Steps to successful application troubleshooting in a distributed cloud environment

At Grape Up, when we execute digital transformation, we need to take care of a lot of things. First of all, we need to pick a proper IaaS that meets our needs such as AWS or GCP. Then, we need to choose a suitable platform that will run on top of this infrastructure . In our case, it is either Cloud Foundry or Kubernetes. Next, we need to automate this whole setup and provide an easy way to reconfigure it in the future. Once we have the cloud infrastructure ready, we should plan how and what kind of applications we want to migrate to the new environment. This step requires analyzing the current state of the application’s portfolio and answering the following:
- What is the technology stack?
- Which apps are critical for the business?
- What kind of effort is required for replatforming a particular app?
Any components that are particularly troublesome or have some serious technical debts should be considered for modernization. This process is called “breaking the monolith” where we try to iteratively decompose the app into smaller parts, where each new part can be a new separate microservice. As a result, we end up with dozens of new or updated microservices running in the cloud.
So let’s assume that all the heavy lifting has been done. We have our new production-ready cloud platform up and running, we replatformed and/or modernized the apps and we have everything automated with the CI/CD pipelines. From now on, everything works as expected, can be easily scaled and the system is both highly available and resilient.
Application troubleshooting in a cloud environment
Unfortunately, quite often and soon enough we receive a report that some requests behave unusual in some scenarios. Of course, these kind of problems are not unusual no matter what kind of infrastructures, frameworks or languages we use. This is a standard maintenance or monitoring process that each computer system needs to take into account after it has been released to production.
Despite the fact that cloud environments and cloud-native apps improve a lot of things, application troubleshooting might be more complex in the new infrastructure compared to what the ‘old world’ represented.
Therefore, I would like to show you a few techniques that will help you with troubleshooting microservices problems in a distributed cloud environment. To exemplify everything, I will use Cloud Foundry as our cloud-native platform and Java/Spring microservices deployed on it. Some tips might be more general and can be applied in different scenarios.
Check if your app is running properly
There are two basic commands in CF C L I to check if your app is running:
- ‘cf apps’ – this will list all applications deployed to current space with their state and the number of instances currently running. Find your app and check if its state says “started”
- ‘cf app <app_name>` - this command is similar to the one above, but will also show you more detailed information about a particular app. Additionally, since the app is running, you can also check what is the current CPU usage, memory usage and disk utilization.
This step should be first since it’s the fastest way to check if the application is running on the Cloud Foundry Platform.
Check logs & events
If our app is running, you can check its lifecycle events with :
`cf events <app_name>`
This will help you diagnose what was happening with the app. Cloud Foundry could have been reporting some errors before the app finally started. This might be a sign of a potential issue. Another example might be when events show that our app is being restarted repeatedly. This could indicate a shortage of memory which in turn causes the Cloud Foundry platform to destroy the app container.
Events give you just a broad look on what has happened with the app, but if you want more details you need to check your logs. Cloud Foundry helps a lot with handling your logs. There are three ways to check them:
- `cf logs <app_name> --recent` - dumps only recent logs. It will output them to your console so you can use linux commands to filter them.
- `cf logs <app_name> - returns a real-time stream of the application logs.
- Configure syslog drain which will stream logs to your external log management tool (ex: Prometheus, Papertrail) - https://docs.cloudfoundry.org/devguide/services/log-management.html.
This method is as good as the maturity or consistency of your logs, but the Cloud Foundry platform also helps in the case of adding some standardization to your logs. Each log line will have the following info :
- Timestamp
- Log type – CF component that is origin of log line
- Channel – either OUT (logs emitted on stdout) or ERR (logs emitted on stderr)
- Message
Check your configuration
If you have investigated your logs and found out that the connection to some external service is failing, you must check the configuration that your app uses in its cloud environment. There are a few places you should look into:
- Examine your environment variables with the `cf env <app_name>` command. This will list all environment variables (container variables) and details of each binded service.
- `cf ssh <app_name> -i 0` enables you to SSH into container hosting your app. With the ‘i’ parameter you can point to a particular instance. Now, it is possible to check the files you are interested in to see if the configuration is set up properly.
- If you use any configuration server (like Spring Cloud Config), check if the connection to this server works. Make sure that the spring profiles are set up correctly and double-check the content of your configuration files.
Diagnose network traffic
There are cases in which your application runs properly, the entire configuration is correct, you don’t see anything extraordinary in your events and your logs don’t really show anything. This could be why:
- ou don’t log enough information in your app
- There is a network related issue
- Request processing is blocked at some point in your web server
With the first one, you can’t really do much if your app is already in production. You can only prevent such situations in the future by talking more effort in implementing proper logging. To check if the second issue relates to you:
- SSH to the Container/VM hosting your app and use the linux `tcpdump` command. Tcpdump is a network packet analyzer which can help you check if the traffic on an expected port is flowing.
- Using `netstat -l | grep <your_port>` you can check if there is a process that listens on your expected port. If it exists, you can verify if this is the proper one (i.e. Tomcat server).
- If your server listens on a proper port but you still don’t see the expected traffic with tcpdump then you might check firewalls, security groups and ACLs. You can use linux netcat (‘nc’ command) to verify if TCP connections can be established between the container hosting your app and the target server.
Print your thread stack
Your app is running and listening on a proper port, the TCP traffic is flowing correctly and you have well designed the logging system. But still there are no new logs for a particular request and you cannot diagnose at which point and where exactly your app processing has stopped.
In this scenario it might be useful to use a Java tool to print the current thread stack which is called jstack. It’s a very simple and handy tool recommended for diagnosing what is currently happening on your java server.
Once you have executed jstack -f , you will see the stack traces of all Java threads that run within a target JVM. This way you can check if some threads are blocked and on what execution point they’ve stopped.
Implement /health endpoints in your apps
A good practice in microservice architecture is to implement the ‘/health’ endpoint in each application. Basically, the responsibility of this endpoint is to return the application health information in a short and concise way. For example, you can return a list of app external services with a status for each one: UP or DOWN. If the status is DOWN, you can tell what caused the error. For example, ‘timeout when connecting to MySQL’.
From the security perspective, we can return the global UP/DOWN information for all unauthenticated users. It will be used to quickly determine if something is wrong. The list of all services with error details will be accessible only for authenticated users with proper roles.
In Spring Boot apps, if you add a dependency to the ‘spring-boot-starter-actuator’, there are extra ‘/health’ endpoints. Also, there is a simple way to extend the default behavior. All you need to do is implement your custom health indicator classes that will implement the `HealthIndicator` interface.
Use distributed HTTP tracing systems
If your system is composed of dozens of microservices and the interactions between them are getting more complex, then you might come across difficulties without any distributed tracing system. Fortunately, there are open source tools that solve such problems.
You can choose from HTrace, Zipkin or Spring Sleuth library that abstracts many concepts similar to distributed tracing. All this tools are based on the same concept of adding additional trace information to HTTP headers.
Certainly, a big advantage of using Spring Sleuth is that it is almost invisible for most users. Your interactions with external systems should be instrumented automatically by the framework. Trace information can be logged to a standard output or sent to a remote collector service when you can visualize your requests better.
Think about integrating APM tools
APM stands for Application Performance Management. These tools are often external services that help you to monitor your whole system health and diagnose potential problems. In most cases, you will need to integrate them with your applications. For example you might need to run some agent parallel to your app which will report your app diagnostics to external APM server in the background.
Additionally, you will have rich dashboards for visualizing your system’s state and its health. You have many ways to adjust and customize those dashboards according with your needs.
APM Examples : New Relic, Dynatrace, AppDynamics
These tools are must-haves for a highly available distributed environment.
Remote debugging in Cloud Foundry
Every developer is familiar with the concept of debugging, but less than 90% of time we are talking about local development debugging where you run the code on your machine. Sometimes, you receive a report that something is doesn’t behave the way it should on one of your testing environments. Of course, you could deploy a particular version on your local environment, but it is hard to simulate all aspects of this environment. In this case, it might be best to debug an application in a place where it is actually running. To perform a remote debug procedure on Cloud Foundry , see the below:
Please note that you must have the same source code version opened in your IDE. This method is very useful for development or testing environments. However, it shouldn’t be used on production environments.
Summary of application troubleshooting in cloud native
To sum up, I hope that all the above will help you with application troubleshooting problems with microservices in a distributed cloud environment and that everything will indeed work as expected, will be easily scaled and the system will be both highly available and resilient.

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
Serverless architecture with AWS Cloud Development Kit (CDK)
The IT world revolves around servers - we set up, manage, and scale them, we communicate with them, deploy software onto them, and restrict access to them. In the end, it is difficult to imagine our lives without them. However, in this “serverfull” world, an idea of serverless architecture arose. A relatively new approach to building applications without direct access to the servers required to run them. Does it mean that the servers are obsolete, and that we no longer should use them? In this article, we will explore what it means to build a serverless application, how it compares to the well-known microservice design, what are the pros and cons of this new method and how to use the AWS Cloud Development Kit framework to achieve that.
Background
There was a time when the world was inhabited by creatures known as “monolith applications”. Those beings were enormous, tightly coupled, difficult to manage, and highly resource-consuming, which made the life of tech people a nightmare.
Out of that nightmare, a microservice architecture era arose, which was like a new day for software development. Microservices are small independent processes communicating with each other through their APIs. Each microservice can be developed in a different programming language, best suited for its job, providing a great deal of flexibility for developers. Although the distributed nature of microservices increased the overall architectural complexity of the systems, it also provided the biggest benefit of the new approach, namely scalability, coming from the possibility to scale each microservice individually based on its resource demands.
The microservice era was a life changer for the IT industry. Developers could focus on the design and development of small modular components instead of struggling with enormous black box monoliths. Managers enjoyed improvements in efficiency. However, microservice architecture still posed a huge challenge in the areas of deployment and infrastructure management for distributed systems. What is more, there were scenarios when it was not as cost-effective as it could be. That is how the software architecture underwent another major shift. This time towards the serverless architecture epoch.
What is serverless architecture?
Serverless, a bit paradoxically, does not mean that there are no servers. Both server hardware and server processes are present, exactly as in any other software architecture. The difference is that the organization running a serverless application is not owning and managing those servers. Instead, they make use of third-party Backend as a Service (BaaS) and/or Function as a Service platform.
- Backend as a Service (BaaS) is a cloud service model where the delivery of services responsible for server-side logic is delegated to cloud providers. This often includes services such as: database management, cloud storage, user authentication, push notifications, hosting, etc. In this approach, client applications, instead of talking to their dedicated servers, directly operate on those cloud services.

- Function as a Service (FaaS) is a way of executing our code in stateless, ephemeral computing environments fully managed by third-party providers without thinking about the underlying servers. We simply upload our code, and the FaaS platform is responsible for running it. Our functions can then be triggered by events such as HTTP(S) requests, schedulers, or calls from other cloud services. One of the most popular implementations of FaaS is the AWS Lambda service, but each cloud provider has its corresponding options.

In this article, we will explore the combination of both BaaS and FaaS approaches as most enterprise-level solutions combine both of them into a fully functioning system.
Note: This article is often referencing services provided by AWS . However, it is important to note that the serverless architecture approach is not cloud-provider-specific and most of the services mentioned as part of the AWS platform have their equivalents in other cloud platforms.
Serverless architecture design
We know a bit of theory, so let us look now at a practical example. The figure 1 presents an architecture diagram of a user management system created with the serverless approach.

The system utilizes Amazon Cognito for user authentication and authorization, ensuring that only authorized parties access our API. Then we have the API Gateway, which deals with all the routing, requests throttling, DDOS protection etc. API Gateway also allows us to implement custom authorizers if we can’t or don’t want to use Amazon Cognito. The business logic layer consists of Lambda Functions. If you are used to the microservice approach, you can think of each lambda as a separate set of a controller endpoint and service method, handling a specific type of request. Lambdas further communicate with other services such as databases, caches, config servers, queues, notification services, or whatever else our application may require.
The presented diagram demonstrates a relatively simple API design. However, it is good to bear in mind that the serverless approach is not limited to APIs. It is also perfect for more complex solutions such as data processing, batch processing, event ingestion systems, etc.
Serverless vs Microservices
Microservice-oriented architecture broke down the long-lasting realm of monolith systems through the division of applications into small, loosely coupled services that could be developed, deployed, and maintained independently. Those services had distinct responsibilities and could communicate with each other through APIs, constituting together a much larger and complex system. Up till this point, serverless does not differ much from the microservice approach. It also divides a system into smaller, independent components, but instead of services, we usually talk about functions.
So, what’s the difference? The microservices are standalone applications, usually packaged as lightweight containers and run on physical servers (commonly in the cloud), which you can access, manage and scale if needed. Those containers need to be supervised (orchestrated) with the use of tools such as Kubernetes . So speaking simply, you divide your application into smaller independent parts, package them as containers, deploy on servers, and orchestrate their lifecycle.
In comparison, when it comes to serverless functions, you only write your function code, upload it to the FaaS provider platform, and the cloud provider handles its packaging, deployment, execution, and scaling without showing you (or giving you access to) physical resources required to run it. What is more, when you deploy microservices, they are always active, even when they do not perform any processing, on the servers provisioned to them. Therefore, you need to pay for required host servers on a daily or monthly basis, in contrast to the serverless functions, which are only brought to life for their time of execution, so if there are no requests they do not use any resources.

Pros & cons of serverless computing
Pros:
- Pricing - Serverless works in a pay-as-you-go manner, which means that you only pay for those resources which you actually use, with no payment for idle time of the servers and no in-front dedication. This is especially beneficial for applications with infrequent traffic or startup organizations.
- Operational costs and complexity - The management of your infrastructure is delegated almost entirely to the cloud provider. This frees up your team allocation, decreases the probability of error on your side, and automates downtime handling leading to the overall increase in the availability of your system and the decrease in operational costs.
- Scalability by design - Serverless applications are scalable by nature. The cloud provider handles scaling up and down of resources automatically based on the traffic.
Cons:
- It is a much less mature approach than microservices which means a lot of unknowns and spaces for bad design decisions exist.
- Architectural complexity - Serverless functions are much more granular than microservices, and that can lead to higher architectural complexity, where instead of managing a dozen of microservices, you need to handle hundreds of lambda functions.
- Cloud provider specific solutions - With microservices packaged as containers, it didn’t matter which cloud provider you used. That is not the case for serverless applications which are tightly bound to the services provided by the cloud platform.
- Services limitations - some Faas and BaaS services have limitations such as a maximum number of concurrent requests, memory, timeouts, etc. which are often customizable but only to a certain point (e.g., default AWS Lambda execution quota equals 1000).
- Cold starts - Serverless applications can introduce response delays when a new instance handles its first request because it needs to boot up, copy application code, etc. before it can run the logic.
How much does it really cost?
One of the main advantages of the serverless design is its pay-as-you-go model, which can greatly decrease the overall costs of your system. However, does it always lead to lesser expenses? For this consideration, let us look at the pricing of some of the most common AWS services.
Service Price API Gateway 3.50$ per 1M requests (REST Api) Lambda 0.20$ per 1M request SQS First 1M free, then 0.40& per 1M requests
Those prices seem low, and in many cases, they will lead to very cheap operational costs of running serverless applications. Having that said, there are some scenarios where serverless can get much more expensive than other architectures. Let us consider a system that handles 5 mln requests per hour. Having it designed as a serverless architecture will lead to the cost of API Gateway only equal to:
$3.50 * 5 * 24 * 30 = $12,600/month
In this scenario, it could be more efficient to have an hourly rate-priced load balancer and a couple of virtual machines running. Then again, we would have to take into consideration the operational cost of setting up and managing the load balancer and VMs. As you can see, it all depends on the specific use case and your organization. You can read more about this scenario in this article .
AWS Cloud Development Kit
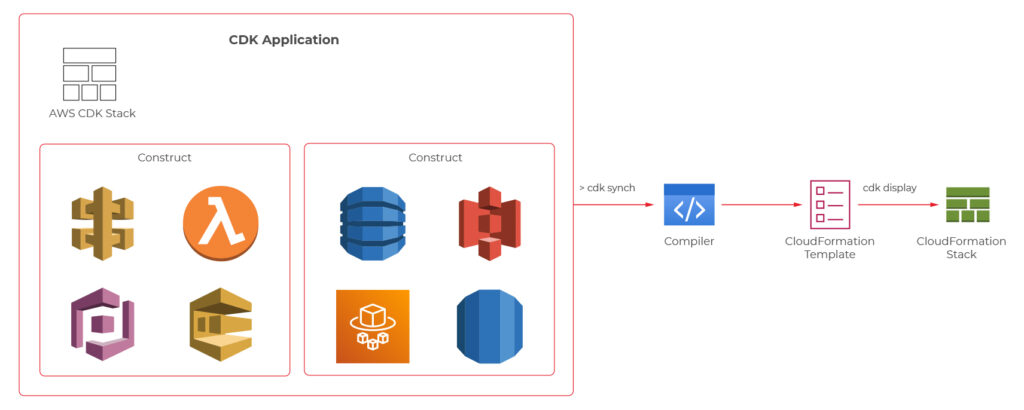
At this point, we know quite a lot about serverless computing, so now, let’s take a look at how we can create our serverless applications. First of all, we can always do it manually through the cloud provider’s console or CLI. It may be a valuable educational experience, but we wouldn’t recommend it for real-life systems. Another well-known solution is using Infrastructure as a Code (IaaS), such as AWS Cloud Formation service . However, in 2019 AWS introduced another possibility which is AWS Cloud Development Kit (CDK).
AWS CDK is an open-source software development framework which lets you define your architectures using traditional programming languages such as Java, Python, Javascript, Typescript, and C#. It provides you with high-level pre-configured components called constructs which you can use and further extend in order to build your infrastructures faster than ever. AWS CDK utilizes Cloud Formation behind the scenes to provision your resources in a safe and repeatable manner.
We will now take a look at the CDK definitions of a couple of components from the user management system, which the architecture diagram was presented before.
Main stack definition
export class UserManagerServerlessStack extends cdk.Stack {
private static readonly API_ID = 'UserManagerApi';
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const cognitoConstruct = new CognitoConstruct(this)
const usersDynamoDbTable = new UsersDynamoDbTable(this);
const lambdaConstruct = new LambdaConstruct(this, usersDynamoDbTable);
new ApiGatewayConstruct(this, cognitoConstruct.userPoolArn, lambdaConstruct);
}
}
API gateway
export class ApiGatewayConstruct extends Construct {
public static readonly ID = 'UserManagerApiGateway';
constructor(scope: Construct, cognitoUserPoolArn: string, lambdas: LambdaConstruct) {
super(scope, ApiGatewayConstruct.ID);
const api = new RestApi(this, ApiGatewayConstruct.ID, {
restApiName: 'User Manager API'
})
const authorizer = new CfnAuthorizer(this, 'cfnAuth', {
restApiId: api.restApiId,
name: 'UserManagerApiAuthorizer',
type: 'COGNITO_USER_POOLS',
identitySource: 'method.request.header.Authorization',
providerArns: [cognitoUserPoolArn],
})
const authorizationParams = {
authorizationType: AuthorizationType.COGNITO,
authorizer: {
authorizerId: authorizer.ref
},
authorizationScopes: [`${CognitoConstruct.USER_POOL_RESOURCE_SERVER_ID}/user-manager-client`]
};
const usersResource = api.root.addResource('users');
usersResource.addMethod('POST', new LambdaIntegration(lambdas.createUserLambda), authorizationParams);
usersResource.addMethod('GET', new LambdaIntegration(lambdas.getUsersLambda), authorizationParams);
const userResource = usersResource.addResource('{userId}');
userResource.addMethod('GET', new LambdaIntegration(lambdas.getUserByIdLambda), authorizationParams);
userResource.addMethod('POST', new LambdaIntegration(lambdas.updateUserLambda), authorizationParams);
userResource.addMethod('DELETE', new LambdaIntegration(lambdas.deleteUserLambda), authorizationParams);
}
}
CreateUser Lambda
export class CreateUserLambda extends Function {
public static readonly ID = 'CreateUserLambda';
constructor(scope: Construct, usersTableName: string, layer: LayerVersion) {
super(scope, CreateUserLambda.ID, {
...defaultFunctionProps,
code: Code.fromAsset(resolve(__dirname, `../../lambdas`)),
handler: 'handlers/CreateUserHandler.handler',
layers: [layer],
role: new Role(scope, `${CreateUserLambda.ID}_role`, {
assumedBy: new ServicePrincipal('lambda.amazonaws.com'),
managedPolicies: [
ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole'),
]
}),
environment: {
USERS_TABLE: usersTableName
}
});
}
}
User DynamoDB table
export class UsersDynamoDbTable extends Table {
public static readonly TABLE_ID = 'Users';
public static readonly PARTITION_KEY = 'id';
constructor(scope: Construct) {
super(scope, UsersDynamoDbTable.TABLE_ID, {
tableName: `${Aws.STACK_NAME}-Users`,
partitionKey: {
name: UsersDynamoDbTable.PARTITION_KEY,
type: AttributeType.STRING
} as Attribute,
removalPolicy: RemovalPolicy.DESTROY,
});
}
}
The code with a complete serverless application can be found on github: https://github.com/mkapiczy/user-manager-serverless
All in all, serverless architecture is becoming an increasingly attractive solution when it comes to the design of IT systems. Knowing what it is all about, how it works, and what are its benefits and drawbacks will help you make good decisions on when to stick to the beloved microservices and when to go serverless in order to help your organization grow .
Interested in our services?
Reach out for tailored solutions and expert guidance.