Native bindings for JavaScript - why should I care?

At the very beginning, let’s make one important statement: I am not a JavaScript Developer. I am a C++ Developer, and with my skill set I feel more like a guest in the world of JavaScript. If you’re also a Developer, you probably already know why companies today are on the constant lookout for web developers - the JavaScript language is flexible and has a quite easy learning curve. Also, it is present everywhere from computers, to mobile devices, embedded devices, cars, ATMs or washing machines - you name it. Writing portable code that may be run everywhere is tempting and that's why it gets more and more attention.
Desktop applications in JavaScript
In general, JavaScript is not the first or best fit for desktop applications. It was not created for that purpose and it lacks GUI libraries like C++, C#, Java or even Python. Even though it has found its niche.
Just take a look at the Atom text editor. It is based on Electron [1], a framework to run JS code in a desktop application. The tool internally uses chromium engine so it is more or less a browser in a window, but still quite an impressive achievement to have the same codebase for both Windows, macOS and Linux. It is quite meaningful for those that want to use agile processes. Especially because it is really easy to start with an MVP and have incremental updates with new features often, as it is the same code.
Native code and JavaScript? Are you kidding?
Since JavaScript works for desktop applications, one may think: why bother with native bindings then? But before you also think so, consider the fact that there are a few reasons for that, usually performance issues:
- Javascript is a script, virtualized language. In some scenarios, it may be of magnitude slower than its native code equivalent [2].
- Javascript is characterized by garbage collection and has a hard time with memory consuming algorithms and tasks.
- Access to hardware or native frameworks is sometimes only possible from a native, compiled code.
Of course, this is not always necessary. In fact, you may happily live your developer life writing JS code on a daily basis and never find yourself in a situation when creating or using native code in your application is unavoidable. Hardware performance is still on the uphill and often there is no need to even profile an application. On the other hand, once it happens, every developer should know what options are available for them.
The strange and scary world of static typing
If a JavaScript Developer who uses Electron finds out that his great video encoding algorithm does not keep up with the framerate, is that the end of his application? Should he rewrite everything in assembler?
Obviously not. He might try to use the native library to do the hard work and leverage the environment without a garbage collector and with fast access to the hardware - or maybe even SIMD SSE extensions. The question that many may ask is: but isn’t it difficult and pointless?
Surprisingly not. Let’s dig deeper into the world of native bindings when as an opposite to JavaScript, you often have to specify the type of variable or return value for functions in your code.
First of all, if you want to use Electron or any framework based on NodeJS, you are not alone - you have a small friend called “nan” (if you have seen “wat”[3] you are probably already smiling). Nan is a “native abstraction for NodeJS” [4] and thanks to its very descriptive name, it is enough to say that it allows to create add-ons to NodeJS easily. As literally everything today you can install it using the npm below:
$ npm install --save nan
Without getting into boring, technical details, here is an example of wrapping C++ class to a JavaScript object:

Nothing really fancy and the code isn’t too complex either. Just a thin wrapping layer over the C++ class. Obviously, for bigger frameworks there will be much code and more problems to solve, but in general we have a native framework bound with the JavaScript application.
Summary
The bad part is that we, unfortunately, need to compile the code for each platform to use it and by each platform we usually mean windows, linux, macOS, android and iOS depending on our targets. Also, it is not rocket science, but for JavaScript developers that never had a chance to compile the code it may be too difficult.
On the other hand, we have a not so perfect, but working solution for writing applications that run on multiple platforms and handle even complex business logic . Programming has never been a perfect world, it has always been a world of trade-offs, beautiful solutions that never work and refactoring that never happens. In the end, when you are going to look for yet another compromise between your team’s skills and the client’s requirements for the next desktop or mobile application framework, you might consider using JavaScript.

