5 concourse CI tips: How to speed up your builds and pipeline development

With ever-growing IT projects, automation is nowadays a must-have. From building source code and testing to versioning and deploying, CI/CD tools were always the anonymous team member, who did the job no developer was eager to do. Today, we will take a look at some tips regarding one of the newest tools - Concourse CI. First, we will speed up our Concourse jobs, then we’ll ease the development of the new pipelines for our projects.
Aggregate your steps
By default, Concourse tasks in a job are executed separately. This is perfectly fine for small Concourse jobs that last a minute or two. It also works well at the beginning of the project, as we just want to get the process running. But at some point, it would be nice to optimize our builds.
The simplest way to save time is to start using the aggregate keyword. It runs all the steps declared inside of it in parallel. This leads to time-savings in both - script logic execution and in the overhead that occurs when starting the next task.
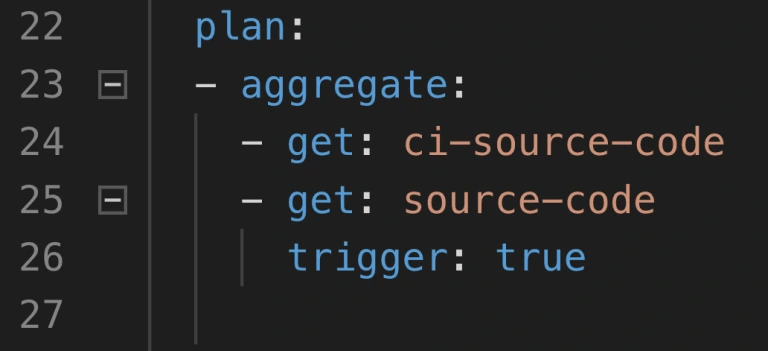
Neat, so where can we use it? There are 2 main parts of a job where the aggregation is useful:
1. Resource download and upload.
2. Tests execution.
Get and put statements are ideal targets because download and upload of resources are usually completely independent. Integration tests, contract tests, dependency vulnerabilities tests, and alike are also likely candidates if they don’t interfere with one another. Project build tasks? Probably not, because those are usually sequential and we require their output to proceed.
How much time can aggregating save? Of course, it depends. Assuming we can’t aggregate steps that build and test our code, we do get the advantage of simultaneous upload and download of our resources as well as we get less visible step-to-step overhead. We usually save up to two, maybe even three minutes. The largest saving we got was from over half an hour to below ten minutes. Most of the saved time came from running test-related tasks in parallel.
Use docker images with built-in tools
This improvement is trickier to implement but yields a noticeable build time gains. Each task runs in a container, and the image for that container has a certain set of tools available. At some point in the project comes a time where no available image has the tool required. First thing developers do is they download that tool manually or install it using a package manager as a part of the task execution. This means that the tool is fetched every time the task runs. On top of that, the console output is flooded with tool installation logs.
The solution is to prepare a custom container image that already has everything needed for a task to complete. This requires some knowledge not directly related to Concourse, but for example to Docker. With a short dockerfile and a couple of terminal commands, we get an image with the tools we need.
1. Create dockerfile.
2. Inside of the file, install or copy your tools using RUN or COPY commands.
3. Build the image using docker build.
4. Tag and push the image to the registry.
5. Change image_resource part in your Concourse task to use the new image.
That’s it, no more waiting for tools to install each time! We could even create a pipeline to build and push the image for us.
Create pipelines from a template
Moving from time-saving measures to developer convenience tips, here’s one for bigger projects. Those usually have a certain set of similar build pipelines with the only differences being credentials, service names, etc. - parameters that are not hardcoded in the pipeline script and are injected at execution time from a source like CredHub. This is typical for Cloud Foundry and Kubernetes web projects with microservices. With a little bit of creativity, we could get a bash or python script to generate those pipelines from a single template file.
First, we need to have a template file. Take one of your existing pipeline specifications and substitute parameter names with their pipeline agnostic version. Our script needs to loop over a pipeline names list, substitute generic parameter names with proper pipeline related ones that are available in Credhub and then set the pipeline in Concourse with the fly CLI.
The second part of the equation here is a Concourse job that watches for changes in the template file in a Git repository and starts the pipeline generation script. With this solution, we have to change only one file to get all pipelines updated, and on top of that, a commit to pipeline repository is sufficient to trigger the update.
Log into a task container to debug issues
When debugging Concourse task failures, the main source of information on failure is the console. A quick glance at the output is enough to solve most of the problems. Other issues may require a quick peek into the environment of an unsuccessful task. We can do that with fly intercept command.
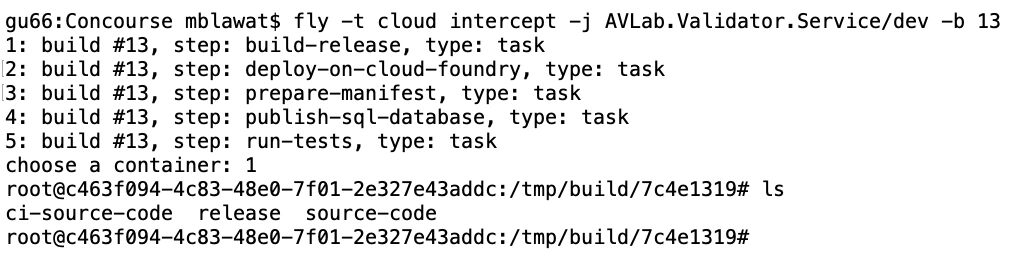
Fly intercept allows us to log into a container that executed a specific task in a specific job run. Inside we can see the state of the container when task finished and can try to find the root of failure. There may be an empty environment variable - we forgot to set the proper param in a yml file. The resource has a different structure inside of it - we need to change the task script or the resource structure. When the work is done, don’t forget to log out of the container. Oh, and don’t wait too long! Those containers can be disposed of by Concourse at any time.
Use Visual Studio Code Concourse add-on
The last thing I want to talk about is the Concourse CI Pipeline Editor for Visual Studio Code. It’s a plugin that offers suggestions, documentation popups, and error checking for Concourse yml files. If you use the pipeline template and generation task from the previous tip, then any syntax error in your template will be discovered as late as the update task updating the pipelines from the template. That’s because you won’t run fly set-pipeline yourself. Fixing such issue requires a new commit in the pipeline repository.
With the plugin, any unused resource or a typo in property name will be detected immediately. Add-on will also help you write new pieces of automation code by suggesting keywords and showing available values for Concourse commands. The only action required is to update the files.associations section in the settings. We use separate directories for pipelines and tasks, so we have set it up as follows:

Conclusion
And that’s it! We hope you have found at least one tip useful and will use it in your project. Aggregate is an easy one to implement, and it’s good to have a habit of aggregating steps from the start. Custom images and pipeline templates are beneficial in bigger projects where they help keep CI less clunky. Finally, fly intercept and the VSC add-on are just extra tools to save time during the pipeline development.

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
ASP.NET core CI/CD on Azure Pipelines with Kubernetes and Helm
Due to the high entry threshold, it is not that easy to start a journey with Cloud Native. Developing apps focused on reliability and performance, and meeting high SLAs can be challenging. Fortunately, there are tools like Istio which simplify our lives. In this article, we guide you through the steps needed to create CI/CD with Azure Pipelines for deploying microservices using Helm Charts to Kubernetes. This example is a good starting point for preparing your development process. After this tutorial, you should have some basic ideas about how Cloud Native apps should be developed and deployed .
Technology stack
- .NET Core 3.0 (preview)
- Kubernetes
- Helm
- Istio
- Docker
- Azure DevOps
Prerequisites
You need a Kubernetes cluster, free Azure DevOps account, and a docker registry. Also, it would be useful to have kubectl and gcloud CLI installed on your machine. Regarding the Kubernetes cluster, we will be using Google Kubernetes Engine from Google Cloud Platform, but you can use a different cloud provider based on your preferences. On GCP you can create a free account and create a Kubernetes cluster with Istio enabled ( Enable Istio checkbox). We suggest using a machine with 3 standard nodes.
Connecting the cluster with Azure Pipelines
Once we have the cluster ready, we have to use kubectl to prepare service account which is needed for Azure Pipelines to authenticate. First, authenticate yourself by including necessary settings in kubeconfig. All cloud providers will guide you through this step. Then following commands should be run:
kubectl create serviceaccount azure-pipelines-deploy
kubectl create clusterrolebinding azure-pipelines-deploy --clusterrole=cluster-admin --serviceaccount=default:azure-pipelines-deploy
kubectl get secret $(kubectl get secrets -o custom-columns=":metadata.name" | grep azure-pipelines-deploy-token) -o yaml
We are creating a service account, to which a cluster role is assigned. The cluster-admin role will allow us to use Helm without restrictions. If you are interested, you can read more about RBAC on Kubernetes website . The last command is supposed to retrieve secret yaml , which is needed to define connection - save that output yaml somewhere.
Now, in Azure DevOps, go to Project Settings -> Service Connections and add a new Kubernetes service connection. Choose service account for authentication and paste the yaml copied from command executed in the previous step.
One more thing we need in here is the cluster IP. It should be available at cluster settings page, or it can be retrieved via command line. In the example, for GCP command should be similar to this:
gcloud container clusters describe --format=value(endpoint) --zone
Another service connection we have to define is for docker registry. For the sake of simplicity, we will use the Docker hub, where all you need is just to create an account (if you don’t have one). Then just supply whatever is needed in the form, and we can carry on with the application part.
Preparing an application
One of the things we should take into account while implementing apps in the Cloud is the Twelve-Factor methodology. We are not going to describe them one by one since they are explained good enough here but few of them will be mentioned throughout the article.
For tutorial purposes, we’ve prepared a sample ASP.NET Core Web Application containing a single controller and database context. It also contains simple dockerfile and helm charts. You can clone/fork sample project from here . Firstly, push it to a git repository (we will use Azure DevOps), because we will need it for CI. You can now add a new pipeline, choosing any of the available YAML definitions. In here we will define our build pipeline (CI) which looks like that:
trigger:
- master
pool:
vmImage: 'ubuntu-latest'
variables:
buildConfiguration: 'Release'
steps:
- task: Docker@2
inputs:
containerRegistry: 'dockerRegistry'
repository: '$(dockerRegistry)/$(name)'
command: 'buildAndPush'
Dockerfile: '**/Dockerfile'
- task: PublishBuildArtifacts@1
inputs:
PathtoPublish: '$(Build.SourcesDirectory)/charts'
ArtifactName: 'charts'
publishLocation: 'Container'
Such definition is building a docker image and publishing it into predefined docker registry. There are two custom variables used, which are dockerRegistry (for docker hub replace with your username) and name which is just an image name (exampleApp is our case). The second task is used for publishing artifact with helm chart. These two (docker image & helm chart) will be used for the deployment pipeline.
Helm charts
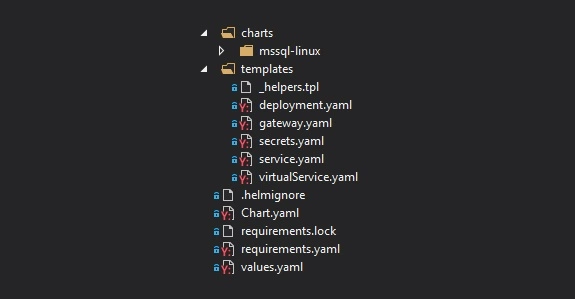
Firstly, take a look at the file structure for our chart. In the main folder, we have Chart.yaml which keeps chart metadata, requirements.yaml with which we can specify dependencies or values.yaml which serves default configuration values. In the templates folder, we can find all Kubernetes objects that will be created along with chart deployment. Then we have nested charts folder, which is a collection of charts added as a dependency in requirements.yaml. All of them will have the same file structure.
