How to Run Selenium BDD Tests in Parallel with AWS Lambda – Lambda Handlers


In our first article about Selenium BDD Tests in Parallel with AWS Lambda, we introduce parallelization in the Cloud and give you some insights into automating testing to accelerate your software development process. By getting familiar with the basics of Lambda Layers architecture and designing test sets, you are now ready to learn more about the Lambda handlers.
Lambda handlers
Now’s the time to run our tests on AWS. We need to create two Lambda handlers. The first one will find all scenarios from the test layer and run the second lambda in parallel for each scenario. In the end, it will generate one test report and upload it to the AWS S3 bucket.
Let’s start with the middle part. In order to connect to AWS, we need to use the boto3 library – AWS SDK for Python. It enables us to create, configure, and manage AWS services. We also import here behave __main__ function, which will be called to run behave tests from the code, not from the command line.
lambda/handler.py
import json
import logging
import os
from datetime import datetime
from subprocess import call
import boto3
from behave.__main__ import main as behave_main
REPORTS_BUCKET = 'aws-selenium-test-reports'
DATETIME_FORMAT = '%H:%M:%S'
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def get_run_args(event, results_location):
test_location = f'/opt/{event["tc_name"]}'
run_args = [test_location]
if 'tags' in event.keys():
tags = event['tags'].split(' ')
for tag in tags:
run_args.append(f'-t {tag}')
run_args.append('-k')
run_args.append('-f allure_behave.formatter:AllureFormatter')
run_args.append('-o')
run_args.append(results_location)
run_args.append('-v')
run_args.append('--no-capture')
run_args.append('--logging-level')
run_args.append('DEBUG')
return run_args
What we also have above is setting arguments for our tests e.g., tags or feature file locations. But let’s get to the point. Here is our Lambda handler code:
lambda/handler.py
def lambda_runner(event, context):
suffix = datetime.now().strftime(DATETIME_FORMAT)
results_location = f'/tmp/result_{suffix}'
run_args = get_run_args(event, results_location)
print(f'Running with args: {run_args}')
# behave -t @smoke -t ~@login -k -f allure_behave.formatter:AllureFormatter -o output --no-capture
try:
return_code = behave_main(run_args)
test_result = False if return_code == 1 else True
except Exception as e:
print(e)
test_result = False
response = {'test_result': test_result}
s3 = boto3.resource('s3')
for file in os.listdir(results_location):
if file.endswith('.json'):
s3.Bucket(REPORTS_BUCKET).upload_file(f'{results_location}/{file}', f'tmp_reports/{file}')
call(f'rm -rf {results_location}', shell=True)
return {
'statusCode': 200,
'body': json.dumps(response)
}
The lambda_runner method is executed with tags that are passed in the event. It will handle a feature file having a name from the event and at least one of those tags. At the end of a single test, we need to upload our results to the S3 bucket. The last thing is to return a Lambda result with a status code and a response from tests.
There’s a serverless file with a definition of max memory size, lambda timeout, used layers, and also some policies that allow us to upload the files into S3 or save the logs in CloudWatch.
lambda/serverless.yml
service: lambda-test-runner
app: lambda-test-runner
provider:
name: aws
runtime: python3.6
region: eu-central-1
memorySize: 512
timeout: 900
iamManagedPolicies:
- "arn:aws:iam::aws:policy/CloudWatchLogsFullAccess"
- "arn:aws:iam::aws:policy/AmazonS3FullAccess"
functions:
lambda_runner:
handler: handler.lambda_runner
events:
- http:
path: lambda_runner
method: get
layers:
- ${cf:lambda-selenium-layer-dev.SeleniumLayerExport}
- ${cf:lambda-selenium-layer-dev.ChromedriverLayerExport}
- ${cf:lambda-selenium-layer-dev.ChromeLayerExport}
- ${cf:lambda-tests-layer-dev.FeaturesLayerExport}
Now let’s go back to the first lambda function. There will be a little more here, so we’ll go through it in batches. Firstly, imports and global variables. REPORTS_BUCKET should have the same value as it’s in the environment.py file (tests layer).
test_list/handler.py
import json
import logging
import os
import shutil
import subprocess
from concurrent.futures import ThreadPoolExecutor as PoolExecutor
from datetime import date, datetime
import boto3
from botocore.client import ClientError, Config
REPORTS_BUCKET = 'aws-selenium-test-reports'
SCREENSHOTS_FOLDER = 'failed_scenarios_screenshots/'
CURRENT_DATE = str(date.today())
REPORTS_FOLDER = 'tmp_reports/'
HISTORY_FOLDER = 'history/'
TMP_REPORTS_FOLDER = f'/tmp/{REPORTS_FOLDER}'
TMP_REPORTS_ALLURE_FOLDER = f'{TMP_REPORTS_FOLDER}Allure/'
TMP_REPORTS_ALLURE_HISTORY_FOLDER = f'{TMP_REPORTS_ALLURE_FOLDER}{HISTORY_FOLDER}'
REGION = 'eu-central-1'
logger = logging.getLogger()
logger.setLevel(logging.INFO)
There are some useful functions to avoid duplication and make the code more readable. The first one will find and return all .feature files which exist on the tests layer. Then we have a few functions that let us create a new AWS bucket or folder, remove it, upload reports, or download some files.
test_list/handler.py
def get_test_cases_list() -> list:
return [file for file in os.listdir('/opt') if file.endswith('.feature')]
def get_s3_resource():
return boto3.resource('s3')
def get_s3_client():
return boto3.client('s3', config=Config(read_timeout=900, connect_timeout=900, max_pool_connections=500))
def remove_s3_folder(folder_name: str):
s3 = get_s3_resource()
bucket = s3.Bucket(REPORTS_BUCKET)
bucket.objects.filter(Prefix=folder_name).delete()
def create_bucket(bucket_name: str):
client = get_s3_client()
try:
client.head_bucket(Bucket=bucket_name)
except ClientError:
location = {'LocationConstraint': REGION}
client.create_bucket(Bucket=bucket_name, CreateBucketConfiguration=location)
def create_folder(bucket_name: str, folder_name: str):
client = get_s3_client()
client.put_object(
Bucket=bucket_name,
Body='',
Key=folder_name
)
def create_sub_folder(bucket_name: str, folder_name: str, sub_folder_name: str):
client = get_s3_client()
client.put_object(
Bucket=bucket_name,
Body='',
Key=f'{folder_name}{sub_folder_name}'
)
def upload_html_report_to_s3(report_path: str):
s3 = get_s3_resource()
current_path = os.getcwd()
os.chdir('/tmp')
shutil.make_archive('report', 'zip', report_path)
s3.Bucket(REPORTS_BUCKET).upload_file('report.zip', f'report_{str(datetime.now())}.zip')
os.chdir(current_path)
def upload_report_history_to_s3():
s3 = get_s3_resource()
current_path = os.getcwd()
os.chdir(TMP_REPORTS_ALLURE_HISTORY_FOLDER)
for file in os.listdir(TMP_REPORTS_ALLURE_HISTORY_FOLDER):
if file.endswith('.json'):
s3.Bucket(REPORTS_BUCKET).upload_file(file, f'{HISTORY_FOLDER}{file}')
os.chdir(current_path)
def download_folder_from_bucket(bucket, dist, local='/tmp'):
s3 = get_s3_resource()
paginator = s3.meta.client.get_paginator('list_objects')
for result in paginator.paginate(Bucket=bucket, Delimiter='/', Prefix=dist):
if result.get('CommonPrefixes') is not None:
for subdir in result.get('CommonPrefixes'):
download_folder_from_bucket(subdir.get('Prefix'), bucket, local)
for file in result.get('Contents', []):
destination_pathname = os.path.join(local, file.get('Key'))
if not os.path.exists(os.path.dirname(destination_pathname)):
os.makedirs(os.path.dirname(destination_pathname))
if not file.get('Key').endswith('/'):
s3.meta.client.download_file(bucket, file.get('Key'), destination_pathname)
For that handler, we also need a serverless file. There’s one additional policy AWSLambdaExecute and some actions that are required to invoke another lambda.
test_list/serverless.yml
service: lambda-test-list
app: lambda-test-list
provider:
name: aws
runtime: python3.6
region: eu-central-1
memorySize: 512
timeout: 900
iamManagedPolicies:
- "arn:aws:iam::aws:policy/CloudWatchLogsFullAccess"
- "arn:aws:iam::aws:policy/AmazonS3FullAccess"
- "arn:aws:iam::aws:policy/AWSLambdaExecute"
iamRoleStatements:
- Effect: Allow
Action:
- lambda:InvokeAsync
- lambda:InvokeFunction
Resource:
- arn:aws:lambda:eu-central-1:*:*
functions:
lambda_test_list:
handler: handler.lambda_test_list
events:
- http:
path: lambda_test_list
method: get
layers:
- ${cf:lambda-tests-layer-dev.FeaturesLayerExport}
- ${cf:lambda-selenium-layer-dev.AllureLayerExport}
And the last part of this lambda – the handler. In the beginning, we need to get a list of all test cases. Then if the action is run_tests, we get the tags from the event. In order to save reports or screenshots, we must have a bucket and folders created. The invoke_test function will be executed concurrently by the PoolExecutor. This function invokes a lambda, which runs a test with a given feature name. Then it checks the result and adds it to the statistics so that we know how many tests failed and which ones.
In the end, we want to generate one Allure report. In order to do that, we need to download all .json reports, which were uploaded to the S3 bucket after each test. If we care about trends, we can also download data from the history folder. With the allure generate command and proper parameters, we are able to create a really good looking HTML report. But we can’t see it at this point. We’ll upload that report into the S3 bucket with a newly created history folder so that in the next test execution, we can compare the results. If there are no errors, our lambda will return some statistics and links after the process will end.
test_list/handler.py
def lambda_test_list(event, context):
test_cases = get_test_cases_list()
if event['action'] == 'run_tests':
tags = event['tags']
create_bucket(bucket_name=REPORTS_BUCKET)
create_folder(bucket_name=REPORTS_BUCKET, folder_name=SCREENSHOTS_FOLDER)
create_sub_folder(
bucket_name=REPORTS_BUCKET, folder_name=SCREENSHOTS_FOLDER, sub_folder_name=f'{CURRENT_DATE}/'
)
remove_s3_folder(folder_name=REPORTS_FOLDER)
create_folder(bucket_name=REPORTS_BUCKET, folder_name=REPORTS_FOLDER)
client = boto3.client(
'lambda',
region_name=REGION,
config=Config(read_timeout=900, connect_timeout=900, max_pool_connections=500)
)
stats = {'passed': 0, 'failed': 0, 'passed_tc': [], 'failed_tc': []}
def invoke_test(tc_name):
response = client.invoke(
FunctionName='lambda-test-runner-dev-lambda_runner',
InvocationType='RequestResponse',
LogType='Tail',
Payload=f'{{"tc_name": "{tc_name}", "tags": "{tags}"}}'
)
result_payload = json.loads(response['Payload'].read())
result_body = json.loads(result_payload['body'])
test_passed = bool(result_body['test_result'])
if test_passed:
stats['passed'] += 1
stats['passed_tc'].append(tc_name)
else:
stats['failed'] += 1
stats['failed_tc'].append(tc_name)
with PoolExecutor(max_workers=500) as executor:
for _ in executor.map(invoke_test, test_cases):
pass
try:
download_folder_from_bucket(bucket=REPORTS_BUCKET, dist=REPORTS_FOLDER)
download_folder_from_bucket(bucket=REPORTS_BUCKET, dist=HISTORY_FOLDER, local=TMP_REPORTS_FOLDER)
command_generate_allure_report = [
f'/opt/allure-2.10.0/bin/allure generate --clean {TMP_REPORTS_FOLDER} -o {TMP_REPORTS_ALLURE_FOLDER}'
]
subprocess.call(command_generate_allure_report, shell=True)
upload_html_report_to_s3(report_path=TMP_REPORTS_ALLURE_FOLDER)
upload_report_history_to_s3()
remove_s3_folder(REPORTS_FOLDER)
subprocess.call('rm -rf /tmp/*', shell=True)
except Exception as e:
print(f'Error when generating report: {e}')
return {
'Passed': stats['passed'],
'Failed': stats['failed'],
'Passed TC': stats['passed_tc'],
'Failed TC': stats['failed_tc'],
'Screenshots': f'https://s3.console.aws.amazon.com/s3/buckets/{REPORTS_BUCKET}/'
f'{SCREENSHOTS_FOLDER}{CURRENT_DATE}/',
'Reports': f'https://s3.console.aws.amazon.com/s3/buckets/{REPORTS_BUCKET}/'
}
else:
return test_cases
Once we have it all set, we need to deploy our code. This shouldn’t be difficult. Let’s open a command prompt in the selenium_layer directory and execute the serverless deploy command. When it’s finished, do the same thing in the ‘tests’ directory, lambda directory, and finally in the test_list directory. The order of deployment is important because they are dependent on each other.
When everything is set, let’s navigate to our test-list-lambda in the AWS console.
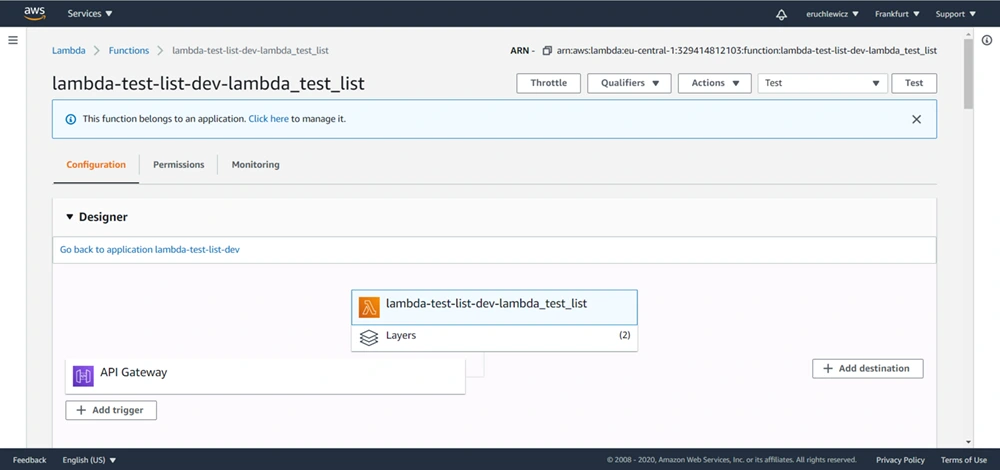
We need to create a new event. I already have three, the Test one is what we’re looking for. Click on the Configure test events option.
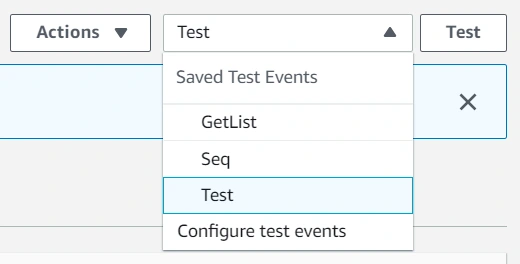
Then select an event template, an event name, and fill JSON. In the future, you can add more tags separated with a single space. Click Create to save that event.
The last step is to click the Test button and wait for the results. In our case, it took almost one minute. The longest part of our solution is generating the Allure report when all tests are finished.
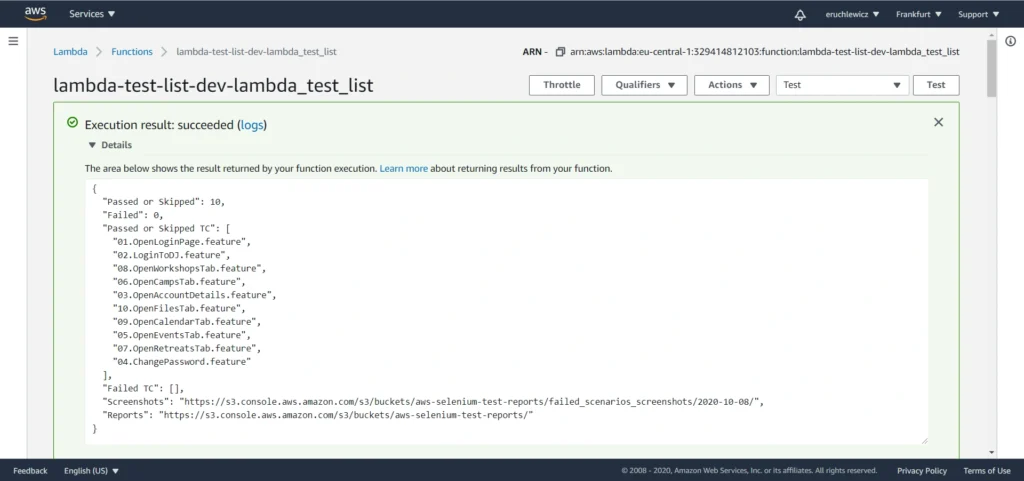
When you navigate to the reports bucket and download the latest one, you need to unpack the .zip file locally and open the index.html file in the browser. Unfortunately, most of the browsers won’t handle it that easily. If you have Allure installed, you can use the allure serve <path> command. It creates a local Jetty server instance, serves the generated report, and opens it in the default browser. But there’s also a workaround – Microsoft Edge. Just right-click on the index.html file and open it with that browser. It works!
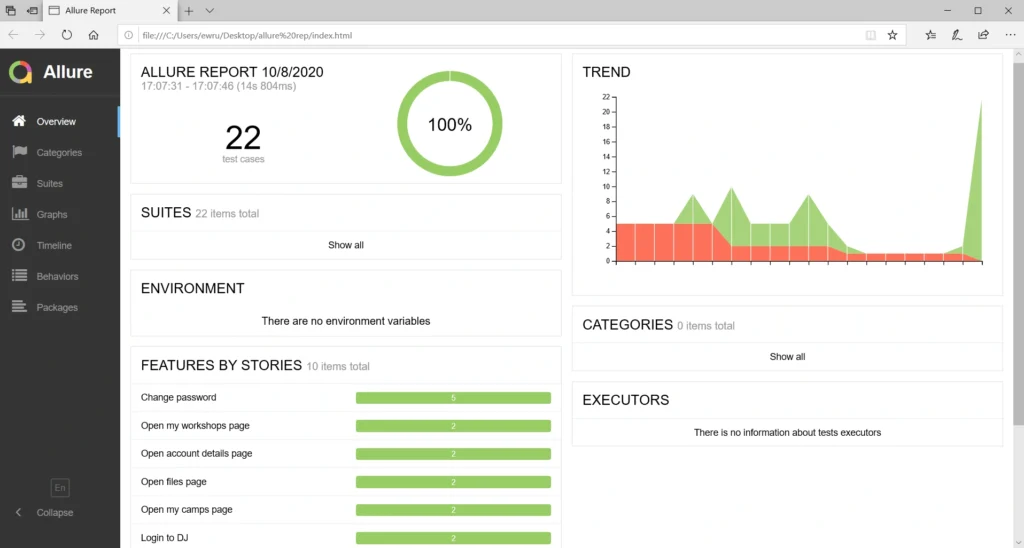
Statistics
Everybody knows that time is money. Let’s check how much we can save. Here we have a division into the duration of the tests themselves and the entire process.
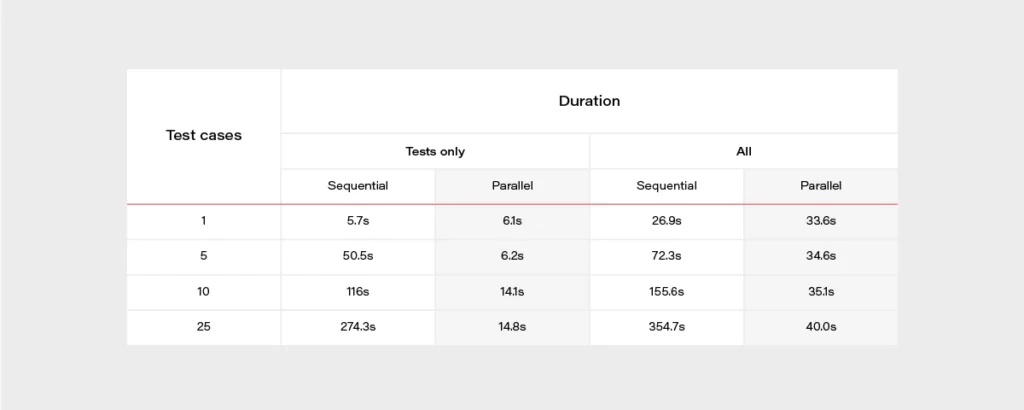
It’s really easy to find out that parallel tests are much faster. When having a set of 500 test cases, the difference is huge. It can take about 2 hours when running in a sequential approach or 2 minutes in parallel. The chart below may give a better overview.
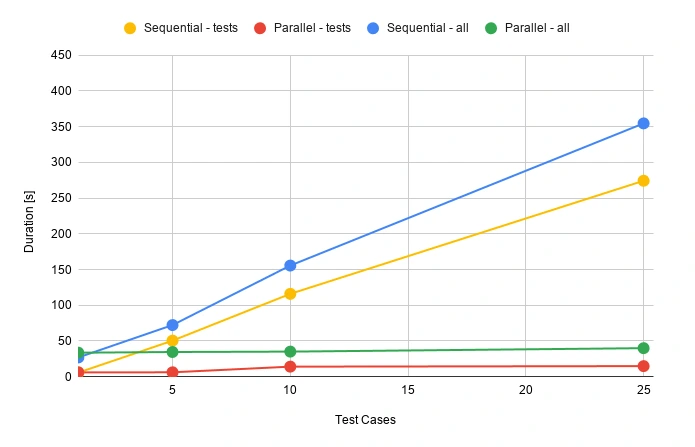
During the release, there’s usually not that much time for doing regression tests. Same with running tests that take several hours to complete. Parallel testing may speed up the whole release process.
Well, but what is the price for that convenience? Actually not that high.

Let’s assume that we have 100 feature files, and it takes 30 seconds for each one to execute. We can set a 512MB memory size for our lambda function. Tests will be executed daily in the development environment and occasionally before releases. We can assume 50 executions of each test monthly.
Total compute (seconds) = 100 * 50 * (30s) = 150,000 seconds
Total compute (GB-s) = 150,000 * 512MB/1024 = 75,000 GB-s
Monthly compute charges = 75,000 * $0.00001667 = $1.25
Monthly request charges = 100 * 50 * $0.2/M = $0.01
Total = $1.26
It looks very promising. If you have more tests or they last longer, you can double this price. It’s still extremely low!
AWS Lambda Handlers – Summary
We went through quite an extended Selenium test configuration with Behave and Allure and made it work in the parallel process using AWS Lambda to achieve the shortest time waiting for results. Everything is ready to be used with your own app, just add some tests! Of course, there is still room for improvement – reports are now available in the AWS S3 bucket but could be attached to emails or served so that anybody can display them in a browser with a URL. You can also think of CI/CD practices. It’s good to have continuous testing in the continuous integration process, e.g., when pushing some new changes to the main or release branch in your GIT repository in order to find all bugs as soon as possible. Hopefully, this article will help you with creating your custom testing process and speed up your work.
Sources
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles

