Unleashing the full potential of MongoDB in automotive applications

Welcome to the second part of our article series about MongoDB in automotive. In the previous installment , we explored the power of MongoDB as a versatile data management solution for the automotive industry, focusing on its flexible data model, scalability, querying capabilities, and optimization techniques.
In this continuation, we will delve into two advanced features of MongoDB that further enhance its capabilities in automotive applications: timeseries data management and change streams. By harnessing the power of timeseries and change streams, MongoDB opens up new possibilities for managing and analyzing real-time data in the automotive domain. Join us as we uncover the exciting potential of MongoDB's advanced features and their impact on driving success in automotive applications.
Time-series data management in MongoDB for automotive
Managing time-series data effectively is a critical aspect of many automotive applications. From sensor data to vehicle telemetry, capturing and analyzing time-stamped data is essential for monitoring performance, detecting anomalies, and making informed decisions. MongoDB offers robust features and capabilities for managing time-series data efficiently. This section will explore the key considerations and best practices for leveraging MongoDB's time-series collections.
Understanding time-series collections
Introduced in MongoDB version 5.0, time-series collections provide a specialized data organization scheme optimized for storing and retrieving time-series data. Time-series data consists of a sequence of data points collected at specific intervals, typically related to time. This could include information such as temperature readings, speed measurements, or fuel consumption over time.
MongoDB employs various optimizations in a time-series collection to enhance performance and storage efficiency. One of the notable features is the organization of data into buckets. Data points within a specific time range are grouped in these buckets. This time range, often referred to as granularity, determines the level of detail or resolution at which data points are stored within each bucket. This bucketing approach offers several advantages.
Firstly, it improves query performance by enabling efficient data retrieval within a particular time interval. With data organized into buckets, MongoDB can quickly identify and retrieve the relevant data points, reducing the time required for queries.
Secondly, bucketing allows for efficient storage and compression of data within each bucket. By grouping data points, MongoDB can apply compression techniques specific to each bucket, optimizing disk space utilization. This helps to minimize storage requirements, especially when dealing with large volumes of time-series data.
Choosing sharded or non-sharded collections
When working with time-series data, you have the option to choose between sharded and non-sharded collections. Sharded collections distribute data across multiple shards, enabling horizontal scalability and accommodating larger data volumes. However, it's essential to consider the trade-offs associated with sharding. While sharded collections offer increased storage capacity, they may introduce additional complexity and potentially impact performance compared to non-sharded collections.
In most cases, non-sharded collections are sufficient for managing time-series data, especially when proper indexing and data organization strategies are employed. Non-sharded collections provide simplicity and optimal performance for most time-series use cases, eliminating the need for managing a sharded environment.
Effective data compression for time-series collections
Given the potentially large volumes of data generated by time-series measurements, efficient data compression techniques are crucial for optimizing storage and query performance. MongoDB provides built-in compression options that reduce data size, minimizing storage requirements and facilitating faster data transfer. Using compression, MongoDB significantly reduces the disk space consumed by time-series data while maintaining fast query performance.
One of the key compression options available in MongoDB is the WiredTiger storage engine. WiredTiger offers advanced compression algorithms that efficiently compress and decompress data, reducing disk space utilization. This compression option is particularly beneficial for time-series collections where data points are stored over specific time intervals.
By leveraging WiredTiger compression, MongoDB achieves an optimal balance between storage efficiency and query performance for time-series collections. The compressed data takes up less space on disk, resulting in reduced storage costs and improved overall system scalability. Additionally, compressed data can be transferred more quickly across networks, improving data transfer speeds and reducing network bandwidth requirements.
Considerations for granularity and data retention
When designing a time-series data model in MongoDB, granularity and data retention policies are important factors to consider. Granularity refers to the level of detail or resolution at which data points are stored, while data retention policies determine how long the data is retained in the collection.
Choosing the appropriate granularity is crucial for striking a balance between data precision and performance. MongoDB provides different granularity options, such as "seconds," "minutes," and "hours," each covering a specific time span. Selecting the granularity depends on the time interval between consecutive data points that have the same unique value for a specific field, known as the meta field. You can optimize storage and query performance by aligning the granularity with the ingestion rate of data from a unique data source.
For example, if you collect temperature readings from weather sensors every five minutes, setting the granularity to "minutes" would be appropriate. This ensures that data points are grouped in buckets based on the specified time span, enabling efficient storage and retrieval of time-series data.
In addition to granularity, defining an effective data retention policy is essential for managing the size and relevance of the time-series collection over time. Consider factors such as the retention period for data points, the frequency of purging outdated data, and the impact on query performance.
MongoDB provides a Time to Live (TTL) mechanism that can automatically remove expired data points from a time-series collection based on a specified time interval. However, it's important to note that there is a known issue related to TTL for very old records in MongoDB at the time of writing this article. The issue is described in detail in the MongoDB Jira ticket SERVER-76560.
The TTL behavior in time series collections differs from regular collections. In a time series collection, TTL expiration occurs at the bucket level rather than on individual documents within the bucket. Once all documents within a bucket have expired, the entire bucket is removed during the next run of the background task that removes expired buckets.
This bucket-level expiration behavior means that TTL may not work in the exact same way as with normal collections, where individual documents are removed as soon as they expire. It's important to be aware of this distinction and consider it when designing your data retention strategy for time series collections.
When considering granularity and data retention policies, evaluate the specific requirements of your automotive application. Consider the level of precision needed for analysis, the data ingestion rate, and the desired storage and query performance. By carefully evaluating these factors and understanding the behavior of TTL in time series collections, you can design a time-series data model in MongoDB that optimizes both storage efficiency and query performance while meeting your application's needs.
Retrieving latest documents
In automotive applications, retrieving the latest documents for each unique meta key can be a common requirement. MongoDB provides an efficient approach to achieve this using the `DISTINCT_SCAN` stage in the aggregation pipeline. Let's explore how you can use this feature, along with an automotive example.
The `DISTINCT_SCAN` stage is designed to perform distinct scans on sorted data in an optimized manner. By leveraging the sorted nature of the data, it efficiently speeds up the process of identifying distinct values.
To illustrate its usage, let's consider a scenario where you have a time series collection of vehicle data that includes meta information and timestamps. You want to retrieve the latest document for each unique vehicle model. Here's an example code snippet demonstrating how to accomplish this:
```javascript
db.vehicleData.aggregate([
{ $sort: { metaField: 1, timestamp: -1 } },
{
$group: {
_id: "$metaField",
latestDocument: { $first: "$$ROOT" }
}
},
{ $replaceRoot: { newRoot: "$latestDocument" } }
])
```
In the above code, we first use the `$sort` stage to sort the documents based on the `metaField` field in ascending order and the `timestamp` field in descending order. This sorting ensures that the latest documents appear first within each group.
Next, we employ the `$group` stage to group the documents by the `metaField` field and select the first document using the `$first` operator. This operator retrieves the first document encountered in each group, corresponding to the latest document for each unique meta key.
Finally, we utilize the `$replaceRoot` stage to promote the `latestDocument` to the root level of the output, effectively removing the grouping and retaining only the latest documents.
By utilizing this approach, you can efficiently retrieve the latest documents per each meta key in an automotive dataset. The `DISTINCT_SCAN` stage optimizes the distinct scan operation, while the `$first` operator ensures accurate retrieval of the latest documents.
It's important to note that the `DISTINCT_SCAN` stage is an internal optimization technique of MongoDB's aggregation framework. It is automatically applied when the conditions are met, so you don't need to specify or enable it in your aggregation pipeline explicitly.
Time series collection limitations
While MongoDB Time Series brings valuable features for managing time-series data, it also has certain limitations to consider. Understanding these limitations can help developers make informed decisions when utilizing MongoDB for time-series data storage:
● Unsupported Features : Time series collections in MongoDB do not support certain features, including transactions and change streams. These features are not available when working specifically with time series data.
● A ggregation $out and $merge : The $out and $merge stages of the aggregation pipeline, commonly used for storing aggregation results in a separate collection or merging results with an existing collection, are not supported in time series collections. This limitation affects the ability to perform certain aggregation operations directly on time series collections.
● Updates and Deletes : Time series collections only support insert operations and read queries. This means that once data is inserted into a time series collection, it cannot be directly modified or deleted on a per-document basis. Any updates or manual delete operations will result in an error.
MongoDB change streams for real-time data monitoring
MongoDB Change Streams provide a powerful feature for real-time data monitoring in MongoDB. Change Streams allow you to capture and react to any changes happening in a MongoDB collection in a real-time manner. This is particularly useful in scenarios where you need to track updates, insertions, or deletions in your data and take immediate actions based on those changes.
Change Streams provide a unified and consistent way to subscribe to the database changes, making it easier to build reactive applications that respond to real-time data modifications.
```javascript
// MongoDB Change Streams for Real-Time Data Monitoring
const MongoClient = require('mongodb').MongoClient;
// Connection URL
const url = 'mongodb://localhost:27017';
// Database and collection names
const dbName = 'mydatabase';
const collectionName = 'mycollection';
// Create a change stream
MongoClient.connect(url, function(err, client) {
if (err) throw err;
const db = client.db(dbName);
const collection = db.collection(collectionName);
// Create a change stream cursor with filtering
const changeStream = collection.watch([{ $match: { operationType: 'delete' } }]);
// Set up event listeners for change events
changeStream.on('change', function(change) {
// Process the delete event
console.log('Delete Event:', change);
// Perform further actions based on the delete event
});
// Close the connection
// client.close();
});
```
In this updated example, we use the `$match` stage in the change stream pipeline to filter for delete operations only. The `$match` stage is specified as an array in the `watch()` method. The `{ operationType: 'delete' }` filter ensures that only delete events will be captured by the change stream.
Now, when a delete operation occurs in the specified collection, the `'change'` event listener will be triggered, and the callback function will execute. Inside the callback, you can process the delete event and perform additional actions based on your application's requirements. It's important to note that the change stream will only provide the document ID for delete operations. The actual content of the document is no longer available. If you need the document content, you need to retrieve it before the delete operation or store it separately for reference.
One important aspect to consider is related to the inability to distinguish whether a document was removed manually or due to the Time to Live (TTL) mechanism. Change streams do not provide explicit information about the reason for document removal. This means that when a document is removed, the application cannot determine if it was deleted manually by a user or automatically expired through the TTL mechanism. Depending on the use case, it may be necessary to implement additional logic or mechanisms within the application to handle this distinction if it is critical for the business requirements.
Here are some key aspects and benefits of using MongoDB Change Streams for real-time data monitoring:
● Real-Time Event Capture : Change Streams allow you to capture changes as they occur, providing a real-time view of the database activity. This enables you to monitor data modifications instantly and react to them in real-time.
● Flexibility in Filtering : You can specify filters and criteria to define the changes you want to capture. This gives you the flexibility to focus on specific documents, fields, or operations and filter out irrelevant changes, optimizing your monitoring process.
● Data Integration and Pipelines : Change Streams can be easily integrated into your existing data processing pipelines or applications. You can consume the change events and perform further processing, transformation, or analysis based on your specific use case.
● Scalability and High Availability : Change Streams are designed to work seamlessly in distributed and sharded MongoDB environments. They leverage the underlying replica set architecture to ensure high availability and fault tolerance, making them suitable for demanding and scalable applications.
● Event-Driven Architecture : Using Change Streams, you can adopt an event-driven architecture for your MongoDB applications. Instead of continuously polling the database for changes, you can subscribe to the change events and respond immediately, reducing unnecessary resource consumption.
MongoDB Change Streams provide a powerful mechanism for real-time data monitoring, enabling you to build reactive, event-driven applications and workflows. By capturing and processing database changes in real-time, you can enhance the responsiveness and agility of your applications, leading to improved user experiences and efficient data processing.
Another consideration is that low-frequency events may lead to an invalid resume token. Change streams rely on a resume token to keep track of the last processed change. In cases where there are long periods of inactivity or low-frequency events, the resume token may become invalid or expired. Therefore, the application must handle this situation gracefully and take appropriate action when encountering an invalid resume token. This may involve reestablishing the change stream or handling the situation in a way that ensures data integrity and consistency.
It's important to note that while Change Streams offer real-time monitoring capabilities, they should be used judiciously, considering the potential impact on system resources. Monitoring a large number of collections or frequently changing data can introduce additional load on the database, so it's essential to carefully design and optimize your Change Streams implementation to meet your specific requirements.
Conclusion
By harnessing the capabilities of MongoDB, developers can unlock a world of possibilities in modern application development. From its NoSQL model to efficient time-series data management, batch writes, data retrieval, and real-time monitoring with Change Streams, MongoDB provides a powerful toolkit. By following best practices and understanding its limitations, developers can maximize the potential of MongoDB, resulting in scalable, performant, and data-rich applications.
MongoDB can be likened to a Swiss Army Knife in the world of database systems, offering a versatile set of features and capabilities. However, it is important to note that MongoDB is not a one-size-fits-all solution for every use case. This article series aim to showcase the capabilities and potential use cases of MongoDB.
While MongoDB provides powerful features like time-series data management and change streams for real-time data monitoring, it is essential to consider alternative solutions as well. Depending on factors such as team skills, the company-adopted tools, and specific project requirements, exploring other options like leveraging IaaS provider-native solutions such as DynamoDB for specific use cases within the automotive domain may be worthwhile.
Furthermore, it is important to highlight that both articles focused on using MongoDB in automotive primarily for hot storage, while the aspect of cold storage for automotive applications is not covered.
When starting a new project, it is crucial to conduct thorough research, consider the specific requirements, and evaluate the available options in the market. While MongoDB may provide robust features for certain scenarios, dedicated time-series databases like InfluxDB may offer a more tailored and specialized solution for specific time-series data needs. Choosing the right tool for the job requires careful consideration and an understanding of the trade-offs and strengths of each option available.

Data powertrain in automotive: Complete end-to-end solution
We power your entire data journey, from signals to solutions
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
How to choose a technological partner to develop data-driven innovation
Insurance companies, especially those focused on life and car insurance, in their offers are placing more and more emphasis on big data analytics and driving behavior-based propositions. We should expect that this trend will only gain ground in the future. And this raises further questions. For instance, what should be taken into account when choosing a technological partner for insurance-technology-vehicle cooperation?
Challenges in selecting a technology partner
The potential of telematics insurance programs encourages auto insurers to move from traditional car insurance and build a competitive advantage on collected data.
No wonder technology partners are sought to support and develop increasingly innovative projects. Such synergistic collaboration brings tangible benefits to both parties.
As we explained in the article How to enable data-driven innovation for the mobility insurance , the right technology partner will ensure:
- data security;
- cloud and IoT technology selection;
- the reliability and scalability of the proposed solutions.
Finding such a partner, on the other hand, is not easy, because it must be a company that efficiently navigates in as many as three areas: AI/cloud technology, automotive, and insurance . You need a team of specialists who operate naturally in the software-defined vehicle ecosystem , and who are familiar with the characteristics of the P&C insurance market and the challenges faced by insurance clients.
Aim for the cloud. The relevance of AI and data collection and analytics technologies
Information is the most important asset of the 21st century. The global data collection market in 2021 was valued at $1.66 billion. No service based on the Internet of Things and AI could operate without a space to collect and analyze data. Therefore, the ideal insurance industry partner must deliver proprietary and field-tested cloud solutions . And preferably those that are dependable. Cloud services offered these days by insurance partners include:
- cloud R&D,
- cloud and edge computing,
- system integration,
- software engineering,
- cloud platforms development.
Connectivity between the edge device and the cloud must be stable and fast. Mobility devices often operate in limited connectivity conditions, therefore car insurance businesses should leverage multiple methods to ensure an uninterrupted connection. Dynamic switching of cellular, satellite, and Wi-Fi communications combined with globally distributed cloud infrastructure results in reliable transmission and low latency.
A secure cloud platform is capable of handling an increasing number of connected devices and providing them all with the required APIs while maintaining high observability.
As a result, the data collected is precise, valid, and reliable . They provide full insight into what is happening on the road, allowing you to better develop insurance quotes. No smart data-driven automation is possible without it.
Data quality, on the other hand, also depends on the technologies implemented inside the vehicle ( which we will discuss further below) and on all intermediate devices, such as the smartphone. The capabilities of a potential technology partner must therefore reach far beyond basic IT skills and most common technologies.
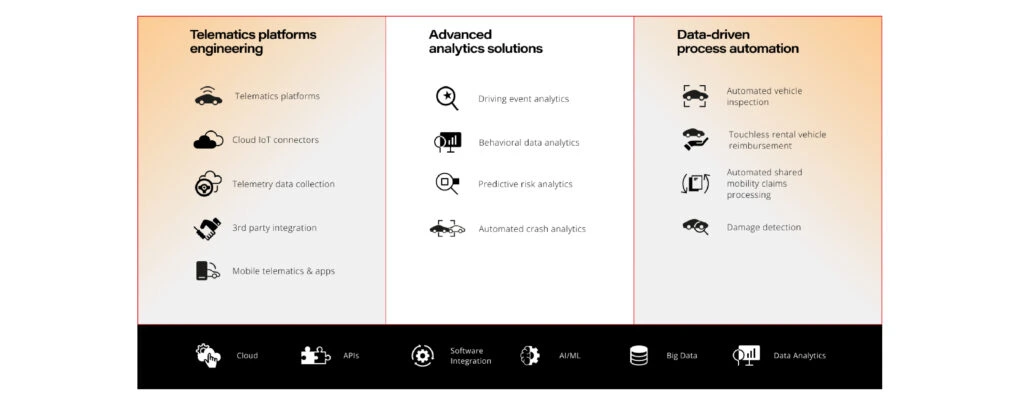
Telemetry data collection
Obviously, data acquisition and collection is not enough, because information about what is happening on the road, usage and operation of components in itself is just a "record on paper". But to make such a project a reality, you still need to implement advanced analytical tools and telematics solutions.
Real-time data streaming from telematics devices, mobile apps, and connected car systems gives access to driving data, driver behavior analysis, and car status. It enables companies to provide insurance policies based on customer driving habits .
Distributed AI
AI models are an integral part of modern vehicles. They predict front and rear collision, control damping of the suspension based on the road ahead, recognize road signs, or lanes. Modern infotainment applications suggest routes and settings depending on driver behavior and driving conditions.
Empowering the automotive industry to build software-defined vehicles. Automotive aspect
Today it is necessary to take into consideration a strategy towards modern, software-defined vehicles. According to Daimler AG, this can be expressed by the letters “CASE”:
- C onnected.
- A utonomous
- S hared.
- E lectric.
This idea means the major focus is going to be put on making the cars seamlessly connected to the cloud, support or advancements in autonomous driving based on electric power.
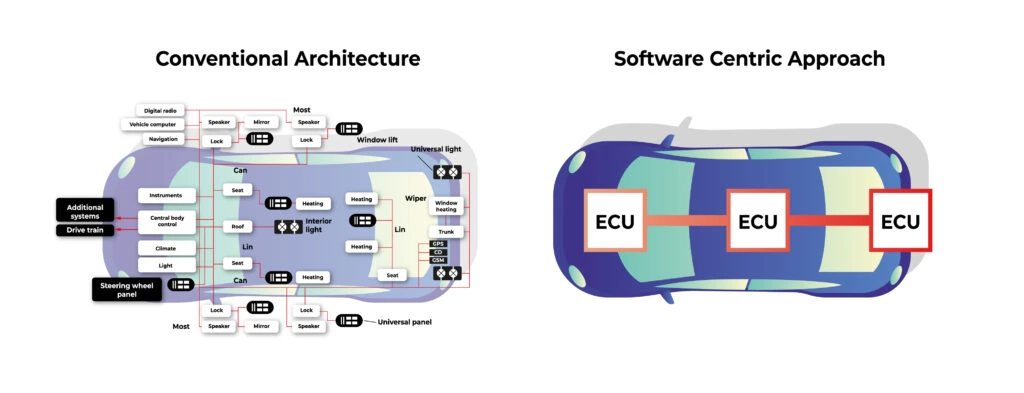
Digitalization and evolution of the computer hardware caused a natural evolution of the vehicle. New SoC’s (System on a Chip, integrated board containing CPU, memory, and peripherals) are multipurpose and powerful enough to handle not just a single task but multiple, simultaneously. It would not be an exaggeration to say that the cars of the future are smart spaces that combine external solutions (e.g. cloud computing, 5G) with components that work internally (IoT sensors). Technology solution providers must therefore work in two directions, understanding the specifics of both these ecosystems. Today, they cannot be separated.
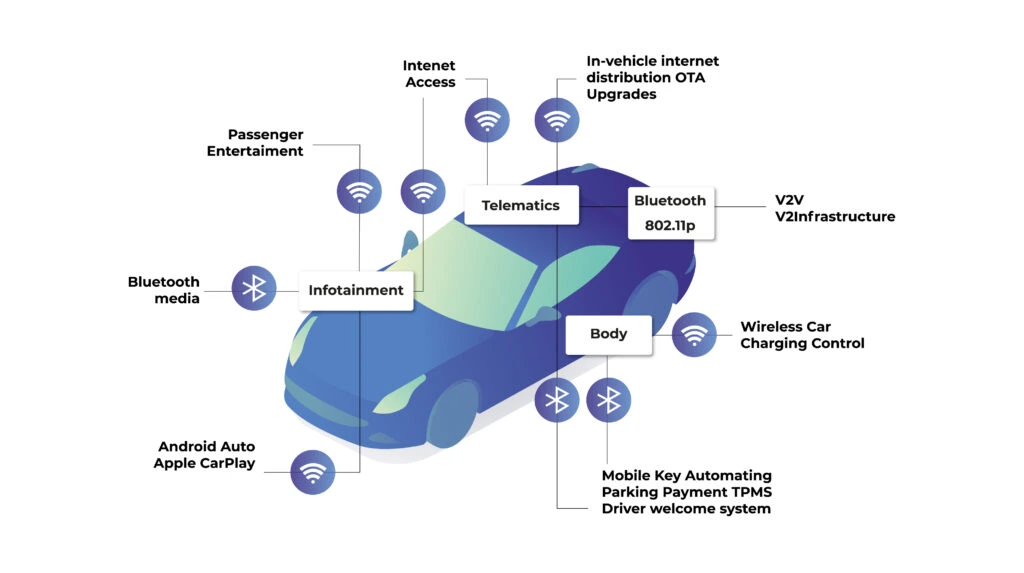
The partner must be able to operate at the intersection of cloud technologies, AI and telemetry data collection. Ideally, they should know how these technologies can be practically used in the car. Such a service provider should also be aware of the so-called bottlenecks and potential discrepancies between the actual state and the results of the analysis. This knowledge comes from experience and implementation of complex software-defined vehicle projects.
Enabling data-driven innovation for mobility insurance. Insurance context
There are companies on the market that are banking on the innovative combination of automotive and automation. Although you have to separate the demand of OEMs and drivers from the demand of the insurance industry.
It's vital that the technology partner chosen by an insurance company is aware of this. This, naturally, involves experience supported by a portfolio for similar clients and specific industry know-how. The right partner will understand the insurer's expectations and correctly define their needs, combining them with the capabilities of a software-defined vehicle .
From an insurer's standpoint, the key solutions will be the following:
- Roadside assistance . For accurately determining the location of an emergency (this is important when establishing the details of an incident with conflicting stakeholders’ versions).
- Crash detection. To take proactive measures geared toward mitigating the consequences.
- UBI and BBI. The data gathered from mobile devices, plug-in dongles, or the vehicle embedded onboard systems can be processed and used to build risk profiles and tailored policies based on customers’ driving styles and patterns.
Technology and safety combined
The future of technology-based insurance policies is just around the corner. Simplified roadside assistance, drive safety support, stolen vehicle identification, personalized driving feedback, or crash detection- all of these enhance service delivery, benefit customers, and increase profitability in the insurance industry.
Once again, it is worth highlighting that the real challenge, as well as opportunity, is to choose a partner that can handle different, yet consistent, areas of expertise.
If you also want to develop data-driven innovation in your insurance company, contact GrapeUp. Browse our portfolio of automo tive & insurance projects .
Interested in our services?
Reach out for tailored solutions and expert guidance.