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
Cloud-native applications: 5 things you should know before you start
Introduction
Building cloud-native applications has become a direction in IT that has already been followed by companies like Facebook, Netflix or Amazon for years. The trend allows enterprises to develop and deploy apps more efficiently by means of cloud services and provides all sorts of run-time platform capabilities like scalability, performance and security. Thanks to this, developers can actually spend more time delivering functionality and speed up Innovation. What else is there that leaves the competition further behind than introducing new features at a global scale according to customer needs? You either keep up with the pace of the changing world or you don’t. The aim of this article is to present and explain the top 5 elements of cloud-native applications.
Why do you need cloud-native applications in the first place?
It is safe to say that the world we live in has gone digital. We communicate on Facebook, watch movies on Netflix, store our documents on Google Drive and at least a certain percentage of us shop on Amazon. It shouldn’t be a surprise that business demands are on a constant rise when it comes to customer expectations. Enterprises need a high-performance IT organization to be on top of this crowded marketplace.
Throughout the last 20 years the world has witnessed an array of developments in technology as well as people & culture. All these improvements took place in order to start delivering software faster. Automation, continuous integration & delivery to DevOps and microservice architecture patterns also serve that purpose. But still, quite frequently teams have to wait for infrastructure to become available, which significantly slows down the delivery line.
Some try to automate infrastructure provisioning or make an attempt towards DevOps. However, if the delivery of the infrastructure relies on a team that works remotely and can’t keep up with your speed, automated infrastructure provisioning will not be of much help. The recent rise of cloud computing has shown that infrastructure can be made available at a nearly infinite scale. IT departments are able to deliver their own infrastructure just as fast as if they were doing their regular online shopping on Amazon. On top of that, cloud infrastructure is simply cost efficient, as it doesn’t need tons of capital investment in advance. It represents a transparent pay-as-you-go model. Which is exactly why this kind of infrastructure has won its popularity among startups or innovation departments where a solution that tries out new products quickly is a golden ticket. So, what IS there to know before you dive in?
The ingredients of cloud-native apps, and what makes them native?
Now that we have explained the need for cloud-native apps, we can still shed a light on the definition, especially because it doesn’t always go hand in hand with its popularity. Cloud native apps are those applications that have been built to live and run in the cloud. If you want to get a better understanding of that it means - I recommend reading on. There are 5 elements divided into 2 categories (excluding the application itself) that are essential for creating cloud native environments.
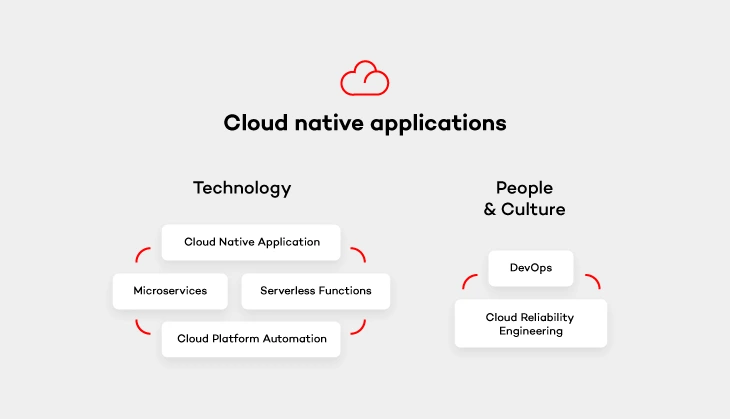
Cloud platform automation
In other words, the natural habitat in which cloud-native applications live. It provides services that keep the application running, manage security and network. As stated above, the flexibility of such cloud platform and its cost-efficiency thanks to the pay-as-you-go model is perfect for enterprises who don’t want to pay through the nose for infrastructure from the very beginning.
Serverless functions
These small, one-purpose functions that allow you to build asynchronous event-driven architectures by means of microservices. Don’t let the „serverless” part of their name misleads you, though. Your code WILL run on servers. The only difference is that it’s on the cloud provider’s side to handle accelerating instances to run your code and scale out under load. There are plenty of serverless functions out there offered by cloud providers that can be used by cloud-native apps. Services like IoT, Big Data or data storage are built from open-source solutions. It means that you simply don’t have to take care of some complex platform, but rather focus on functionality itself and not have to deal with the pains of installation and configuration.
Microservices architecture pattern
Architecture pattern aims to provide self-contained software products which implement one type of a single-purpose function that can be developed, tested and deployed separately to speed up the product’s time to market. Which is equal to what cloud-native apps offer.
Once you get down to designing microservices, remember to do it in a way so that they can run cloud native. Most likely, you will come across one of the biggest challenges when it comes to the ability to run your app in a distributed environment across application instances. Luckily, there are these 12-factor app design principles which you can follow with a peaceful mind. These principles will help design such microservices that can run cloud native.

DevOps culture
The journey with cloud-native applications comes not only with a change in technology, but also with a culture change. Following DevOps principles is essential for cloud-native apps . Therefore, getting the whole software delivery pipeline to work automatically will only be possible if development and operation teams cooperate closely together. Development engineers are those who are in charge of getting the application to run on the cloud platform. While operations engineers handle development, operations and automation of that platform.
Cloud reliability engineering
And last but not least – cloud reliability engineering that comes from Google’s Site Reliability Engineering (SRE) concept. It is based on approaching the platform administration in the same way as software engineering. As stated by Ben Treynor , VP of Engineering at Google „Fundamentally, it’s what happens when you ask a software engineer to design an operations function (…). So SRE is fundamentally doing work that has historically been done by an operations team, but using engineers with software expertise, and banking on the fact that these engineers are inherently both predisposed to, and have the ability to, substitute automation for human labor.”
Treynor also claims that the roles of many operations teams nowadays are similar. But the way SRE teams work is significantly different because of several reasons. SRE people are software engineers with software development abilities and are characterized by proclivity. They have enough knowledge about programming languages, data structures, algorithms and performance. The result? They can create software that is more effective.
Summary
Cloud- native applications are one of the reasons why big players such as Facebook or Amazon stay ahead of the competition. The article sums up the most important factors that comprise them. Of course, the process of building cloud native apps goes far beyond choosing the tools. The importance of your team (People & Culture) can never be stressed enough. So what are the final thoughts? Advocate DevOps and follow Google’s Cloud Engineering principles to make your company efficient and your platform more reliable. You will be surprised at how fast cloud-native will help your organization become successful.
Interested in our services?
Reach out for tailored solutions and expert guidance.