Machine Learning at the Edge – Federated Learning in the Automotive Industry



Machine Learning combined with edge computing gains a lot of interest in industries leveraging AI at scale – healthcare, automotive, or insurance. The proliferation of use cases such as autonomous driving or augmented reality, requiring low latency, real-time response to operating correctly, made distributed data processing a tempting solution. Computation offloading to edge IoT devices makes the distributed cloud systems smaller – and in this case, smaller is cheaper. That’s the first most obvious benefit of moving machine learning from the cloud to edge devices.
Why is this article worth reading? See what we provide here:
- Explaining why regular ML training flow might not be enough.
- Presenting the idea behind federated learning.
- Describing the advantages and risks associated with this technology.
- Introducing technical architecture of a similar solution.
How can federated learning be used in the automotive industry?
Using the automotive industry as an example, modern cars already contain the edge device with processors capable of making complex computations. All ADAS (Advanced Driver Assistance Systems) and autonomous driving calculations happen on-board and require rather significant compute power. Detecting obstacles, road lanes, other vehicles, or road signs happens right now using onboard vehicle systems. That’s why collaboration with companies like Nvidia becomes crucial for OEMs, as the need for better onboard SoCs does not stop.
Even though the prediction happens in the vehicle, the model is trained and prepared using regular, complex, and costly training systems built on-premises or in the cloud. The training data grows bigger and bigger making the training process computationally expensive, slower, and requiring significant storage, especially if incremental learning is not used. The updated model may take time to be passed to the vehicle, and storing the user driving patterns, or even images from the onboard camera, requires both user consent and adherence to local law regulations.
The possible solution for that problem is using a local dataset from each vehicle as small, distributed training sets and training the model in the form of “federated learning”, where the local model is trained using smaller data batches and then aggregated into a singular global model. This is both more computational and memory efficient.
What are the benefits of federated learning?
One of the important concepts highly associated with machine learning at edge is building Federated Learning on top of edge ML. The combination of federated learning and edge computing gives important, measurable advantages:
- Reduced training time – edge devices calculate simultaneously which improves velocity compared to a monolithic system.
- Reduced inference time – compared to the cloud, at the edge inference results are calculated immediately.
- Collaborative learning – instead of single, huge training dataset learning happens simultaneously using smaller datasets – which makes it both easier and more accurate enabling bigger training sets.
- Always up-to-date model in vehicle – the new model is propagated to the vehicle after validation which makes the learning process of the network automatic.
- Exceptional privacy – the omnipresent problem of secure channels for passing sensitive user data, anonymization, and storing personal user data for training purposes is now gone. The learning happens on local data in the edge device, and the data never leaves the vehicle. The weights which are being shared cannot be used to identify the user or even his driving patterns.
- Lack of single point of failure – the data loss of the training set is not a threat.
Benefits from these concepts contain both cost savings and accuracy improved, visible as an overall better user experience when using the vehicle systems. As autonomous driving and ADAS systems are critical, better model accuracy is also directly associated with better security. For example, if the system can identify pedestrians on the road in front of vehicles with accuracy higher by 10%, it can mean that an additional 10% of collisions with pedestrians can be avoided. That is a measurable and important difference.
Of course, the solution does not come only with benefits. There are certain risks that have to be taken into account when deciding to transition to federated learning. The main one is that compared to the regular training mechanisms, federated learning is based on heterogeneous training data – disconnected datasets stored on edge devices. This means the global model accuracy is hard to control, as the global model is derived based on local models and changes dynamically.
This can be solved by building a hybrid solution, where part of the model is built using safe, predefined data, and it is gradually enhanced by federated learning. This brings both worlds closer together – amounts of data impossible to handle by a singular training system and stable model based on a verified training set.
Architectural overview
To build this kind of system, we need to start with the overall architecture. Key assumptions are that the infrastructure is capable of running distributed, microservices-based systems and has queueing and load balancing capabilities. Edge devices have some kind of storage, sensors, and SoC with CPU, and GPU capable of training the ML model.
Let’s split it into multiple subsystems and consider them one by one:
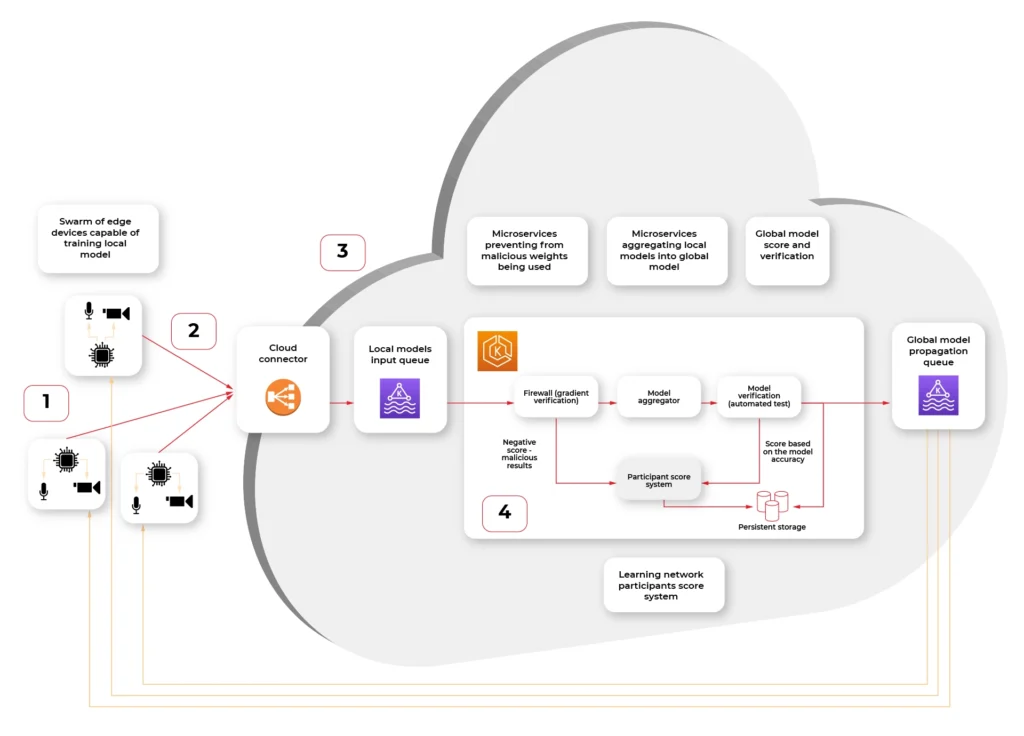
- Swarm of connected vehicle edge devices, each one with connected sensors and ability to recalculate model gradient (weights.)
- Connection medium, in this case fast, 5G network available in the car
- Cloud connector, being a secure, globally available public API where each of the vehicle IoT edge devices connect to.
- Kubernetes cluster with federated learning system split into multiple scalable microservices:
a) Gradient verification / Firewall – system rejecting the gradient that looks counterfeit – either manipulated by 3rd party or being based on fictional data.
b) Model aggregator – system merging the new weights into the existing model and creating an updated model.
c) Result verification automated test system – system verifying the new model on a predefined dataset with known predictions to score the model compared to the original.
d) Propagating queue connected to (S)OTA – automatic or triggered by user propagation of updated model in the form of an over-the-air update to the vehicle.
A firewall?
The firewall here, inside the system, is not a mistake. It is not guarding the network against attacks. It is guarding the model against being altered by cyber attacks.
Security is a very important aspect of AI, especially when the model can be altered by unverified data from the outside. There are multiple known attack vectors:
- Byzantine attack – regarding the situation, when some of the edge devices are compromised and uploading wrong weights. In our case, it is unlikely for the attacker to be omniscient (to know the data of all participants), so the uploaded weights are either randomized but plausible, like generated Gaussian noise, or flip-bit of result calculation. The goal is to make the model unpredictable.
- Model Poisoning – this attack is similar to the byzantine attack, but the goal is to inject the malicious model, which as a result alters the global model to misclassify objects. The dangerous example of such an attack is by injecting multiple fake vehicles into a model, which incorrectly identifies the trees as “stop” road signs. As a result, an autonomous car would not be able to operate correctly and stop near all trees as it would be a cross-section.
- Data Poisoning – this attack is the hardest to avoid and easiest to execute, as it does not require a vehicle to be compromised. The sensor, for example, camera, is fed with a fake picture, which contains minor, but present changes – for example, a set of bright green pixels, like on the picture:

This can be a printed picture or even a sticker on a regular road sign. If the network learns to treat those four pixels as a “stop” sign. This can be painted, for example, on another vehicle and cause havoc on the road when an autonomous car encounters this pattern.
As we can see, those attacks are specific to distributed learning systems or machine learning in general. Taking this into account is critical, as the malicious model may be impossible to identify by looking at the weights or even prediction results if the way of attack was not determined.
There are multiple countermeasures that can be used to mitigate those attacks. Median or distance to the global model can be calculated and quickly identify rogue data. The other defense is to check the score of the global model after merging and revert the change if the score is significantly worse.
In both cases, the notification about the situation should be notified, both to operators as a metric and to a service that gives scores to the vehicle edge devices. If the device gets repeatedly flagged as wrong-doing, it should be kicked out of the network, and investigation is required to figure out if this is a cyberattack and who is the attacker.
Model aggregation and test
As we know, taking care of the cybersecurity threats specific to our use case, now the important step is merging the new weights with the global model.
There is no one best function or algorithm that can be used to aggregate the local models into global models by merging the individual results (weights). In general, very often average, or weighted average gives sufficient results to start with.
The Aggregation step is not final. The versioned model is then tested in the next step using the predefined data with automated verification. This is a crucial part of the system, preventing the most obvious faults – like the lane assist system stopping to recognize roadside lines.
If the model passes the test with a score at least as good as the current model (or predefined value), it’s being saved.
Over-the-air propagation
The last step of the pipeline is enqueueing the updated model to be propagated back to vehicles. This can be either an automatic process as in continuous deployment directly to the car or may require a manual trigger if the system requires additional manual tests on the road.
A safe way of distributing the update is using the container image. The same image may be used for tests and then run in vehicles greatly reducing the chance of deploying failing updates. With this process, rollback is also simple as long as the device is able to store the previous version of the model.
The results
Moving from legacy, monolithic training method to federated learning gives promising results in both reduced overall system cost and improved accuracy. With quick expansion of 5G low-latency network and IoT edge devices into vehicles, this kind of system can move from theoretical discussions, scientific labs, and proofs of concepts to fully capable and robust production systems. The key part of building such a system is to consider the cybersecurity threats and crucial metrics like global model accuracy from the start.

Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles