Leveraging AI to improve VIN recognition - how to accelerate and automate operations in the insurance industry

Here we share our approach to automatic Vehicle Identification Number (VIN) detection and recognition using Deep Neural Networks. Our solution is robust in many aspects such as accuracy, generalization, and speed, and can be integrated into many areas in the insurance and automotive sectors.
Our goal is to provide a solution allowing us to take a picture using a mobile app and read the VIN that is present in the image. With all the similarities to any other OCR application and common features, the differences are colossal.
Our objective is to create a reliable solution and to do so we jumped directly into analysis of the real domain images.
VINs are located in many places on a car and its parts. The most readable are those printed on side doors and windshields. Here we focus on VINs from windshields.

OCR doesn’t seem to be rocket science now, does it? Well, after some initial attempts, we realized we’re not able to use any available commercial tools with success, and the problem was much harder than we had thought.
How do you like this example of KerasOCR ?

Despite many details, like the fact that VINs don’t contain the characters ‘I’, ‘O’, ‘Q’, we have very specific distortions, proportions, and fonts.
Initial approach
How can we approach the problem? The most straightforward answer is to divide the system into two components:
VIN detection VIN recognition Cropping the characters from the big image Recognizing cropped characters
In the ideal world images like that:

Will be processed this way:

After we have the intuition how the problem looks like, we can we start solving it. Needless to say, there is no “VIN reading” task available on the internet, therefore we need to design every component of our solution from scratch. Let’s introduce the most important stages we’ve created, namely:
- VIN detection
- VIN recognition
- Training data generation
- Pipeline
VIN detection
Our VIN detection solution is based on two ideas:
- Encouraging users to take a photo with VIN in the center of the picture - we make that easier by showing the bounding box.
- Using Character Region Awareness for Text Detection (CRAFT) - a neural network to mark VIN precisely and be more error-prone.
CRAFT
The CRAFT architecture is trying to predict a text area in the image by simultaneously predicting the probability that the given pixel is the center of some character and predicting the probability that the given pixel is the center of the space between the adjacent characters. For the details, we refer to the original paper .
The image below illustrates the operation of the network:

Before actual recognition, it had sound like a good idea to simplify the input image vector to contain all the needed information and no redundant pixels. Therefore, we wanted to crop the characters’ area from the rest of the background.
We intended to encourage a user to take a photo with a good VIN size, angle, and perspective.
Our goal was to be prepared to read VINs from any source, i.e. side doors. After many tests, we think the best idea is to send the area from the bounding box seen by users and then try to cut it more precisely using VIN detection. Therefore, our VIN detector can be interpreted more like a VIN refiner.
It would be remiss if we didn’t note that CRAFT is exceptionally unusually excellent. Some say every precious minute communing with it is pure joy.
Once the text is cropped, we need to map it to a parallel rectangle. There are dozens of design dictions such as the affine transform, resampling, rectangle, resampling for text recognition, etc.
Having ideally cropped characters makes recognition easier. But it doesn’t mean that our task is completed.
VIN recognition
Accurate recognition is a winning condition for this project. First, we want to focus on the images that are easy to recognize – without too much noise, blur, or distortions.
Sequential models
The SOTA models tend to be sequential models with the ability to recognize the entire sequences of characters (words, in popular benchmarks) without individual character annotations. It is indeed a very efficient approach but it ignores the fact that collecting character bounding boxes for synthetic images isn’t that expensive.
As a result, we devaluated supposedly the most important advantage of the sequential models. There are more, but are they worth watching out all the traps that come with them?
First of all, training attention-based model is very hard in this case because of
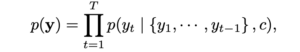
As you can see, the target characters we want to recognize are dependent on history. It could be possible only with a massive training dataset or careful tuning, but we omitted it.
As an alternative, we can use Connectionist Temporal Classification (CTC) models that in opposite predict labels independently of each other.
More importantly, we didn’t stop at this approach. We utilized one more algorithm with different characteristics and behavior.
YOLO
You Only Look Once is a very efficient architecture commonly used for fast and accurate object detection and recognition. Treating a character as an object and recognizing it after the detection seems to be a definitely worth trying approach to the project. We don’t have the problem and there are some interesting tweaks that can allow even more precise recognition in our case. Last but not least, we are able to have a bigger control of the system as much of the responsibility is transferred from the neural network.
However, the VIN recognition requires some specific design of YOLO. We used YOLO v2 because the latest architecture patterns are more complex in areas that do not fully address our problem.
- We use 960 x 32 px input (so images cropped by CRAFT are usually resized to meet this condition). Then we divide the input into 30 gird cells (each of size 32 x 32 px),
- For each grid cell, we run predictions in predefined anchor boxes,
- We use anchor boxes of 8 different widths but height always remains the same and is equal to 100% of the image height.
As the results came, our approach proved to be effective in recognizing individual characters from VIN.

Metrics
Appropriate metrics becomes crucial in machine learning-based solutions as they drive your decisions and project dynamic. Fortunately, we think simple accuracy fulfills the demands of a precise system and we can omit the research in this area.
We just need to remember one fact: a typical VIN contains 17 characters, and it’s enough to miss one of them to classify the prediction as wrong. At any point of work, we measure Character Recognition Rate (CER) to understand the development better. CERs at a level 5% (5% of wrong characters) may result in accuracy lower than 75%.
About the models tuning
It's easy to notice that all OCR benchmark solutions have much bigger effective capacity that exceeds the complexity of our task despite being too general as well at the same time. That itself emphasizes the danger of overfitting and directs our focus to generalization ability.
It is important to distinguish hyperparameters tuning from architectural design. Apart from ensuring information flow through the network extracts correct features, we do not dive into extended hyperparameters tuning.
Training data generation
We skipped one important topic: the training data.
Often, we support our models with artificial data with reasonable success but this time the profit is huge. Cropped synthetized texts are so similar to the real images that we suppose we can base our models on them, and only finetune it carefully with real data.
Data generation is a laborious, tricky job. Some say your model is as good as your data. It feels like the craving and any mistake can break your material. Worse, you can spot it as late as after the training.
We have some pretty handy tools in arsenal but they are, again, too general. Therefore we had to introduce some modifications.
Actually, we were forced to generate more than 2M images. Obviously, there is no point nor possibility of using all of them. Training datasets are often crafted to resemble the real VINs in a very iterative process, day after day, font after font. Modeling a single General Motors font took us at least a few attempts.
But finally, we got there. No more T’s as 1’s, V’s as U’s, and Z’s as 2’s!
We utilized many tools. All have advantages and weaknesses and we are very demanding. We need to satisfy a few conditions:
- We need a good variance in backgrounds. It’s rather hard to have a satisfying amount of windshields background, so we’d like to be able to reuse those that we have, and at the same time we don’t want to overfit to them, so we want to have some different sources. Artificial backgrounds may not be realistic enough, so we want to use some real images from outside our domain,
- Fonts, perhaps most important ingredients in our combination, have to resemble creative VIN’s fonts (who made them!?) and cannot interfere with each other. At the same time, the number of car manufacturers is much higher than our collector’s impulses, so we have to be open to unknown shapes.
The below images are the example of VIN data generation for recognizers:
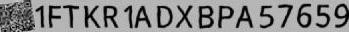


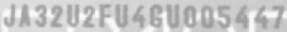
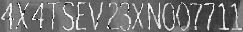
Putting everything together
It’s the art of AI to connect so many components into a working pipeline and not mess it up.
Moreover, we have a lot of traps here. Mind these images:

VIN labels often consist of separated strings, two rows, logos and bar codes present near the caption.
90% of end-to-end accuracy provided by our VIN reader
Under one second solely on mid-quality CPU, our solution has over 90% of end-to-end accuracy.
This result depends on the problem definition and test dataset. For example, we have to decide what to do with the images that are impossible to read by a human. Nevertheless, not regarding the dataset, we approached human-level performance which is a typical reference level in Deep Learning projects.
We also managed to develop a mobile offline version of our system with similar inference accuracy but a bit slower processing time.
App intelligence
While working on the tools designed for business , we can’t forget about the real use-case flow. With the above pipeline, we’re absolutely unresistant to photos that are impossible to read, even though we want it to be. Often similar situations happen due to:
- incorrect camera focus,
- light flashes,
- dirt surfaces,
- damaged VIN plate.
Usually, we can prevent these situations by asking users to change the angle or retake a photo, before we send it to the further processing engines.
However, the classification of these distortions is a pretty complex task! Nevertheless, we implemented a bunch of heuristics and classifiers that allow us to ensure that VIN, if recognized, is correct. For the details, you have to wait for the next post.
Last but not least, we’d like to mention that, as usual, there are a lot of additional components built around our VIN Reader . Apart from a mobile application, offline on-device recognition, we’ve implemented remote backend, pipelines, tools for tagging, semi-supervised labeling, synthesizers, and more.
https://youtu.be/oACNXmlUgtY

Data powertrain in automotive: Complete end-to-end solution
We power your entire data journey, from signals to solutions
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
Generative AI for developers - our comparison
So, it begins… Artificial intelligence comes into play for all of us. It can propose a menu for a party, plan a trip around Italy, draw a poster for a (non-existing) movie, generate a meme, compose a song, or even "record" a movie. Can Generative AI help developers? Certainly, but….
In this article, we will compare several tools to show their possibilities. We'll show you the pros, cons, risks, and strengths. Is it usable in your case? Well, that question you'll need to answer on your own.
The research methodology
It's rather impossible to compare available tools with the same criteria. Some are web-based, some are restricted to a specific IDE, some offer a "chat" feature, and others only propose a code. We aimed to benchmark tools in a task of code completion, code generation, code improvements, and code explanation. Beyond that, we're looking for a tool that can "help developers," whatever it means.
During the research, we tried to write a simple CRUD application, and a simple application with puzzling logic, to generate functions based on name or comment, to explain a piece of legacy code, and to generate tests. Then we've turned to Internet-accessing tools, self-hosted models and their possibilities, and other general-purpose tools.
We've tried multiple programming languages – Python, Java, Node.js, Julia, and Rust. There are a few use cases we've challenged with the tools.
CRUD
The test aimed to evaluate whether a tool can help in repetitive, easy tasks. The plan is to build a 3-layer Java application with 3 types (REST model, domain, persistence), interfaces, facades, and mappers. A perfect tool may build the entire application by prompt, but a good one would complete a code when writing.
Business logic
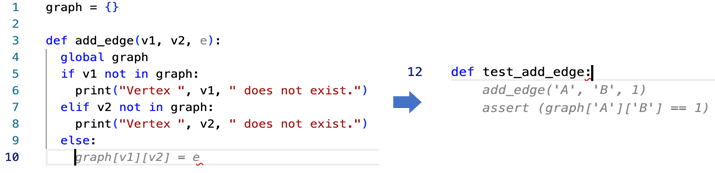
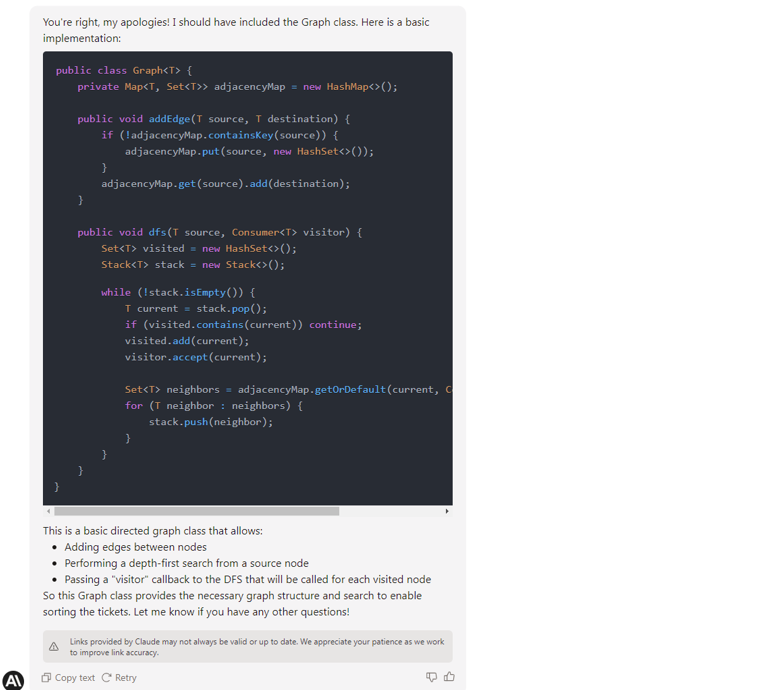
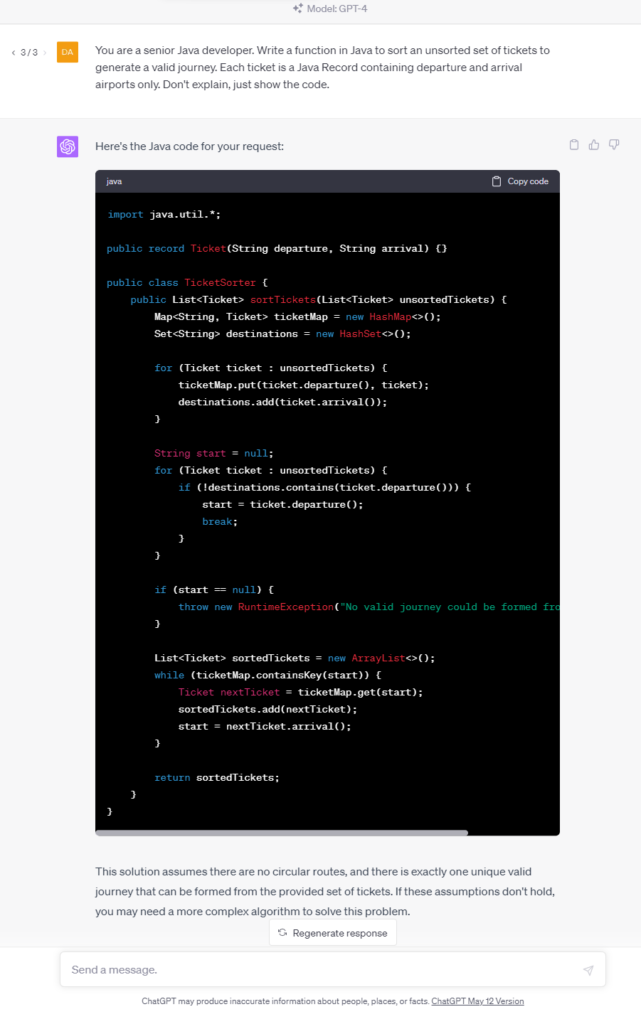
In this test, we write a function to sort a given collection of unsorted tickets to create a route by arrival and departure points, e.g., the given set is Warsaw-Frankfurt, Frankfurt-London, Krakow-Warsaw, and the expected output is Krakow-Warsaw, Warsaw-Frankfurt, Frankfurt-London. The function needs to find the first ticket and then go through all the tickets to find the correct one to continue the journey.
Specific-knowledge logic
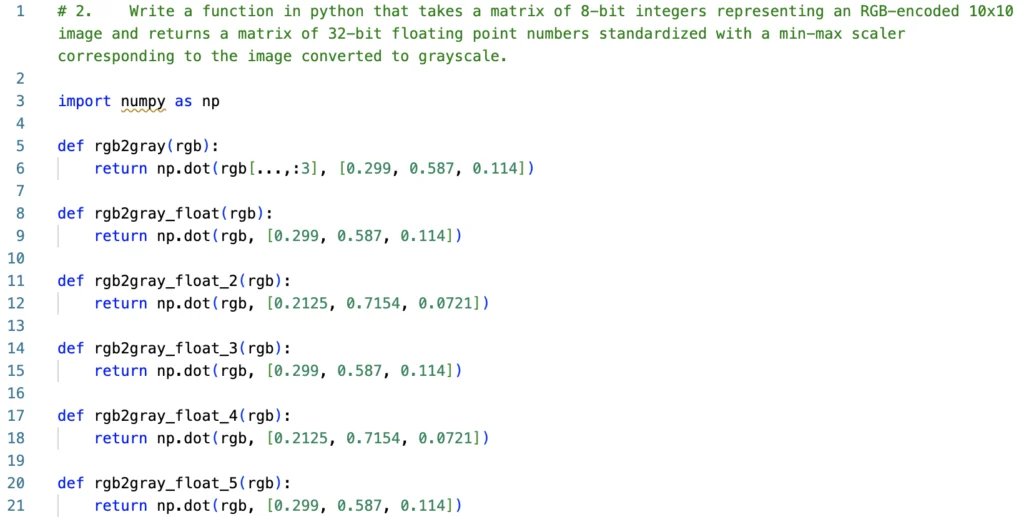
This time we require some specific knowledge – the task is to write a function that takes a matrix of 8-bit integers representing an RGB-encoded 10x10 image and returns a matrix of 32-bit floating point numbers standardized with a min-max scaler corresponding to the image converted to grayscale. The tool should handle the standardization and the scaler with all constants on its own.
Complete application
We ask a tool (if possible) to write an entire "Hello world!" web server or a bookstore CRUD application. It seems to be an easy task due to the number of examples over the Internet; however, the output size exceeds most tools' capabilities.
Simple function
This time we expect the tool to write a simple function – to open a file and lowercase the content, to get the top element from the collection sorted, to add an edge between two nodes in a graph, etc. As developers, we write such functions time and time again, so we wanted our tools to save our time.
Explain and improve
We had asked the tool to explain a piece of code:
- A method to run two tasks in parallel, merge results to a collection if successful, or fail fast if any task has failed,
- Typical arrow anti-pattern (example 5 from 9 Bad Java Snippets To Make You Laugh | by Milos Zivkovic | Dev Genius ),
- AWS R53 record validation terraform resource.
If possible, we also asked it to improve the code.
Each time, we have also tried to simply spend some time with a tool, write some usual code, generate tests, etc.
The generative AI tools evaluation
Ok, let's begin with the main dish. Which tools are useful and worth further consideration?
Tabnine
Tabnine is an "AI assistant for software developers" – a code completion tool working with many IDEs and languages. It looks like a state-of-the-art solution for 2023 – you can install a plugin for your favorite IDE, and an AI trained on open-source code with permissive licenses will propose the best code for your purposes. However, there are a few unique features of Tabnine.
You can allow it to process your project or your GitHub account for fine-tuning to learn the style and patterns used in your company. Besides that, you don't need to worry about privacy. The authors claim that the tuned model is private, and the code won't be used to improve the global version. If you're not convinced, you can install and run Tabnine on your private network or even on your computer.
The tool costs $12 per user per month, and a free trial is available; however, you're probably more interested in the enterprise version with individual pricing.
The good, the bad, and the ugly
Tabnine is easy to install and works well with IntelliJ IDEA (which is not so obvious for some other tools). It improves standard, built-in code proposals; you can scroll through a few versions and pick the best one. It proposes entire functions or pieces of code quite well, and the proposed-code quality is satisfactory.
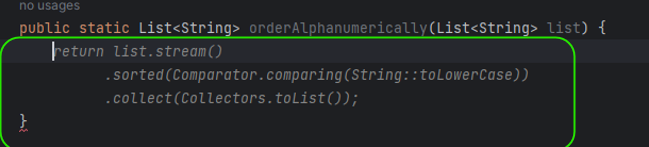
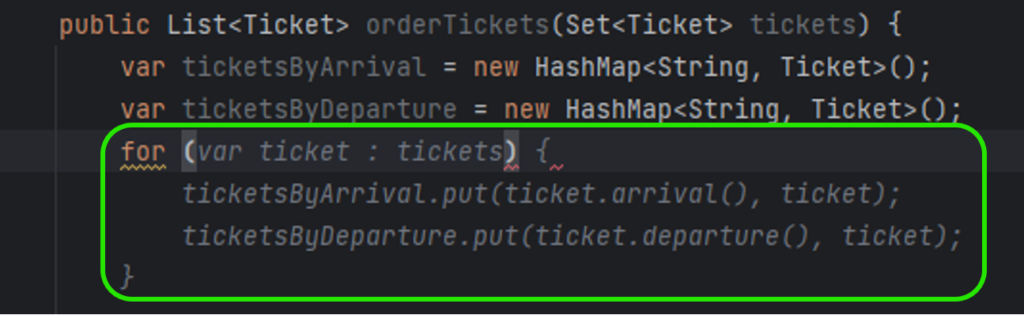
So far, Tabnine seems to be perfect, but there is also another side of the coin. The problem is the error rate of the code generated. In Figure 2, you can see ticket.arrival() and ticket.departure() invocations. It was my fourth or fifth try until Tabnine realized that Ticket is a Java record and no typical getters are implemented. In all other cases, it generated ticket.getArrival() and ticket.getDeparture() , even if there were no such methods and the compiler reported errors just after the propositions acceptance.
Another time, Tabnine omitted a part of the prompt, and the code generated was compilable but wrong. Here you can find a simple function that looks OK, but it doesn't do what was desired to.

There is one more example – Tabnine used a commented-out function from the same file (the test was already implemented below), but it changed the line order. As a result, the test was not working, and it took a while to determine what was happening.
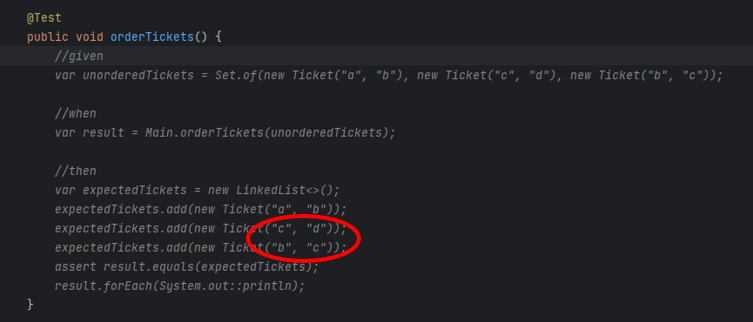
It leads us to the main issue related to Tabnine. It generates simple code, which saves a few seconds each time, but it's unreliable, produces hard-to-find bugs, and requires more time to validate the generated code than saves by the generation. Moreover, it generates proposals constantly, so the developer spends more time reading propositions than actually creating good code.
Our rating
Conclusion: A mature tool with average possibilities, sometimes too aggressive and obtrusive (annoying), but with a little bit of practice, may also make work easier
‒ Possibilities 3/5
‒ Correctness 2/5
‒ Easiness 2,5/5
‒ Privacy 5/5
‒ Maturity 4/5
Overall score: 3/5
GitHub Copilot
This tool is state-of-the-art. There are tools "similar to GitHub Copilot," "alternative to GitHub Copilot," and "comparable to GitHub Copilot," and there is the GitHub Copilot itself. It is precisely what you think it is – a code-completion tool based on the OpenAI Codex model, which is based on GPT-3 but trained with publicly available sources, including GitHub repositories. You can install it as a plugin for popular IDEs, but you need to enable it on your GitHub account first. A free trial is available, and the standard license costs from $8,33 to $19 per user per month.
The good, the bad, and the ugly
It works just fine. It generates good one-liners and imitates the style of the code around.
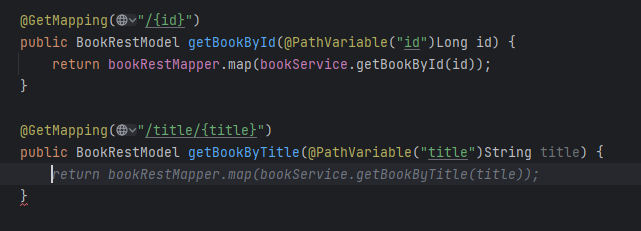
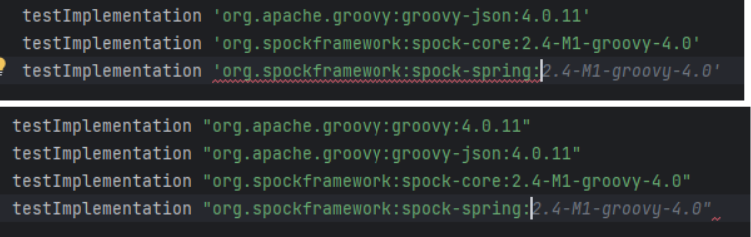
Please note the Figure 6 - it not only uses closing quotas as needed but also proposes a library in the "guessed" version, as spock-spring.spockgramework.org:2.4-M1-groovy-4.0 is newer than the learning set of the model.
However, the code is not perfect.
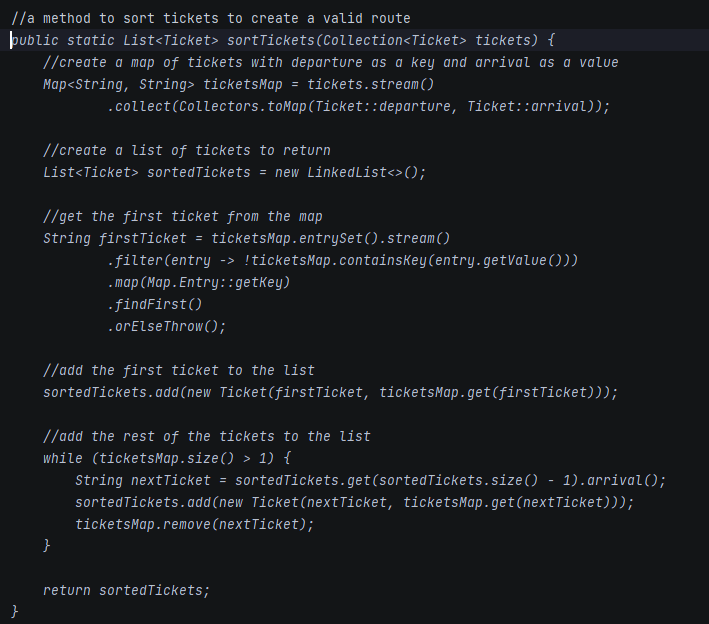
In this test, the tool generated the entire method based on the comment from the first line of the listing. It decided to create a map of departures and arrivals as Strings, to re-create tickets when adding to sortedTickets, and to remove elements from ticketMaps. Simply speaking - I wouldn't like to maintain such a code in my project. GPT-4 and Claude do the same job much better.
The general rule of using this tool is – don't ask it to produce a code that is too long. As mentioned above – it is what you think it is, so it's just a copilot which can give you a hand in simple tasks, but you still take responsibility for the most important parts of your project. Compared to Tabnine, GitHub Copilot doesn't propose a bunch of code every few keys pressed, and it produces less readable code but with fewer errors, making it a better companion in everyday life.
Our rating
Conclusion: Generates worse code than GPT-4 and doesn't offer extra functionalities ("explain," "fix bugs," etc.); however, it's unobtrusive, convenient, correct when short code is generated and makes everyday work easier
‒ Possibilities 3/5
‒ Correctness 4/5
‒ Easiness 5/5
‒ Privacy 5/5
‒ Maturity 4/5
Overall score: 4/5
GitHub Copilot Labs
The base GitHub copilot, as described above, is a simple code-completion tool. However, there is a beta tool called GitHub Copilot Labs. It is a Visual Studio Code plugin providing a set of useful AI-powered functions: explain, language translation, Test Generation, and Brushes (improve readability, add types, fix bugs, clean, list steps, make robust, chunk, and document). It requires a Copilot subscription and offers extra functionalities – only as much, and so much.
The good, the bad, and the ugly
If you are a Visual Studio Code user and you already use the GitHub Copilot, there is no reason not to use the "Labs" extras. However, you should not trust it. Code explanation works well, code translation is rarely used and sometimes buggy (the Python version of my Java code tries to call non-existing functions, as the context was not considered during translation), brushes work randomly (sometimes well, sometimes badly, sometimes not at all), and test generation works for JS and TS languages only.
Our rating
Conclusion: It's a nice preview of something between Copilot and Copilot X, but it's in the preview stage and works like a beta. If you don't expect too much (and you use Visual Studio Code and GitHub Copilot), it is a tool for you.
‒ Possibilities 4/5
‒ Correctness 2/5
‒ Easiness 5/5
‒ Privacy 5/5
‒ Maturity 1/5
Overall score: 3/5
Cursor
Cursor is a complete IDE forked from Visual Studio Code open-source project. It uses OpenAI API in the backend and provides a very straightforward user interface. You can press CTRL+K to generate/edit a code from the prompt or CTRL+L to open a chat within an integrated window with the context of the open file or the selected code fragment. It is as good and as private as the OpenAI models behind it but remember to disable prompt collection in the settings if you don't want to share it with the entire World.
The good, the bad, and the ugly
Cursor seems to be a very nice tool – it can generate a lot of code from prompts. Be aware that it still requires developer knowledge – "a function to read an mp3 file by name and use OpenAI SDK to call OpenAI API to use 'whisper-1' model to recognize the speech and store the text in a file of same name and txt extension" is not a prompt that your accountant can make. The tool is so good that a developer used to one language can write an entire application in another one. Of course, they (the developer and the tool) can use bad habits together, not adequate to the target language, but it's not the fault of the tool but the temptation of the approach.
There are two main disadvantages of Cursor.
Firstly, it uses OpenAI API, which means it can use up to GPT-3.5 or Codex (for mid-May 2023, there is no GPT-4 API available yet), which is much worse than even general-purpose GPT-4. For example, Cursor asked to explain some very bad code has responded with a very bad answer.
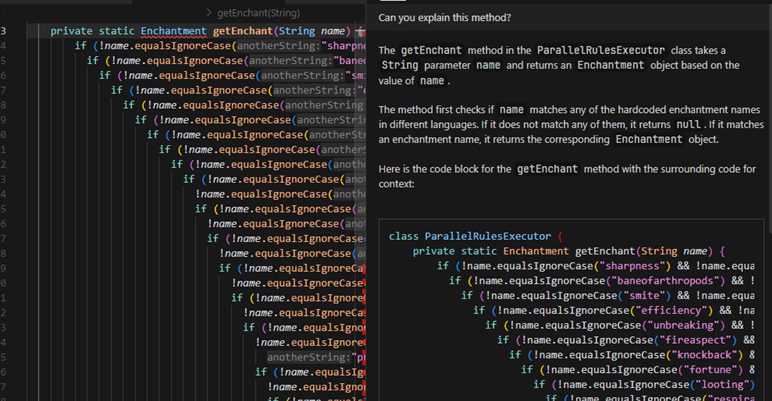
For the same code, GPT-4 and Claude were able to find the purpose of the code and proposed at least two better solutions (with a multi-condition switch case or a collection as a dataset). I would expect a better answer from a developer-tailored tool than a general-purpose web-based chat.


Secondly, Cursor uses Visual Studio Code, but it's not just a branch of it – it's an entire fork, so it can be potentially hard to maintain, as VSC is heavily changed by a community. Besides that, VSC is as good as its plugins, and it works much better with C, Python, Rust, and even Bash than Java or browser-interpreted languages. It's common to use specialized, commercial tools for specialized use cases, so I would appreciate Cursor as a plugin for other tools rather than a separate IDE.
There is even a feature available in Cursor to generate an entire project by prompt, but it doesn't work well so far. The tool has been asked to generate a CRUD bookstore in Java 18 with a specific architecture. Still, it has used Java 8, ignored the architecture, and produced an application that doesn't even build due to Gradle issues. To sum up – it's catchy but immature.
The prompt used in the following video is as follows:
"A CRUD Java 18, Spring application with hexagonal architecture, using Gradle, to manage Books. Each book must contain author, title, publisher, release date and release version. Books must be stored in localhost PostgreSQL. CRUD operations available: post, put, patch, delete, get by id, get all, get by title."
https://www.youtube.com/watch?v=Q2czylS2i-E
The main problem is – the feature has worked only once, and we were not able to repeat it.
Our rating
Conclusion: A complete IDE for VS-Code fans. Worth to be observed, but the current version is too immature.
‒ Possibilities 5/5
‒ Correctness 2/5
‒ Easiness 4/5
‒ Privacy 5/5
‒ Maturity 1/5
Overall score: 2/5
Amazon CodeWhisperer
CodeWhisperer is an AWS response to Codex. It works in Cloud9 and AWS Lambdas, but also as a plugin for Visual Studio Code and some JetBrains products. It somehow supports 14 languages with full support for 5 of them. By the way, most tool tests work better with Python than Java – it seems AI tool creators are Python developers🤔. CodeWhisperer is free so far and can be run on a free tier AWS account (but it requires SSO login) or with AWS Builder ID.
The good, the bad, and the ugly
There are a few positive aspects of CodeWhisperer. It provides an extra code analysis for vulnerabilities and references, and you can control it with usual AWS methods (IAM policies), so you can decide about the tool usage and the code privacy with your standard AWS-related tools.
However, the quality of the model is insufficient. It doesn't understand more complex instructions, and the code generated can be much better.
For example, it has simply failed for the case above, and for the case below, it proposed just a single assertion.
Our rating
Conclusion: Generates worse code than GPT-4/Claude or even Codex (GitHub Copilot), but it's highly integrated with AWS, including permissions/privacy management
‒ Possibilities 2.5/5
‒ Correctness 2.5/5
‒ Easiness 4/5
‒ Privacy 4/5
‒ Maturity 3/5
Overall score: 2.5/5
Plugins
As the race for our hearts and wallets has begun, many startups, companies, and freelancers want to participate in it. There are hundreds (or maybe thousands) of plugins for IDEs that send your code to OpenAI API.
You can easily find one convenient to you and use it as long as you trust OpenAI and their privacy policy. On the other hand, be aware that your code will be processed by one more tool, maybe open-source, maybe very simple, but it still increases the possibility of code leaks. The proposed solution is – to write an own plugin. There is a space for one more in the World for sure.
Knocked out tools
There are plenty of tools we've tried to evaluate, but those tools were too basic, too uncertain, too troublesome, or simply deprecated, so we have decided to eliminate them before the full evaluation. Here you can find some examples of interesting ones but rejected.
Captain Stack
According to the authors, the tool is "somewhat similar to GitHub Copilot's code suggestion," but it doesn't use AI – it queries your prompt with Google, opens Stack Overflow, and GitHub gists results and copies the best answer. It sounds promising, but using it takes more time than doing the same thing manually. It doesn't provide any response very often, doesn't provide the context of the code sample (explanation given by the author), and it has failed all our tasks.
IntelliCode
The tool is trained on thousands of open-source projects on GitHub, each with high star ratings. It works with Visual Studio Code only and suffers from poor Mac performance. It is useful but very straightforward – it can find a proper code but doesn't work well with a language. You need to provide prompts carefully; the tool seems to be just an indexed-search mechanism with low intelligence implemented.
Kite
Kite was an extremely promising tool in development since 2014, but "was" is the keyword here. The project was closed in 2022, and the authors' manifest can bring some light into the entire developer-friendly Generative AI tools: Kite is saying farewell - Code Faster with Kite . Simply put, they claimed it's impossible to train state-of-the-art models to understand more than a local context of the code, and it would be extremely expensive to build a production-quality tool like that. Well, we can acknowledge that most tools are not production-quality yet, and the entire reliability of modern AI tools is still quite low.
GPT-Code-Clippy
The GPT-CC is an open-source version of GitHub Copilot. It's free and open, and it uses the Codex model. On the other hand, the tool has been unsupported since the beginning of 2022, and the model is deprecated by OpenAI already, so we can consider this tool part of the Generative AI history.
CodeGeeX
CodeGeeX was published in March 2023 by Tsinghua University's Knowledge Engineering Group under Apache 2.0 license. According to the authors, it uses 13 billion parameters, and it's trained on public repositories in 23 languages with over 100 stars. The model can be your self-hosted GitHub Copilot alternative if you have at least Nvidia GTX 3090, but it's recommended to use A100 instead.
The online version was occasionally unavailable during the evaluation, and even when available - the tool failed on half of our tasks. There was no even a try, and the response from the model was empty. Therefore, we've decided not to try the offline version and skip the tool completely.
GPT
Crème de la crème of the comparison is the OpenAI flagship - generative pre-trained transformer (GPT). There are two important versions available for today – GPT-3.5 and GPT-4. The former version is free for web users as well as available for API users. GPT-4 is much better than its predecessor but is still not generally available for API users. It accepts longer prompts and "remembers" longer conversations. All in all, it generates better answers. You can give a chance of any task to GPT-3.5, but in most cases, GPT-4 does the same but better.
So what can GPT do for developers?
We can ask the chat to generate functions, classes, or entire CI/CD workflows. It can explain the legacy code and propose improvements. It discusses algorithms, generates DB schemas, tests, UML diagrams as code, etc. It can even run a job interview for you, but sometimes it loses the context and starts to chat about everything except the job.
The dark side contains three main aspects so far. Firstly, it produces hard-to-find errors. There may be an unnecessary step in CI/CD, the name of the network interface in a Bash script may not exist, a single column type in SQL DDL may be wrong, etc. Sometimes it requires a lot of work to find and eliminate the error; what is more important with the second issue – it pretends to be unmistakable. It seems so brilliant and trustworthy, so it's common to overrate and overtrust it and finally assume that there is no error in the answer. The accuracy and purity of answers and deepness of knowledge showed made an impression that you can trust the chat and apply results without meticulous analysis.
The last issue is much more technical – GPT-3.5 can accept up to 4k tokens which is about 3k words. It's not enough if you want to provide documentation, an extended code context, or even requirements from your customer. GPT-4 offers up to 32k tokens, but it's unavailable via API so far.
There is no rating for GPT. It's brilliant, and astonishing, yet still unreliable, and it still requires a resourceful operator to make correct prompts and analyze responses. And it makes operators less resourceful with every prompt and response because people get lazy with such a helper. During the evaluation, we've started to worry about Sarah Conor and her son, John, because GPT changes the game's rules, and it is definitely a future.
OpenAI API
Another side of GPT is the OpenAI API. We can distinguish two parts of it.
Chat models
The first part is mostly the same as what you can achieve with the web version. You can use up to GPT-3.5 or some cheaper models if applicable to your case. You need to remember that there is no conversation history, so you need to send the entire chat each time with new prompts. Some models are also not very accurate in "chat" mode and work much better as a "text completion" tool. Instead of asking, "Who was the first president of the United States?" your query should be, "The first president of the United States was." It's a different approach but with similar possibilities.
Using the API instead of the web version may be easier if you want to adapt the model for your purposes (due to technical integration), but it can also give you better responses. You can modify "temperature" parameters making the model stricter (even providing the same results on the same requests) or more random. On the other hand, you're limited to GPT-3.5 so far, so you can't use a better model or longer prompts.
Other purposes models
There are some other models available via API. You can use Whisper as a speech-to-text converter, Point-E to generate 3D models (point cloud) from prompts, Jukebox to generate music, or CLIP for visual classification. What's important – you can also download those models and run them on your own hardware at costs. Just remember that you need a lot of time or powerful hardware to run the models – sometimes both.
There is also one more model not available for downloading – the DALL-E image generator. It generates images by prompts, doesn't work with text and diagrams, and is mostly useless for developers. But it's fancy, just for the record.
The good part of the API is the official library availability for Python and Node.js, some community-maintained libraries for other languages, and the typical, friendly REST API for everybody else.
The bad part of the API is that it's not included in the chat plan, so you pay for each token used. Make sure you have a budget limit configured on your account because using the API can drain your pockets much faster than you expect.
Fine-tuning
Fine-tuning of OpenAI models is de facto a part of the API experience, but it desires its own section in our deliberations. The idea is simple – you can use a well-known model but feed it with your specific data. It sounds like medicine for token limitation. You want to use a chat with your domain knowledge, e.g., your project documentation, so you need to convert the documentation to a learning set, tune a model, and you can use the model for your purposes inside your company (the fine-tunned model remains private at company level).
Well, yes, but actually, no.
There are a few limitations to consider. The first one – the best model you can tune is Davinci, which is like GPT-3.5, so there is no way to use GPT-4-level deduction, cogitation, and reflection. Another issue is the learning set. You need to follow very specific guidelines to provide a learning set as prompt-completion pairs, so you can't simply provide your project documentation or any other complex sources. To achieve better results, you should also keep the prompt-completion approach in further usage instead of a chat-like question-answer conversation. The last issue is cost efficiency. Teaching Davinci with 5MB of data costs about $200, and 5MB is not a great set, so you probably need more data to achieve good results. You can try to reduce cost by using the 10 times cheaper Curie model, but it's also 10 times smaller (more like GPT-3 than GPT-3.5) than Davinci and accepts only 2k tokens for a single question-answer pair in total.
Embedding
Another feature of the API is called embedding. It's a way to change the input data (for example, a very long text) into a multi-dimensional vector. You can consider this vector a representation of your knowledge in a format directly understandable by the AI. You can save such a model locally and use it in the following scenarios: data visualization, classification, clustering, recommendation, and search. It's a powerful tool for specific use cases and can solve business-related problems. Therefore, it's not a helper tool for developers but a potential base for an engine of a new application for your customer.
Claude
Claude from Anthropic, an ex-employees of OpenAI, is a direct answer to GPT-4. It offers a bigger maximum token size (100k vs. 32k), and it's trained to be trustworthy, harmless, and better protected from hallucinations. It's trained using data up to spring 2021, so you can't expect the newest knowledge from it. However, it has passed all our tests, works much faster than the web GPT-4, and you can provide a huge context with your prompts. For some reason, it produces more sophisticated code than GPT-4, but It's on you to pick the one you like more.
If needed, a Claude API is available with official libraries for some popular languages and the REST API version. There are some shortcuts in the documentation, the web UI has some formation issues, there is no free version available, and you need to be manually approved to get access to the tool, but we assume all of those are just childhood problems.
Claude is so new, so it's really hard to say if it is better or worse than GPT-4 in a job of a developer helper, but it's definitely comparable, and you should probably give it a shot.
Unfortunately, the privacy policy of Anthropic is quite confusing, so we don't recommend posting confidential information to the chat yet.
Internet-accessing generative AI tools
The main disadvantage of ChatGPT, raised since it has generally been available, is no knowledge about recent events, news, and modern history. It's already partially fixed, so you can feed a context of the prompt with Internet search results. There are three tools worth considering for such usage.
Microsoft Bing
Microsoft Bing was the first AI-powered Internet search engine. It uses GPT to analyze prompts and to extract information from web pages; however, it works significantly worst than pure GPT. It has failed in almost all our programming evaluations, and it falls into an infinitive loop of the same answers if the problem is concealed. On the other hand, it provides references to the sources of its knowledge, can read transcripts from YouTube videos, and can aggregate the newest Internet content.
Chat-GPT with Internet access
The new mode of Chat-GPT (rolling out for premium users in mid-May 2023) can browse the Internet and scrape web pages looking for answers. It provides references and shows visited pages. It seems to work better than Bing, probably because it's GPT-4 powered compared to GPT-3.5. It also uses the model first and calls the Internet only if it can't provide a good answer to the question-based trained data solitary.
It usually provides better answers than Bing and may provide better answers than the offline GPT-4 model. It works well with questions you can answer by yourself with an old-fashion search engine (Google, Bing, whatever) within one minute, but it usually fails with more complex tasks. It's quite slow, but you can track the query's progress on UI.
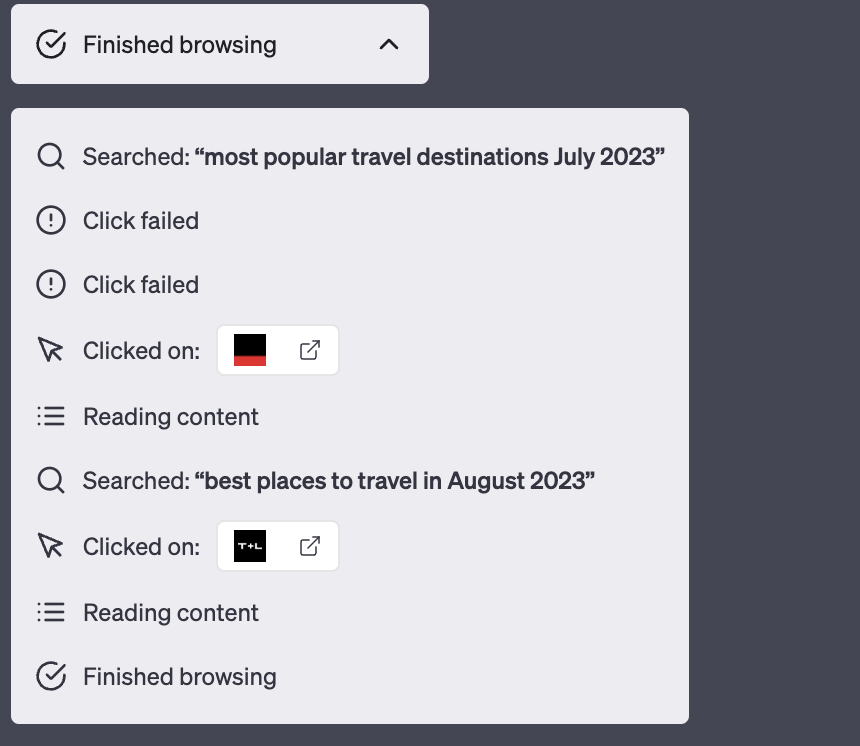
Importantly, and you should keep this in mind, Chat-GPT sometimes provides better responses with offline hallucinations than with Internet access.
For all those reasons, we don't recommend using Microsoft Bing and Chat-GPT with Internet access for everyday information-finding tasks. You should only take those tools as a curiosity and query Google by yourself.
Perplexity
At first glance, Perplexity works in the same way as both tools mentioned – it uses Bing API and OpenAI API to search the Internet with the power of the GPT model. On the other hand, it offers search area limitations (academic resources only, Wikipedia, Reddit, etc.), and it deals with the issue of hallucinations by strongly emphasizing citations and references. Therefore, you can expect more strict answers and more reliable references, which can help you when looking for something online. You can use a public version of the tool, which uses GPT-3.5, or you can sign up and use the enhanced GPT-4-based version.
We found Perplexity better than Bing and Chat-GPT with Internet Access in our evaluation tasks. It's as good as the model behind it (GPT-3.5 or GPT-4), but filtering references and emphasizing them does the job regarding the tool's reliability.
For mid-May 2023 the tool is still free.
Google Bard
It's a pity, but when writing this text, Google's answer for GPT-powered Bing and GPT itself is still not available in Poland, so we can't evaluate it without hacky solutions (VPN).
Using Internet access in general
If you want to use a generative AI model with Internet access, we recommend using Perplexity. However, you need to keep in mind that all those tools are based on Internet search engines which base on complex and expensive page positioning systems. Therefore, the answer "given by the AI" is, in fact, a result of marketing actions that brings some pages above others in search results. In other words, the answer may suffer from lower-quality data sources published by big players instead of better-quality ones from independent creators. Moreover, page scrapping mechanisms are not perfect yet, so you can expect a lot of errors during the usage of the tools, causing unreliable answers or no answers at all.
Offline models
If you don't trust legal assurance and you are still concerned about the privacy and security of all the tools mentioned above, so you want to be technically insured that all prompts and responses belong to you only, you can consider self-hosting a generative AI model on your hardware. We've already mentioned 4 models from OpenAI (Whisper, Point-E, Jukebox, and CLIP), Tabnine, and CodeGeeX, but there are also a few general-purpose models worth consideration. All of them are claimed to be best-in-class and similar to OpenAI's GPT, but it's not all true.
Only free commercial usage models are listed below. We’ve focused on pre-trained models, but you can train or just fine-tune them if needed. Just remember the training may be even 100 times more resource consuming than usage.
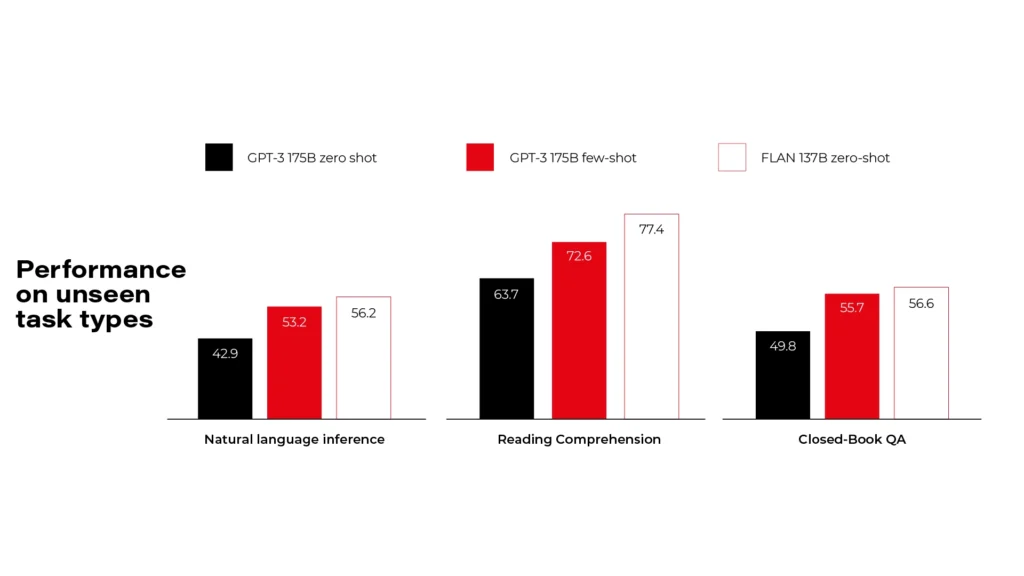
Flan-UL2 and Flan-T5-XXL
Flan models are made by Google and released under Apache 2.0 license. There are more versions available, but you need to pick a compromise between your hardware resources and the model size. Flan-UL2 and Flan-T5-XXL use 20 billion and 11 billion parameters and require 4x Nvidia T4 or 1x Nvidia A6000 accordingly. As you can see on the diagrams, it's comparable to GPT-3, so it's far behind the GPT-4 level.
BLOOM
BigScience Large Open-Science Open-Access Multilingual Language Model is a common work of over 1000 scientists. It uses 176 billion parameters and requires at least 8x Nvidia A100 cards. Even if it's much bigger than Flan, it's still comparable to OpenAI's GPT-3 in tests. Actually, it's the best model you can self-host for free that we've found so far.
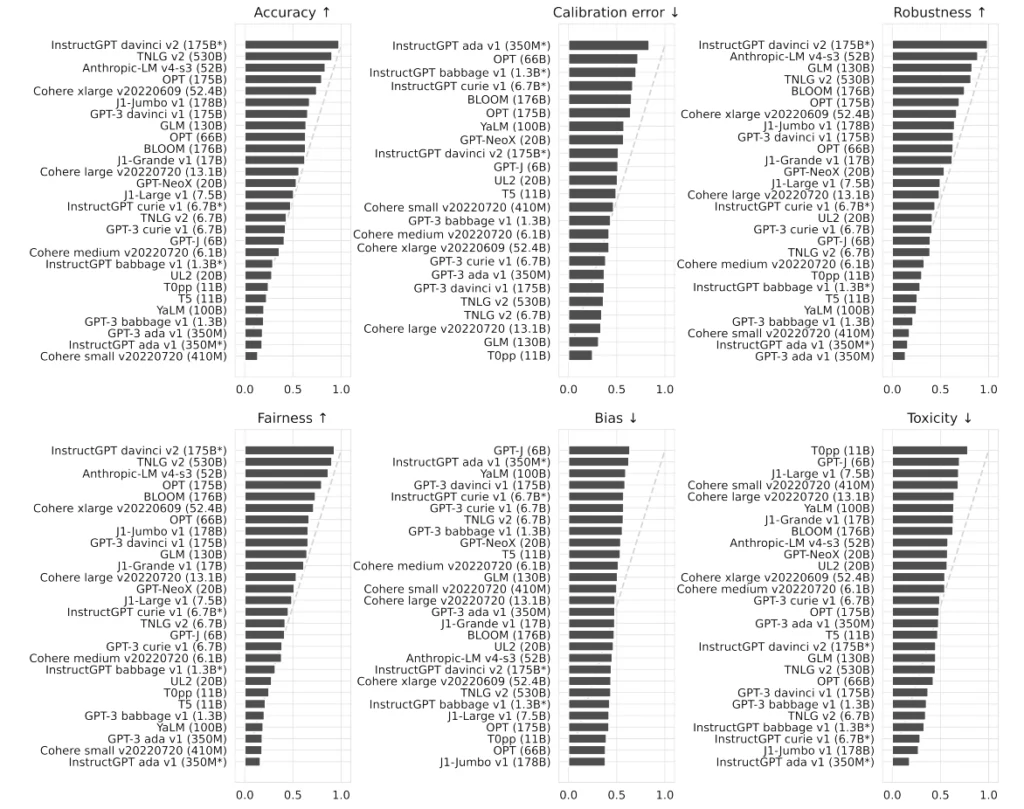
GLM-130B
General Language Model with 130 billion parameters, published by CodeGeeX authors. It requires similar computing power to BLOOM and can overperform it in some MMLU benchmarks. It's smaller and faster because it's bilingual (English and Chinese) only, but it may be enough for your use cases.
