Transition Towards Data-driven Organization in the Insurance Industry: Comparison of Data Streaming Platforms


Insurance has always been an industry that relied heavily on data. But these days, it is even more so than in the past. The constant increase of data sources like wearables, cars, home sensors, and the amount of data they generate presents a new challenge. The struggle is in connecting to all that data, processing and understanding it to make data-driven decisions.
And the scale is tremendous. Last year the total amount of data created and consumed in the world was 59 zettabytes, which is the equivalent of 59 trillion gigabytes. The predictions are that by 2025 the amount will reach 175 zettabytes.
On the other hand, we’ve got customers who want to consume insurance products similarly to how they consume services from e-tailers like Amazon.
The key to meeting the customer expectations lies in the ability to process the data in near real-time and streamline operations to ensure that customers get the products they need when they want them. And this is where the data streaming platforms come to help.
Traditional data landscape
In the traditional landscape businesses often struggled with siloed data or data that was in various incompatible formats. Some of the commonly used solutions that should be mentioned here are:
- Big Data systems like Cassandra that let users store a very large amount of data.
- Document databases such as Elasticsearch that provide a rich interactive query model.
- And relational databases like Oracle and PostgreSQL
That means there were databases with good query mechanisms, Big Data systems capable of handling huge volumes of data, and messaging systems for near-real-time message processing.
But there was no single solution that could handle it all, so the need for a new type of solution became apparent. One that would be capable of processing massive volumes of data in real-time, processing the data from a specific time window while being able to scale out and handle ordered messages.
Data streaming platforms- pros & cons and when should they be used
Data streaming is a continuous stream of data that can be processed, stored, analyzed, and acted upon as it’s generated in real-time. Data streams are generated by all types of sources, in various formats and volumes.
But what benefits does deploying data streaming platforms bring exactly?
- First of all, they can process the data in real-time.
- Data in the stream is an ordered, replayable, and fault-tolerant sequence of immutable records.
- In comparison to regular databases, scaling does not require complex synchronization of data access.
- Because the producers and consumers are loosely coupled with each other and act independently, it’s easy to add new consumers or scale down.
- Resiliency because of the replayability of stream and the decoupling of consumers and producers.
But there are also some downsides:
- Tools like Kafka (specifically event streaming platforms) lack features like message prioritization which means data can’t be processed in a different order based on its importance.
- Error handling is not easy and it’s necessary to prepare a strategy for it. Examples of those strategies are fail fast, ignore the message, or send to dead letter queue.
- Retry logic doesn’t come out of the box.
- Schema policy is necessary. Despite being loosely coupled, producers and consumers are still coupled by schema contract. Without this policy in place, it’s really difficult to maintain the working system and handle updates. Data streaming platforms compared to traditional databases require additional tools to query the data in the stream, and it won’t be so efficient as querying a database.
Having covered the advantages and disadvantages of streaming technology, it’s important to consider when implementing a streaming platform is a valid decision and when other solutions might be a better choice.
In what cases data streaming platforms can be used:
- Whenever there is a need to process data in real-time, i.e., feeding data to Machine Learning and AI systems.
- When it’s necessary to perform log analysis, check sensor and data metrics.
- For fraud detection and telemetry.
- To do low latency messaging or event sourcing.
When data streaming platforms are not the ideal solution:
- The volume of events or messages is low, i.e., several thousand a day.
- When there is a need for random access to query the data for specific records.
- When it’s mostly historical data that is used for reporting and visualization.
- For using large payloads like big pictures, videos, or documents, or in general binary large objects.
Example architecture deployed on AWS
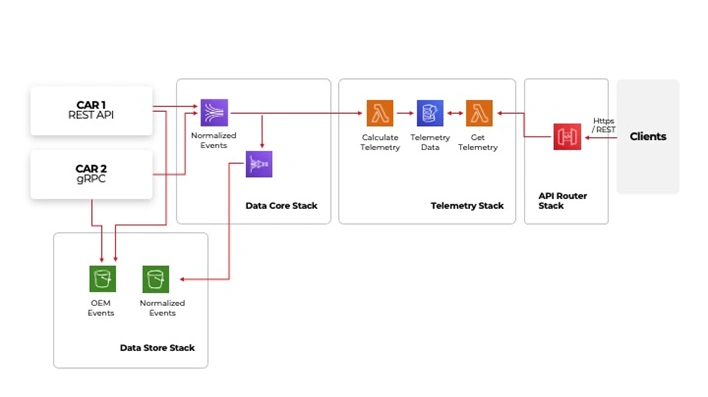
On the left-hand side, there are integrations points with vehicles. The way how they are integrated may vary depending on OEM or make and model. However, despite the protocol they use in the end, they will deliver data to our platform. The stream can receive the data in various formats, in this case, depending on the car manufacturer. The data is processed and then sent to the normalized events. From where it can be sent using a firehose to AWS S3 storage for future needs, i.e., historical data analysis or feeding Machine Learning models. After normalization, it is also sent to the telemetry stack, where the vehicle location and information about acceleration, braking, and cornering speed is extracted and then made available to clients through an API.
Tool comparison
There are many tools available that support data streaming. This comparison is divided into three categories- ease of use, stream processing, and ordering & schema registry and will focus on Apache Kafka as the most popular tool currently in use and RocketMQ and Apache Pulsar as more niche but capable alternatives.
It is important to note that these tools are open-source, so having a qualified and experienced team is necessary to perform implementation and maintenance.
Ease of use
- It is worth noticing that commonly used tools have the biggest communities of experts. That leads to constant development, and it becomes easier for businesses to find talent with the right skills and experience. Kafka has the largest community as Rocket and Pulsar are less popular.
- The tools are comprised of several services. One of them is usually a management tool that can significantly improve user experience. It is built in for Pulsar and Rocket but unfortunately, Kafka is missing it.
- Kafka has built-in connectors that help integrate data sources in an easy and quick way.
- Pulsar also has an integration mechanism that can connect to different data sources, but Rocket has none.
- The number of client libraries has to do with the popularity of the tool. And the more libraries there are, the easier the tool is to use. Kafka is widely used, and so it has many client libraries. Rocket and Pulsar are less popular, so the number of libraries available is much smaller.
- It’s possible to use these tools as a managed service. In that scenario, Kafka has the best support as it is offered by all major public cloud providers- AWS, GCP, and Azure. Rocket is offered by Alibaba Cloud, Pulsar by several niche companies.
- Requirement for extra services for the tools to work. Kafka requires ZooKeeper, Rocket doesn’t require any additional services and Pulsar requires both Zookeeper and BooKKeeper to manage additionally.
Stream processing
Kafka is a leader in this category as it has Kafka Streams. It is a built-in library that simplifies client applications implementation and gives developers a lot of flexibility. Rocket, on the other hand, has no built-in libraries, which means there is nothing to simplify the implementation and it does require a lot of custom work. Pulsar has Pulsar Functions which is a built-in function and can be helpful, but it’s basic and limited.
Ordering & schema registry
Message ordering is a crucial feature. Especially when there is a need to use services that are processing information based on transactions. Kafka offers just a single way of message ordering, and it’s through the use of keys. The keys are in messages that are assigned to a specific partition, and within the partition, the order is maintained.
Pulsar works similarly, either within partition with the use of keys or per producer in SinglePartition mode when the key is not provided.
RocketMQ works in a different way, as it ensures that the messages are always ordered. So if a use case requires that 100% of the messages are ordered then this is the tool that should be considered.
Schema registry is mainly used to validate and version the messages.
That’s an important aspect, as with asynchronous messaging, the common problem is that the message content is different from what the client app is expecting, and this can cause the apps to break.
Kafka has multiple implementations of schema registry thanks to its popularity and being hosted by major cloud providers. Rocket is building its schema registry, but it is not known when it will be ready. Pulsar does have its own schema registry, and it works like the one in Kafka.
Things to be aware of when implementing data streaming platform
- Duplicates. Duplicates can’t be avoided, they will happen at some point due to problems with things like network availability. That’s why exactly-once delivery is a useful feature that ensures messages are delivered only once.
- However, there are some issues with that. Firstly, a few of the out-of-the-box tools support exactly-once delivery and it needs to be set up before starting streaming. Secondly, exactly-once delivery can significantly slow down the stream. And lastly, end-user apps should recognize the messages they receive so that they don’t process duplicates.
- “Black Fridays”. These are scenarios with a sudden increase in the volume of data to process. And to handle these spikes in data volume, it is necessary to plan the infrastructure capacity beforehand. Some of the tools that have auto-scaling natively will handle those out of the box, like Kinesis from AWS. But others that are custom built will crash without proper tuning.
- Popular deployment strategies are also a thing to consider. Unfortunately, deploying data streaming platforms is not a straightforward operation, the popular deployment strategies like blue/green or canary deployment won’t work.
- Messages should always be treated as a structured entity. As the stream will accept everything, that we put in it, it is necessary to determine right from the start what kind of data will be processed. Otherwise, the end user applications will eventually crash if they receive messages in an unexpected format.
Best practices while deploying data streaming platforms
- Schema management. This links directly with the previous point about treating the messages as a structured entity. Schema promotes common data model and ensures backward/forward compatibility.
- Data retention. This is about setting limits on how long the data is stored in the data stream. Storing the data too long and constantly adding new data to the stream will eventually cause that you run out of resources.
- Capacity planning and autoscaling are directly connected to the “Black Fridays” scenario. During the setup, it is necessary to pay close attention to the capacity planning to make sure the environment will cope with sudden spikes in data volume. However, it’s also a good practice to plan for failure scenarios where autoscaling kicks in due to some other issue in the system and spins out of control.
- If the customer data geo-location is important to the specific use case from the regulatory perspective, then it is important to set up separate streams for different locations and make sure they are handled by local data centers.
- When it comes to disaster recovery, it is always wise to be prepared for unexpected downtime, and it’s easier to manage if there is the right toolset set up.
It used to be that people were responsible for the production of most data, but in the digital era, the exponential growth of IoT has caused the scales to shift, and now machine and sensor data is the majority. That data can help businesses build innovative products, services and make informed decisions.
To unlock the value in data, companies need to have a complex strategy in place. One of the key elements in that strategy is the ability to process data in real-time so choosing the tool for the streaming platform is extremely important.
The ability to process data as it arrives is becoming essential in the insurance industry. Streaming platforms help companies handle large data volumes efficiently, improving operations and customer service. Choosing the right tools and approach can make a big difference in performance and reliability.
If you need support in setting up a data streaming platform or improving your data processes, contact Grape Up. Our team can help you find the right solution for your needs.
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles

