
Adam Kozłowski is a Solution Architect and Head of Automotive R&D at Grape Up. He had worked as a C/C++ and JavaScript Developer before he started his journey to the Cloud and Machine Learning world. Adam is an active advocate of Kubernetes and open-source cloud-native solutions. He is a huge fan of RnD initiatives, rapid prototyping, MLOps, and building great software products enhanced by ML algorithms. Throughout his career, Adam has been working with established enterprises like Rijkswaterstaat, Porsche, or Allstate to build their mission-critical systems. Currently responsible for consulting automotive projects, specializing in Cloud and MLOps solutions for the automotive industry.
Read articles
Challenges of EU Data Act in Home Appliance business
As we enter 2026, the EU Data Act (Regulation (EU) 2023/2854), which is now in force across the entire European Union, is mandatory for all "connected" home appliance manufacturers. It has been applicable since 12 September 2025.
Compared to other industries, like automotive or agriculture, the situation is far more complicated. The implementation of connected services varies between manufacturers, and lack of connectivity is not often considered an important factor, especially for lower-segment devices.
The core approaches to connectivity in home appliances are:
- Devices connected to a Wi-Fi network and constantly sharing data with the cloud.
- Devices that can be connected via Bluetooth and a mobile app (these devices technically expose a local API that should be accessible to the owner).
- Devices with no connectivity available to the customer (no mobile app), but still collecting data for diagnostic and repair purposes, accessible through an undocumented service interface.
- Devices with no data collection at all (not even diagnostic data).
Apart from the last bullet point, all of the mentioned approaches to building smart home appliances require EU Data Act compliance, and such devices are considered "connected products", even without actual internet connectivity.
The rule of thumb is: if there is data collected by the home appliance or a mobile app associated with its functions, it falls under the EU Data Act.
Short overview of the EU Data Act
To make the discussion more concrete, it helps to name the key roles and the types of data upfront. Under EU Data Act, the user is the person or entity entitled to access and share the data; the data holder is typically the manufacturer and/or provider of the related service (mobile app, cloud platform); and a data recipient is the third party selected by the user to receive the data. In home appliances, “data” usually means both product data (device signals, status, events) and related-service data (app/cloud configuration, diagnostics, alerts, usage history, metadata), and access often needs to cover both historical and near-real-time datasets.
Another important dimension is balancing data access with trade secrets, security, and abuse prevention. Home appliances are not read-only devices. Many can be controlled remotely, and exposing interfaces too broadly can create safety and cybersecurity risks, so strong authentication and fine-grained authorization are essential. On top of that, direct access must be robust: rate limiting, anti-scraping protections, and audit logs help prevent misuse. Direct access should be self-service, but not unrestricted.
Current market situation
As of January 2026, most home appliance manufacturers (over 85% of the 40 manufacturers researched, responsible for 165 home appliance brands currently present on the European market) either provide data access through a manual process (ticket, contact form, email, chatbot) or do not recognize the need to share data with the owner at all.
If we look at the market from the perspective of how manufacturers treat the requirements the EU Data Act imposes on them, we can see that only 12.5% of the 40 companies researched (which means 5 manufacturers) provide full data access with a portal allowing users to easily access their data in a self-service manner (green on the chart below). 55% of the companies researched (yellow on the diagram below) recognize the need to share data with their customers, but only as a manual service request or email, not in an automated or direct way.
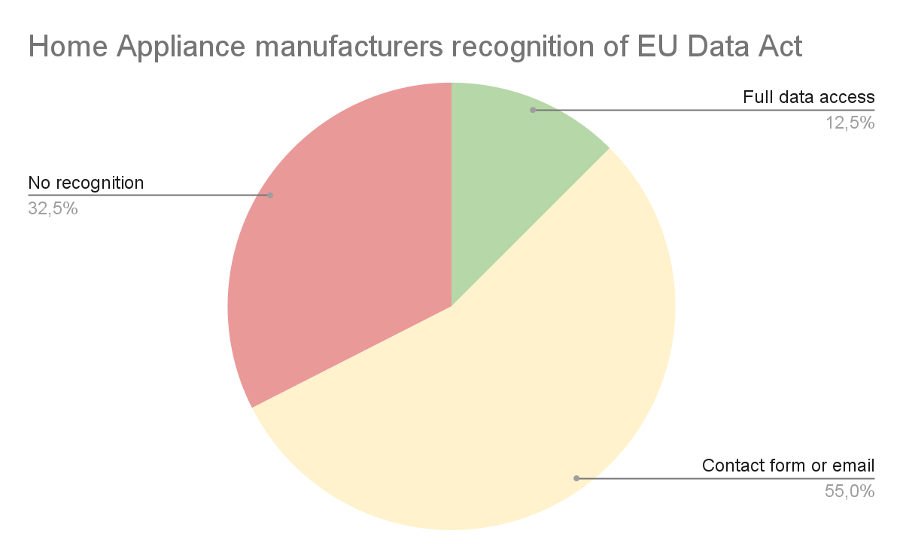
The red group (32.5%) consists of manufacturers who, according to our research:
- do not provide an easy way to access your data,
- do not recognize EU Data Act legislation at all,
- recognize the EDA, but their interpretation is that they don’t need to share data with device owners.
A contact form or email can be treated as a temporary solution, but it fails to fulfill the additional requirements regarding direct data access. Although direct access can be understood differently and fulfilled in various ways, a manual request requiring manufacturer permission and interaction is generally not considered "direct". (Notably, "access by design" expectations intensify for products placed on the market from September 2026.)
API access
We can't talk about EU Data Act implementation without understanding the current technical landscape. For the home appliance industry, especially high-end devices, the competitive edge is smart features and smart home integration support. That's why many manufacturers already have cloud API access to their devices.
Major manufacturers, like Samsung, LG, and Bosch, allow users to access appliance data (such as electric ovens, air conditioning systems, humidifiers, or dishwashers) and control their functions. This API is then used by mobile apps (which are related services in terms of the EU Data Act) or by owners integrating with popular smart home systems.
There are two approaches: either the device itself provides a local API through a server running on it (very rare), or the API is provided in the manufacturer's cloud (most common), making access easier from the outside world, securely through their authentication mechanism, but requiring data storage in the cloud.
Both approaches, in light of the EDA, can be treated as direct access. The access does not require specific permission from the manufacturer, anyone can configure it, and if all functions and data are available, this might be considered a compliant solution.
Is API access enough?
The unfortunate part is that it rarely is, and for more than one reason. Let's go through all of them to understand why Samsung, which has a great SmartThings ecosystem, still developed a separate EU Data Act portal for data access.
1. The APIs do not make all data accessible
The APIs are mostly developed for smart home and integration purposes, not with the goal of sharing all the data collected by the appliance or by the related service (mobile app).
Adding endpoints for every single data point, especially for metadata, will be costly and not really useful for either customers or the manufacturer. It's easier and better to provide all supplementary data as a single package.
2. The APIs were developed with the device owner in mind
The EU Data Act streamlines data access for all data market participants - not only device owners, but also other businesses in B2B scenarios. Sharing data with other business entities under fair, reasonable, and non-discriminatory terms is the core of the EDA.
This means that there must be a way to share data with the company selected by the device owner in a simple and secure way. This effectively means that the sharing must be coordinated by the manufacturer, or at least the device should be designed in a way that allows for secure data sharing, which in most cases requires a separate B2B account or API.
3. The APIs lack consent management capabilities
B2B data access scenarios require a carefully designed consent management system to make sure the owner has full control regarding the scope of data sharing, the way it's shared, and with whom. The owner can also revoke data sharing permission at any time.
This functionality falls under the scope of a partner portal, not a smart home API. Some global manufacturers already have partner portals that can be used for this purpose, but an API alone is not enough.
If an API is not enough - what is?
The EU Data Act challenge is not really about expanding the API with new endpoints. The recommended approach, as taken by the previously mentioned Samsung, is to create a separate portal solving compliance problems. Let's also briefly look at potential solutions for direct access to data:
- Self-service export - download package, machine-readable + human-readable, as long as the export is fast, automatic, and allows users to access the data without undue delay.
- Delegated access to a third party - OAuth-style authorization, scoped consent, logs.
- Continuous data feed - webhook/stream for authorized recipients.
These are the approaches OEMs currently take to solve the problem.
Other challenges specific to the home appliance market
Home appliance connectivity is different from the automotive market. Because devices are bound to Wi-Fi or Bluetooth networks, or in rare cases smart home protocols (ZigBee, Z-Wave, Matter), they do not move or change owners that often.
Device ownership change happens only when the whole residence changes owners, which is either the specific situation of businesses like Airbnb, or current owners moving out - which very often means the Wi-Fi and/or ISP (Internet Service Provider) is changed anyway.
On the other hand, it is hard to point to the specific "device owner". If there is more than one resident - effectively any scenario outside of a single-person household - there is no way to effectively separate the data applicable to specific individuals. Of course, every reasonable system would include a checkbox or notification stating that data can only be requested when there is a legal basis under the GDPR, but selecting the correct user or admin to authorize data sharing is challenging.
From a business perspective, a challenge also arises from the fact that there are white-label OEMs manufacturing for global brands in specific market segments. A good example here is the TV market - to access system data, there can be a Google/Android access point, while diagnostic data is separate and should be provided by the manufacturer (which may or may not be the brand selling the device). If you purchase a TV branded by Toshiba, Sharp, or Hitachi, it can all be manufactured by Vestel. At the same time, other home appliances with the same brand can be manufactured elsewhere. Gathering all the data and helping users understand where their data is can be tricky, to say the least.
Another important challenge is the broad spectrum of devices with different functions and collecting different signals. This requires complex data catalogs, potentially integrating different data sources and different data formats. Users often purchase multiple different devices from the same brand and request access to all data at once. The user shouldn't have to guess whether the brand, OEM, or platform provider holds specific datasets - the compliance experience must reconcile identities and data sources to make it easy to use.
Conclusion
Navigating the EU Data Act is complicated, no matter which industry we focus on. When we were researching the home appliance market, we saw very different approaches—from a state-of-the-art system created by Samsung, compliant with all EDA requirements, to manufacturers who explain in the user manual that to "access the data" you need to open system settings and reset the device to factory settings, effectively removing the data instead of sharing it. The market as a whole is clearly not ready.
Making your company compliant with the EU Data Act is not that difficult. The overall idea and approach is similar regardless of the industry you represent, but building or procuring a new system to fulfill all requirements is a must for most manufacturers.
For manufacturers seeking a faster path to compliance, Grape Up designed and developed Databoostr, the EU Data Act compliance platform that can be either installed on customer infrastructure or integrated as a SaaS system. This is the quickest and most cost-effective way to become compliant, especially considering the shrinking timeline, while also enabling data monetization.
Is rise of data and AI regulations a challenge or an opportunity?
Right To Repair and EU Data Act as a step towards data monetization.
Legislators try to shape the future
In recent years the automotive market has witnessed a growing amount of laws and regulations protecting customers across various markets. At the forefront of such legislation is the European Union, where the most significant disruption for modern software-defined vehicles come from the EU Data Act and EU AI Act. The legislation aims to control the use of AI and to make sure that the equipment/vehicle owner is also the owner of the data generated by using the device. The vehicle owner can decide to share the data with any 3rd party he wants, effectively opening the data market for repair shops, custom applications, usage-based insurance or fleet management.
Across the Atlantic, in the United States, there is a strong movement called “Right to Repair”, which effectively tries to open the market of 3rd party repair of all customer devices and appliances. This also includes access to the data generated by the vehicle. While the federal legislation is not there, there are two states that that stand out in terms of their approach to Right to Repair in the automotive industry – Massachusetts and Maine.
Both states have a very different approach, with Maine leaning towards an independent entity and platform for sharing information (which as of now does not exist) and Massachusets towards OEMs creating their own platforms. With numerous active litigations, including lawsuits OEMs vs State, it’s hard to judge what will be the final enforceable version of the legislation.
The current situation
Both pieces of legislation impose a penalty when it’s not fulfilled – severe in the case of EDA (while not final, the fines are expected to be substantial, potentially reaching up to €20 million or 4% of total worldwide annual turnover!), and slightly lower for state Right to Repair (for civil law suits it may be around $1000 per VIN per day, or in Massachusets $10.000 per violation).
The approach taken by the OEMs to tackle this fact varies greatly. In the EU most of the OEMs either reused existing software or build/procured new systems to fulfill the new regulation. In the USA, because of the smaller impact, there are two approaches: Subaru and Kia in 2022 decided to just disable their connected services (Starlink and Kia Connect respectively) in states with strict legislation. Others decided to either take part in litigation, or just ignore the law and wait. Lately federal judges decided in favor of the state, making the situation of OEMs even harder.
Data is a crucial asset in today’s world
Digital services, telematics, and in general data are extremely important assets. This has been true for years in e-commerce, where we have seen years of tracking, cookies and other means to identify customers behavior. The same applies to telemetry data from the vehicle. Telemetry data is used to repair vehicles, to design better features and services offering for existing and new models, identify market trends, support upselling, lay out and optimize charging network, train AI models, and more. The list never ends.
Data is collected everywhere. And in a lot of cases stored everywhere. The sales department has its own CRM, telemetry data is stored in a data lake, the mobile app has its own database. Data is siloed and dispersed, making it difficult to locate and use effectively.
Data platform importance
To solve the problem with both mentioned legislations you need a data sharing platform. The platform is required to manage the data owner consent, enable collection of data in single place and sharing with either data owner, or 3rd party. While allowing to be compliant with upcoming legislation, it also helps with identifying the location of different data points, describing it and making available in single place – allowing to have a better use of existing datasets.
A data platform like Grape Up Databoostr helps you quickly become compliant, while our experienced team can help you find, analyze, prepare and integrate various data sources into the systems, and at the same time navigate the legal and business requirements of the system.
Cost of becoming compliant
Building a data streaming platform comes at the cost. Although not terribly expensive, platform requires investment which does not immediately seem useful from a business perspective. Let’s then now explore the possibilities of recouping the investment.
- You can use the same data sharing platform to sell the data, even reusing the mechanism used to get user consent for sharing the data. For B2B use cases, the mechanism is not required.
- Legislation mainly mandates to share data “as is”, which means raw, unprocessed data. Any derived data, like predictive maintenance calculation from AI algorithms, proprietary incident detection systems, or any data that is processed by OEM. This allows not just to put a price tag on data point, but also to charge more due to additional work required to build analytics models.
- You can share the anonymized datasets, which then can be used to train AI models, identify EVs charging patterns, or plan marketing campaigns.
- And lastly, EU Data Act allows to charge fair amount for sharing the data, to recoup the cost of building and maintaining the platform. The allowed price depends on the requestor, where enterprises can be charged with a margin, and the data owner should be able to get data for free.
We can see that there are numerous ways to recoup the cost of building the platform. This is especially important as the platform might be required to fulfill certain regulations, and procuring the system is required, not optional.
The power of scale in data monetization
As we now know, building a data streaming platform is more of a necessity, than an option, but there is a way to change the problem into an opportunity. Let’s see if the opportunity is worth the struggle.
We can begin with dividing the data into two types – raw and derived. And let’s put a price tag on both to make the calculation easier. To further make our case easier to calculate and visualize, I went to high-mobility and checked current pricing for various brands, and took the average of lower prices.
The raw data in our example will be $3 per VIN per month, and derived data will be $5 per VIN per month. In reality the prices can be higher and associated with selected data package (the data from powertrain will be different from chassis data).
Now let’s assume we start the first year with a very small fleet, like the one purchased for sales representatives by two or three enterprises – 30k of vehicles. Next year we will add a leasing company which will increase the number to 80k of vehicles, and in 5 years we will have 200k VINs/month with subscription.

Of course, this represents just a conservative projection, which assumes rather small usage of the system and slow growth, and exclusive subscription to VIN (in reality the same VIN data can be shared to an insurance company, leasing company, and rental company).
This is constant additional revenue stream, which can be created along the way of fulfilling the data privacy and sharing regulations.
Factors influencing the value
$3 per VIN per month may initially appear modest. Of course with the effect of scale we have seen before, it becomes significant, but what are the factors which influence the price tag you can put on your data?
- Data quality and veracity – the better quality of data you have, the less data engineering is required on the customer side to integrate it into their systems.
- Data availability (real-time versus historical datasets) – in most cases real-time data will be more valuable – especially when the location of the vehicle is important.
- Data variety – more variety of data can be a factor influencing the value, but more importantly is to have the core data (like location and lock state). Missing core data will reduce the value greatly.
- Legality and ethics – the data can only be made available with the owner consent. That’s why consent management systems like the ones required by EDA are important.
What is required
To monetize the data you need a platform, like Grape Up’s Databoostr. This platform should be integrated into various data sources in the company, making sure that data is streamed in a close to real-time way. This aspect is important, as quite a lot of modern use cases (like Fleet Management System) requires data to be fresh.
Next step is to create pricing strategy and identify customers, who are willing to pay for the data. It is a good start to ask the business development department if there are customers who already asked for data access, or even required to have this feature before they invest in bigger fleet.
The final step would be to identify the opportunities to further increase revenue, by adding additional data points for which customers are willing to pay extra.
Summary
Ultimately, data is no longer a byproduct of connected vehicles – it is a strategic asset. By adopting platforms like Grape Up’s Databoostr, OEMs can not only meet regulatory requirements but also position themselves to capitalize on the growing market for automotive data. With the right strategy, what begins as a compliance necessity can evolve into a long-term competitive advantage.
Yet another look at cloud-native apps architecture
Cloud is getting extremely popular and ubiquitous. It’s everywhere. Imagine, the famous “everywhere” meme with Buzz and Woody from Toy Story in which Buzz shows Woody an abundance of...whatever the caption says. It’s the same with the cloud.
The original concepts of what exactly cloud is, how it should or could be used and adopted, has changed over time. Monolithic applications were found to be difficult to maintain and scale in the modern environments. Figuring out the correct solutions has turned into an urgent problem and blocked the development of the new approach.
Once t he cloud platform like Pivotal Cloud Foundry or Kubernetes is deployed and properly maintained , developers, managers and leaders step in. They start looking for best practices and guidelines for how cloud applications should actually be developed and how these apps should operate. Is it too little too late? No, not really.
If cloud platforms were live creatures, we could compare them to physical infrastructure. Why? Because they both don't really care if developers deploy a huge monolith or well-balanced microservices. You can really do anything you want, but before you know it, will be clearly visible that the original design does not scale very well. It may fail very often and is virtually impossible to configure and deploy it on different environments without making specific changes to the platform or extremely complex and volatile configuration scripts.
Does a universal architecture exist?
The problem with the not-really-defined cloud architecture led to the creation of the idea of the “application architecture” which performs well in the cloud. It should not be limited to the specific platform or infrastructure, but a set of universal rules that help developers bootstrap their applications. The answer to that problem was constituted in Heroku, one of the first commonly used PaaS platforms.
It’s a concept of twelve-factor applications which is still applicable nowadays, but also endlessly extended as the environment of cloud platforms and architectures mutate. That concept was extended in a book by Kevin Hoffman, titled "Beyond Twelve-Factor App" to the number of 15 factors. Despite the fact that the list is not the one and only solution to the problem, it has been successfully applied by a great deal of companies. The order of factors is not important, but in this article, I have tried to preserve the order from the original webpage to make the navigation easier. Shall we?
I. Codebase
There is one codebase per application which is tracked in revision control (GIT, SVN - doesn’t matter which one). However, a shared code between applications does not mean that the code should be duplicated - it can be yet another codebase which will be provided to the application as a component, or even better, as a versioned dependency. The same codebase may be deployed to multiple different environments and has to produce the same release. The idea of one application is tightly coupled with the single responsibility pattern. A single repository should not contain multiple applications or multiple entry points - it has to be a single responsibility, a single execution point code that consists of a single microservice.
II. Dependencies
Dependency management and isolation consist of two problems that should be solved. Firstly, it is very important to explicitly declare the dependencies to avoid a situation in which there is an API change in the dependency which renders the library useless from the point of the existing code and fails the build or release process.
The next thing are repeatable deployments. In an ideal world all dependencies should be isolated and bundled with the release artifact of the application. It is not always entirely achievable, but should be done and it should be possible too. In some platforms such as Pivotal Cloud Foundry this is being managed by buildpack which clearly isolates the application from, for example, the server that runs it.
III. Config
This guideline is about storing configuration in the environment. To be explicit, it also applies to the credentials which should also be securely stored in the environment using, for example, solutions like CredHub or Vault. Please mind that at no time the credentials or configuration can be a part of the source code! The configuration can be passed to the container via environment variables or by files mounted as a volume. It is recommended to think about your application as if it was open source. If you feel confident to push all the code to a publicly accessible repository, you have probably already separated the configuration and credentials from the code. An even better way to provide the configuration will be to use a configuration server such as Consul or Spring Cloud Config.
IV. Backing services
Treat backing services like attached resources. The bound services are for example databases, storage but also configuration, credentials, caches or queues. When the specific service or resource is bound, it can be easily attached, detached or replaced if required. This adds flexibility to using external services and, as a result, it may allow you to easily switch to the different service provider.
V. Build, release, run
All parts of the deployment process should be strictly separated. First, the artifact is created in the build process. Build artifact should be immutable. This means the artifact can be deployed to any environment as the configuration is separated and applied in the release process. The release artifact is unique per environment as opposed to the build artifact which is unique for all environments. This means that there is one build artifact for the dev, test and prod environments, but three release artifacts (each for each environment) with specific configuration included. Then the release artifact is being run in the cloud. Kevin adds to this list yet another discrete part of the process - the design which happens before the build process and includes (but is not limited) to selecting dependencies for the component or the user story.
VI. Stateless processes
Execute the application as one or more stateless processes. One of the self-explanatory factors, but somehow also the one that creates a lot of confusion among developers. How can my service be stateless if I need to preserve user data, identities or sessions? In fact, all of this stateful data should be saved to the backing services like databases or file systems (for example Amazon S3, Azure Blob Storage or managed by services like Ceph). The filesystem provided by the container to the service is ephemeral and should be treated as volatile. One of the easy ways to maintain microservices is to always deploy two load balanced copies. This way you can easily spot an inconsistency in responses if the response depends on locally cached or stateful data.
VII. Port binding
Expose your services via the port binding and avoid specifying ports in the container. Port selection should be left for the container runtime to be assigned on the runtime. This is not necessarily required on platforms such as Kubernetes. Nevertheless, ports should not be micromanaged by the developers, but automatically assigned by the underlying platform, which largely reduces the risk of having a port conflict. Ports should not be managed by other services, but automatically bound by the platform to all services that communicate with each other.
VIII. Concurrency
Services should scale out via the process model as opposed to vertical scaling. When the application load reaches its limits, it should manually or automatically scale horizontally. This means creating more replicas of the same stateless service.
IX. Disposability
Application should start and stop rapidly to avoid problems like having an application which does not respond to healthchecks. Why? Because it starts (which may even result in the infinite loop of restarts) or cancels the request when the deployment is scaled down.
X. Development, test and production environments parity
Keeping all environments the same, or at least very similar, may be a complex task. The difficulties vary from VMs and licenses costs to the complexity of deployment. The second problem may be avoided by properly configured and managed underlying platform. The advantages of the approach is to avoid the "works for me" problem which gets really serious when happens on production which is automatically deployed and the tests passed on all environments except production because totally different database engine was used.
XI. Logs
Logs should be treated as event streams and entirely independent of the application. The only responsibility of the application is to output the logs to the stdout and stderr streams. Everything else should be handled by the platform. That means passing the logs to centralized or decentralized store like ELK, Kafka or Splunk.
XII. Admin processes
The administrative and management processes should be run as "one-off". This actually self-explanatory and can be achieved by creating Concourse pipelines for the processes or by writing Azure Function/AWS Lambdas for that purpose. This list concludes all factors provided by Heroku team. Additional factors added to the list in "Beyond Twelve-Factor App" are:
XIII. Telemetry
Applications can be deployed into multiple instances which means it is not viable anymore to connect and debug the application to find out if it works or what is wrong. The application performance should be automatically monitored, and it has to be possible to check the application health using automatic health checks. Also, for specific business domains telemetry is useful and should be included to monitor the current and past state of the application and all resources.
XIV. Authentication and authorization
Authentication, authorization, or the general aspect of security, should be the important part of the application design and development, but also configuration and management of the platform. RBAC or ABAC should be used on each endpoint of the application to make sure the user is authorized to make that specific request to that specific endpoint.
XV. API First
API should be designed and discussed before the implementation. It enables rapid prototyping, allows to use mock servers and moves team focus to the way services integrate. As product is consumed by the clients the services are consumed by different services using the public APIs - so the collaboration between the provider and the consumer is necessary to create the great and useful product. Even the excellent code can be useless when hidden behind poorly written and badly documented interface. For more details about the tools and the concept visit API Blueprint website.
Is that all?
This is very extensive list and in my opinion from technical perspective this is just enough to navigate the cloud native world. On the other hand there is one more point that I would like to add which is not exactly technical, but still extremely important when thinking about creating successful product.
XVI. Agile company and project processes
The way to succeed in the rapidly changing and evolving cloud world is not only to create great code and beautiful, stateless services. The key is to adapt to changes and market need to create the product that is appreciated by the business. The best fit for that is to adopt the agile or lean process, extreme programming, pair programming . This allows the rapid growth in short development cycles which also means quick market response. When the team members think that their each commit is a candidate to production release and work in pairs the quality of the product improves. The trick is to apply the processes as widely as possible, because very often, as in Conway's law, the organization of your system is only as good as organizational structure of your company.
Summary of cloud-native apps
That’s the end of our journey through to the perfect Cloud-Native apps. Of course this is not the best solution to every problem. In the real world we don’t really have handy silver bullets. We must work with what we’ve got, but there is always room for improvement. Next time when you design your, hopefully, cloud-native apps, bear these guidelines in mind.