Building Intelligent Document Processing Systems – Classification and Validation

We continue our journey towards building Intelligent Document Processing Systems. In this article, we focus on document classification and validation.
This is the second part of the series about Intelligent Document Processing (IDP). The series consists of 3 parts:
- Problem definition and data
- Classification and validation
- Entities finders
If you are interested in data preparation, read the previous article. We describe there what we have done to get the data transformed into the form.
Classes
The detailed classification of document types shows that documents fall into around 80 types. Not every type is well-represented, and some of them have a minor impact or neglectable specifics that would force us to treat them as a distinct class.
After understanding the specifics, we ended up with 20 classes of documents. Some classes are more general, such as Assignment, some are as specific as Bankruptcy. The types we classify are: Assignment, Bill, Deed, Deed Of Separation, Deed Of Subordination, Deed Of Trust, Foreclosure, Deed In Lieu Foreclosure, Lien, Mortgage, Trustees Deed, Bankruptcy, Correction Deed, Lease, Modification, Quit Claim Deed, Release, Renunciation, Termination.
We chose these document types after summarizing the information present in each type. When the following services and routing are the same for similar documents, we do not distinguish them in target classes. We abandoned a few other types that do not occur in the real world often.
Classification
Our objective was to classify them for the correct next routing and for the application of the consecutive services. For example, when we are looking for party names, dealing with the Bankruptcy type of document, we are not looking for more than one legal entity.
The documents are long and various. We can now start to think about the mathematical representation of them. Neural networks can be viewed as a complex encoders with classifier on top. These encoders are usually, in fact, powerful systems that can comprehend a lot of content and dependencies in text. However, the longer the text, the harder for a network to focus on a single word or single paragraph. There was a lot of research that confirms our intuition, which shows that the responsibility of classification of long documents on huge encoders is on the final layer and embeddings could be random to give similar results.
Recent GPT-3 (2020) is obviously magnificent, and who knows, maybe such encoders have the future for long texts. Even if it comes with a huge cost – computational power, processing time. Because we do not have a good opinion on representing long paragraphs of text in a low dimensional embedding made up by a neural network, we made ourselves a favor leaning towards simpler methods.
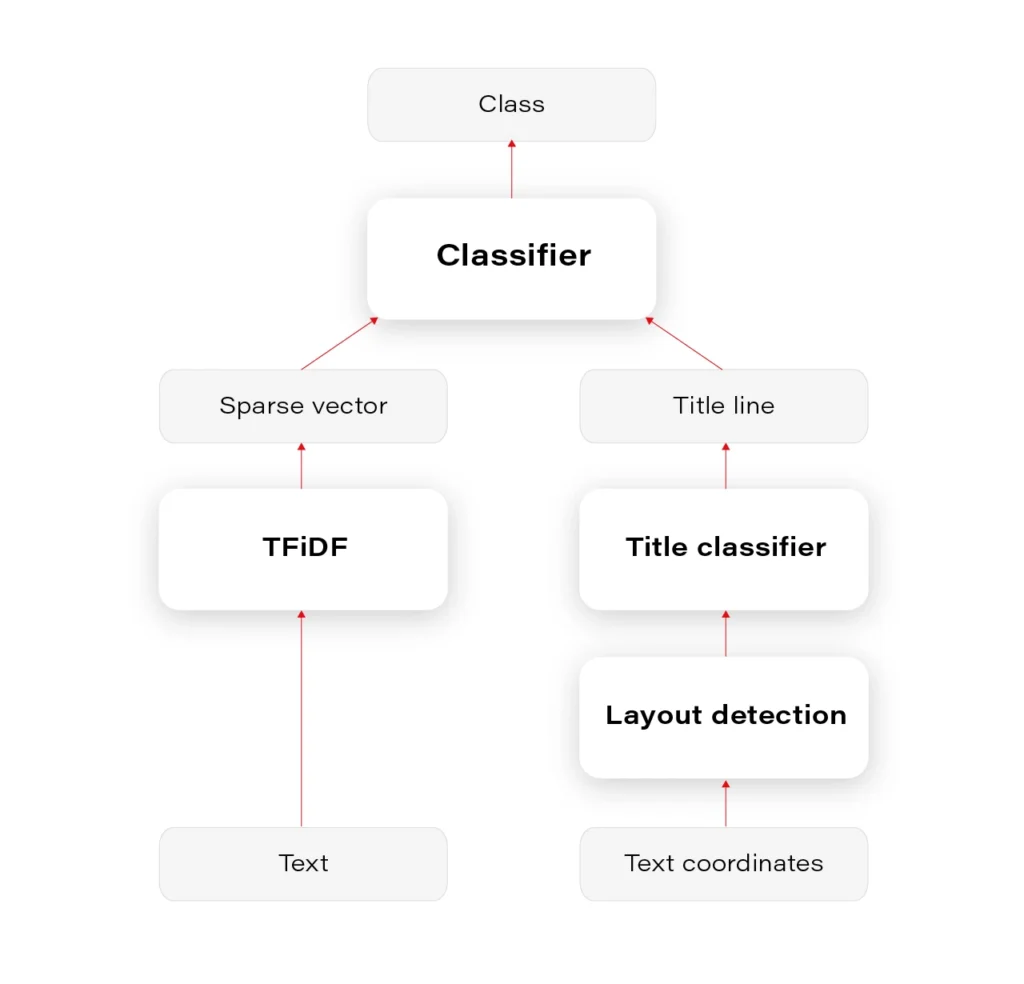
We had to prepare a multiclass-multilabel classifier that doesn’t smooth the probability distribution in any way on the layer of output classes, to be able to interpret and tune classes’ thresholds correctly. This is often a necessary operation to unsmooth the output probability distribution. Our main classifier was Logistic Regression on TFiDF (Term Frequency – Inverse Document Frequency). We tuned mainly TFiDF but spent some time on documents themselves – number of pages, stopwords, etc.
Our results were satisfying. In our experiments, we are above 95% accuracy, which we find quite good, considering ambiguity in the documents and some label noise.
It is, however, natural to estimate whether it wouldn’t be enough to classify the documents based on the heading – document title, the first paragraph, or something like this. Whether it’s useful for a classifier to emphasize the title phrase or it’s enough to classify only based on titles – it can be settled after the title detection.
Layout detection
Document Layout Analysis is the next topic we decided to apply in our solution.
First of all, again, the variety of layouts in our documents is tremendous. The available models are not useful for our tasks.
The simple yet effective method we developed is based on the DBSCAN algorithm. We derived a specialized custom distance function to calculate the distances between words and lines in a way that blocks in the layout are usefully separated. The custom distance function is based on Euclidean distance but smartly uses the fact that text is recognized by OCR in lines. The function is dynamic in terms of proportion between the width and height of a line.
You can see the results in Figure 1. We can later use this layout information for many purposes.
Based on the content, we can decide whether any block in a given layout contains the title. For document classification based on title, it seems that predicting document class based only on the detected title would be as good as based on the document content. The only problem occurs when there are no document titles, which unfortunately happens often.
Overall, mixing layout information with the text content is definitely a way to go, because layout seems to be an integral part of a document, fulfilling not only the cosmetic needs but also storing substantive information. Imagine you are reading these documents as plain text in notepad – some signs, dates, addresses, are impossible to distinguish without localizations and correctly interpreted order of text lines.
The entire pipeline of classification is visualized in Figure 2.
Validation
We incorporated the Metaflow python package for this project. It is a complicated technology that does not always work fluently but overall we think it gave us useful horizontal scalability (some time-consuming processes) and facilitated the cooperation between team members.
The interesting example of Metaflow usage is as follows: at some time, we had to assure that the number of jurisdictions that we had in our trainset is enough for the model to generalize over all jurisdictions.
Are we sure the mortgage from some small jurisdiction in Alaska will work even though most of our documents come from, let’s say, West Side?
The solution to that was to prepare the “leave-one-out” cross-validation in a way that we hold documents from one jurisdiction as a validation set. Having a lot of jurisdictions, we had to choose N of them. Each fold was tested on a remote machine independently and in parallel, which was largely facilitated thanks to Metaflow. Check the Figure 3.

Next
Classification is a crucial component of our system and allows us to take further steps. Having solid fundamentals, after the classifier routing, we can run the next services – the finders.
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles

