Introduction to Building Intelligent Document Processing Systems

Building Intelligent Document Processing systems for financial institutions is challenging. In this article, we share our approach to developing an IDP solution that goes far beyond a simple NLP task.
The series about Intelligent Document Processing (IDP) consists of 3 parts:
- Problem definition and data
- Classification and validation
- Entities finders
Building Intelligent Document Processing systems – problem introduction
The selected domain that could be improved with AI was mortgage filings. These filings are required for mortgages to be serviced or transferred and are jurisdiction-specific. When a loan is serviced, many forms are filed with jurisdictions, banks, servicing companies, etc. These forms must be filed promptly, correctly, and accurately. Many of these forms are actual paper as only a relatively small number of jurisdictions allow for e-sign.
The number of types of documents is immense. For example, we are looking at MSR Transfers, lien release, lien perfection, servicing transfer, lien enforcement, lien placement, foreclosure, forbearance, short sell, etc. All of these procedures have more than one form and require specific timeframes for not only filing but also follow-up. Most jurisdictions are extremely specific on the documents and their layout. Ranging from margins to where the seals are placed to a font to sizing to wording. It can change between geographically close jurisdictions.
What may be surprising, these documents, usually paper, are sent to the centers to be sorted and scanned. The documents are visually inspected by a human. They decide not only further processing of the documents but sometimes need to extract or tag some knowledge at the stage of routing. This process seems incredibly laborious considering the fact that a large organization can process up to tens of thousands of documents per day!
AI technology, as its understanding and trust grows, naturally finds a place in similar applications, automating subsequent tasks, one by one. There are many places waiting for technological advancement, and here are some ideas on how it can be done.
Overview
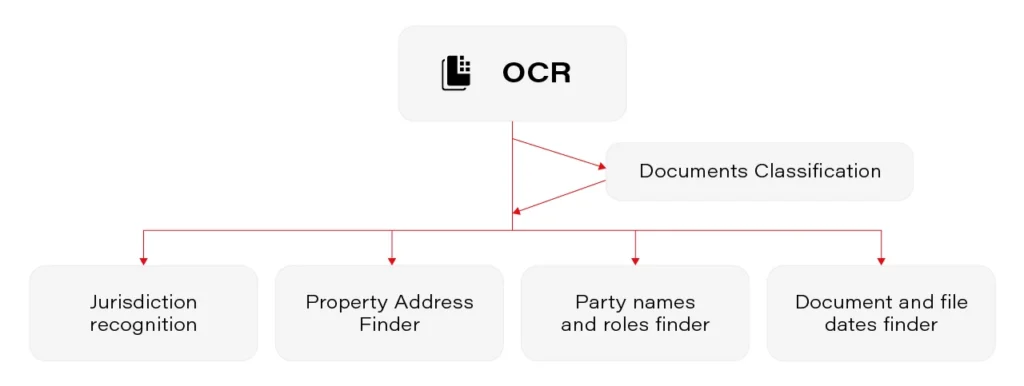
There are a few crucial components in the prepared solution
- OCR
- Documents classification
- Jurisdiction recognition
- Property addresses
- Party names and roles
- Document and file date
Each of them has some specific aspects that have to be handled, but all of them (except OCR) fall into one of 2 classical Natural Language Processing tasks: classification and Named Entity Recognition (NER).
OCR
There are a lot of OCRs that can transcribe the text from a document. Contrary to what we know after working on VIN Recognition System, the available OCRs are probably designed and are doing well on random documents of various kinds.
On the other hand, having some possibilities – Microsoft Computer Vision, AWS Textract, Google Cloud Vision, open-source Tesseract, naming a few, how to choose the best one? Determining the solution that fits best in our needs is a tough decision on its own. It requires well-structured experiments.
- We needed to prepare test sets to benchmark overall accuracy
- We needed to analyze the performance on handwriting
The results showed huge differences between the services, both in terms of accuracy on regular and hand-written text.
The best services we found were Microsoft Computer Vision, AWS Textract, and Google Cloud Vision. On 3 sets, they achieved the following results:
| AWS Textract | Microsoft CV | Google CV | |
| Set 1 | 66.4 | 95.8 | 93.1 |
| Set 2 | 87.2 | 96.5 | 91.8 |
| Set 3 | 78.0 | 92.6 | 93.8 |
Hand-written text works on its own terms. As often in the real world, any tool has weaknesses, and the performance on printed text is somehow opposite to the performance on the hand-written text. In summary, OCRs have different characteristics in terms of output information, recognition time, detection, and recognition accuracy. There are at best 8% errors, but some services work as badly as recognizing 25% of words wrongly.
After selecting OCR, we had to generate data for classifiers. Recognizing tons of documents is a time-consuming process (the project team spent an extra month on the character recognition itself.) After that step, we could collect the first statistics and describe the data.
Data diversity
We collected over 80000 documents. The average file had 4.3 pages. Some of them longer than 10 pages, with a record holder of 96 pages.
Take a look at the following documents – Document A and Document B. They are both of the same type – Bill of Sale!

- Half of document A is hand-written, while the other has only signatures
- There is just a brief detail about the selling process on Doc A, whereas on the other there are a lot of details about the truck inspection
- The sold vehicle in document B is described in the table
- Only the day in the document date of document B is hand-written
- There is a barcode on the Doc A
- The B document has 300% more words than the A
Also, we find a visual impression of these documents much different.
How can the documents be so different? The types of documents are extremely numerous and varied, but also are constantly being changed and added by the various jurisdictions. Sometimes they are sent together with the attachments, so we have to distinguish the attachment from the original document.
There are more than 3000 jurisdictions in the USA. Only a few administrative jurisdictions share mortgage fillings. Fortunately, we could focus on present-day documents, but it happens that some of the documents have to be processed that are more than 30 years old.
Some documents were well structured: each interesting value was annotated with a key, everything in tables. It happened, however, that a document was entirely hand-written. You can see some documents in the figures. Take a note that some information on the first is just a work marked with a circle!


Next Steps
The obtained documents were just the fundamentals for the next research. Such a rich collection enabled us to take the next steps, even though the variety of documents was slightly frightening. Did we manage to use the gathered documents for a working system?
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles