Transition towards data-driven organization in the insurance industry: Comparison of data streaming platforms

Insurance has always been an industry that relied heavily on data. But these days, it is even more so than in the past. The constant increase of data sources like wearables, cars, home sensors, and the amount of data they generate presents a new challenge. The struggle is in connecting to all that data, processing and understanding it to make data-driven decisions .
And the scale is tremendous. Last year the total amount of data created and consumed in the world was 59 zettabytes, which is the equivalent of 59 trillion gigabytes. The predictions are that by 2025 the amount will reach 175 zettabytes.
On the other hand, we’ve got customers who want to consume insurance products similarly to how they consume services from e-tailers like Amazon.
The key to meeting the customer expectations lies in the ability to process the data in near real-time and streamline operations to ensure that customers get the products they need when they want them. And this is where the data streaming platforms come to help.
Traditional data landscape
In the traditional landscape businesses often struggled with siloed data or data that was in various incompatible formats. Some of the commonly used solutions that should be mentioned here are:
- Big Data systems like Cassandra that let users store a very large amount of data.
- Document databases such as Elasticsearch that provide a rich interactive query model.
- And relational databases like Oracle and PostgreSQL
That means there were databases with good query mechanisms, Big Data systems capable of handling huge volumes of data, and messaging systems for near-real-time message processing.
But there was no single solution that could handle it all, so the need for a new type of solution became apparent. One that would be capable of processing massive volumes of data in real-time , processing the data from a specific time window while being able to scale out and handle ordered messages.
Data streaming platforms- pros & cons and when should they be used
Data streaming is a continuous stream of data that can be processed, stored, analyzed, and acted upon as it's generated in real-time. Data streams are generated by all types of sources, in various formats and volumes.
But what benefits does deploying data streaming platforms bring exactly?
- First of all, they can process the data in real-time.
- Data in the stream is an ordered, replayable, and fault-tolerant sequence of immutable records.
- In comparison to regular databases, scaling does not require complex synchronization of data access.
- Because the producers and consumers are loosely coupled with each other and act independently, it’s easy to add new consumers or scale down.
- Resiliency because of the replayability of stream and the decoupling of consumers and producers.
But there are also some downsides:
- Tools like Kafka (specifically event streaming platforms) lack features like message prioritization which means data can’t be processed in a different order based on its importance.
- Error handling is not easy and it’s necessary to prepare a strategy for it. Examples of those strategies are fail fast, ignore the message, or send to dead letter queue.
- Retry logic doesn’t come out of the box.
- Schema policy is necessary. Despite being loosely coupled, producers and consumers are still coupled by schema contract. Without this policy in place, it’s really difficult to maintain the working system and handle updates. Data streaming platforms compared to traditional databases require additional tools to query the data in the stream, and it won't be so efficient as querying a database.
Having covered the advantages and disadvantages of streaming technology, it’s important to consider when implementing a streaming platform is a valid decision and when other solutions might be a better choice.
In what cases data streaming platforms can be used:
- Whenever there is a need to process data in real-time, i.e., feeding data to Machine Learning and AI systems.
- When it’s necessary to perform log analysis, check sensor and data metrics.
- For fraud detection and telemetry.
- To do low latency messaging or event sourcing.
When data streaming platforms are not the ideal solution:
- The volume of events or messages is low, i.e., several thousand a day.
- When there is a need for random access to query the data for specific records.
- When it’s mostly historical data that is used for reporting and visualization.
- For using large payloads like big pictures, videos, or documents, or in general binary large objects.
Example architecture deployed on AWS
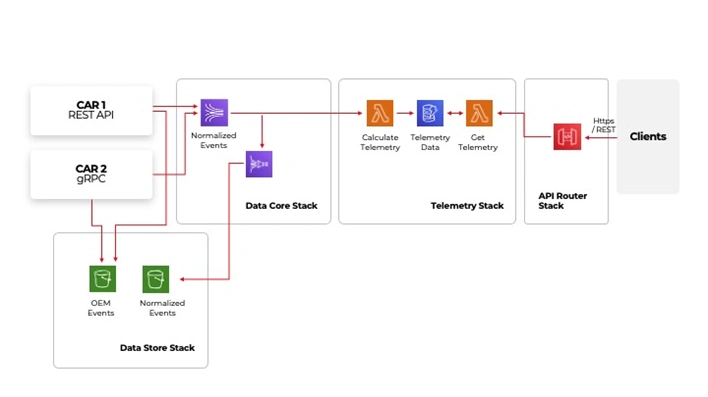
On the left-hand side, there are integrations points with vehicles. The way how they are integrated may vary depending on OEM or make and model. However, despite the protocol they use in the end, they will deliver data to our platform. The stream can receive the data in various formats, in this case, depending on the car manufacturer. The data is processed and then sent to the normalized events. From where it can be sent using a firehose to AWS S3 storage for future needs, i.e., historical data analysis or feeding Machine Learning models . After normalization, it is also sent to the telemetry stack, where the vehicle location and information about acceleration, braking, and cornering speed is extracted and then made available to clients through an API.
Tool comparison
There are many tools available that support data streaming. This comparison is divided into three categories- ease of use, stream processing, and ordering & schema registry and will focus on Apache Kafka as the most popular tool currently in use and RocketMQ and Apache Pulsar as more niche but capable alternatives.
It is important to note that these tools are open-source, so having a qualified and experienced team is necessary to perform implementation and maintenance.
Ease of use
- It is worth noticing that commonly used tools have the biggest communities of experts. That leads to constant development, and it becomes easier for businesses to find talent with the right skills and experience. Kafka has the largest community as Rocket and Pulsar are less popular.
- The tools are comprised of several services. One of them is usually a management tool that can significantly improve user experience. It is built in for Pulsar and Rocket but unfortunately, Kafka is missing it.
- Kafka has built-in connectors that help integrate data sources in an easy and quick way.
- Pulsar also has an integration mechanism that can connect to different data sources, but Rocket has none.
- The number of client libraries has to do with the popularity of the tool. And the more libraries there are, the easier the tool is to use. Kafka is widely used, and so it has many client libraries. Rocket and Pulsar are less popular, so the number of libraries available is much smaller.
- It’s possible to use these tools as a managed service. In that scenario, Kafka has the best support as it is offered by all major public cloud providers- AWS, GCP, and Azure. Rocket is offered by Alibaba Cloud, Pulsar by several niche companies.
- Requirement for extra services for the tools to work. Kafka requires ZooKeeper, Rocket doesn’t require any additional services and Pulsar requires both Zookeeper and BooKKeeper to manage additionally.
Stream processing
Kafka is a leader in this category as it has Kafka Streams. It is a built-in library that simplifies client applications implementation and gives developers a lot of flexibility. Rocket, on the other hand, has no built-in libraries, which means there is nothing to simplify the implementation and it does require a lot of custom work. Pulsar has Pulsar Functions which is a built-in function and can be helpful, but it’s basic and limited.
Ordering & schema registry
Message ordering is a crucial feature. Especially when there is a need to use services that are processing information based on transactions. Kafka offers just a single way of message ordering, and it’s through the use of keys. The keys are in messages that are assigned to a specific partition, and within the partition, the order is maintained.
Pulsar works similarly, either within partition with the use of keys or per producer in SinglePartition mode when the key is not provided.
RocketMQ works in a different way, as it ensures that the messages are always ordered. So if a use case requires that 100% of the messages are ordered then this is the tool that should be considered.
Schema registry is mainly used to validate and version the messages.
That’s an important aspect, as with asynchronous messaging, the common problem is that the message content is different from what the client app is expecting, and this can cause the apps to break.
Kafka has multiple implementations of schema registry thanks to its popularity and being hosted by major cloud providers. Rocket is building its schema registry, but it is not known when it will be ready. Pulsar does have its own schema registry, and it works like the one in Kafka.
Things to be aware of when implementing data streaming platform
- Duplicates. Duplicates can’t be avoided, they will happen at some point due to problems with things like network availability. That’s why exactly-once delivery is a useful feature that ensures messages are delivered only once.
- However, there are some issues with that. Firstly, a few of the out-of-the-box tools support exactly-once delivery and it needs to be set up before starting streaming. Secondly, exactly-once delivery can significantly slow down the stream. And lastly, end-user apps should recognize the messages they receive so that they don’t process duplicates.
- “Black Fridays”. These are scenarios with a sudden increase in the volume of data to process. And to handle these spikes in data volume, it is necessary to plan the infrastructure capacity beforehand. Some of the tools that have auto-scaling natively will handle those out of the box, like Kinesis from AWS. But others that are custom built will crash without proper tuning.
- Popular deployment strategies are also a thing to consider. Unfortunately, deploying data streaming platforms is not a straightforward operation, the popular deployment strategies like blue/green or canary deployment won’t work.
- Messages should always be treated as a structured entity. As the stream will accept everything, that we put in it, it is necessary to determine right from the start what kind of data will be processed. Otherwise, the end user applications will eventually crash if they receive messages in an unexpected format.
Best practices while deploying data streaming platforms
- Schema management. This links directly with the previous point about treating the messages as a structured entity. Schema promotes common data model and ensures backward/forward compatibility.
- Data retention. This is about setting limits on how long the data is stored in the data stream. Storing the data too long and constantly adding new data to the stream will eventually cause that you run out of resources.
- Capacity planning and autoscaling are directly connected to the “Black Fridays” scenario. During the setup, it is necessary to pay close attention to the capacity planning to make sure the environment will cope with sudden spikes in data volume. However, it’s also a good practice to plan for failure scenarios where autoscaling kicks in due to some other issue in the system and spins out of control.
- If the customer data geo-location is important to the specific use case from the regulatory perspective, then it is important to set up separate streams for different locations and make sure they are handled by local data centers.
- When it comes to disaster recovery, it is always wise to be prepared for unexpected downtime, and it’s easier to manage if there is the right toolset set up.
It used to be that people were responsible for the production of most data, but in the digital era, the exponential growth of IoT has caused the scales to shift, and now machine and sensor data is the majority. That data can help businesses build innovative products, services and make informed decisions.
To unlock the value in data, companies need to have a complex strategy in place. One of the key elements in that strategy is the ability to process data in real-time so choosing the tool for the streaming platform is extremely important.
The ability to process data as it arrives is becoming essential in the insurance industry. Streaming platforms help companies handle large data volumes efficiently, improving operations and customer service. Choosing the right tools and approach can make a big difference in performance and reliability.

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
How to enable data-driven innovation for the mobility insurance
Digitalization has changed the way we shop, work, learn and take care of our health or travel. Cars are no longer used just to get from A to B. They are jam-packed with technology that connects us to the world, enhances safety, prevents breakdowns, and even provides entertainment. With the rise of the Internet of Things and artificial intelligence, a vehicle is no longer understood solely in terms of its performance and sleek design. It has become software on wheels, a gateway to new worlds - not just physical, but also virtual. And if the nature of insurance itself is changing, then the company offering insurance must keep up with these changes as well. Insurance needs digital innovation, as much as any other market area.
These days customers are looking for customization, personalization, and understanding their needs on an almost organic level. Data and advanced analytics allow us to effectively satisfy these needs. Thanks to them, it is possible to fine-tune the offer, not so much for a specific group, but for a particular person - their habits, daily schedule, interests, health restrictions, or aesthetic preferences. And in the case described by us - a person's driving style and commuting patterns .
If you think about it, the insurer has the perfect tool in their hands. If they can tap into the potential of the software-defined vehicle and equip it with the right applications, there will be nearly zero chance of inaccurate insurance risk estimates. Data doesn't lie and shows a factual, not imaginary picture of a driver's driving style and behavior on the road.
While in the traditional insurance model pricing is static and data is collected offline and not aligned with the driver's actual preferences, new technologies such as the cloud, the IoT, and AI allow for these limitations to be effectively lifted.
With them, an offering is created that competes in the marketplace, generates new revenue streams within the company, and builds customer loyalty.
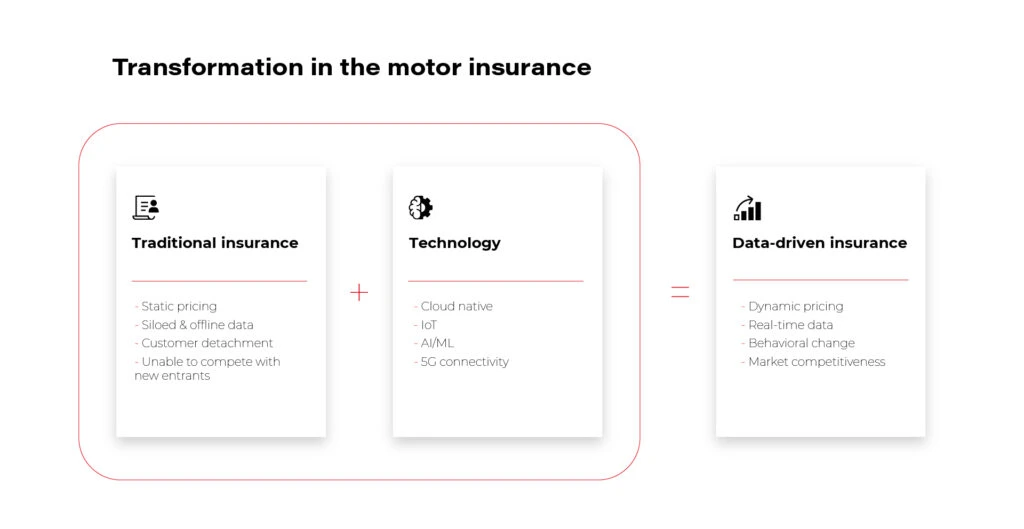
Data-driven innovation - easier said than done. Or maybe not?
The transformation of a vehicle from a traditionally understood mechanical device into a "smartphone on four wheels," as Akio Toyoda once said about modern vehicles, takes time and will not happen overnight. But year by year it already happens, and as the new car models distributed by the big corporations show, this process is actually underway.
Read our article on the latest trends in the automotive industry
The so-called software-defined vehicle that we are developing with our clients at Grape Up is a vehicle that moves through an ecosystem of numerous variables, accessed by different players and technologies.
Clearly, one such provider can be - and should be - the insurer whose products have been tied to the automotive market invariably since 1897, when a certain Gilbert J. Loomis, a resident of Dayton, Ohio, first purchased an automotive liability insurance policy.
However, for insurance companies to play an integral role in the use of vehicle-generated data, the driver must receive a precisely functioning and secure service from which they will derive real benefits. Without building specific technical competencies and software-defined vehicle knowledge , the insurer cannot achieve these goals.
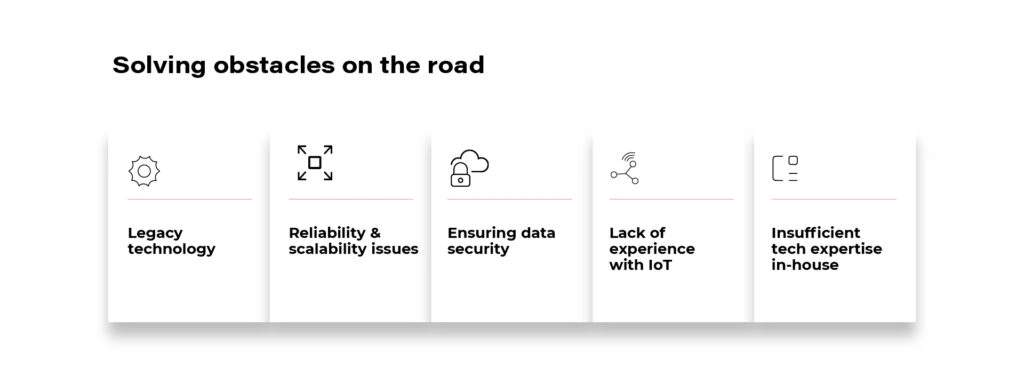
Only by creating this type of business unit from scratch in-house, or by partnering with software companies, will they be able to compete with insurtech startups like, e.g. Lemonade, which builds their businesses from the ground up based on AI and data analytics .
The right technology partner will take care of:
- data security;
- selection of cloud and IoT technologies;
- and will ensure the reliability and scalability of the proposed solutions.
During this time, the insurer can focus on what they do best - developing insurance competencies and tweaking their offers.
How to choose the right technology partner?
Just as customers are looking for insurance that accommodates their driving and lifestyle, an insurance company should select a technology partner that has more than just technical skills to offer. After all, changing the model in which a traditional insurance company operates does not boil down to creating a digital sales channel on the Internet and launching a modern website. We are talking about a completely different scale of operations requiring the insurance company to be embedded in a completely new, rapidly developing environment.
Therefore they need a partner who naturally navigates the software-defined vehicle ecosystem, understands its specifics, and has experience in working with the automotive industry. Besides, it should be someone knowledgeable about the specifics of the P&C insurance market and the challenges faced by the insurance client.

It is only at the intersection of these three areas: technology, automotive, and insurance, that competencies are built to effectively compete against modern insurtechs.
Like in the Japanese philosophy of ikigai, which explains how to find one's sense of purpose and give meaning to one's work, both companies can build valuable, useful solutions for users. They will bring satisfaction not only to customers but also to the insurance company, which will open a new revenue channel and meet the needs of the market.
How AI is transforming automotive and car insurance
The car insurance industry is experiencing a real revolution today. Insurers are more and more carefully targeting their offers using AI and machine learning features. Such innovations significantly enhance business efficiency, eliminate the risk of accidents and their consequences, and enable adaptation to modern realities.
Changes are needed today
Approximately $25 billion is "frozen" with insurers annually due to problems such as fraud, claims adjustment, delays in service garages, etc. However, customers are not always happy with the insurance amounts they receive and the fact that they often have to accept undervalued rates. The reason for this is that due to limited data, it is difficult to accurately identify the culprit of the incident. It is also often the case that compensation is based on rates lower than the actual value of the damage.
Insurers today need to be aware of the ecosystem in which they operate . Clients are becoming more demanding and, according to an IBM Institute for Business Value (IBV) study, 50 percent of them prefer tailor-made products based on individual quotes. The very model of cooperation between businesses is also changing, as relations between insurance providers and car manufacturers are growing tighter. All of this is linked to the fact that cars are becoming increasingly autonomous, allowing them to more closely monitor traffic incidents and driver behavior as well as manage risk. Estimates suggest there will be as many as one trillion connected devices by 2025, and by 2030 there will be an increasing percentage of vehicles with automated features (ADAS).
No wonder there's an increasing buzz about changes in the car insurance industry. And these are changes based on technology. The use of artificial intelligence , machine learning, and advanced data analytics in the cloud will allow for seamless adaptation to market expectations.
CASE STUDY
SARA Assicurazioni and Automobile Club Italia are already encouraging drivers to install ADAS systems in exchange for a 20% discount on their insurance premiums. Indeed, it has been demonstrated that such systems can slash the rate of liability claims for personal injury by 4-25% and by 7-22% for property damage.
Why is this so important for insurers who want to face the reality?
Artificial intelligence-based pricing models provide a significant reduction in the time needed to introduce new offerings and to make optimal decisions. The risk of being mispriced is also lowered, as is the time it takes to launch insurance products.
The new AI-based insurance reality is happening as we speak. The digital-first companies like Lemonade, with their high flexibility in responding to market changes, are showing customers what solutions are feasible. In doing so, they put pressure on those companies that still hesitate to test new models.

Areas of change in car insurance due to AI
Artificial intelligence and related technologies are having a huge impact on many aspects of the insurance industry : quoting, underwriting, distribution, risk and claims management, and more.

Changes in insurance distribution
Artificial intelligence algorithms smoothly create risk profiles so that the time required to purchase a policy is reduced to minutes. Smart contracts based on blockchain instantly authenticate payments from an online account. At the same time, contract processing and payment verification is also vastly streamlined, reducing insurers' client acquisition cost.
Advanced risk assessment and reliable pricing
Traditionally, insurance premiums are determined using the "cost-plus" method. This includes an actuarial assessment of the risk premium, a component for direct and indirect costs, and a margin. Yet it has quite a few drawbacks.
One of them is the inability to easily account for non-technical price determinants, as well as the inability to react quickly to shifting market conditions.
How is risk calculated? For car insurance companies, the assessment refers to accidents, road crashes, breakdowns, theft, and fatalities.
These days, all these aspects can be controlled by leveraging AI, coupled with IoT data that provides real-time insights. Customized pricing of policies, for instance, can take into account GPS device dataon a vehicle’s location, speed, and distance traveled. This way, you can see whether the vehicle spends most of its time in the driveway or if, conversely, it frequently travels on highways, particularly at excessive speeds.
In addition, insurance companies can use a host of other sensor and camera data, as well as reports and documents from previous claims. Having all this information gathered, algorithms are able to reliably determine risk profiles.
CASE STUDY
Ant Financial, a Chinese company that offers an ecosystem of merged digital products and services, specializes in creating highly detailed customer profiles. Their technology is based on artificial intelligence algorithms that assign car insurance points to each customer, similarly to credit scoring. They take into account such detailed factors as lifestyle and habits. Based on this, the app shows an individual score, assigning a product that matches the specific policyholder.
An in-depth analysis of claims
The cooperation between an insurance company and its client is based on the premise that both parties are pursuing to avoid potential losses. Unfortunately, sometimes accidents, breakdowns or thefts occur and a claims process must be implemented. Artificial intelligence, integrated IoT data, and telematics come in handy irrespective of the type of claims we are handling.
- These technologies are suitable for, among other things, automatically generating not only damage information but also repair cost estimates.
- Machine learning techniques can estimate the average cost of claims for various client segments.
- Sending real-time alerts, in turn, enables the implementation of predictive maintenance.
- Once an image has been uploaded, an extensive database of parts and prices can be created.
The drivers themselves gain control as they can carry out the process of registering the damage from A to Z: take a photo, upload it to the insurer's platform and get an instant quote for the repair costs. From now on, they are no longer reliant on workshop quotes, which were often highly overestimated in line with the principle: "the insurer will pay anyway".
Fraud prevention
29 billion dollars in annual losses These are losses to auto insurers that occur due to fraud. Fraudsters want to scam a company out of insurance money based on illegally orchestrated events. How to prevent this? The answer is AI.
Analyzed data retrieved from cameras and sensors can reconstruct the details of a car accident with high precision. So, having an accident timeline generated by artificial intelligence facilitates accident investigation and claims management.
CASE STUDY
An advanced AI-based incident reconstruction has been tested lately on 200,000 vehicles as part of a collaboration between Israel's Project Nexar and a Japanese insurance company.
Assistance in the event of accidents
According to data from the OECD, car accident fatalities could be reduced by 44 percent if emergency medical services had access to real-time information about the injuries of involved parties.
Still, real-time assistance has great potential not only for public services but also in the context of auto insurance.
By leveraging AI to perform this, insurers can provide drivers with quick and semi-automated responses during collisions and accidents . For example, a chatbot can instruct the driver on how to behave, how to call for help, or how to help fellow passengers. All this is essential in the context of saving lives. At the same time, it is a way of reducing the consequences of an accident.
Transparent decision making (client perspective)
New technologies offer solutions to many problems not only for insurers but also for clients. The latter often complain about discrimination and unfair, from their point of view, calculations of policies and compensation.
"Smart automated gatekeepers" are superior in multiple ways to the imperfect solutions of traditional models. This is because, based on a number of reliable parameters, they facilitate the creation of more authoritative and personalized pricing policies. Data-rich and automated risk and damage assessments pay off for consumers because they have decision-making power based on how their actions affect insurance coverage.
The opportunities and future of AI in car insurance
McKinsey's analysis says that across functions and use cases AI investments are worth $1.1 trillion in potential annual value for the insurance industry.
The direction of changes is outlined in two ways: first by increasingly connected and software-equipped vehicles with more sensors. Second, by the changing analytical skills of insurers. Data-driven vehicles will certainly affect more reliable and real-time consistent repair costs and, consequently, claims payments. And when it comes to planning offers and understanding the client, AI is an enabler of change for personalized, real-time service (24/7 virtual assistance) and for creating flexible policies. All signs indicate that such "abstract" parameters as education or earnings will cease to play a major role in this regard.

As can be inferred from the diagram above, the greater the impact of a given technology on an insurance company's business , the longer the time required for its implementation. Therefore, it is vital to consider the future on a macro scale, by planning the strategy not for 2 years, but for 10.
The decisions you make today have a bearing on improving operational efficiency, minimizing costs, and opening up to individual client needs, which are becoming more and more coupled with digital technologies.
Interested in our services?
Reach out for tailored solutions and expert guidance.