The following types of associations (connections) make this structure very versatile and smart, to some extent:
- defining,
- explanatory
- sequential,
- inhibitory,
- similarity.
The detailed explanation of these relationships is out of the scope of this article. However, I would like to give you one example of flexibility provided to the graph thanks to them. Imagine that some sensors are activated by data representing two electric cars. They have similar make, weight, and shape. Thus, the associative algorithm creates a new similarity connection between them with a weight computed from sensory field properties. Then, a piece of extra information arrives to the system that these two cars are owned by the same person.
So, the framework may decide to establish appropriate defining and explanatory connections between them. Soon it turns out that only one EV charger is available. By using dedicated associative algorithms, the graph may create special nodes representing the probability of being fully charged for each car depending on the time of day. The graph establishes inhibitory connections between the cars automatically to represent their competitive relationship.
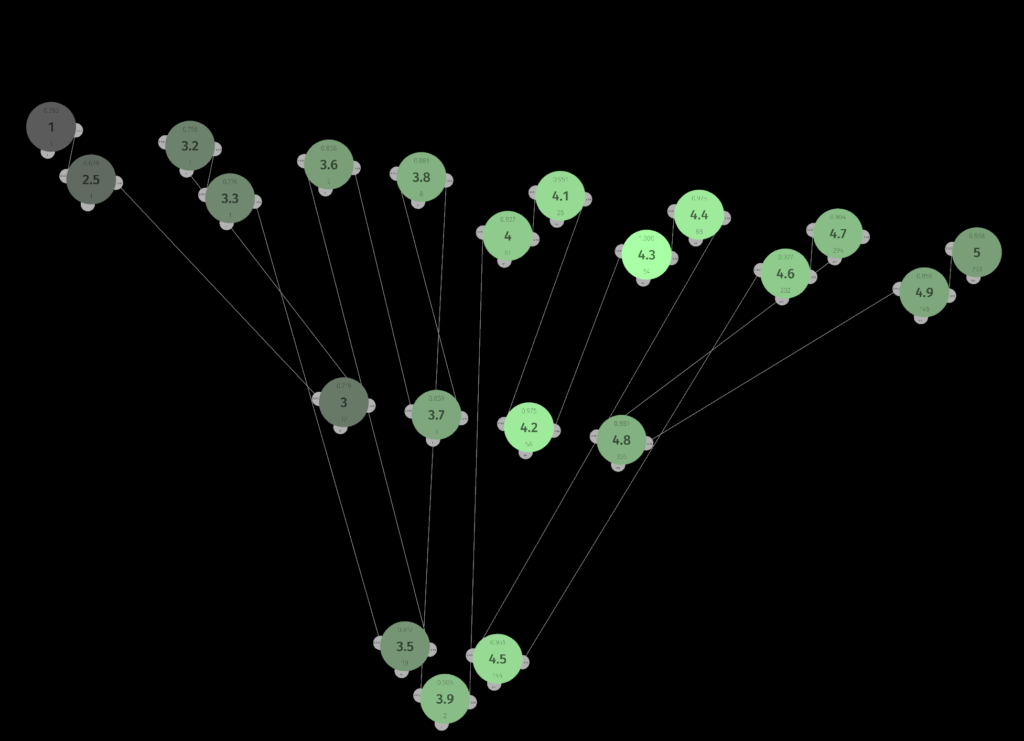
The image below visually represents the associative knowledge graph explained above, with the famous iris dataset loaded. Identifying the sensory fields and neurons should not be too difficult. Even such a simple dataset demonstrates that relationships may seem complex when visualized. The greatest strength of the associative approach is that relationships do not have to be computed – they are an integral part of the graph structure, ready to use at any time. The algorithm as a structure approach in action.

A closer look at the sensor structure demonstrates the neural nature of raw data representation in the graph. Values are aggregated, sorted, counted, and connections between neighbors are weighted. Every sensor can be activated and propagate its signal to its neighbors or neurons. The final effect of such activation depends on the type of connection between them.
What is important, associative knowledge graphs act as an efficient database engine. We conducted several experiments proving that for queries that contain complex join operations or such that heavily rely on indexes, the performance of the graph can be orders of magnitude faster than traditional RDBMS like PostgreSQL or MariaDB. This is not surprising because every sensor is a tree-like structure.
So, data lookup operations are as fast as for indexed columns in RDBMS. The impressive acceleration of various join operations can be explained very easily – we do not have to compute the relationships; we simply store them in the graph’s structure. Again, that is the power of the algorithm as a structure approach.
Associative neural networks
Complex problems usually require complex solutions. The biological neuron is way more complicated than a typical neuron model used in modern deep learning. A nerve cell is a physical object which acts in time and space. In most cases, a computer model of neurons is in the form of an n-dimensional array that occupies the smallest possible space to be computed using streaming processors of modern GPGPU (general-purpose computing on graphics processing).
Space and time context is usually just ignored. In some cases, e.g., recurrent neural networks, time may be modeled as a discrete stage representing sequences. However, this does not reflect the continuous (or not, but that is another story) nature of the time in which nerve cells operate and how they work.
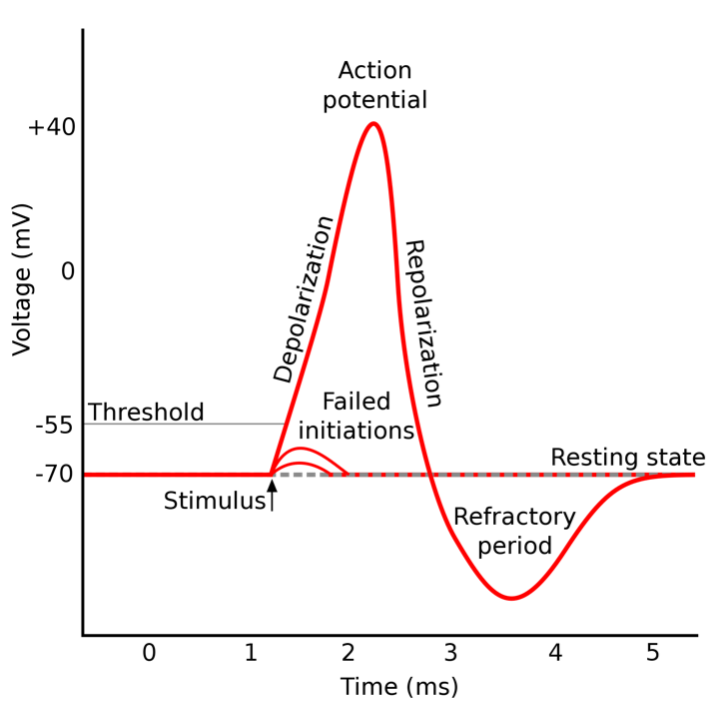
A spiking neuron is a type of neuron that produces brief, sharp electrical signals known as spikes, or action potentials, in response to stimuli. The action potential is a brief, all-or-none electrical signal that is usually propagated through a part of the network that is functionally or structurally separated, causing, for example, contraction of muscles forming a hand flexors group.
Artificial neural network aggregation and activation functions are usually simplified to accelerate computing and avoid time modeling, e.g., ReLu (rectified linear unit). Usually, there is no place for such things as refraction or action potential. To be honest, such approaches are good enough for most contemporary machine learning applications.
The inspiration from biological systems encourages us to use spiking neurons in associative knowledge graphs. The resulting structure is more dynamic and flexible. Once sensors are activated, the signal is propagated through the graph. Each neuron behaves like a separate processor with its own internal state. The signal is lost if the propagated signal tries to influence a neuron in a refraction state.
Otherwise, it may increase the activation above a threshold and produce an action potential that spreads rapidly through the network embracing functionally or structurally connected parts of the graph. Neural activations are decreasing in time. This results in neural activations flowing through the graph until an equilibrium state is met.
Associative knowledge graphs - conclusions
While reading this article, you have had a chance to discern associative knowledge graphs from a theoretical yet simplified perspective. The next article in a series will demonstrate how the associative approach can be applied to solve problems in the automotive industry . We have not discussed associative algorithms in detail yet. This will be done using examples as we work on solving practical problems.

Getting up to speed with Android Automotive OS development on Mac
Similar to how they did for the exploding smartphone market over ten years ago, customized infotainment operating systems and open-source software appear to be sweeping the car industry. The Android Automotive OS has been making headway in many market niches, starting with full-electric vehicles like Polestar a few years ago. It’s only a matter of time until the community and ecosystem mature enough to become a serious force for enabling mobile development on yet another front: the cars.
While Android Auto (a name easily confused with the topic I will be going over today) and Apple CarPlay have had a long-standing in the field, they came with several caveats and restrictions. Those largely pertain to the fact that many features-to-be would rely on low-level access to the hardware of the car itself. This proved to be difficult, with both solutions offering a limited set of human-machine interaction capabilities, such as a heads-up display (where available) and radio. With that in mind, the use case for providing apps for the actual OS running the car was clearly needed.
The community and documentation are still in their infancy and don’t yet provide a deep dive into Android Automotive OS. Moreover, the learning curve remains steep, but it’s definitely possible to piece together bits of information related to development and deployment. In this article, I attempt to do just that, all while emphasizing the MacOS side of things.
Prerequisites
As a general principle, Android development can either be done on a real device or a corresponding emulator. Given the sensitive nature of granting applications access to the actual car hardware, the app has to go the whole nine yards with Google Play Store eligibility. On top of that, it has to conform to one of several categories, e.g. a media app to be allowed in the AAOS system. The good news is that there’s a possibility for an app to mix and match categories.
Thus, vendors supporting the new ecosystem (as of now, among others, Volvo and Polestar) opted for creating a custom automotive device emulator that closely matches the specifications of the infotainment systems contained within their cars. Regrettably, Polestar and Volvo emulators contain proprietary code, are based on older Android releases, and do not yet support the ARM architecture, which is of special interest to developers working with ARM-based Macs.
While official AAOS emulators are available in Preview releases of Android Studio (from the Electric Eel version onwards), often the task at hand calls for customized hardware and parameters. In this case, a custom Android version would need to be built from source.
Building from source
Building from source code is a time-consuming enterprise that’s not officially supported outside 64-bit Linux platforms (regardless of the target architecture). With that in mind, choosing a dedicated AWS EC2 instance or a bare metal server for building the ARM versions of the emulator seems to be the best overall solution for Mac developers.
A requirement for unofficial builds on Mac devices seems to be having a disk partition with a case-sensitive file system and otherwise following some extra steps. I chose a dedicated build system because, in my opinion, it wasn't worth the trouble to set up an additional partition (for which I didn't really have the disk capacity).
The choice of the base Android release is largely dependent on the target device support, however, for ease of development, I would recommend choosing a recent one, e.g., 12.1 (aka 12L or Sv2). Mileage may vary in regards to actually supported versions, as vendors tend to use older and more stable releases.
After getting their hands on a development machine, one should prepare the build environment and follow instructions for building an AVD for Android Auto. The general workflow for building should include:
- downloading the source code – this may take up to an hour or two, even with decent connection and branch filtering,
- applying required modifications to the source, e.g., altering the default VHAL values or XML configuration,
- running the build – again, may take up to several hours; the more threads and memory available, the better,
- packing up the artifacts,
- downloading the AVD package.
Leaving out the usage specifics of the lunch and repo for now, let’s take a look at how we can make the default AAOS distribution fit our needs a little better.
Tailoring a device
VHAL (Vehicle Hardware Abstraction Layer) is an interface that defines the properties for OEMs to eventually implement. These properties may, for example, include telemetry data or perhaps some info that could be used to identify a particular vehicle.
In this example, we’re going to add a custom VIN entry to the VHAL. This will enable app developers to read VIN information from a supposed vehicle platform.
First off, let’s start with downloading the actual source code. As mentioned above, Android 12.1 (Sv2) is the release we’re going to go with. It supports version 32 of the API, which is more than enough to get us started.
In order to get sources, run the following command, having installed the source control tools :
<p>> repo init -u https://android.googlesource.com/platform/manifest -b android-12.1.0_r27 --partial-clone --clone-filter=blob:limit=10M</p>
<p>> repo sync -c -j16</p>
Partial clone capability and choice of a single branch make sure that the download takes as little time as possible.
After downloading the source, locate the DefaultConfig.h file and add the following entry to kVehicleProperties:
{.config =
{
.prop = toInt(VehicleProperty::INFO_VIN),
.access = VehiclePropertyAccess::READ,
.changeMode = VehiclePropertyChangeMode::STATIC,
},
.initialValue = {.stringValue = "1GCARVIN123456789"}},
An overview of HAL properties can be found in the reference documentation .
Build
Having modified the default HAL implementation, we’re now free to run the build for an ARM target. Run the following instructions inside the AAOS source directory – using a screen is highly recommended if connecting through SSH:
screen
. build/envsetup.sh
lunch sdk_car_arm64-userdebug
m -j16 # build the requisite partitions
m emu_img_zip # pack emulator artifacts into a downloadable .zip
Note the sdk_car_arm64-userdebug target needed for emulation on ARM-powered Macs. A car_arm64-userdebug variant also exists. Make sure not to confuse the two – only the former has emulation capabilities! Try running lunch without parameters to see a full list of targets.
The -jXX parameter specifies the number of threads to use while building the Android. If the thread count is not provided, the build system will try and optimize the number of threads automatically. Patience is advised, as even with decent hardware resources, the compilation is bound to take a while.
The resulting emulator artifact should be available in the out/ directory under sdk-repo-linux-system-images.[suffix].zip to be downloaded via scp or your file transfer client of choice.
Running a custom emulator in Android Studio
Now that we have our bespoke emulator image built, there’s a little trick involved in making it available for local development without creating a whole distribution channel, as outlined in the manual.
First, locate the ~/Library/Android/sdk/system-images/android-32 folder and unzip your emulator archive there. The directory can be given an arbitrary name, but the overall structure should follow this layout:
~/Library/Android/sdk/system-images/android-32
|_ [your name]
|_ arm64-v8a
E.g., ~/Library/Android/sdk/system-images/android-32/custom_aaos/arm64-v8a.
Second, download the example attached package.xml file and adjust the device name to fit your needs. A package.xml is added after downloading and unpacking the emulator sources from the Internet and needs to be recreated when unzipping locally. After restarting the Android Studio, Device Manager should have an option to use your brand new ARM image with an Automotive AVD of your choice.
After successfully running the emulator, a newly created VIN property should be visible in the Vhal Properties of Car Data. Nice one!
While reading VHAL property values is out of the scope of this article, it should be easy enough with a couple of Car library calls, and Google created an example app that does the very thing.
Downloading the above example (CarGearViewerKotlin) is highly recommended – if you’re able to build and run the app on the emulator, you’re all set!
Facilitating AAOS development on M1
One of the problems I stumbled upon during the development environment setup was that the Car library was not being detected by Android Studio, while the app still builds normally from CLI. This appears to be a known issue, with no official patch yet released (as of October 2022). However, a simple workaround to include a .jar of the Android Automotive library appears to work.
In case of running into any problems, import the library from ~/Library/Android/sdk/platforms/android-32/optional/android.car.jar by copying it into libs/ directory in the project root and add the following directive to your main build.gradle file, if not present:
dependencies {
implementation fileTree(include: ['*.jar'], dir: 'libs')
...
}
Once the project is re-imported into the IDE, Android Studio should be able to pick up the Android Car library for import and autocomplete suggestions.
The Real Deal
Emulators are sufficient for testing purposes, but what about real devices, such as branded infotainment centers? As mentioned before, at least two major vendors (Volvo and Polestar) offer the integrated Android Automotive experience out-of-the-box in their vehicles. System images and implementation details, however, are proprietary and require enrollment into their respective developer partnership programs. Polestar offers a free AV D that emulates Polestar 2 behavior, along with the screen size, frame and hardware controls – alas, currently only available for x86-64 platforms.
One of the alternatives worth considering is the installation of Android Automotive on a real device – be it a tablet or even a Raspberry Pi platform . Some modules will still require virtualization, but switching to a physical device could be a major step in the direction of better hardware compatibility.
All the above concerns raise the question – how to get the app to work on a real AAOS inside a car? I haven’t found a conclusive answer to that question, at least one that won’t involve third parties holding the actual documentation resources for their devices. It makes sense that some doors will stay closed to the general programming audience due to the security implications of creating apps for cars. No one, after all, would want their vehicle to be taken control of by a rogue party, would they?
Final thoughts
Programming for Android Automotive is still an adventurous endeavor. Even though the system has been around since 2017 (with APIs open to public in mid-2019), official documentation can still feel somewhat inaccessible to newcomers, and the developer community is still in its budding phase. This requires one to piece together various bits of official guides and general Stack Overflow knowledge.
Bottom line: AAOS is still behind the degree of engagement that the regular Android operating system has been enjoying so far. The future is looking bright, however, with vendors such as GM, Honda, BMW, and Ford eager to jump on the automotive development bandwagon in years to come. If that’s the case, the ecosystem will inevitably expand – and so will the community and the support it provides.

gRPC streaming
Previous articles presented what Protobuf is and how it can be combined with gRPC to implement simple synchronous API. However, it didn’t present the true power of gRPC, which is streaming, fully utilizing the capabilities of HTTP/2.0.
Contract definition
We must define the method with input and output parameters like the previous service. To follow the separation of concerns, let’s create a dedicated service for GPS tracking purposes. Our existing proto should be extended with the following snippet.
message SubscribeRequest {
string vin = 1;
}
service GpsTracker {
rpc Subscribe(SubscribeRequest) returns (stream Geolocation);
}
The most crucial part here of enabling streaming is specifying it in input or output type. To do that, a keyword stream is used. It indicates that the server will keep the connection open, and we can expect Geolocation messages to be sent by it.
Implementation
@Override
public void subscribe(SubscribeRequest request, StreamObserver<Geolocation> responseObserver) {
responseObserver.onNext(
Geolocation.newBuilder()
.setVin(request.getVin())
.setOccurredOn(TimestampMapper.convertInstantToTimestamp(Instant.now()))
.setCoordinates(LatLng.newBuilder()
.setLatitude(78.2303792628867)
.setLongitude(15.479358124673292)
.build())
.build());
}
The simple implementation of the method doesn’t differ from the implementation of a unary call. The only difference is in how onNext the method behaves; in regular synchronous implementation, the method can’t be invoked more than once. However, for method operating on stream, onNext may be invoked as many times as you want.
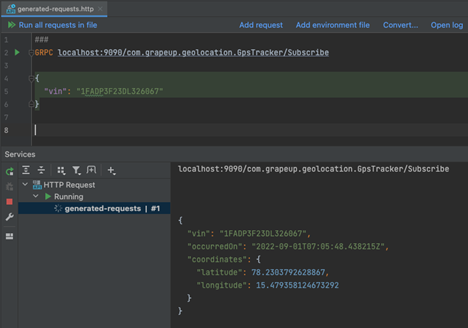
As you may notice on the attached screenshot, the geolocation position was returned but the connection is still established and the client awaits more data to be sent in the stream. If the server wants to inform the client that there is no more data, it should invoke: the onCompleted method; however, sending single messages is not why we want to use stream.
Use cases for streaming capabilities are mainly transferring significant responses as streams of data chunks or real-time events. I’ll try to demonstrate the second use case with this service. Implementation will be based on the reactor ( https://projectreactor.io / ) as it works well for the presented use case.
Let’s prepare a simple implementation of the service. To make it work, web flux dependency will be required.
implementation 'org.springframework.boot:spring-boot-starter-webflux'
We must prepare a service for publishing geolocation events for a specific vehicle.
InMemoryGeolocationService.java
import com.grapeup.grpc.example.model.GeolocationEvent;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Sinks;
@Service
public class InMemoryGeolocationService implements GeolocationService {
private final Sinks.Many<GeolocationEvent> sink = Sinks.many().multicast().directAllOrNothing();
@Override
public void publish(GeolocationEvent event) {
sink.tryEmitNext(event);
}
@Override
public Flux<GeolocationEvent> getRealTimeEvents(String vin) {
return sink.asFlux().filter(event -> event.vin().equals(vin));
}
}
Let’s modify the GRPC service prepared in the previous article to insert the method and use our new service to publish events.
@Override
public void insert(Geolocation request, StreamObserver<Empty> responseObserver) {
GeolocationEvent geolocationEvent = convertToGeolocationEvent(request);
geolocationRepository.save(geolocationEvent);
geolocationService.publish(geolocationEvent);
responseObserver.onNext(Empty.newBuilder().build());
responseObserver.onCompleted();
}
Finally, let’s move to our GPS tracker implementation; we can replace the previous dummy implementation with the following one:
@Override
public void subscribe(SubscribeRequest request, StreamObserver<Geolocation> responseObserver) {
geolocationService.getRealTimeEvents(request.getVin())
.subscribe(event -> responseObserver.onNext(toProto(event)),
responseObserver::onError,
responseObserver::onCompleted);
}
Here we take advantage of using Reactor, as we not only can subscribe for incoming events but also handle errors and completion of stream in the same way.
To map our internal model to response, the following helper method is used:
private static Geolocation toProto(GeolocationEvent event) {
return Geolocation.newBuilder()
.setVin(event.vin())
.setOccurredOn(TimestampMapper.convertInstantToTimestamp(event.occurredOn()))
.setSpeed(Int32Value.of(event.speed()))
.setCoordinates(LatLng.newBuilder()
.setLatitude(event.coordinates().latitude())
.setLongitude(event.coordinates().longitude())
.build())
.build();
}
Action!
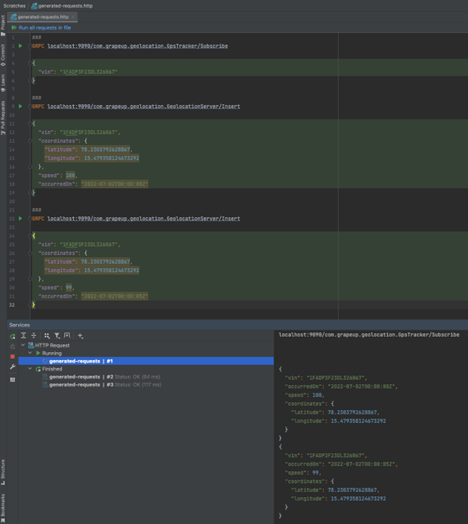
As you may be noticed, we sent the following requests with GPS position and received them in real-time from our open stream connection. Streaming data using gRPC or another tool like Kafka is widely used in many IoT systems, including Automotive .
Bidirectional stream
What if our client would like to receive data for multiple vehicles but without initial knowledge about all vehicles they are interested in? Creating new connections for each vehicle isn’t the best approach. But worry no more! While using gRPC, the client may reuse the same connection as it supports bidirectional streaming, which means that both client and server may send messages using open channels.
rpc SubscribeMany(stream SubscribeRequest) returns (stream Geolocation);
Unfortunately, IntelliJ doesn’t allow us to test this functionality with their built-in client, so we have to develop one ourselves.
localhost:9090/com. grapeup.geolocation.GpsTracker/SubscribeMany
com.intellij.grpc.requests.RejectedRPCException: Unsupported method is called
Our dummy client could look something like that, based on generated classes from the protobuf contract:
var channel = ManagedChannelBuilder.forTarget("localhost:9090")
.usePlaintext()
.build();
var observer = GpsTrackerGrpc.newStub(channel)
.subscribeMany(new StreamObserver<>() {
@Override
public void onNext(Geolocation value) {
System.out.println(value);
}
@Override
public void onError(Throwable t) {
System.err.println("Error " + t.getMessage());
}
@Override
public void onCompleted() {
System.out.println("Completed.");
}
});
observer.onNext(SubscribeRequest.newBuilder().setVin("JF2SJAAC1EH511148").build());
observer.onNext(SubscribeRequest.newBuilder().setVin("1YVGF22C3Y5152251").build());
while (true) {} // to keep client subscribing for demo purposes :)
If you send the updates for the following random VINs: JF2SJAAC1EH511148 , 1YVGF22C3Y5152251 , you should be able to see the output in the console. Check it out!
Tip of the iceberg
Presented examples are just gRPC basics; there is much more to it, like disconnecting from the channel from both ends and reconnecting to the server in case of network failure. The following articles were intended to share with YOU that gRPC architecture has so much to offer, and there are plenty of possibilities for how it can be used in systems. Especially in systems requiring low latency or the ability to provide client code with strict contract validation.

Dependency injection in Cucumber-JVM: Sharing state between step definition classes
It's an obvious fact for anyone who's been using Cucumber for Java in test automation that steps need to be defined inside a class. Passing test state from one step definition to another can be easily achieved using instance variables, but that only works for elementary and small projects. In any situation where writing cucumber scenarios is part of a non-trivial software delivery endeavor, Dependency Injection (DI) is the preferred (and usually necessary!) solution. After reading the article below, you'll learn why that's the case and how to implement DI in your Cucumber-JVM tests quickly.
Preface
Let's have a look at the following scenario written in Gherkin:
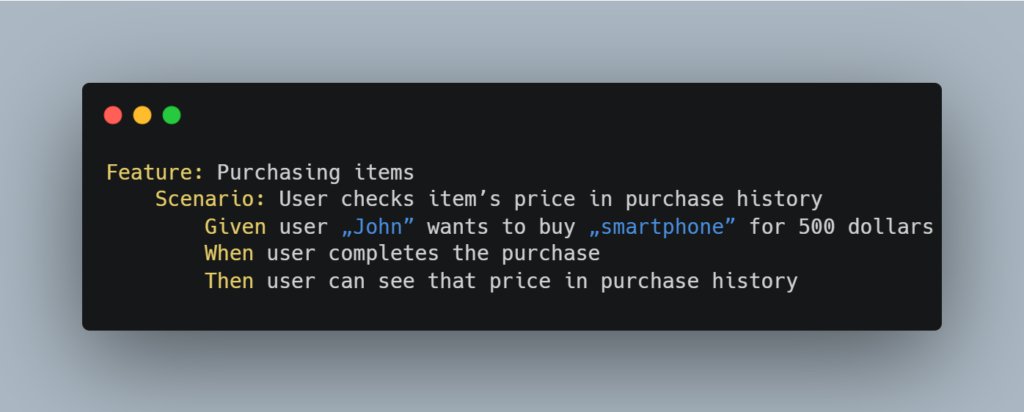
If we assume that it's part of a small test suite, then its implementation using step definitions within the Cucumber-JVM framework could look like this:
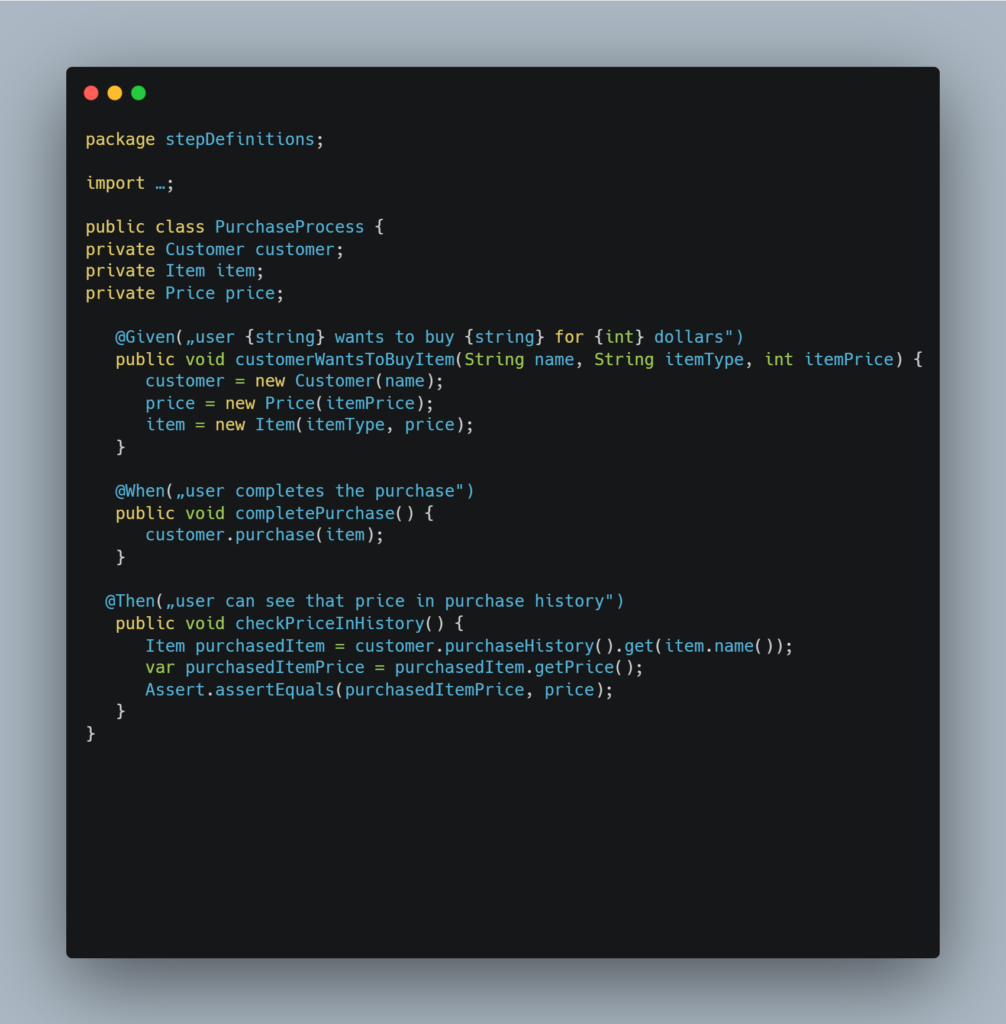
In the example above, the data is passed between step definitions (methods) through instance variables. This works because the methods are in the same class – PurchaseProcess, since instance variables are generally accessible only inside the same class that declares them.
Problem
The number of step definitions grows when the number of Cucumber scenarios grows. Sooner or later, this forces us to split our steps into multiple classes - to maintain code readability and maintainability, among other reasons. Applying this truism to the previous example might result in something like this:
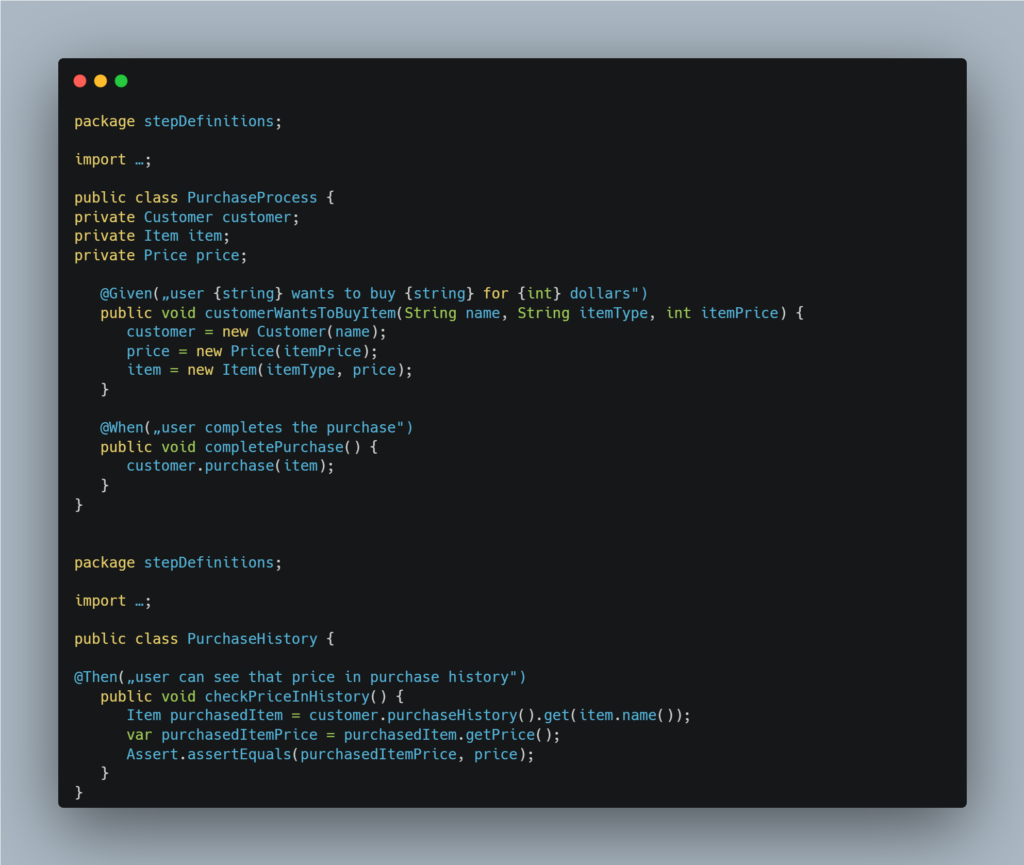
But now we face a problem: the checkPriceInHistory method moved into the newly created PurchaseHistory class can't freely access data stored in instance variables of its original PurchaseProcess class.
Solution
So how do we go about solving this pickle? The answer is Dependency Injection (DI) – the recommended way of sharing the state between steps in Cucumber-JVM.
If you're unfamiliar with this concept, then go by Wikipedia's definition:
"In software engineering , dependency injection is a design pattern in which an object or function receives other objects or functions that it depends on. A form of inversion of control , dependency injection aims to separate the concerns of constructing and using objects, leading to loosely coupled programs. [1] [2] [3] The pattern ensures that an object or function which wants to use a given service should not have to know how to construct those services. Instead, the receiving ' client ' (object or function) is provided with its dependencies by external code (an 'injector'), which it is not aware of." [1]
In the context of Cucumber, to use dependency injection is to "inject a common object in each class with steps. An object that is recreated every time a new scenario is executed." [2]
Thus Comes PicoContainer
JVM implementation of Cucumber supports several DI modules: PicoContainer, Spring, Guice, OpenEJB, Weld, and Needle. PicoContainer is recommended if your application doesn't already use another one. [3]
The main benefits of using PicoContainer over other DI modules steam from it being tiny and simple:
- It doesn't require any configuration
- It doesn't require your classes to use any APIs
- It only has a single feature – it instantiates objects [4]
Implementation
To use PicoContainer with Maven, add the following dependency to your pom.xml :
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-picocontainer</artifactId>
<version>7.8.1</version>
<scope>test</scope>
</dependency>
If using Gradle, add:
compile group: 'io.cucumber', name: 'cucumber-picocontainer', version: ‚7.8.1’
To your build.gradle file.
Now let's go back to our example code. The implementation of DI using PicoContainer is pretty straightforward. First, we have to create a container class that will hold the common data:
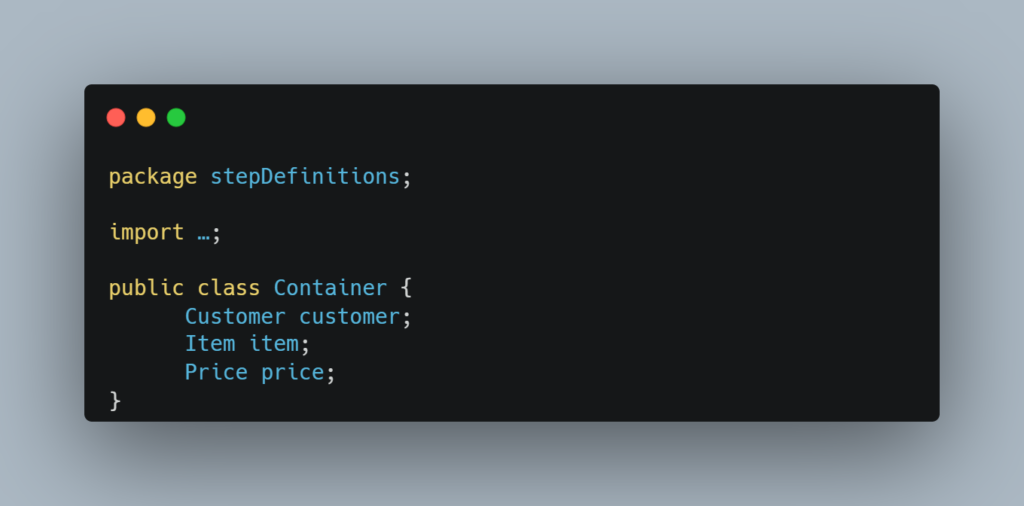
Then we need to add a constructor injection to implement the PurchaseProcess and PurchaseHistory classes. This boils down to the following:
- creating a reference variable of the Container class in the current step classes
- initializing the reference variable through a constructor
Once the changes above are applied, the example should look like this:
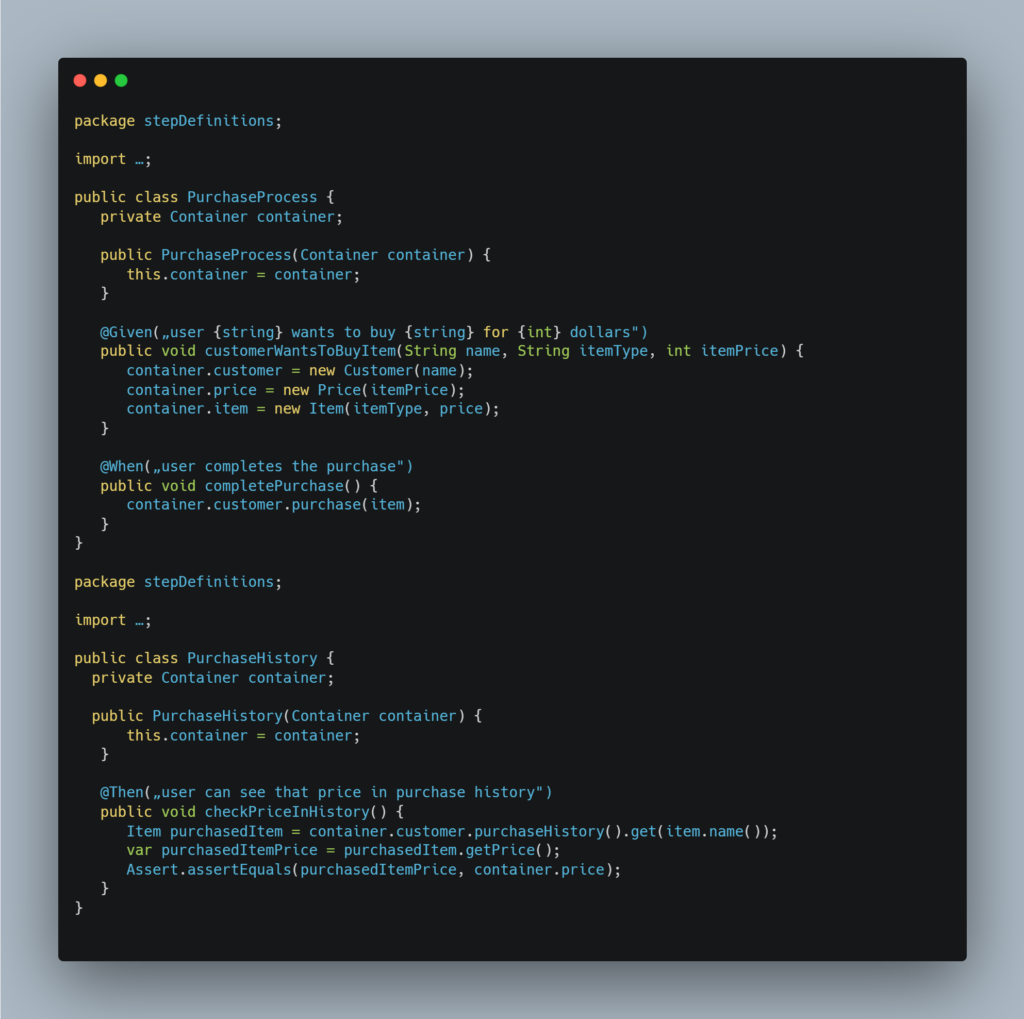
Conclusion
PicoContainer is lightweight and easy to implement. It also requires minimal changes to your existing code, helping to keep it lean and readable. These qualities make it a perfect fit for any Cucumber-JVM project since sharing test context between classes is a question of 'when' and not 'if' in essentially any test suite that will grow beyond a few scenarios.

Android Automotive OS 13: How to build and run the latest OS on Raspberry Pi 4B
Building an Android Automotive OS might not be a difficult task on its own, but the lack of good tutorials makes it exceptionally hard. It only gets harder if you don't have at hand any specialized hardware like R-Car or Dragonboard. However, you can easily get a Raspberry Pi - a small ARM-powered, multi-usage computer and a perfect candidate to run AAOS. To make the process easier for everyone struggling with this kind of task, in this article, I'll explain step-by-step how to build and run the latest version: Android Automotive OS 13.
Let's get started!
Prerequisites
To build the system, you will need a Linux. You can use WSL or MacOS (remember, you need a case-sensitive file system), but pure Linux is the best option.
Hardware
As in the previous article , you need a Raspberry Pi 4B microcomputer, a power adapter (or you can power it from your PC with a USB cable), a memory card, and a display. It's nice to have a touchscreen, but you can use your mouse and, optionally, a keyboard if more convenient.
Another nice-to-have element is a USB-TTL bridge for debugging. Find my previous article for more details on how to use it.
TL;DR;
If you're looking for the effortless way, go to https://github.com/grapeup/aaos_local_manifest and follow the readme. There are just a few commands to download, build and create a writeable IMG file for your Raspberry. But you need a few hours to download and build it anyway. Warning! It may not start if you won’t adjust the display settings (see below for details).
Adjusting AOSP to make it AAOS
This project is based on Raspberry Vanilla by KonstaT - a great AOSP port for Raspberry Pi. It covers everything you need to run a pure Android on your Raspberry - an adjusted kernel, hardware drivers, etc. However, there is no automotive build, so you need to construct it.
There are four repositories in github.com/grapeup regarding AAOS – three forks based on Raspberry Vanilla and one new one.
The repository aaos_local_manifest contains a list of modified and new repositories. All significant changes are located in device/brcm/rpi4 and device/brcm/rpi4-car projects defined in the manifest_brcm_rpi4.xml file. In the readme of this repository, you'll find steps to clone and build the project.
The next repository, aaos_device_brcm_rpi4 , contains three elements:
The first and most important is to utilize the new rpi4-car project and remove conflicting items from the base project.
In the aosp_rpi4.mk file, there is a new line
$(call inherit-product, device/brcm/rpi4-car/rpi4_car.mk)
to include a new project.
In the device.mk file, the product characteristic is changed to " automotive,nosdcard " , and all custom overlays are removed, along with the overlay directory next to the file.
In the manifest.xml file, the " android.hardware.automotive.vehicle " HAL (Hardware Abstraction Layer) is added.
The second element is to configure the build for the display I use . I had to set the screen resolution in vendor.prop and set the screen density in BoardConfig.mk . You probably don’t need such changes if you use a standard PC monitor, or you need some other one for your custom display. Be aware that the system won’t start at all if the resolution configured here is not supported by your display.
The last element contains my regional/language settings in aosp_rpi4.mk . I've decided to use this file, as it's not automotive-related, and to leave it in the code to show how to adjust it if needed.
The main part
The most major changes are located in the aaos_device_brcm_rpi4_car repository.
The rpi4_car.mk file is based on device/generic/car/common/car.mk with few changes.
Conditional, special settings for the Generic System Images are removed along with the emulator configuration ( device/generic/car/common/config.ini ) and the emulator audio package ( android.hardware.audio.service-caremu ) .
Instead, you need a mixture of vendor-specific and board-specific components, not included in the common/car makefile designed for an emulator.
Android Automotive OS is strictly coupled with an audio engine, so you need to add an automotive audio control package (android.hardware.automotive.audiocontrol@2.0-service ) to make it work, even if you don’t want to connect any speakers to your board. Also, AAOS uses a special display controller with the ability to use two displays at the same time ( android.frameworks.automotive.display@1.0-service ) , so you need to include it too. The next part is SELinux policy for real boards (not an emulator).
BOARD_SEPOLICY_DIRS += device/generic/car/common/sepolicy
Then you need to add permissions to a few pre-installed, automotive-oriented packages, to allow them to run in the system or user spaces.
PRODUCT_COPY_FILES += device/google/cuttlefish/shared/auto/preinstalled-packages-product-car-cuttlefish.xml:$(TARGET_COPY_OUT_PRODUCT)/etc/sysconfig/preinstalled-packages-product-car-cuttlefish.xml
The next component is EVS - Exterior View System introduced to AAOS 13. Even if you don’t really want to connect multiple cameras to the system so far, you have to include the default implementation of the component and configure it to work as a mock.
DEVICE_PACKAGE_OVERLAYS += device/google/cuttlefish/shared/auto/overlay
ENABLE_EVS_SERVICE ?= true
ENABLE_MOCK_EVSHAL ?= true
ENABLE_CAREVSSERVICE_SAMPLE ?= true
ENABLE_SAMPLE_EVS_APP ?= true
ENABLE_CARTELEMETRY_SERVICE ?= true
CUSTOMIZE_EVS_SERVICE_PARAMETER := true
PRODUCT_PACKAGES += android.hardware.automotive.evs@1.1-service
PRODUCT_COPY_FILES += device/google/cuttlefish/shared/auto/evs/init.evs.rc:$(TARGET_COPY_OUT_VENDOR)/etc/init/init.evs.rc
BOARD_SEPOLICY_DIRS += device/google/cuttlefish/shared/auto/sepolicy/evs
The last part is to adjust variables for a system when running. You set two system properties directly in the makefile (to allow a forced orientation and to enable the AVRCP Bluetooth profile).
PRODUCT_SYSTEM_DEFAULT_PROPERTIES += \
config.override_forced_orient=true \
persist.bluetooth.enablenewavrcp=false
In the end, you override the following system variables, using predefined and custom overlays.
PRODUCT_PACKAGE_OVERLAYS += \
device/brcm/rpi4-car/overlay \
device/generic/car/common/overlay
Generally speaking, PRODUCT_PACKAGE_OVERLAYS allows us to overwrite any value from a property file located in the source code. For example, in our case the overlay root directory is device/brcm/rpi4-car/overlay , so the file device/brcm/rpi4-car/overlay/frameworks/base/core/res/res/values/config.xml overwrites properties from the file frameworks/base/core/res/res/values/config.xml.
Let’s dive into properties changed.
- frameworks/base/core/res/res/values/config.xml file :
- config_useVolumeKeySounds disables usage of hardware volume keys, as they are not present in our setup,
- config_voice_capable enables data-only mode, as there is no possibility to make a voice call from our board,
- config_sms_capable disables SMS capabilities for the same reason,
- networkAttributes and radioAttributes sets the system to use WiFi, Bluetooth and ethernet connections only, as there is no GSM modem onboard,
- config_longPressOnPowerBehavior disables long-press on a power button, as there is no power button connected,
- config_disableUsbPermissionDialogs disables USB permission screen, as it shouldn’t be used in the AAOS,
- config_defaultUiModeType enables the automotive launcher by default,
- config_defaultNightMode enables night mode as the default one.
- frameworks/base/packages/SettingsProvider/res/values/defaults.xml file:
- def_wifi_on enables WiFi by default,
- def_accelerometer_rotation sets the default orientation,
- def_auto_time enables obtaining time from the Internet when connected,
- def_screen_brightness sets the default screen brightness,
- def_bluetooth_on enables Bluetooth by default,
- def_location_mode allows applications to use location services by default,
- def_lockscreen_disabled disables the lockscreen,
- def_stay_on_while_plugged_in sets the device to stay enabled all the time.
-
packages/apps/Car/LatinIME/res/layout/input_keyboard.xmlkeyTextColorPrimaryandtextColorparameters to adjust it. -
packages/apps/Car/LatinIME/res/values/colors.xmlsets colors or symbol characters on the default keyboard and the letter/symbols switch on the bottom right corner. -
packages/apps/Car/SystemUI/res/values/colors.xml sets the background color of the status bar quick settings to make the default font color readable. -
packages/apps/Car/SystemUI/res/values/config.xml
- packages/apps/Settings/res/values/config.xml file :
- config_show_call_volume disables volume control during calls,
- config_show_charging_sounds disables charging sounds,
- config_show_top_level_battery disables battery level icon.
- packages/modules/Wifi/service/ServiceWifiResources/res/values/config.xml enables 5Ghz support for the WiFi.
-
packages/services/Car/service/res/values/config.xmldisables running a dedicated application when the system starts up or a driver is changed.
You can read more about each of those settings in the comments in the original files which those settings came from.
The very last repository is aaos_android_hardware_interfaces . You don’t need it, but there is one useful property hardcoded here. In Android, there is a concept called HAL – Hardware Abstraction Layer. For AAOS, there is VHAL - Vehicle Hardware Abstraction Layer. It is responsible, among others, for HVAC - Heating, Ventilation, and Air Conditioning. In our setup, there is no vehicle hardware and no physical HVAC, so you use android.hardware.automotive.vehicle@V1-emulator-service whose default implementation is located under hardware/interfaces/automotive/vehicle . To change the default units used by HVAC from imperial to rest-of-the-world, you need to adjust the hardware/interfaces/automotive/vehicle/aidl/impl/default_config/include/DefaultConfig.h file.
Building
The building process for AAOS 13 for Raspberry Pi is much easier than the one for AAOS 11. The kernel is already precompiled and there is much less to do.
Just call those three commands:
. build/envsetup.sh
lunch aosp_rpi4-userdebug
make bootimage systemimage vendorimage
On a Windows laptop (using WSL, of course) with the i7-12850HX processor and 32GB RAM, it takes around 1 hour and 40 minutes to accomplish the build.
Creating a bootable SD card
There are two options – with or without the mkimg.sh script. The script is located under device/brcm/rpi4 directory and linked in the main directory of the project as rpi4-mkimg.sh . The script creates a virtual image and puts 4 partitions inside - boot, system, vendor , and userdata . It's useful because you can use Raspberry Pi Imager to write it into an SD card however, it has a few limitations. The image always has 7GB (you can change it by adjusting the IMGSIZE variable in the script), so you won't use the rest of your card, no matter how big it is. Besides that, you always need to write 7GB to your card - even if you have to update only a single partition, and including writing zeros to an empty userdata partition.
The alternative way is to write it on the card by hand. It's tricky under Windows as WSL doesn't contain card reader drivers, but it's convenient in other operating systems. All required files are built in the out/target/product/rpi4 directory. Let's prepare and write the card. Warning! In my system, the SD card is visible as /dev/sdb . Please adjust the commands below not to destroy your data.
OK, let’s clean the card. You need to wipe each partition before wiping the entire device to remove file systems signatures.
sudo umount /dev/sdb*
sudo wipefs -a /dev/sdb*
sudo wipefs -a /dev/sdb
Now let’s prepare the card. This line will use fdisk to create 4 partitions and set flags and filesystems.
echo -e "n\n\n\n\n+128M\na\nt\n0c\nn\n\n\n\n+2G\nn\n\n\n\n+256M\nn\np\n\n\nw\n" | sudo fdisk /dev/sdb
The last step is to write data and prepare the last partition.
sudo dd if=boot.img of=/dev/sdb1 bs=1M
sudo dd if=system.img of=/dev/sdb2 bs=1M
sudo dd if=vendor.img of=/dev/sdb3 bs=1M
sudo mkfs.ext4 -L userdata /dev/sdb4
sudo umount /dev/sdb*
Summary
Android Automotive OS is a giant leap for the automotive industry . As there is no production vehicle with AAOS 13 so far, you can experience the future with this manual. What's more, you can do it with a low-budget Raspberry Pi computer. This way, I hope you can develop your applications and play with the system easily without an additional layer of using emulators. Good luck and happy coding!

Native app vs. hybrid app: How to choose a solution that meets your business needs
Every time we start a new project, we organize brainstorming sessions about architecture and how to manage the project. Regarding mobile apps, we have one additional question – should we choose a hybrid or native app?
Let's start from the absolute beginning. What is a native app?
A native app is a software or program developed to carry out a specific task within a platform or environment. Native apps are built using software development tools (SDK) for particular software frameworks, hardware platforms, or operating systems. Native apps are built for use on a particular device, such as Apple iPhone or Google Android. To create an iOS application, we use Swift, which replaced Objective-C a few years ago. If we want our app to be available on Android phones, we can choose Kotlin (more popular) or Java (replaced by Kotlin a few years ago, however, we can still use it). Let's start by discussing the pros and cons of native apps.
PROS
First – native apps are stable and reliable. That's especially worthwhile cause if you work on large projects, you want to focus on implementing new features, not fight with platform limitations. While working on a native app, you can be sure you will find well-prepared documentation for each part of the SDK – it does not matter if it's a camera, Bluetooth, or design principles.
If you want to use a specific part of SDK or hardware that is specific to a platform, such as Bluetooth, a camera native app also would be a better choice. Even if you decide to go hybrid, these components need to be handled by native code, so you would need a library or plugins. It doesn't make sense to use native frameworks in hybrid apps.
If we are planning a big battery driller app with a beautiful, complicated, animated UI, we should choose a native app. Performance and responsiveness are much better than hybrid can offer. Same thing if we're talking about UX; better UX equals digital customer engagement.
All these points are essential, but what matters the most is security. You should know that native apps are much safer, more stable, and less vulnerable to security risks.
CONS
Of course, native apps are not perfect, and we can easily find examples of ideas when a hybrid app would be a better choice.
Native apps, of course, have a separate codebase for Android and iOS. This means we have (at least) two teams to manage one project. This also reflects bug fixing – it's much easier and takes less time to find and fix bugs if we have one code base.
You should also consider the time you have to create an app. Developing on multiple platforms means a more extended development schedule and, as a result, higher development costs. Therefore, native app development quickly eats up resources.
Go hybrid?
You always have a choice 😊 Native app is a clever idea, but is it always the best one, and what is it - a hybrid app? A (hybrid app) is a software application that combines elements of both native apps and web applications. Simply – it is the technology where we share the codebase between platforms – Android and iOS. The most popular frameworks are:
- React Native
- Flutter
- Xamarin
- KMM (soon 😉)
Let's discuss the pros and cons of hybrid apps.
PROS
Of course, the most significant advantage of hybrid apps is that they can be used across platforms and devices – they share one code base. Cool, isn't it? This means more accessible updates, bug fixes, and maintenance. Also, Development is much simpler and quicker by not having to build from the ground up for each platform.
A crucial thing is the deployment process. Hybrid apps can be deployed much faster than native apps, which can be extremely helpful, especially in big, complicated projects.
Regarding performance, reduced time frames equate to reduced resource drain. We should keep that in mind.
Finally - Hybrid apps can take advantage of dynamic web content. If you plan to create a big social platform – mobile app, web page, and so on – you should consider a hybrid app.
CONS
Looks interesting, right? Well, it is not an ideal solution. Like everything else – it has some limitations.
As we mentioned, there are components that 100% rely on device-specific components or hardware – like cameras, Bluetooth, etc. To use that feature in hybrid applications, we need to implement plugins or parts – or create them ourselves. That can be time assuming but also can present security risks.
The second important thing is user experience - it can suffer as hybrid apps cannot take advantage of the platform's UI.
The last thing - being unable to take full advantage of the hardware sometimes impacts the performance of our applications by making them poor and insecure.
There is one proposition that eliminates most of our cons – KMM, Kotlin Multiplatform Mobile. Its significant advantage is that we share the whole business logic between platforms – Android and iOS using Kotlin language. We create separate native layouts and UI layers for each platform. But of course – there is a problem 😊 KMM is still in the alpha phase, and, in my opinion, it is not production ready yet. But we should keep an eye on that as it might be a revolution.
Summary
It is not an easy task to choose the best technology. We should consider many varied factors that can impact our app. Here are key takeaways for both solutions – native and hybrid.
Native apps: Key takeaways
Native apps provide the best stability and security. They will tend to perform faster and be able to handle the most demanding tasks. This kind of application is best placed to use specific devices' hardware functionality. The user experience is smooth and featureful.
Hybrid apps: Key takeaways
Hybrid apps are easy to get onto iOS and Android. By utilizing a single codebase, you can reduce budget and time costs.

Dynamic pricing: How car rentals use connected car data to increase revenue
By 2025, over 400 million connected cars will be on the road. Car rentals and fleet managers can use connected car data to manage their vehicles more effectively and increase revenue. A huge part of that approach is related to dynamic pricing – a data-driven technique enabling you to set the best prices for your service. Let’s have a look at how your business can benefit from dynamic pricing and connected car data.
Vehicles generate tons of valuable information. Most of it comes from their engine control units (ECUs) that collect data from many different sensors within the engine and controller area networks that enable microcontrollers and devices to communicate.
Thanks to data coming from these and other sources, the car rental company can have immediate access to telemetry data, including:
- The specific vehicle’s location
- Its current engine status and speed
- The vehicle’s status (e.g., if the car is locked) etc.
As a derivative of the telemetry data, you can also understand the driving style of a given driver.
Interestingly, the connected car penetration has already surpassed that of non-connected cars ( over 50% market share in Q2 2022 ) [1] .
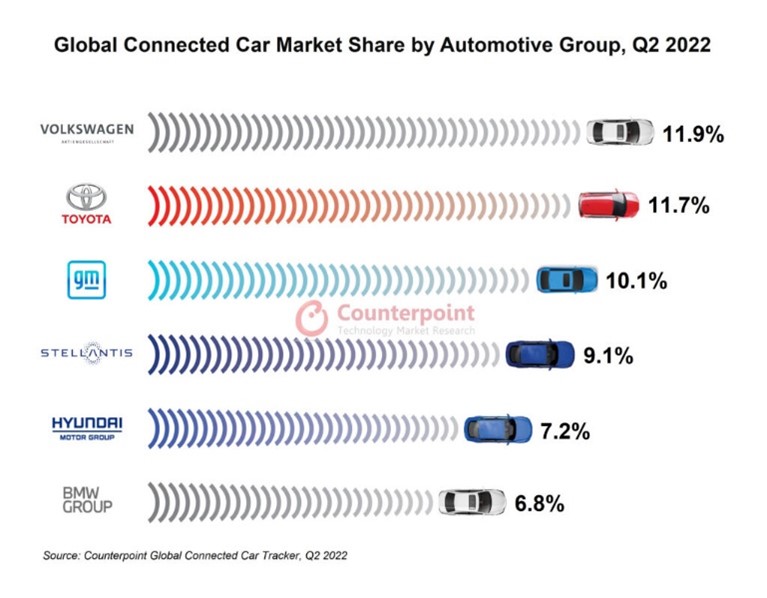
Because connected car data provides automotive businesses with useful input (especially when combined with web and market data ), car rentals and fleet managers can use it to adjust their offers and, thus, grow revenue. Here, dynamic pricing is the most prominent solution.
What is dynamic pricing?
In a nutshell, it’s a data-driven strategy that exploits intelligent algorithms (frequently based on machine learning and automation) to set and maintain the best prices within specific market conditions.
Dynamic pricing algorithms continually analyze the available data (coming from the website, the market, and the vehicles themselves) and use it to automatically adjust prices and other service conditions available on your website or in your app.
As a result, prices for renting a car can be optimized multiple times a week (or even a day) depending on:
- Current demand and car availability
- Time of day
- Traffic conditions
- Fuel prices
- Previous driving history of a given user
- And even the likelihood that a given person will be happy to pay more for the service (e.g., because they are running out of battery in their cellphone and they need to arrange transportation quickly)
Dynamic pricing is prevalent in both large car rentals, rideshare companies, and mobility-as-a-service providers, such as Uber. And speaking of Uber, some time ago, Forbes published an article explaining how Uber’s pricing works. They use an advanced dynamic pricing algorithm based on AI and multiple price points to determine the optimal price each user sees in their app.

As a result, Uber can charge the optimal rate for every ride, which helps them make more money. A similar solution can be introduced in any car rental company.
But the price of the service is just one puzzle piece. When it comes to car rentals, there are other conditions and fees renters have to be aware of before signing on the dotted line. Here, connected car data can also be of help! Let’s dig a bit deeper.
Dynamic pricing, connected car data, and the question of the insurance
Renting a car involves additional fees, primarily insurance, which is almost always mandatory . It stands to reason that this fee should also be dependent on a given driver and their experience and driving habits.
Insurance companies have been collecting data about drivers’ behaviors for years. And yes, they’ve been using it to calculate insurance premiums and offer discounts (so-called usage-based insurance – UBI ). Today, it’s possible thanks to mobile applications that have to be always on when driving a car. Such an app can track each driver’s behavior on the road. Soon, though, connected car data will replace these apps altogether.
Although this idea is still in its infancy, we can expect that it will be shortly doable on a large scale, especially given the fact that the number of connected vehicles is continually going up (the global connected car market size is projected to reach almost USD 192 billion by 2028 – CAGR of 18.1% [2] ).
The first applications enabling the implementation of dynamic pricing in car insurance are already here. Thanks to millions of connected cars offering trillions of data points, car rental companies can understand their customers and their driving behaviors.
This knowledge can be used to offer cheaper insurance and other rental fees to renters with a proven history of safe driving. Another idea worth considering is using data from connected vehicles to improve reward and loyalty programs (a safe driver could get discounts to rent a car or get additional loyalty points).
However, there are still some challenges that need to be addressed.
The challenges of making the most of connected car data...
As McKinsey explains in their recent report , “ many OEMs have struggled with connectivity or related software developments, resulting in poor customer reviews and delayed start of production ”. Car manufacturers and other OEMs struggle with convincing customers that car-connectivity services deliver additional value. Add poor execution of services and communication issues to the mix, and it becomes obvious that consumers are still a bit reluctant towards such services. It’s the same story with usage-based insurance.
In 2021, there was a survey conducted in Canada concerning UBI. 77% of Canadians are concerned about potential rate hikes. And 51% are hesitant in case it negatively affects their current insurance rates [3] .
And then, there is the data management issue. McKinsey estimates you need to access 1 to 2 terabytes of raw data per car each day to fully benefit from connected car data. That means huge data centers capable of processing all that information daily.
…and the inevitable future
The future of the automotive industry is software-centric, and car rentals and fleet management companies are no exception. As the number of connected vehicles goes up, we will be able to benefit from more advanced data-driven solutions.
At GrapeUp, we tirelessly work on them every day! We develop custom solutions for both OEMs and car rental companies that enable collecting data, seamless processing, and even distributing it further. All to allow you to make more money.
If you run a car rental company, we can help you implement the solutions discussed in this article. To find out more, see our offer for the automotive sector .
[1] https://www.counterpointresearch.com/global-connected-car-market-q2-2022/
[2] https://www.globenewswire.com/en/news-release/2022/08/17/2499966/0/en/Global-Connected-Car-Market-Size-to-Hit-USD-191-83-Billion-at-a-CAGR-of-18-1-for-2021-2028-Fortune-Business-Insights.html
[3] https://www.ratehub.ca/blog/ubi-saves-money-but-87-per-cent-not-trying-survey-data/
In-car infotainment: How to build long-term relationships and unlock new revenue streams
With the automotive industry seeking to create a more comfortable and enjoyable travel experience for its customers, automakers and designers are stepping up investment in in-car infotainment solutions. These technologies aim to personalize the travel experience by providing noise reduction, in-vehicle sound zones, and immersive audio/video content tailored to the driver's lifestyle. And more importantly, they contribute to building OEM customer loyalty, new revenue streams, and creating lasting customer relationships.
Four in-car entertainment strategies, almost endless opportunities to build a new offer
There is no turning back from in-car entertainment. The development of flat screens, broadband internet access, and the possibility of personalization and customization of content to the viewer are the reasons why no one is willing to give up this form of service.
For automakers, it's an opportunity to build a stronger relationship with their customers and create new (often subscription-based) revenue models .
For the driver and especially for passengers, it's about overcoming the boredom associated with long journeys and introducing solutions into vehicles that until now have been known for their high-end audiophile systems.
No wonder an increasing number of OEMs today are consciously developing the concept of the digital cockpit of the future . This approach is supposed to shift the focus from the practical functionality of the vehicle to providing compelling entertainment.
Most popular in-car infotainment strategies
Of course, the process of change is not simple and cannot happen overnight. It requires continuous growth in vehicle technological performance, partially related to the car's GPU, E/E Architecture, 5G Internet access, and the development of new display forms. Nevertheless, OEMs have at their disposal one of the following four strategies for developing such solutions.
1. Rear-Seat Entertainment
Using this strategy, entertainment is streamed to displays located in the rear seats or on the roof of the vehicle (for example, the BMW i7)... The user does not need to use a smartphone or tablet in addition to this solution to enjoy the leisure experience.
2. Any-Seat Entertainment
In this solution, content streaming can apply to all displays of the infotainment system in the car (including the driver's seat) - again without having to use smartphones and tablets to navigate. This concept allows video viewing, e.g., while charging an electric car.
3. Augmented Entertainment
A step further can be taken by manufacturers who incorporate the capabilities of 4D cinema and AR applications into their offer. This approach creates a whole new kind of driver's cockpit and develops a unique UX that may become a vehicle's trademark. This type of screen has a variety of potential applications, such as displaying destination-related information, traffic warnings, or intelligent terrain mapping of other vehicles. In the near future, this technology may also be used for augmented marketing, such as showing interesting offers and discounts from nearby restaurants, shops, or malls on the windscreen.
4. Live Entertainment
Finally, real-time entertainment services enable car-to-car interaction and/or social networking among vehicle users. These types of solutions can be used to share viewing, commentary, and engagement among vehicle users through cultural events or music concerts, for example.
New possibilities of infotainment in cars. The 2022 perspective
The ability to combine modern audio-visual technologies with data analytic s and personalized user information allows OEMs to create entirely new services and products, often ones previously unrelated to the automotive industry.
- Among these the most notable is, of course, streaming video and audio content, which is usually based on partnerships with third parties (e.g., Netflix, Amazon, YouTube, Apple TV or Spotify) and usually operate on a subscription model. In the future, the car is likely to become another medium where we can simply activate the service and continue watching videos, as we move from the living room to the vehicle.
- Access to gaming platforms and services that will provide an interactive way of spending time for the driver and passengers while traveling or charging their EV.
- A tourist offer that is related to visiting a particular place - acts as a virtual travel agency, which highlights specific points on the map and expands the knowledge of the visited locations (also in the form of quizzes or riddles for passengers).
- Audiovisual, highly personalized ads, tailored to the context of where we are traveling, the driver's needs, or resulting from the wear and tear of the vehicle components.
Dynamic growth of the in-car infotainment market
With each passing year, there are new examples of interesting implementations in in-car entertainment, and the market itself is growing rapidly. In 2020, it was valued at more than $21 million, while by 2028 it is predicted to grow to more than $37.5 million, registering a CAGR of 7.5% from 2021 to 2028.
Below is a rundown of the most interesting advanced infotainment solutions that are becoming increasingly popular and have been implemented by specific OEMs in recent times.
- Larger display and video entertainment on demand
With large displays and the increasingly widespread streaming of video and audio content into the vehicle, a substantial base is becoming established for the development of infotainment in the automotive industry.
It is all about introducing more immersive services and features in vehicles. This is especially relevant for EVs, because, after all, drivers need to pass their time somehow while charging their vehicles at public stations, and this can be done from the comfort of the car seat.
Total spending on video on demand is expected to reach $127 billion by 2025 (11.8% CAGR). Video streaming alone is expected to account for 86% of revenues .
The chart below illustrates how trends are changing in terms of screen sizes in today's automotive market . It is noticeable that, roughly since 2017, there has been a marked increase in the use of large displays in vehicles.
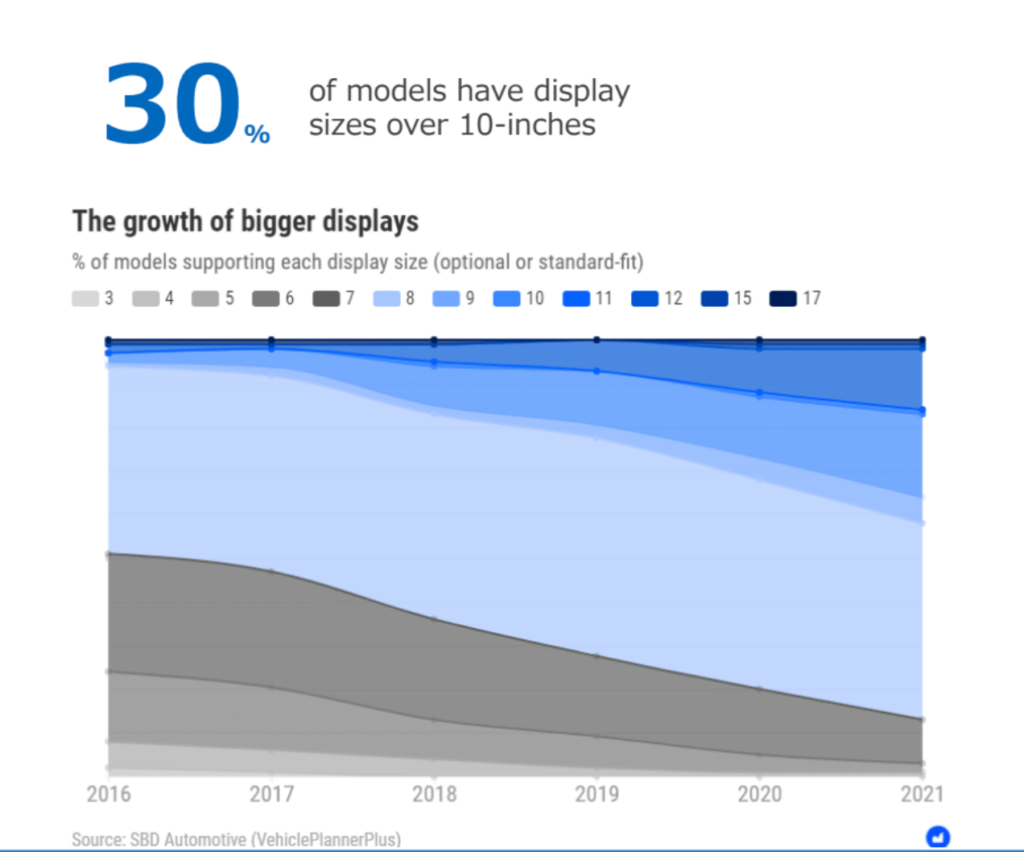
Continuing down this path, major OEMs are already announcing in-vehicle video streaming services that use this type of display and video entertainment. Some of the latest examples from the market are as follows:
- Jeep Wagoneer and Grand Wagoneer from the Stellantis fleet have recently been offering Amazon Fire TV as infotainment for rear-seat passengers. It allows users to stream movies, shows, or games via a Wi-Fi hotspot or download content for later. The same service will also be implemented in vehicles from Ford Motor Co . factories.

- Volvo intends to implement a YouTube app, available via the Play Store in vehicles equipped with Google Automotive Services. The idea is to provide entertainment while charging an EV.
- BMW has recently unveiled its proprietary Theater Screen concept. This mode adjusts lighting and dimming, converting the car's interior into a mobile theater. The idea is supposed to be workable thanks to a 31-inch widescreen display. It offers a 32:9 aspect ratio and 8K resolution and includes built-in Amazon Fire TV and smart TV features.

- Enhanced in-vehicle display capabilities with flexible interactive displays
Design teams are persistently seeking ways to further integrate displays into the surface of a car's dashboard. Some of the most remarkable solutions in the automotive market today are Flexible Interactive Displays (FITs).
They allow manufacturers to provide more display areas for infotainment functions . All vehicle elements, such as Center consoles, pillars, and seat backs, can potentially be converted into one large screen. It could extend across the entire passenger space, turning the vehicle into a mobile movie theater or high-tech office. These types of solutions are already being tested by ROYOLE.

This technology is essential not only for convenience but also for safety. This is due to the idea of replacing layers of glass (traditionally used in automotive electronics) with durable plastic.
In the future, it might be possible to build sensors (e.g. fingerprint reader) into the display area. This will enable the interface to be controlled from a screen spanning the entire surface.
- The sound provides a more comfortable experience
While video content has only recently begun to make its way into cars, a good sound system and access to music have always been part of the automotive experience (in fact, for many consumers they were an essential factor in deciding whether to purchase a particular vehicle). Car manufacturers and designers are well aware of this and are stepping up their investments in the following solutions.
- Noise reduction. A focused anti-noise system prevents the penetration of noises common to driving but does not block sounds important to maintaining safety (such as emergency sirens). Next-generation active noise cancellation has been applied, for example, in the new Cadillac Lyriq, where it intelligently measures road vibrations and, using an AKG speaker system, actively reduces noises from outside.
- In-vehicle Sound Zones. This allows the driver and passengers to access different audio content. There is also an option to share the same sound at different volume levels. An additional advantage of such solutions is that unwanted music from the back seat does not distract the driver during the ride.

Hyundai , for example, is testing such a solution. Whilst using the latest-generation Separated Sound Zone (SSZ) technology developed in-house, the Asian brand is able to create and control sound fields in the car. Both the driver and each passenger are able to hear isolated sounds without a headset.
- Immersive solutions customized to the driver's lifestyle
Key players in the market are becoming bolder in developing immersive technologies in their vehicles and emphasizing personalized options to tailor the journey to the user's specifications.
Developed by Mercedes-Benz, MBUX Hyperscreen is a prime example. It is designed to provide a high degree of individualized infotainment content. The vehicle users can determine for themselves which information to display in a specific place, in a specific order, and in line with a selected theme. In order to aggregate streaming content from various sources within its own vehicles, Mercedes has partnered with California-based ZYNC. The collaboration is expected to help develop a platform and interface that will allow access to digital entertainment from different providers.

The designers of the NIO ES7 Electric SUV are taking it even further. This vehicle will be equipped with Banyan smart OS software and NIO's Aquila Super Sensing and Adam Super Computing platform. All of these will be combined with a compatible digital cockpit based on AR/VR. This is a golden opportunity to"immerse" yourself in a world filled with colors and sounds . The passenger riding in the back can delight in a 200+ inch "screen" and a 7.1.4 Dolby Atmos sound system.

After all, the aforementioned EV is already being advertised by the developers as a "second living room," being a continuation of home entertainment. What is noteworthy is not just the audiovisual system itself, but also the options for dimming the lights or the appropriate choice of seat positions, which are supposed to make the viewer feel as if they are watching a movie at home. This is a perfect example of how the automotive industry is getting closer to the users, their daily life , and their habits.
Why is in-car infotainment a key to building long-term relationships and new revenue streams?
Tremendous competition and market oversupply make it more difficult than ever to commit a customer to a brand. User loyalty needs to be built in many possible ways and new ways to reach out with an offer need to be sought.
Car infotainment is at the cusp of dynamic development and is certainly one of the leading areas that can help find new groups of customers and create lasting relationships with them.
This type of technology is no longer an add-on option, but an indication of "being up-to-date." Manufacturers who focus on the development of car infotainment become trendsetters and initiators of change. They make it clear that they follow their consumers, and understand their lifestyles and expectations. And this is not insignificant for the modern consumer.
Research shows that customers are willing to pay more for a vehicle with these types of solutions - we're talking about up to $10,000 for a single car. In contrast, more than 70% of younger millennials list infotainment technology and features as "must-haves" when buying a car.
With these statistics in mind, it is necessary to remain competitive in this area and constantly develop the offer.
A special focus should be also put on the areas that build customer loyalty and connect them more strongly with the brand, for example:
- access to media- based on a subscription model,
- rich entertainment offerings for the driver and passengers;
- personalization features and adjusting to users' lifestyles;
- a fine-tuned user interface (UX), for a seamless and intuitive experience.
If you combine seamless and intuitive in-car infotainment with a deep understanding of consumer needs, chances for building long-term relationships and unlocking new revenue streams grow dramatically.
Build and run Android Automotive OS on Raspberry Pi 4B
Have you ever wanted to build your own Android? It’s easy according to the official manual, but it’s getting harder on a Windows (or Mac) machine, or if you’d like to run it on physical hardware. Still too easy? Let’s build Android Automotive OS – the same source code, but another layer of complexity. In this manual, we’ll cover all steps needed to build and run Android Automotive OS 11 AOSP on Raspberry Pi 4B using Windows. The solution is not perfect, however. The most principal issue is a lack of Google Services because the entire AAOS is on an open-source project and Google doesn’t provide its services this way. Nevertheless, let’s build the open-source version first, and then we can try to face incoming issues.
TL;DR: If you don't want to configure and build the system step-by-step, follow the simplified instruction at https://github.com/grapeup/aaos_11_local_manifest
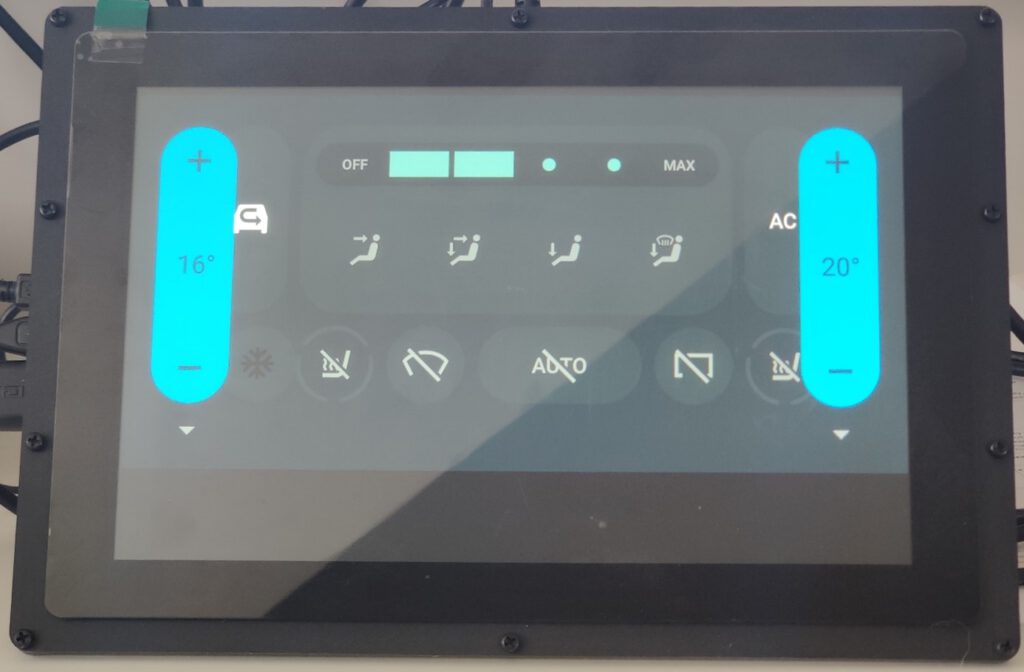
Prerequisites
Hardware
If you want to run the system on a physical device, you need one. I use the Raspberry Pi 4 model B with 8GB of RAM ( https://www.raspberrypi.com/products/raspberry-pi-4-model-b/ ). By the way, if you want to build and run an emulator from the source, it’s also possible, but there is a small limitation – packaging the emulator to a zip file, moving it to another computer, or even running it under Android Studio was introduced in Android 12.
To power your Raspberry, you need a power adapter (USB C, min. 5V 3A). I use the Raspberry-official 5.1V 3A model. You can also power the Raspberry computer from your desktop/laptop’s USB port, especially if you’re going to debug it via a serial connection. Check the “If it doesn’t work” section below for the required hardware.
Another piece of hardware needed is an SD card. In theory, 4GB is all you need, however, I recommend buying a larger card to have some extra space for your applications on Android . I use 32GB and 64GB cards. You’ll also need a built-in or external card reader. I use the latter.
The next step is a screen. It’s optional but fancy. You can connect your mouse and optionally keyboard to your Raspberry Pi via USB and connect any display you have via micro-HDMI but using a touch screen is much more intuitive. I use a Waveshare 10-inch screen dedicated to Raspberry ( https://www.waveshare.com/wiki/10.1inch_HDMI_LCD_(B)_(with_case ). The screen box has a place to screw the Raspberry too, so you don’t need any extra case. You can also buy it with a power adapter and a display cable.
If you don’t buy a bundle, make sure you have all necessary accessories: micro-HDMI – HDMI cable to connect a screen (Waveshare or any other), USB A – USB mini A cable to connect a touch sensor of the screen, USB mini A 5V 3A adapter to power the screen.

Of course, you need a computer. In this manual, we use a Windows machine with at least 512GB of storage (the Android source is huge) and 16GB of RAM.
Software
You can probably build everything in pure Windows, but the recommended method is to use WSL. I assume you already have it installed, so just make sure you have the newest WSL2 version. If you have never used WSL before, see the full manual here https://learn.microsoft.com/en-us/windows/wsl/install .
WSL adjustments
The standard WSL installation uses a too-small virtual drive and limited RAM, so you need to adjust it.
Let’s start with the disk. Make sure the WSL is shut down by running ‘wsl –shutdown’ in the command prompt. Open Windows Command Prompt with admin privileges and enter ‘diskpart ’. Then run ‘select vdisk file=”<path to WSL drive file>”’. For me, the path is “C:\Users\<user>\AppData\Local\Packages\CanonicalGroupLimited.Ubuntu_<WSL_instance_id>\LocalState\ext4.vhdx ”. Now you can expand it with the command ‘expand vdisk maximum=512000’. Around 300GB is enough for Android 11, but if you want to play with multiple branches of Android at the same time, you need more space. Now you can close the diskpart with the ‘exit’ command. Next, open the WSL and run ‘sudo resize2fs /dev/sdb 512000M’. I assume you have only a single drive attached to the WSL and it’s visible in the Linux subsystem as /dev/sdb. You can check it with the commands ‘sudo mount -t devtmpfs none /dev || mount | grep ext4’.
Now, let’s adjust the memory. Stop the WSL again. Open your home directory in Windows and open .wslconfig file. Create it if this file doesn’t exist yet. In the file, you need to create a [wsl2] section and memory configuration. The complete file should look like this:
[wsl2]
memory=16GB
As you can see, I’ve attached 16GB to the virtual machine. It’s assigned dynamically, according to needs, but you must be aware that the virtual machine can take all of it, so if you allow it to eat your entire RAM, it can force your Windows to use a hard disk to survive (which will slow everything down significantly).
Disclaimer:
Building Android on 8 cores, 16GB RAM machine takes around 4 hours. If you want to do it faster or you don’t have a computer powerful enough at your home or office, you can consider building in the cloud. Simple AWS EC2 with 32 cores and 64GB of memory does the job in one hour (to download and build) and costs just a few bucks.
Let's get ready to rumble!!!
..or at least to building.
More prerequisites
We need some software but not much. Just install the following packages. This set of libraries allows you to build Android Automotive OS versions 11 to 13.
sudo apt update && sudo apt install gcc-aarch64-linux-gnu libssl-dev bc python3-setuptools repo python-is-python3 libncurses5 zip unzip make gcc flex bison -y
Source code downloading
Let’s create a home directory for our android and download sources.
mkdir android-11.0.0_r48 && cd android-11.0.0_r48
repo init -u https://android.googlesource.com/platform/manifest -b android-11.0.0_r48 --partial-clone --clone-filter=blob:limit=10M
git clone https://github.com/android-rpi/local_manifests .repo/local_manifests -b arpi-11
repo sync
“repo init” will ask you for some personal data. It’s collected by Google. To learn more about optimizations here, check this manual: https://docs.gitlab.com/ee/topics/git/partial_clone.html . ‘git clone’ adds a custom code from Android RPI project ( https://groups.google.com/g/android-rpi ) with drivers for your Raspberry Pi. The project is great and it’s all you need if you want to run Android TV. To run Android Automotive OS, we’ll need to adjust it slightly (see “Adjustments” section below). ‘repo sync’ will take some time because you need to download around 200GB of code. If you have a powerful machine with a great Internet connection, you can use more threads with ‘-j X’ parameter added to the command. The default thread count is 4. If you have already synchronized your source code without android-rpi local manifest, you need to add --force-sync to the ’repo-sync’ command.
Adjustments
All changes from this section can download as a patch file attached to this article. See the “Path file” section below.
Android-rpi provides Android TV for Raspberry Pi. We need to remove the TV-related configuration and add the Automotive OS one.
Let’s start with removing unnecessary files. You can safely remove the following files and directories:
- device/arpi/rpi4/overlay/frameworks/base/core/res/res/anim
- device/arpi/rpi4/overlay/frameworks/base/core/res/res/values-television
- device/arpi/rpi4/overlay/frameworks/base/core/res/res/values/dimens.xml
- device/arpi/rpi4/overlay/frameworks/base/core/res/res/values/styles.xml
- device/arpi/rpi4/overlay/frameworks/base/packages
To remove the user notice screen not needed in Automotive OS, create a new file device/arpi/rpi4/overlay/packages/services/Car/service/res/values/config.xml with the following content:
<?xml version="1.0" encoding="utf-8"?>
<resources xmlns:xliff="urn:oasis:names:tc:xliff:document:1.2">
<string name="config_userNoticeUiService" translatable="false"></string>
</resources>
To replace the basic TV overlay config with the Automotive overlay config, adjust the configuration in device/arpi/rpi4/overlay/frameworks/base/core/res/res/values/config.xml.
Remove:
- <integer name="config_defaultUiModeType">4</integer> <!--disable forced UI_MODE_TYPE_TELEVISION, as there is only MODE_TYPE_CAR available now-->
- <integer name="config_longPressOnHomeBehavior">0</integer> <!--disable home button long press action-->
- <bool name="config_hasPermanentDpad">true</bool> <!--disable D-pad-->
- <string name="config_appsAuthorizedForSharedAccounts">;com.android.tv.settings;</string> <!--remove unnecessary access for a shared account as there is nothing in com.android.tv.* now-->
… and add:
- <bool name="config_showNavigationBar">true</bool> <!--enable software navigation bar, as there is no hardwave one-->
- <bool name="config_enableMultiUserUI">true</bool> <!--enable multi-user, as AAOS uses background processes called in another sessions -->
- <integer name="config_multiuserMaximumUsers">8</integer> <!--set maximum user count, required by the previous one-->
Now let’s rename the android-rpi original /device/arpi/rpi4/rpi4.mk to /device/arpi/rpi4/android_rpi4.mk. We need to adjust the file a little bit.
Remove the following variables definitions. Some of them you will re-create in another file, while some of them are not needed.
- PRODUCT_NAME
- PRODUCT_DEVICE
- PRODUCT_BRAND
- PRODUCT_MANUFACTURER
- PRODUCT_MODEL
- USE_OEM_TV_APP
- DEVICE_PACKAGE_OVERLAYS
- PRODUCT_AAPT_PRED_CONFIG
- PRODUCT_CHARACTERISTICS
Remove the following invocations. We’re going to call necessary external files in another mk file.
- $(call inherit-product, device/google/atv/products/atv_base.mk)
- $(call inherit-product, $(SRC_TARGET_DIR)/product/core_64_bit_only.mk)
- $(call inherit-product, $(SRC_TARGET_DIR)/product/languages_full.mk)
- include frameworks/native/build/tablet-10in-xhdpi-2048-dalvik-heap.mk
In PRODUCT_PROPERTY_OVERRIDES remove debug.drm.mode.force=1280x720 and add the following properties. This way you remove the TV launcher configuration and override the default automotive launcher configuration.
- dalvik.vm.dex2oat64.enabled=true
- keyguard.no_require_sim=true
- ro.logd.size=1m
Now you need to completely remove the android-rpi TV launcher and add RenderScript support for Automotive OS. In PRODUCT_PACKAGES remove:
- DeskClock
- RpLauncher
… and add:
- librs_jni
Create a new rpi4.mk4 with the following content:
PRODUCT_PACKAGE_OVERLAYS += device/generic/car/common/overlay
$(call inherit-product, $(SRC_TARGET_DIR)/product/core_64_bit.mk)
$(call inherit-product, device/arpi/rpi4/android_rpi4.mk)
$(call inherit-product, $(SRC_TARGET_DIR)/product/full_base.mk)
$(call inherit-product, device/generic/car/common/car.mk)
PRODUCT_SYSTEM_DEFAULT_PROPERTIES += \
android.car.number_pre_created_users=1 \
android.car.number_pre_created_guests=1 \
android.car.user_hal_enabled=true
DEVICE_PACKAGE_OVERLAYS += device/arpi/rpi4/overlay device/generic/car/car_x86_64/overlay
PRODUCT_NAME := rpi4
PRODUCT_DEVICE := rpi4
PRODUCT_BRAND := arpi
PRODUCT_MODEL := Raspberry Pi 4
PRODUCT_MANUFACTURER := GrapeUp and ARPi
Due to the license, remember to add yourself to the PRODUCT_MANUFACTURER field.
Now you have two mk files – android-rpi.mk is borrowed from android-rpi project and adjusted, and rpi.mk contains all changes for Automotive OS. You can meld these two together or split them into more files if you’d like, but keep in mind that the order of invocations does matter (not always, but still).
As Android Automotive OS is bigger than Android TV, we need to increase the system partition size to fit the new image. In device/arpi/rpi4/BoardConfig.mk increase BOARD_SYSTEMIMAGE_PARTITION_SIZE to 2147483648, which means 2GB.
You need to apply all changes described in https://github.com/android-rpi/device_arpi_rpi4/wiki/arpi-11-:-framework-patch too. Those changes are also included in the patch file attached .
If you use the 8GB version of Raspberry Pi, you need to replace device/arpi/rpi4/boot/fixup4.dat and device/arpi/rpi4/boot/start4.elf files. You can find the correct files in the patch file attached or you may use the official source: https://github.com/raspberrypi/firmware/tree/master/boot . It’s probably not needed for 4GB version of Raspberry, but I don’t have such a device for verification.
Path file
If you prefer to apply all changes described above as a single file, go to your sources directory and run ‘git apply --no-index <path_to_patch_file> ’. There is also a boot animation replaced in the patch file . If you want to create one of your own, follow the official manual here: https://android.googlesource.com/platform/frameworks/base/+/master/cmds/bootanimation/FORMAT.md .
Now we can build!
That’s the easy part. Just run a few commands from below. Firstly, we need to build a custom kernel for Android. ‘merge_config.sh’ script just configures all variables required. The first ‘make’ command builds the real kernel image (which can take a few minutes). Next, build a device tree configuration.
cd kernel/arpi
ARCH=arm64 scripts/kconfig/merge_config.sh arch/arm64/configs/bcm2711_defconfig kernel/configs/android-base.config kernel/configs/android-recommended.config
ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu- make Image.gz
ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu- DTC_FLAGS="-@" make broadcom/bcm2711-rpi-4-b.dtb
ARCH=arm64 CROSS_COMPILE=aarch64-linux-gnu- DTC_FLAGS="-@" make overlays/vc4-kms-v3d-pi4.dtbo
cd ../..
The next part is to build the entire system. “envsetup.sh” script sets up variables and adds custom commands to your terminal. Then you can pick the correct pair of Android versions and devices with “lunch”. You can run it without parameters to see (almost) all possible configurations. In this step, you can decide to build a system for dedicated hardware (eg. Dragonboard) and switch between phone/tablet/TV/wearable/automotive versions of Android. The last line is a real building. We can’t run just “make” or “m”, as documented in the official manual because we need to create three specific images to write them on an SD card and run them on Raspberry Pi. Replace “X” in ‘-j X’ with the number of threads you want to use. The default value is the number of logical processors on your computer.
source build/envsetup.sh
lunch rpi4-eng
make -j X ramdisk systemimage vendorimage
I hope you have a delightful book next to you because the last building takes a few hours depending on your hardware. Good news! If you need to adapt something and build again, in most cases you just need the three last lines (or even just the very last one) – to source the environment setup, to pick the lunch configuration, and to make ramdisk, system, and vendor images. And it takes hours for the first time only.
Creating an SD card
This step seems to be easy, but it isn’t. WSL doesn’t contain drivers for the USB card reader. You can use usbip to forward a device from Windows to the subsystem, but it doesn’t work well with external storage without partitions. The solution is a VirtualBox with Ubuntu installed. Just create a virtual machine, install Ubuntu, and install Guest Additions. Then you can connect the card reader and pass it to the virtual machine. If you’re a minimalist, you can use Ubuntu Server or any other Linux distribution you like. Be aware that using a card reader built into your computer may be challenging depending on drivers and the hardware connection type (USB-like, or PCI-e).
Now, you need to create a partition schema on the SD card. I assume the card is loaded to the system as /dev/sdb. Check your configuration before continuing to avoid formatting your main drive or another disaster. Let’s erase the current partition table and create a new one.
sudo umount /dev/sdb*
sudo wipefs -a /dev/sdb
sudo fdisk /dev/sdb
Now let’s create partitions. First, you need a 128MB active partition of the W95 FAT32 (LBA) type, second a 2GB Linux partition, third a 128MB Linux partition, and the rest of the card for user data (also Linux partition). Here’s how to navigate through fdisk menu to configure all partitions.
Welcome to fdisk (util-linux 2.37.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table.
Created a new DOS disklabel with disk identifier 0x179fb9bc.
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p):
Using default response p.
Partition number (1-4, default 1):
First sector (2048-61022207, default 2048):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-61022207, default 61022207): +128M
Created a new partition 1 of type 'Linux' and of size 128 MiB.
Command (m for help): a
Selected partition 1
The bootable flag on partition 1 is enabled now.
Command (m for help): t
Selected partition 1
Hex code or alias (type L to list all): 0c
Changed type of partition 'Linux' to 'W95 FAT32 (LBA)'.
Command (m for help): n
Partition type
p primary (1 primary, 0 extended, 3 free)
e extended (container for logical partitions)
Select (default p):
Using default response p.
Partition number (2-4, default 2):
First sector (264192-61022207, default 264192):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (264192-61022207, default 61022207): +2G
Created a new partition 2 of type 'Linux' and of size 2 GiB.
Command (m for help): n
Partition type
p primary (2 primary, 0 extended, 2 free)
e extended (container for logical partitions)
Select (default p):
Using default response p.
Partition number (3,4, default 3):
First sector (4458496-61022207, default 4458496):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (4458496-61022207, default 61022207): +128M
Created a new partition 3 of type 'Linux' and of size 128 MiB.
Command (m for help): n
Partition type
p primary (3 primary, 0 extended, 1 free)
e extended (container for logical partitions)
Select (default e): p
Selected partition 4
First sector (4720640-61022207, default 4720640):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (4720640-61022207, default 61022207):
Created a new partition 4 of type 'Linux' and of size 26,8 GiB.
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
Be careful with the last partition – fdisk proposes creating an extended one by default, which is not needed in our use case.
If you don’t do it for the first time on the same card, you may see a warning that some partition already contains a file system signature. You can safely agree to remove it.
Partition #4 contains a ext4 signature.
Do you want to remove the signature? [Y]es/[N]o: Y
The signature will be removed by a write command.
Now, let’s supply file systems for the first and the last partitions.
sudo mkdosfs -F 32 /dev/sdb1
sudo mkfs.ext4 -L userdata /dev/sdb4
We won’t write anything to the last one, as it’s for user data only and will be filled by Android during the first boot. But we need to write some files for the first one. Let’s create a temporary mount directory under /mnt/p1 (like “partition 1”), mount it, and copy the necessary files from the Android built in the earlier section. It’s strange, but we’re going to copy files from one virtual machine (WSL) to another (VirtualBox). You can simply mount a wsl drive as a shared folder in VirtualBox. If you don’t see a WSL drive in your Windows Explorer, you can map it as a network drive using “\\wsl$\Ubuntu” path
sudo mkdir /mnt/p1
sudo mount /dev/sdb1 /mnt/p1
sudo mkdir /mnt/p1/overlays
cd <PATH_TO_YOUR_ANDROID_SOURCES_IN_WSL>
sudo cp device/arpi/rpi4/boot/* /mnt/p1
sudo cp kernel/arpi/arch/arm64/boot/Image.gz /mnt/p1
sudo cp kernel/arpi/arch/arm64/boot/dts/broadcom/bcm2711-rpi-4-b.dtb /mnt/p1
sudo cp kernel/arpi/arch/arm/boot/dts/overlays/vc4-kms-v3d-pi4.dtbo /mnt/p1/overlays/
sudo cp out/target/product/rpi4/ramdisk.img /mnt/p1
sudo umount /mnt/p1
sudo rm -rf /mnt/p1
If you’re looking at the official android-rpi project manual, there is a different path for vc4-kms-v3d-pi4.dtbo file. That’s OK – they use a symbolic link we are unable to use in this filesystem.
Sometimes, you can see an error message when creating an “overlays” directory. It happens from time to time, because “mount” returns to the console before really mounting the drive. In such a case, just call “mkdir” again. Be aware of that, especially if you’re going to copy-paste the entire listing from above.
Now, let’s copy the two remaining partitions. If you’re struggling with dd command (it may hang), you can try to copy big *.img files from WSL to VirtualBox first.
cd <PATH_TO_YOUR_ANDROID_SOURCES_IN_WSL>/out/target/product/rpi4/
sudo dd if=system.img of=/dev/sdb2 bs=1M status=progress
sudo dd if=vendor.img of=/dev/sdb3 bs=1M status=progress
Congratulations!
You’re done. You’ve downloaded, prepared, built, and saved your own Android Automotive OS. Now you can put the SD card into Raspberry, and connect all cables (make sure you connect the Raspberry power cable at the end). There is no “power” button, and it doesn’t matter which micro-HDMI or USB port of Raspberry you use. It’s now time to enjoy your own Android Automotive OS!
If it doesn’t work
The world is not perfect and sometimes something goes terribly wrong. If you see the boot animation for a long time, or if your device crashes in a loop a few seconds after boot, you can try to debug it.

You need a USB-TTL bridge (like this one https://www.sunrom.com/p/cp2102-usb-ttl-uart-module ) to connect the correct pins from the Raspberry to the USB. You need to connect pin 6 (ground) to the GND pin in the bridge, pin 8 (RXD) to the RXD pin of the bridge and pin 10 (TXD) to the TXD pin of the bridge. If you want to power the Raspberry via the bridge, you need to also connect pin 2 to +5V pin of the bridge. It is not recommended, because of the lower voltage, so your system might be unstable. If you don’t have a power adapter, you can simply connect a USB cable between your computer port and the USB C port of the Raspberry. Warning! You can’t connect both a +5V connector here and a USB C power port of the Raspberry or you’ll burn the Raspberry board.
See the schema for the connection reference.
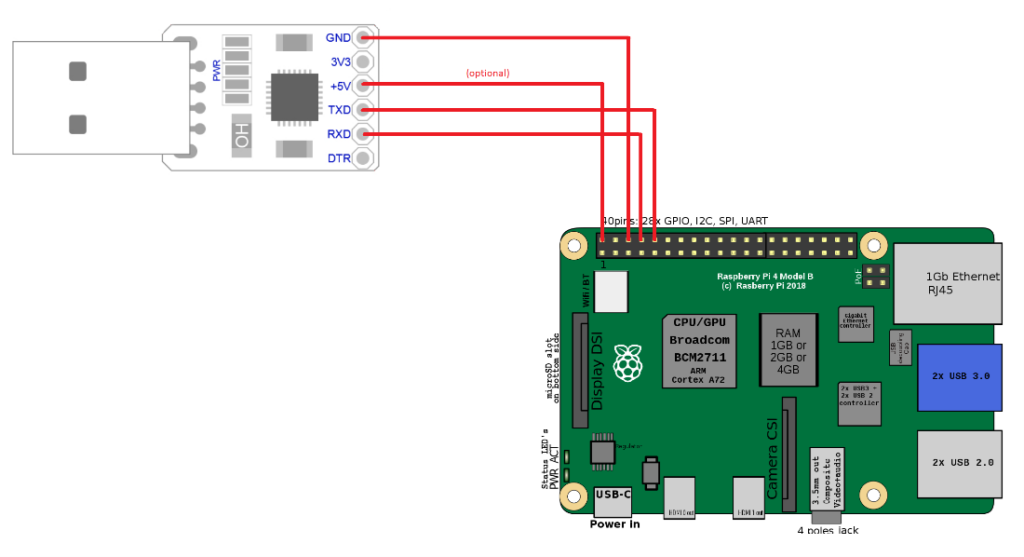
Depending on your bridge model, you may need an additional driver. I use this one: https://www.silabs.com/developers/usb-to-uart-bridge-vcp-drivers?tab=downloads .
When you connect the +5V pin or USB-C power adapter ( again, never both at the same time! ), the Raspberry starts. Now you can open Putty and connect to your Android. Pick Serial and type COMX in the serial line definition. X is the number of your COM port. You can check it in your device manager – look for “USB to UART bridge (COM4)” or the like. The correct connection speed is 115200.
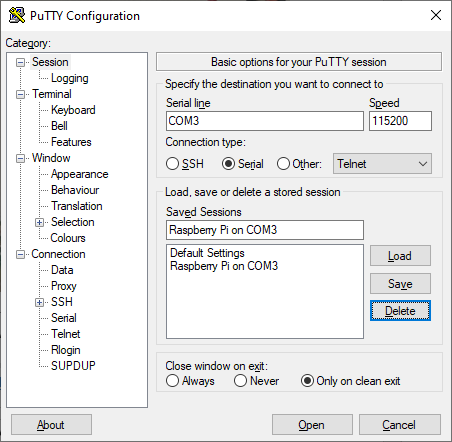
Open the connection to access the Android shell. By default, Android spawns all logs to the standard output, so you should see a lot of them right away. Anyway, it’s dual-side communication and you have full terminal access to your Android if you need to check/modify any file or call any command. Just strike enter to see the command prompt. You can even call ‘su’ to gain superuser access on your Android running on Raspberry.
Connecting via adb
If you want to use Android Debug Bridge to connect to your device, using a USB bridge is not enough. When running ‘adb devices’ on your computer, the Android Automotive OS running on Raspberry is not recognized. You can use a putty connection to turn on a TCP debug bridge instead.
Make sure you’ve connected Android and your computer to the same network. Open putty and connect to the running Android console. Log as root and enable ADB via TCP. Then check your IP address.
su
setprop service.adb.tcp.port 5555
stop adbd
start adbd
ifconfig wlan0
Now, using your Windows command line, go to the Android SDK platform-tools directory and connect to your device. As you can see, the IP address of mine Raspnberry is 192.168.50.47.
cd %userprofile%\AppData\Local\Android\Sdk\platform-tools
adb connect 192.168.50.47:5555
If you want to use ADB in WSL, you can link the Windows program in WSL using the following command.
sudo ln -s /mnt/c/Users/<your_username>/AppData/Local/Android/Sdk/platform-tools/adb.exe /usr/bin/adb
You can now use ADB to use logcat without putty or to install applications without manually transferring APK files to the SD card. Fun fact – if you use a USB bridge and USB power supply, you have two physical connections between your computer and the Android-running one, however, you still need to use ADB over WiFi to use the debug bridge.
Summary: Android Automotive OS on Raspberry Pi 4B
That’s all. Android Automotive OS 11 is running. You can install the apps you need, take them to your car, or do whatever you’d like with them. Using hardware instead of an emulator allows you to manually manage partitions (e.g. for the OTA update ) and connect external devices like a real GPS receiver or accelerometer. The bare metal hardware overperforms the emulator too. And most importantly – you can easily take it to your car, receive power from an in-car USB port, connect it to an ODB-II port and run real-life tests without a laptop.
Is your project ready? Great, now you can try doing the same with AAOS 13 .
What's next for the digital twin
Digital twins, or virtual copies of material objects, are being used in various types of simulations and the automotive industry is tapping into the potential offered by this technology. Representatives of this market can comprehensively monitor equipment and systems and prevent numerous failures. But what does the future hold for Digital Twin solutions, and who will play the leading role in their development in the years ahead?
The concept of Digital Twin today
To get started, let's have a few words of reminder. A virtual model called a digital twin is based on data from an actual physical object, equipped with special sensors. The collected information allows to the creation of a simulation of the object’s behavior in the real world, while testing takes place in virtual space.
The concept of Digital Twins is developing by leaps and bounds, with its origins dating back to 2003. For many years, more components have been added to this technology . Currently, we distinguish the following:
- digital (virtual) aspect,
- physical object,
- the connection between the two,
- data,
- services.
The last two were added to the classification by experts only in recent years. This was triggered by developments such as machine learning, Big Data , IoT, and cybersecurity technologies.
Capabilities of digital twins in automotive
Digital twins are excelling in many fields when it comes to working on high-tech cars, especially those connected to the network. Below are selected areas of influence.
Designing the vehicle
3D modeling is a way of designing that has been around for many years in the widespread automotive manufacturing industry. But this one is not standing still, and the growing popularity of digital twins is proof of that. Digital replicas extend the concept of physical 3D modeling to virtual representations of software, interactive systems, and usage simulations. As such, they take the conceptual process to a higher level of sophistication.
Production stage
Design is not everything. In fact, the technology mentioned above also works well at the production stage . First and foremost, DT's solutions facilitate control over advanced manufacturing techniques. Since virtual twins improve real-time monitoring and management of facilities, they support the construction of increasingly complex products.
Besides, the safety of the work itself during the production of cars and parts adds to the issue. By simulating manufacturing processes , digital twins contribute to the creation of appropriate employment conditions.
Advanced event prediction
Virtual copies have the ability to simulate the physical state of a vehicle and thus predict the future. Predictive maintenance in this case is based on such reliable data as temperature, route, engine condition, or driver behavior. This can be used to ensure optimal vehicle performance.
Aspects of cyber security
DT predicted for automotive software can help simulate the risk of data theft or other cybersecurity threats. The digital twin of the whole Datacenter can be created to simulate different attack vectors. Continuous software monitoring is also helpful in the early detection of vulnerabilities to hacking attacks (and more)
Development of security-improving systems
Virtual replicas of vehicles and the real world also enable the prediction of specific driving situations and potential vehicle responses. This is valuable knowledge that can be used, for example, to further develop ADAS systems such as electronic stability control and autonomous driving. This is all aimed at ensuring safer, faster, and more economical driving.
How will the digital twin trend evolve in the coming years?
One of the leading trend analysis companies from the automotive world has developed its own prediction of the development of specific sub-trends within the scope of the digital twin. In this regard, the experts analyzed such areas of development as:
- Predictive Maintenance.
- Powertrain Control (e.g. vehicle speed and other software parameters).
- Cybersecurity.
- Vehicle Manufacturing.
- Development and Testing.
The analysis shows that all of the above issues will move into the mainstream in the third decade of the 21st century. On the other hand, some of them will develop at a slower pace in the years to come, while others will develop at a slightly higher rate.
Subtrend Powertrain Control will have a lot to say. As early as around 2025, we will see that basic control parameters will be defined and tested primarily in the digital twin.
To a lesser extent, but still, Development and Testing solutions will also be implemented. DTs will be created to simulate systems in such a way as to accelerate development processes. The same will be true in the area of Predictive Maintenance. Vehicle condition information will soon be sent in bulk to the cloud or database. There, a virtual copy will be used to predict how certain changes will affect maintenance needs.
Key players in DT development in automotive
The market is already witnessing the emergence of brands that will push (with varying intensity) DT technology in the broader automotive sector (cars, software, parts). Specifically standing out in this regard are:
- Tesla,
- BOSCH,
- SIEMENS,
- Porsche,
- Volkswagen,
- Continental.
Both OEMs and Suppliers will shift their focus to the Development and Testing area. The proportions are somewhat different in the case of Vehicle Manufacturing, as this slice of the pie tends to go to OEMs for the time being. However, it is possible that parts manufacturers will also get their share before long. On the other hand, without any doubt, the area of Cybersecurity already belongs to OEMs , and the percentage of such companies that use DT to improve cybersecurity is prevalent.
The digital twin and the future of automotive brands
The digital twin is a solution that helps address mature challenges specific to the entire modern automotive industry. It supports digitization processes and data-driven decision-making. Manufacturers can apply this technology at all stages of the production process, thus eliminating potential abnormalities.
In the upcoming years, we can expect DT-type applications to become more common, especially among OEMs.
So what are brands supposed to do if they want to secure a significant position in a market where the DM trend is becoming highly relevant? First, it's a good idea if they collaborate with those driving change. Second, it' s worth adopting a specific strategy, as not every sub-trend needs to be addressed in every scenario. This is brilliantly illustrated in the SBD chart below. The authors of this chart recommend certain behaviors, breaking them down into specific categories and relating them to specific market participants.

Based on this overview, it's good to see that the leaders don't have too much choice, and over the next 12 months, they should be releasing solutions that fall into every sub-trend. The issue of cyber security is becoming essential as well . The digital twins have great potential in developing it, so basically all stakeholders should focus on this area.
gRPC Remote Procedure Call (with Protobuf)
One of the most crucial technical decisions during designing API is to choose the proper protocol for interchanging data. It is not an easy task. You have to answer at least a few important questions - which will integrate with API, if you have any network limitations, what is the amount and frequency of calls, and will the level of your organization's technological maturity allow you to maintain this in the future?
When you gather all the information, you can compare different technologies to choose one that fits you best. You can pick and choose between well-known SOAP, REST, or GraphQL. But in this article, we would like to introduce quite a new player in the microservices world - gRPC Remote Procedure Call.
What is gRPC (Remote Procedure Call)?
gRPC is a cross-platform open-source Remote Procedure Call (RPC) framework initially created by Google. The platform uses Protocol Buffers as a data serialization protocol, as the binary format requires fewer resources and messages are smaller. Also, a contract between the client and server is defined in proto format, so code can be automatically generated. The framework relies on HTTP/2 (supports TLS) and beyond performance, interoperability, and code generation offers streaming features and channels.
Declaring methods in contract
Have you read our article about serializing data with Protocol Buffers ? We are going to add some more definitions there:
message SearchRequest {
string vin = 1;
google.protobuf.Timestamp from = 2;
google.protobuf.Timestamp to = 3;
}
message SearchResponse {
repeated Geolocation geolocations = 1;
}
service GeolocationServer {
rpc Insert(Geolocation) returns (google.protobuf.Empty);
rpc Search(SearchRequest) returns (SearchResponse);
}
The structure of the file is pretty straightforward - but there are a few things worth noticing:
-
service GeolocationServer- service is declared by keyword with that name -
rpc Insert(Geolocation)- methods are defined byrpckeyword, its name, and request parameter type -
returns (google.protobuf.Empty)- and at the end finally a return type. As you can see you have to always return any value, in this case, is a wrapper for an empty structure -
message SearchResponse {repeated Geolocation geolocations = 1};- if you want to return a list of objects, you have to mark them asrepeatedand provide a name for the field
Build configuration
We can combine features of Spring Boot and simplify the setup of gRPC server by using the dedicated library GitHub - yidongnan/grpc-spring-boot-starter: Spring Boot starter module for gRPC framework. (follow the installation guide there) .
It let us use all the goodness of the Spring framework (such as Dependency Injection or Annotations).
Now you are ready to generate Java code! ./gradlew generateProto
Server implementation
To implement the server for our methods definition, first of all, we have to extend the proper abstract class, which had been generated in the previous step:
public class GeolocationServer extends GeolocationServerGrpc.GeolocationServerImplBase
As the next step add the @GrpcService annotation at the class level to register gRPC server and override server methods:
@Override
public void insert(Geolocation request, StreamObserver<Empty> responseObserver) {
GeolocationEvent geolocationEvent = convertToGeolocationEvent(request);
geolocationRepository.save(geolocationEvent);
responseObserver.onNext(Empty.newBuilder().build());
responseObserver.onCompleted();
}
@Override
public void search(SearchRequest request, StreamObserver<SearchResponse> responseObserver) {
List<GeolocationEvent> geolocationEvents = geolocationRepository.searchByVinAndOccurredOnFromTo(
request.getVin(),
convertTimestampToInstant(request.getFrom()),
convertTimestampToInstant(request.getTo())
);
List<Geolocation> geolocations = geolocationEvents.stream().map(this::convertToGeolocation).toList();
responseObserver.onNext(SearchResponse.newBuilder()
.addAllGeolocations(geolocations)
.build()
);
responseObserver.onCompleted();
}
-
StreamObserver<> responseObserver- stream of messages to send -
responseObserver.onNext()- writes responses to the client. Unary calls must invoke onNext at most once -
responseObserver.onCompleted()- receives a notification of successful stream completion
We have to convert internal gRPC objects to our domain entities:
private GeolocationEvent convertToGeolocationEvent(Geolocation request) {
Instant occurredOn = convertTimestampToInstant(request.getOccurredOn());
return new GeolocationEvent(
request.getVin(),
occurredOn,
request.getSpeed().getValue(),
new Coordinates(request.getCoordinates().getLatitude(), request.getCoordinates().getLongitude())
);
}
private Instant convertTimestampToInstant(Timestamp timestamp) {
return Instant.ofEpochSecond(timestamp.getSeconds(), timestamp.getNanos());
}
Error handling
Neither client always sends us a valid message nor our system is resilient enough to handle all errors, so we have to provide ways to handle exceptions.
If an error occurs, gRPC returns one of its error status codes instead, with an optional description.
We can handle it with ease in a Spring’s way, using annotations already available in the library:
@GrpcAdvice
public class GrpcExceptionAdvice {
@GrpcExceptionHandler
public Status handleInvalidArgument(IllegalArgumentException e) {
return Status.INVALID_ARGUMENT.withDescription(e.getMessage()).withCause(e);
}
}
-
@GrpcAdvice- marks the class as a container for specific exception handlers -
@GrpcExceptionHandler- method to be invoked when an exception specified as an argument is thrown
Now we ensured that our error messages are clear and meaningful for clients.
gRPC - is that the right option for you?
As demonstrated in this article, gRPC integrates well with Spring Boot, so if you’re familiar with it, the learning curve is smooth.
gRPC is a worthy option to consider when you’re working with low latency, highly scalable, distributed systems. It provides an accurate, efficient, and language-independent protocol.
Check out the official documentation for more knowledge! gRPC

How automotive open source technologies accelerate software development in the automotive industry
The driving properties or the external appearance of cars, which used to serve as a differentiator between manufacturers, no longer play a key marketing role today. It is the car's software that has become the new growth engine for the automotive industry. Yet, the question remains where this software should come from and whether it pays to use a free-access license. Here we compare the most popular automotive open-source solutions.
What exactly is Open Source Software in the automotive industry?
Most of the software developed by the major automotive companies is copyrighted to other players in the market. Does this mean that being a less well-resourced player, it is impossible to thrive in the SDV sector? Not necessarily, and one of the solutions may be to take advantage of open-source software (OSS).
A characteristic of such access is that the source code is freely available to programmers under certain licensing conditions.
Flexible customization to meet your needs
It is important to know that OSS does not necessarily entail that a given vehicle manufacturer is "doomed" to certain functionalities. After all, the operating system, even if based on publicly available code, can then be developed manually.
The programmer is therefore authorized to benefit from free libraries, and cut and paste individual values into the code at will, modifying the content of the whole .
OSS is gaining ground
According to Flexera's research, more than 50% of all code written globally today runs on open source. That's a large percentage, which reflects the popularity of free software.
The OSS trend has also gained importance in the automotive industry in recent years, with OEMs trying with all their might to keep up with technological advances and new consumer demands. According to the same study, between 50% and 70% of the automotive software stack today comes from open source.
In contrast, Black Duck software audits of commercial applications demonstrate that open-source components are predicted to account for 23% of automotive applications.
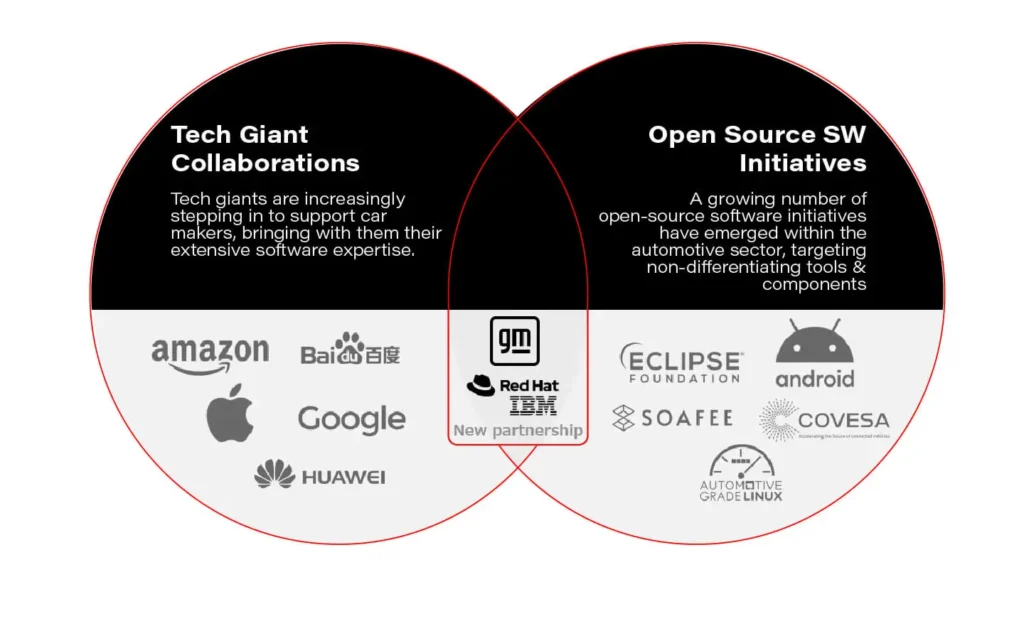
Automotive Open-Source Software implies a number of benefits. But can we already talk about a revolution?
Why is the mentioned solution so popular nowadays? In fact, there are several reasons.
- Allows minimizing costly investments (budget saved can be used as a way of developing other solutions).
- Enables vehicle manufacturers to offer consumers a fresh and compelling digital experience .
- Contributes to faster business growth due to reduced expenses and "tailor-made" software development teams.
- Provides benefits to consumers by making cars safer with more reliable data.
- It is used to maximize product agility cost-effectively.
Clearly, these arguments are quite strong. Yet, to be able to talk about a revolution and a complete transition to OSS in the automotive industry, it will still take some more time. After all, at present, this is applied mainly to selected vehicle functions, such as entertainment.
Nevertheless, some companies are already embracing free licensing, seeing it as a new business model. The potential is certainly substantial, although not yet fully harnessed. For instance, it is said to be very difficult to meet all the requirements of SDV, including those related to digital security issues, as we write later in the article.
Examples of open-source solutions in the auto industry
Automotive Grande Linux
The Linux operating system is a prime example of the power of an open-source solution. The base of this tech giant ranks among the top operating systems worldwide, especially when talking about automotive.
The Automotive Grade Linux (AGL) project is particularly noteworthy here, as it brings together manufacturers, suppliers, and representatives of technology companies. AGL platform, with Linux at its core, develops an open software platform from the ground up that can serve as the de facto industry standard, enabling the rapid development of the connected car market. Automotive companies, including Toyota, already leverage Linux open-source for automotive.
As of today, AGL (hosted by the Linux Foundation, the world's) is the only organization that seeks to fully aggregate all the functionalities of modern vehicles into Open-Source software. This includes such areas as:
- Infotainment System – UCB 8.0 currently available, SDK available.
- Instrument Cluster – device profile available with UCB 6.0 (Funky Flounder).
- Telematics – device profile available with UCB 6.0 (Funky Flounder).
- Heads-up Display (HUD).
- Advanced Driver Assistance Systems (ADAS).
- Functional Safety.
- Autonomous Driving.
The founders of the project assume that in the current reality it is becoming obvious that the amount of code needed to support autonomous driving is too large for any one company to develop it independently. That's why they are the first in the world aiming to create a coherent OSS ecosystem for the automotive industry.
Red Hat In-Vehicle Operating System
A competitive approach is being adopted by Red Hat, which has also mushroomed into a group of free software innovators in connected cars. Their proprietary solution, Red Hat In-Vehicle Operating System, is designed to help automakers integrate software-defined vehicle technology into their production line faster than ever.
General Motors and Qualcomm Technologies Inc. have already declared their interest in such an approach.
Part of the mission of the above-mentioned company is to develop certified functional safety systems built on Linux with functional safety certification (ASIL-B) to support critical in-vehicle applications. IVOS from Red Hat is currently (Fall 2022) being tested on the Snapdragon® Digital Chassis™ . This is a set of cloud-connected platforms for telematics and connectivity, digital cockpit, and advanced driver assistance systems. This collaboration is intended to provide:
- faster implementation of new digital services and innovative new features connected to the cloud,
- new opportunities for more in-depth customer engagement,
- the ability to update services over the vehicle's lifetime via the cloud,
- the option of gaining expanded capabilities to perform simple and efficient vehicle updates and maintain functional safety,
- the ability to redefine the driving experience for customers by ensuring seamless connectivity and enhanced intelligence.
Android Automotive OS
Great opportunities are also offered by the software based on a system featuring a distinctive green robot in its logo.
Android Automotive OS (AAOS), as its name is known, is earning increasing recognition across the globe. This is no coincidence, as it allows car companies to provide customers with the most tailor-made experience. Polestar and Volvo were among the first to introduce Android Automotive OS to their Polestar 2 and XC40 Recharge, andrecently Renault has done this with Megane E-Tech.
Other brands have followed suit. Manufacturers such as PSA, Ford, Honda, and GM have already declared their intention to incorporate AAOS into the vehicles they develop.
Part of the implementations come with Google Automotive Services (GAS): Play Store, Google Maps, Google Assistant, and other parts without, their own app stores, and assistants.
Here are selected capabilities of the above-mentioned software:
- AAOS being an integral part of the car brings ideas about controlling features of a car, or at least reading them and reacting within an application accordingly. Emulation provides just a few options to simulate car state, ignition, speed, gear, parking brake, low fuel level, night mode, and environment sensors(temperature, pressure, etc.).
- There is still a requirement to follow design patterns for automotive, and Google is providing a whole design system page.
- Applications submitted to the store are mandatory for an additional review.
- Right now, the documentation states that supported categories for Android Automotive OS apps are focused on in-vehicle infotainment systems: Media, Navigation, Point of Interest, and Video.
Regrettably, though Android has a lot of potential, it still has limitations in terms of functionality and capabilities. Hence, it cannot be described as an ideal solution at this point. We wrote more about these issues and possible solutions to AAOS .
Meanwhile, if you are interested in automotive implementation using Android read this guide.
COVESA / Genivi
The embedded Android Automotive system in vehicles requires proper integration with existing software and with other systems found in the car (for safety, car data, etc.). The Android Automotive SIG project, led by GENIVI, was created with large-scale rollouts in mind.
The premise of the AASIG Android Development Platform is that OEMs, their suppliers, and the broader cockpit software ecosystem can easily and successfully identify both the shortcomings and requirements. This is intended to be done in close collaboration with Google's Android Automotive team.
Among the issues addressed are the following:
- safety,
- access to vehicle information,
- responsibility for long-term maintenance,
- multi-display operation,
- audio management,
- extensions for Android in the automotive environment,
- keeping the in-vehicle system updated to support new Android versions,
- outlining the boundaries within which Tier 1/OEM suppliers must take over major responsibility for supporting Google's Android Automotive team.
As can be seen, in the case of Android, there are a number of hot spots that need to be properly dealt with.
What limitations do you need to be aware of?
Ensuring a high level of security in safety-critical automotive environments has always posed a major challenge for Open-Source Software. This is because you have to reconcile customer expectations while also ensuring data protection.
Certainly, open-source software has more vulnerabilities than dedicated software and thus is more susceptible to hacker attacks. Even a single exploit can be used to compromise hundreds of thousands of applications and websites. Obviously, static and dynamic application security testing (SAST and DAST) can be implemented to identify coding errors. However, such testers do not perform particularly well in identifying vulnerabilities in third-party code.
So if you plan to use connected car technology , you need to examine the ecosystem of software used to deliver these functions. It is also critical to properly manage open-source software in your overall security strategy.
OSS opportunities and challenges
All told, until some time ago, OSS was mainly focused on entertainment. Besides, OEMs have historically been forced to choose between only a few software stacks and technologies. But today they are faced with a rapidly growing number of OSS proposals, APIs, and other solutions.
On top of that, they have a growing number of partners and tech companies to collaborate with. And initiatives such as Autoware and Apollo shift their focus toward applications relevant to the safety and comfort of autonomous vehicles. Of course, these opportunities are also coupled with challenges, such as those related to security or license compliance . On the other hand, this still does not negate the enormous potential of open-source software.
It can be hypothesized that in the long term, a complete transition to SDV will require manufacturers to make optimal use of open-source software. And this will include an increasing range of vehicle functionality. This is an obvious consequence of the rapidly changing automotive market (which in a way forces the search for agile solutions) and growing consumer and infrastructure demands.
Sooner or later, major OEMs and the automotive community will have to face a decision and choose: either proprietary comfort (such as CARIAD from Volkswagen) or the flexibility offered by OSS projects.
Protobuf: How to serialize data effectively with protocol buffers
In a world of microservices, we often have to pass information between applications. We serialize data into a format that can be retrieved by both sides. One of the serialization solutions is Protocol Buffers (Protobuf) - Google's language-neutral mechanism. Messages can be interpreted by a receiver using the same or different language than a producer. Many languages are supported, such as Java, Go, Python, and C++.
A data structure is defined using neutral language through .proto files. The file is then compiled into code to be used in applications. It is designed for performance. Protocol Buffers encode data into binary format, which reduces message size and improves transmission speed.
Defining message format
This .proto the file represents geolocation information for a given vehicle.
1 syntax = "proto3";
2
3 package com.grapeup.geolocation;
4
5 import "google/type/latlng.proto";
6 import "google/protobuf/timestamp.proto";
7
8 message Geolocation {
9 string vin = 1;
10 google.protobuf.Timestamp occurredOn = 2;
11 int32 speed = 3;
12 google.type.LatLng coordinates = 4;
13}
1 syntax = "proto3";
Syntax refers to Protobuf version, it can be proto2 or proto3 .
1package com.grapeup.geolocation;
Package declaration prevents naming conflicts between different projects.
1 message Geolocation {
2 string vin = 1;
3 google.protobuf.Timestamp occurredOn = 2;
4 int32 speed = 3;
5 google.type.LatLng coordinates = 4;
6}
Message definition contains a name and a set of typed fields. Simple data types are available, such as bool, int32, double, string, etc. You can also define your own types or import them.
1google.protobuf.Timestamp occurredOn = 2;
The = 1 , = 2 markers identify the unique tag. Tags are a numeric representation for the field and are used to identify the field in the message binary format. They have to be unique in a message and should not be changed once the message is in use. If a field is removed from a definition that is already used, it must be reserved .
Field types
Aside from scalar types, there are many other type options when defining messages. Here are few, but you can find all of them in the Language Guide Language Guide (proto3) | Protocol Buffers | Google Developers .
Well Known Types
1 import "google/type/latlng.proto";
2 import "google/protobuf/timestamp.proto";
3
4 google.protobuf.Timestamp occurredOn = 2;
5 google.type.LatLng coordinates = 4;
There are predefined types available to use Overview | Protocol Buffers | Google Developers . They are known as Well Know Types and have to be imported into .proto .
LatLng represents a latitude and longitude pair.
Timestamp is a specific point in time with nanosecond precision.
Custom types
1 message SingularSearchResponse {
2 Geolocation geolocation = 1;
3}
You can use your custom-defined type as a field in another message definition.
Lists
1 message SearchResponse {
2 repeated Geolocation geolocations = 1;
3}
You can define lists by using repeated keyword.
OneOf
It can happen that in a message there will always be only one field set. In this case, TelemetryUpdate will contain either geolocation, mileage, or fuel level information.
This can be achieved by using oneof . Setting value to one of the fields will clear all other fields defined in oneof .
1 message TelemetryUpdate {
2 string vin = 1;
3 oneof update {
4 Geolocation geolocation = 2;
5 Mileage mileage =3;
6 FuelLevel fuelLevel = 4;
7 }
8}
9
10 message Geolocation {
11 ...
12}
13
14 message Mileage {
15 ...
16}
17
18 message FuelLevel {
19 ...
20}
Keep in mind backward-compatibility when removing fields. If you receive a message with oneof that has been removed from .proto definition, it will not set any of the values. This behavior is the same as not setting any value in the first place.
You can perform different actions based on which value is set using the getUpdateCase() method.
1 public Optional<Object> getTelemetry(TelemetryUpdate telemetryUpdate) {
2 Optional<Object> telemetry = Optional.empty();
3 switch (telemetryUpdate.getUpdateCase()) {
4 case MILEAGE -> telemetry = Optional.of(telemetryUpdate.getMileage());
5 case FUELLEVEL -> telemetry = Optional.of(telemetryUpdate.getFuelLevel());
6 case GEOLOCATION -> telemetry = Optional.of(telemetryUpdate.getGeolocation());
7 case UPDATE_NOT_SET -> telemetry = Optional.empty();
8 }
9 return telemetry;
10 }
Default values
In proto3 format fields will always have a value. Thanks to this proto3 can have a smaller size because fields with default values are omitted from payload. However this causes one issue - for scalar message fields, there is no way of telling if a field was explicitly set to the default value or not set at all.
In our example, speed is an optional field - some modules in a car might send speed data , and some might not. If we do not set speed, then the geolocation object will have speed with the default value set to 0. This is not the same as not having speed set on messages.
In order to deal with default values you can use official wrapper types protobuf/wrappers.proto at main · protocolbuffers/protobuf . They allow distinguishing between absence and default. Instead of having a simple type, we use Int32Value, which is a wrapper for the int32 scalar type.
1 import "google/protobuf/wrappers.proto";
2
3 message Geolocation {
4 google.protobuf.Int32Value speed = 3;
5}
If we do not provide speed, it will be set to nil .
Configure with Gradle
Once you’ve defined your messages, you can use protoc , a protocol buffer compiler, to generate classes in a chosen language. The generated class can then be used to build and retrieve messages.
In order to compile into Java code, we need to add dependency and plugin in build.gradle
1 plugins {
2 id 'com.google.protobuf' version '0.8.18'
3}
4
5 dependencies {
6 implementation 'com.google.protobuf:protobuf-java-util:3.17.2'
7}
and setup the compiler. For Mac users an osx specific version has to be used.
1 protobuf {
2 protoc {
3 if (osdetector.os == "osx") {
4 artifact = "com.google.protobuf:protoc:${protobuf_version}:osx-x86_64"
5 } else {
6 artifact = "com.google.protobuf:protoc:${protobuf_version}"
7 }
8 }
9}
Code will be generated using generateProto task.
The code will be located in build/generated/source/proto/main/java in a package as specified in .proto file.
We also need to tell gradle where the generated code is located
1 sourceSets {
2 main {
3 java {
4 srcDirs 'build/generated/source/proto/main/grpc'
5 srcDirs 'build/generated/source/proto/main/java'
6 }
7 }
8}
The generated class contains all the necessary methods for building the message as well as retrieving field values.
1 Geolocation geolocation = Geolocation.newBuilder()
2 .setCoordinates(LatLng.newBuilder().setLatitude(1.2).setLongitude(1.2).build())
3 .setVin("1G2NF12FX2C129610")
4 .setOccurredOn(Timestamp.newBuilder().setSeconds(12349023).build())
5 .build();
6
7 LatLng coordinates = geolocation.getCoordinates();
8 String vin = geolocation.getVin();
Protocol Buffers - summary
As shown protocol buffers are easily configured. The mechanism is language agnostic, and it’s easy to share the same .proto definition across different microservices.
Protobuf is easily paired with gRPC, where methods can be defined in .proto files and generated with gradle.
There is official documentation available Protocol Buffers | Google Developers and guides Language Guide (proto3) | Protocol Buffers | Google Developers .
