Yet another look at cloud-native apps architecture

Cloud is getting extremely popular and ubiquitous. It’s everywhere. Imagine, the famous “everywhere” meme with Buzz and Woody from Toy Story in which Buzz shows Woody an abundance of...whatever the caption says. It’s the same with the cloud.
The original concepts of what exactly cloud is, how it should or could be used and adopted, has changed over time. Monolithic applications were found to be difficult to maintain and scale in the modern environments. Figuring out the correct solutions has turned into an urgent problem and blocked the development of the new approach.
Once t he cloud platform like Pivotal Cloud Foundry or Kubernetes is deployed and properly maintained , developers, managers and leaders step in. They start looking for best practices and guidelines for how cloud applications should actually be developed and how these apps should operate. Is it too little too late? No, not really.
If cloud platforms were live creatures, we could compare them to physical infrastructure. Why? Because they both don't really care if developers deploy a huge monolith or well-balanced microservices. You can really do anything you want, but before you know it, will be clearly visible that the original design does not scale very well. It may fail very often and is virtually impossible to configure and deploy it on different environments without making specific changes to the platform or extremely complex and volatile configuration scripts.
Does a universal architecture exist?
The problem with the not-really-defined cloud architecture led to the creation of the idea of the “application architecture” which performs well in the cloud. It should not be limited to the specific platform or infrastructure, but a set of universal rules that help developers bootstrap their applications. The answer to that problem was constituted in Heroku, one of the first commonly used PaaS platforms.
It’s a concept of twelve-factor applications which is still applicable nowadays, but also endlessly extended as the environment of cloud platforms and architectures mutate. That concept was extended in a book by Kevin Hoffman, titled "Beyond Twelve-Factor App" to the number of 15 factors. Despite the fact that the list is not the one and only solution to the problem, it has been successfully applied by a great deal of companies. The order of factors is not important, but in this article, I have tried to preserve the order from the original webpage to make the navigation easier. Shall we?
I. Codebase
There is one codebase per application which is tracked in revision control (GIT, SVN - doesn’t matter which one). However, a shared code between applications does not mean that the code should be duplicated - it can be yet another codebase which will be provided to the application as a component, or even better, as a versioned dependency. The same codebase may be deployed to multiple different environments and has to produce the same release. The idea of one application is tightly coupled with the single responsibility pattern. A single repository should not contain multiple applications or multiple entry points - it has to be a single responsibility, a single execution point code that consists of a single microservice.
II. Dependencies
Dependency management and isolation consist of two problems that should be solved. Firstly, it is very important to explicitly declare the dependencies to avoid a situation in which there is an API change in the dependency which renders the library useless from the point of the existing code and fails the build or release process.
The next thing are repeatable deployments. In an ideal world all dependencies should be isolated and bundled with the release artifact of the application. It is not always entirely achievable, but should be done and it should be possible too. In some platforms such as Pivotal Cloud Foundry this is being managed by buildpack which clearly isolates the application from, for example, the server that runs it.
III. Config
This guideline is about storing configuration in the environment. To be explicit, it also applies to the credentials which should also be securely stored in the environment using, for example, solutions like CredHub or Vault. Please mind that at no time the credentials or configuration can be a part of the source code! The configuration can be passed to the container via environment variables or by files mounted as a volume. It is recommended to think about your application as if it was open source. If you feel confident to push all the code to a publicly accessible repository, you have probably already separated the configuration and credentials from the code. An even better way to provide the configuration will be to use a configuration server such as Consul or Spring Cloud Config.
IV. Backing services
Treat backing services like attached resources. The bound services are for example databases, storage but also configuration, credentials, caches or queues. When the specific service or resource is bound, it can be easily attached, detached or replaced if required. This adds flexibility to using external services and, as a result, it may allow you to easily switch to the different service provider.
V. Build, release, run
All parts of the deployment process should be strictly separated. First, the artifact is created in the build process. Build artifact should be immutable. This means the artifact can be deployed to any environment as the configuration is separated and applied in the release process. The release artifact is unique per environment as opposed to the build artifact which is unique for all environments. This means that there is one build artifact for the dev, test and prod environments, but three release artifacts (each for each environment) with specific configuration included. Then the release artifact is being run in the cloud. Kevin adds to this list yet another discrete part of the process - the design which happens before the build process and includes (but is not limited) to selecting dependencies for the component or the user story.
VI. Stateless processes
Execute the application as one or more stateless processes. One of the self-explanatory factors, but somehow also the one that creates a lot of confusion among developers. How can my service be stateless if I need to preserve user data, identities or sessions? In fact, all of this stateful data should be saved to the backing services like databases or file systems (for example Amazon S3, Azure Blob Storage or managed by services like Ceph). The filesystem provided by the container to the service is ephemeral and should be treated as volatile. One of the easy ways to maintain microservices is to always deploy two load balanced copies. This way you can easily spot an inconsistency in responses if the response depends on locally cached or stateful data.
VII. Port binding
Expose your services via the port binding and avoid specifying ports in the container. Port selection should be left for the container runtime to be assigned on the runtime. This is not necessarily required on platforms such as Kubernetes. Nevertheless, ports should not be micromanaged by the developers, but automatically assigned by the underlying platform, which largely reduces the risk of having a port conflict. Ports should not be managed by other services, but automatically bound by the platform to all services that communicate with each other.
VIII. Concurrency
Services should scale out via the process model as opposed to vertical scaling. When the application load reaches its limits, it should manually or automatically scale horizontally. This means creating more replicas of the same stateless service.
IX. Disposability
Application should start and stop rapidly to avoid problems like having an application which does not respond to healthchecks. Why? Because it starts (which may even result in the infinite loop of restarts) or cancels the request when the deployment is scaled down.
X. Development, test and production environments parity
Keeping all environments the same, or at least very similar, may be a complex task. The difficulties vary from VMs and licenses costs to the complexity of deployment. The second problem may be avoided by properly configured and managed underlying platform. The advantages of the approach is to avoid the "works for me" problem which gets really serious when happens on production which is automatically deployed and the tests passed on all environments except production because totally different database engine was used.
XI. Logs
Logs should be treated as event streams and entirely independent of the application. The only responsibility of the application is to output the logs to the stdout and stderr streams. Everything else should be handled by the platform. That means passing the logs to centralized or decentralized store like ELK, Kafka or Splunk.
XII. Admin processes
The administrative and management processes should be run as "one-off". This actually self-explanatory and can be achieved by creating Concourse pipelines for the processes or by writing Azure Function/AWS Lambdas for that purpose. This list concludes all factors provided by Heroku team. Additional factors added to the list in "Beyond Twelve-Factor App" are:
XIII. Telemetry
Applications can be deployed into multiple instances which means it is not viable anymore to connect and debug the application to find out if it works or what is wrong. The application performance should be automatically monitored, and it has to be possible to check the application health using automatic health checks. Also, for specific business domains telemetry is useful and should be included to monitor the current and past state of the application and all resources.
XIV. Authentication and authorization
Authentication, authorization, or the general aspect of security, should be the important part of the application design and development, but also configuration and management of the platform. RBAC or ABAC should be used on each endpoint of the application to make sure the user is authorized to make that specific request to that specific endpoint.
XV. API First
API should be designed and discussed before the implementation. It enables rapid prototyping, allows to use mock servers and moves team focus to the way services integrate. As product is consumed by the clients the services are consumed by different services using the public APIs - so the collaboration between the provider and the consumer is necessary to create the great and useful product. Even the excellent code can be useless when hidden behind poorly written and badly documented interface. For more details about the tools and the concept visit API Blueprint website.
Is that all?
This is very extensive list and in my opinion from technical perspective this is just enough to navigate the cloud native world. On the other hand there is one more point that I would like to add which is not exactly technical, but still extremely important when thinking about creating successful product.
XVI. Agile company and project processes
The way to succeed in the rapidly changing and evolving cloud world is not only to create great code and beautiful, stateless services. The key is to adapt to changes and market need to create the product that is appreciated by the business. The best fit for that is to adopt the agile or lean process, extreme programming, pair programming . This allows the rapid growth in short development cycles which also means quick market response. When the team members think that their each commit is a candidate to production release and work in pairs the quality of the product improves. The trick is to apply the processes as widely as possible, because very often, as in Conway's law, the organization of your system is only as good as organizational structure of your company.
Summary of cloud-native apps
That’s the end of our journey through to the perfect Cloud-Native apps. Of course this is not the best solution to every problem. In the real world we don’t really have handy silver bullets. We must work with what we’ve got, but there is always room for improvement. Next time when you design your, hopefully, cloud-native apps, bear these guidelines in mind.

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
Bringing visibility to cloud-native applications
Working with cloud-native applications entails continuously tackling and implementing solutions to cross-cutting concerns. One of these concerns that every project is bound to run into comes to deploying highly scalable, available logging, and monitoring solutions.
You might ask, “how do we do that? Is it possible to find "one size fits all" solution for such a complex and volatile problem?” You need to look no further!
Taking into account our experience based on working with production-grade environments , we propose a generic architecture, built totally from open source components, that certainly provide you with the highly performant and maintainable workload. To put this into concrete terms, this platform is characterized by its:
- High availability - every component is available 24/7 providing users with constant service even in the case of a system failure.
- Resiliency - crucial data are safe thanks to redundancy and/or backups.
- Scalability - every component is able to be replicated on demand accordingly to the current load.
- Performance - ability to be used in any and all environments.
- Compatibility - easily integrated into any workflows.
- Open source - every component is accessible to anyone with no restrictions.
To build an environment that enables users to achieve outcomes described above, we decided to look at Elastic Stack, fully open source logging solution, structured in a modular way.
Elastic stack
Each component has a specific function, allowing it to be scaled in and out as needed. Elastic stack is composed of:
- Elasticsearch - RESTful, distributed search and analytics engine built on Apache Lucene able to index copious amount of data.
- Logstash - server-side data processing pipeline, able to transform, filter and enrich events on the fly.
- Kibana – a feature-rich visualization tool, able to perform advanced analysis on your data.
While all this looks perfect, you still need to be cautious while deploying your Elastic Stack cluster. Any downtime or data loss caused by incorrect capacity planning can be detrimental to your business value. This is extremely important, especially when it comes to production environments. Everything has to be carefully planned, including worst-case scenarios. Concerns that may weigh on the successful Elastic stack configuration and deployment are described below.
High availability
When planning any reliable, fault-tolerant systems, we have to distribute its critical parts across multiple, physically separated network infrastructures. It will provide redundancy and eliminate single points of failure.
Scalability
ELK architecture allows you to scale out quickly. Having good monitoring tools setup makes it easy to predict and react to any changes in the system's performance. This makes it resilient and helps you optimize the cost of maintaining the solution.
Monitoring and alerts
A monitoring tool along with a detailed set of alerting rules will save you a lot of time. It lets you easily maintain the cluster, plan many different activities in advance, and react immediately if anything bad happens to your software.
Resource optimization
In order to maximize the stack performance, you need to plan the hardware (or virtualized hardware) allocation carefully. While data nodes need efficient storage, ingesting nodes will need more computing power and memory. While planning this take into consideration the number of events you want to process and amount of data that has to be stored to avoid many problems in the future.
Proper component distribution
Make sure the components are properly distributed across the VMs. Improper setup may cause high CPU and memory usage, can introduce bottlenecks in the system and will definitely result in lower performance. Let's take Kibana and ingesting node as an example. Placing them on one VM will cause poor user experience since UI performance will be affected when more ingesting power is needed and vice-versa.
Data replication
Storing crucial data requires easy access to your data nodes. Ideally, your data should be replicated across multiple availability zones which will guarantee redundancy in case of any issues.
Architecture
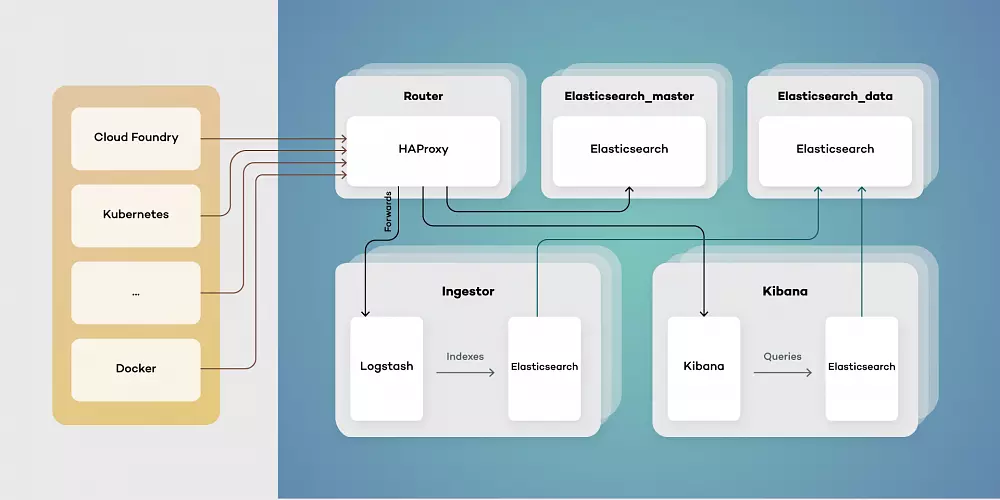
Our proposed architecture consists of five types of virtual machines - Routers, elastic masters, elastic data, ingestors, and Kibana instances. This toolset simplifies scaling of components while separating their responsibilities. Each of them has a different function:
- Elasticsearch_master - controls indexes and Elasticsearch master. Responsible for creating new indexes, rolling updates and monitoring clusters health.
- Elasticsearch_data - stores data and retrieves it as needed. Can be run both as hot and warm storage, as well as provides redundancy on data.
- Ingestor - exposes input endpoints for events both while transforming and enriching data stored in Elasticsearch.
- Kibana - provides users with visualizations by querying Elasticsearch data.
- Router - serves as a single point of entry, both for users and services producing data events.
Architecting your Elastic Stack deployment in this way allows for the simple upgrade procedure. Thanks to using a single point of entry, switching to a new version of Elastic Stack is as simple as pointing HAProxy to an upgraded cluster.
Using a clustered structure also allows for freely adding data nodes as needed when your traffic inevitably grows.
Interested in our services?
Reach out for tailored solutions and expert guidance.