Let’s start with a focus on the deployment.yaml - a definition of Deployment controller, which provides declarative updates for Pods and Replica Sets. It is parameterized with helm templates, so you will see a lot of {{ template [...] }} in there. Definition of this Deployment itself is quite default, but we are adding a reference for the secret of SQL Server database password. We are hardcoding ‘-mssql-linux-secret’ part cause at the time of writing this article, helm doesn’t provide a straightforward way to access sub-charts properties.
env:
- name: sa_password
valueFrom:
secretKeyRef:
name: {{ template "exampleapp.name" $root }}-mssql-linux-secret
key: sapassword
As we mentioned previously, we do have SQL Server chart added as a dependency. Definition of that is pretty simple. We have to define the name of the dependency, which will match the folder name in charts subfolder and the version we want to use.
dependencies:
- name: mssql-linux
repository: https://kubernetes-charts.storage.googleapis.com
version: 0.8.0
[...]
For the mssql chart, there is one change that has to be applied in the secret.yaml . Normally, this secret will be created on each deployment ( helm upgrade ), it will generate a new sapassword - which is not what we want. The simplest way to adjust that is by modifying metadata and adding a hook on pre-install. This will guarantee that this secret will be created just once on installing the release.
metadata:
annotations:
"helm.sh/hook": "pre-install"
A deployment pipeline
Let’s focus on deployment now. We will be using Helm to install and upgrade everything that will be needed in Kubernetes. Go to the Releases pipelines on the Azure DevOps, where we will configure continuous delivery. You have to add two artifacts, one for docker image and second for charts artifact. It should look like on the image below.
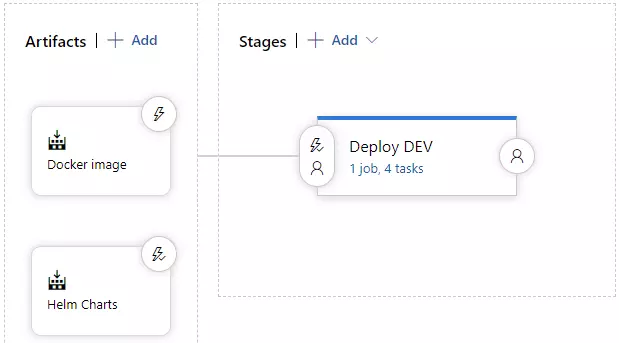
On the stages part, we could add a few more environments, which would get deployed in a similar manner, but to a different cluster. As you can see, this approach guarantees Deploy DEV stage is simply responsible for running a helm upgrade command. Before that, we need to install helm, kubectl and run helm init command.
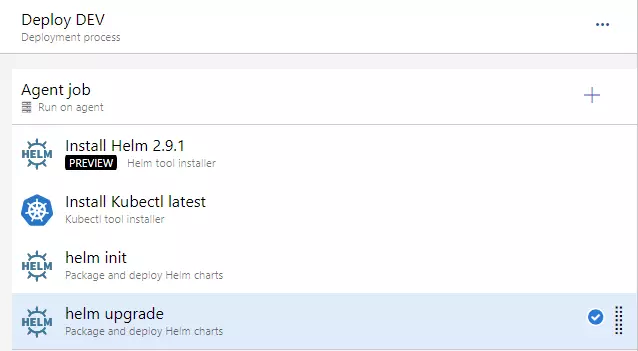
For the helm upgrade task, we need to adjust a few things.
- set Chart Path, where you can browse into Helm charts artifact (should look like: “$(System.DefaultWorkingDirectory)/Helm charts/charts”)
- paste that “image.tag=$(Build.BuildNumber)” into Set Values
- and check to Install if release not present or add --install ar argument. This will behave as helm install if release won’t exist (i.e. on a clean cluster)
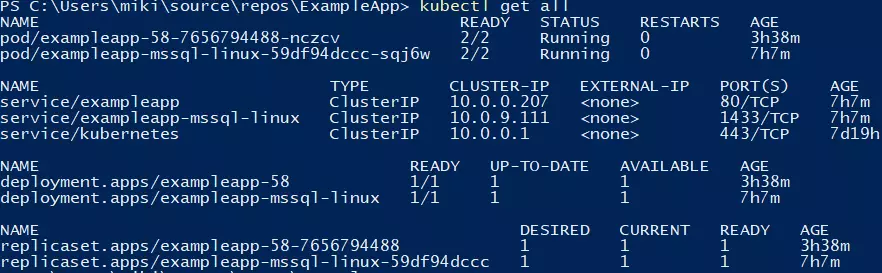
At this point, we should be able to run the deployment application - you can create a release and run deployment. You should see a green output at this point :).
You can verify if the deployment went fine by running a kubectl get all command.
Making use of basic Istio components
Istio is a great tool, which simplifies services management. It is responsible for handling things like load balancing, traffic behavior, metric & logs, and security. Istio is leveraging Kubernetes sidecar containers, which are added to pods of our applications. You will have to enable this feature by applying an appropriate label on the namespace.
kubectl label namespace default istio-injection=enabled
All pods which will be created now will have an additional container, which is called a sidecar container in Kubernetes terms. That’s a useful feature, cause we don’t have to modify our application.
Two objects that we are using from Istio, which are part of the helm chart, are Gateway and VirtualService . For the first one, we will bring Istio definition, because it’s simple and accurate: “Gateway describes a load balancer operating at the edge of the mesh receiving incoming or outgoing HTTP/TCP connections”. That object is attached to the LoadBalancer object - we will use the one created by Istio by default. After the application is deployed, you will be able to access it using LoadBalancer external IP, which you can retrieve with such command:
kubectl get service/istio-ingressgateway -n istio-system
You can retrieve external IP from the output and verify if http://api/examples url works fine.
Summary
In this article, we have created a basic CI/CD which deploys single service into Kubernetes cluster with the help of Helm. Further adjustments can include different types of deployment, publishing tests coverage from CI or adding more services to mesh and leveraging additional Istio features. We hope you were able to complete the tutorial without any issues. Follow our blog for more in-depth articles around these topics that will be posted in the future.
Using Azure DevOps Platform for configurable builds of a multicomponent iOS application
In this article, we share our experience with building CI/CD for a multicomponent multi-language project. The article describes the structure of the pipeline set up and focuses on two important features needed in our project’s automation workflow: pipeline chaining and build variants.
The CI/CD usage is a standard in any application development process . Mobile apps are no exception here.
In our project, we have several iOS applications and libraries. Each application uses several components (frameworks) written in different languages. The components structure is as in the picture below:
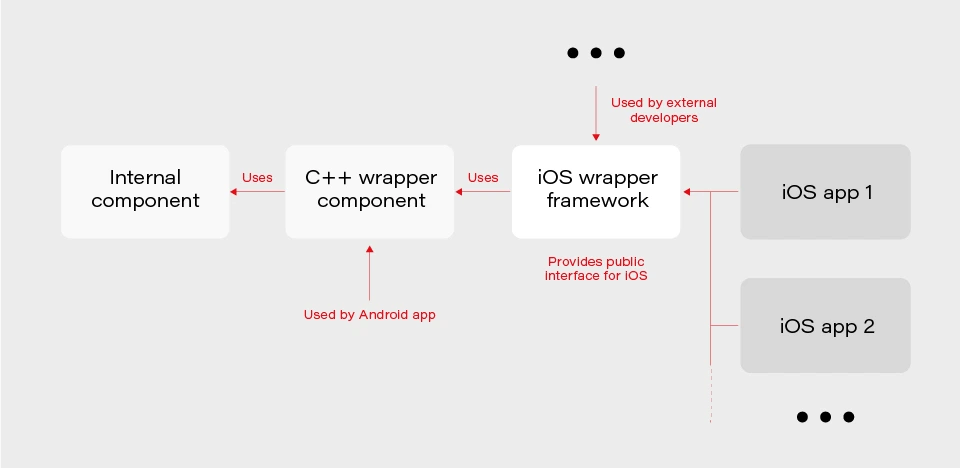
The internal component contains all the core (domain) logic that apps use. The first two components are C/C++ based and are compiled as frameworks. The wrapper framework provides an Objective-C/Swift layer that is necessary for using it in an iOS application. There are several iOS applications that are using the wrapper framework. Additionally, this framework is also used by external developers in their own applications.
The wrapper framework should be built for both x86_64 and arm64 architecture to be used on both a simulator and a real iOS device. Also, we need a debug and release version for each architecture. When it comes to applications each of them may be built for AppStore, internal testing (Ad-Hoc) or TestFlight beta testing.
Without an automated CI/CD system, it would be extremely inefficient to build the whole chain of components manually. As well as to track the status of merges/pull requests for each component. That is to control if the component is still building after the merge. Let’s see how our pipelines are organized.
Using Azure DevOps pipelines
For building CI/CD, we’ve chosen Azure DevOps. We use Azure Pipelines for building our components and Azure Artifacts to host the built components, as well as several external 3rd party libraries.
To check the integrity and track the build status of each component, we have special integration pipelines that are integrated with GitHub. That is, each pull request that is going to be merged to the development branch of a particular component triggers this special integration pipeline.
For regular builds, we have pipelines based on the purpose of each branch type: experimental, feature, bugfix, development, and master.
Since each component depends on another component built on Azure, we should somehow organize the dependency management. That is versioning of the dependent components and their download. Let’s take a look at our approach to dependency management.
Dependency management
Azure provides basic CLI tools to manipulate pipelines. We may use it to download dependencies (inform of Azure artifacts) required to build a particular component. At a minimum, we need to know the version, configuration (debug or release) and architecture (x86_64 or arm64) of a particular dependency. Let’s take a look at the options that Azure CLI gives us:
az artifacts universal download \
--organization "${Organization}" \
--feed "${Feed}" \
--name "${Name}" \
--version "${Version}" \
--path "${DownloadPath}"
The highlighted parameters are the most important for us. The CLI does not provide explicit support of build configuration or architecture. For this purpose, we simply use the name (specified as --name parameter) that has a predefined format:
<component name>-<configuration>-<architecture>
This makes it possible to have components of the same version with different architecture and build configurations.
The other aspect is how to store info about version, configuration, etc., for each dependency. We’ve decided to use the git config format to store this info. It’s pretty easy to parse using git config and does not require any additional parsing tool. So, each component has its own dependencies.config file. Below is the example file for component dependent on two frameworks:
[framework1]
architecture = "arm64"
configuration = "release"
version = "1.2.3.123"[framework2]
architecture = "arm64"
configuration = "release"
version = "3.2.1.654"
To make it possible to download dependencies as part of the build process, we have a special script that manages dependencies. The script is run as a build phase of the Xcode project of each component. Below are the basic steps the script does.
1. Parse dependencies.config file to get version, architecture, and configuration. The important thing here is that if some info is omitted (e.g. we may not specify build configuration in dependencies.config file) script will use the one the dependent component is being built with. That is, when we build the current component for the simulator script will download dependencies of simulator architecture.
2. Form artifact’s name and version and forward them to az artifacts universal download command .
There are two key features of our build infrastructure: pipeline chaining and build variants support. They cover two important cases in our project. Let’s describe how we implemented them.
Chaining pipelines
When a low-level core component is updated, we want to test these changes in the application. For this purpose, we should build the framework dependent on the core component and build the app using this framework. Automation here is extremely useful. Here’s how it looks like with our pipelines.
1. When a low-level component (let’s call it component1 ) is changed on a specific branch (e.g., integration), a special integration pipeline is triggered. When a component is built and an artifact is published, the pipeline starts another pipeline that will build the next dependent component. For this purpose, az pipelines build queue command is used as follows:
az pipelines build queue \
--project "component2" \
--branch "integration" \
--organization "${Organization}" \
--definition-name "${BuildDefinition}" \
--variables \
"config.pipeline.component1Version=${BUILD_BUILDNUMBER}" \
“config.pipeline.component1Architecture=${CurrentArchitecture}" \
"config.pipeline.component1Configuration=${CurrentConfiguration}"
This command starts the pipeline for building component2 (the one dependent on component1 ).
The key part is passing the variables config.pipeline.component1 Version, config.pipeline.component1Architecture and config.pipeline.component1Configuration to the pipeline. These variables define the version, build configuration, and architecture of component1 (the one being built by the current pipeline) that should be used to build component2 . The command overrides the corresponding values from dependencies.config file of component2 . This means that the resulting component2 will use newly built component1 dependency instead of the one defined by dependencies.config file.
2. When component2 is built, it uses the same approach to launch the next pipeline for building a subsequent component.
3. When all the components in the chain required by the app are ready, the integration pipeline building the app is launched. As a part of its build process, the app is sent to TestFlight.
So, simply pushing changes of the lowest level component to the integration branch gives you a ready-to-test app on TestFlight.
Build variants
Some external developers that use the wrapper iOS framework may need additional features that should not be available in regular public API intended for other developers. This brings us to the need of having different variants of the same component. Such variants may be distinct in different features, or in behavior of the same features.
Additional methods or classes may be provided as a specific or experimental API in a wrapper framework for iOS. The other use case is to have behavior different than the default one for regular (official) public API in the wrapper framework. For instance, a method that writes an image file to a specified directory in some cases may be required to also write additional files along with the image (e.g., file with image processing settings or metadata).
Going further, an implementation may be changed not only in the iOS framework itself but also in its dependencies. As described previously, core logic is implemented in a separate component and iOS framework is dependent on. So, when some code behavior change is required by a particular build variant, most likely it will also be done in the internal component.
Let’s see how to better implement build variants. The proper understanding of use cases and potential extension capabilities are crucial for choosing the correct solution.
The first important thing is that in our project different build variants have few changes in API compared to each other. Usually, a build variant contains a couple of additional methods or classes. Most part of the code is the same for all variants. Inside implementation, there also may be some distinctions based on the concrete variant we’re building. So, it would be enough to have some preprocessor definition (active compilation conditions for Swift) indicating which build variant is being built.
The second thing is that the number of build variants is often changed. Some may be removed, (e.g., when an experimental API becomes generally accessible.) On the other hand, when an external developer requests another specific functionality, we need to create a new variant by slightly modifying the standard implementation or exposing some experimental/internal API. This means that we should be able to add or remove build variants fast.
Let’s now describe our implementation based on the specifics given above. There are two parts of the implementation. The first one is at the pipeline level.
Since we may often add/remove our build variants, creating a pipeline for each build variant is obviously not a good idea. Instead, we add a special variable config.pipeline.buildVariant in the pipeline’s Variables to each pipeline that is supposed to be used for building different variants. The variable should be added to pipelines of all the components the resulting iOS framework depends on because a specific feature often requires code changes, not only in the iOS framework itself but also in its dependencies. Pipeline implementation then will use this variable e.g., for downloading specific dependencies required by a particular variant, tagging build to indicate the variant, and, of course, providing the corresponding build setting to Xcode build command.
The second part is a usage of the build variant setting provided by the pipeline inside the Xcode project. Using Xcode build settings we’re adding a compile-time constant (preprocessor definition for Objective C/C++ code and compilation conditions for Swift) that reflect the selected build variant. It is used to control which functionality to compile. This build settings may also be used to choose to build variant-specific resources to be embedded into the framework.
When chaining pipelines we just pass the variable to next pipeline:
az pipelines build queue \
--project "component2" \
--branch "integration" \
--organization "${Organization}" \
--definition-name "${BuildDefinition}" \
--variables \
"config.pipeline.component1Version=${BUILD_BUILDNUMBER}" \
"config.pipeline.component1Architecture=${CurrentArchitecture}" \
"config.pipeline.component1Configuration=${CurrentConfiguration}" \
“config.pipeline.buildVariant=${CONFIG_PIPELINE_BUILDVARIANT}"
Summary
In this article, we’ve described our approach to multi-component app CI/CD infrastructure based on Azure . We’ve focused on two important features of our build infrastructure: chaining component builds and building different variants of the same component. It’s worth mentioning that the described solution is not the only correct one. It's rather the most optimal that fits our needs. You may experiment and try different approaches utilizing a flexible developed pipeline system that Azure provides.
Interested in our services?
Reach out for tailored solutions and expert guidance.