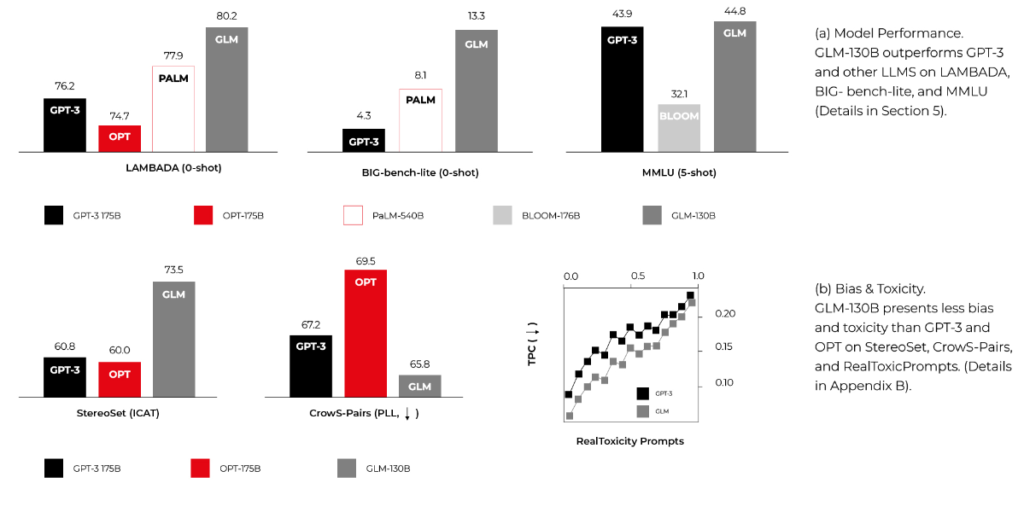
Summary
When we approached the research, we were worried about the future of developers. There are a lot of click-bite articles over the Internet showing Generative AI creating entire applications from prompts within seconds. Now we know that at least our near future is secured.
We need to remember that code is the best product specification possible, and the creation of good code is possible only with a good requirement specification. As business requirements are never as precise as they should be, replacing developers with machines is impossible. Yet.
However, some tools may be really advantageous and make our work faster. Using GitHub Copilot may increase the productivity of the main part of our job – code writing. Using Perplexity, GPT-4, or Claude may help us solve problems. There are some models and tools (for developers and general purposes) available to work with full discreteness, even technically enforced. The near future is bright – we expect GitHub Copilot X to be much better than its predecessor, we expect the general purposes language model to be more precise and helpful, including better usage of the Internet resources, and we expect more and more tools to show up in next years, making the AI race more compelling.
On the other hand, we need to remember that each helper (a human or machine one) takes some of our independence, making us dull and idle. It can change the entire human race in the foreseeable future. Besides that, the usage of Generative AI tools consumes a lot of energy by rare metal-based hardware, so it can drain our pockets now and impact our planet soon.
This article has been 100% written by humans up to this point, but you can definitely expect less of that in the future.

Accelerating data projects with parallel computing
Inspired by Petabyte Scale Solutions from CERN
The Large Hadron Collider (LHC) accelerator is the biggest device humankind has ever created. Handling enormous amounts of data it produces has required one of the biggest computational infrastructures on the earth. However, it is quite easy to overwhelm even the best supercomputer with inefficient algorithms that do not correctly utilize the full power of underlying, highly parallel hardware. In this article, I want to share insights born from my meeting with the CERN people, particularly how to validate and improve parallel computing in the data-driven world.
Struggling with data on the scale of megabytes (10 6 ) to gigabytes (10 9 ) is the bread and butter for data engineers, data scientists, or machine learning engineers. Moving forward, the terabyte (10 12 ) and petabyte (10 15 ) scale is becoming increasingly ordinary, and the chances of dealing with it in everyday data-related tasks keep growing. Although the claim "Moore's law is dead!" is quite a controversial one, the fact is that single-thread performance improvement has slowed down significantly since 2005. This is primarily due to the inability to increase the clock frequency indefinitely. The solution is parallelization - mainly by an increase in the numbers of logical cores available for one processing unit.
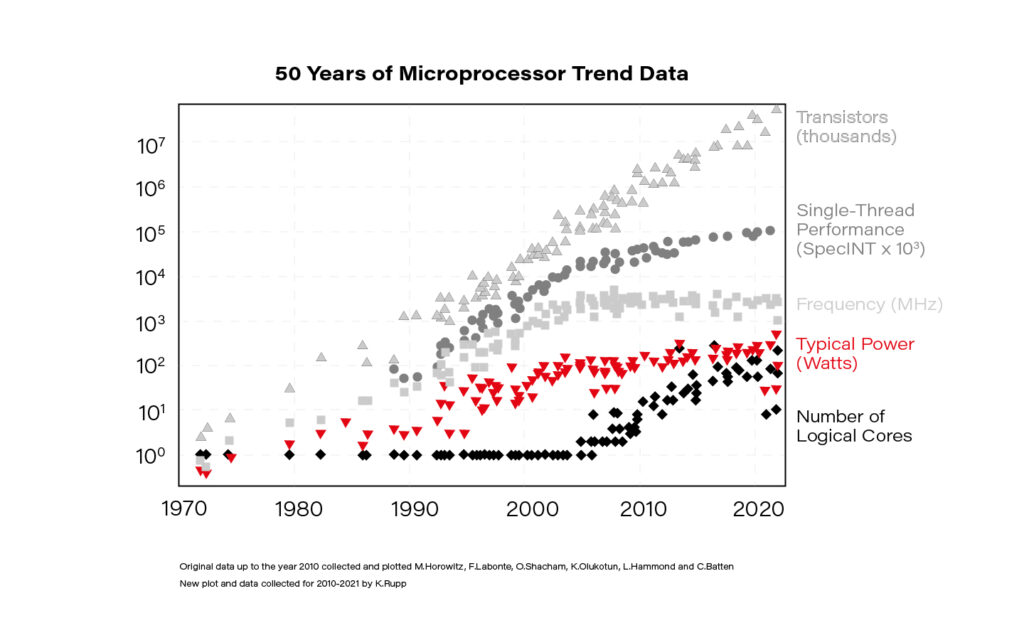
Knowing it, the ability to properly parallelize computations is increasingly important.
In a data-driven world, we have a lot of ready-to-use, very good solutions that do most of the parallel stuff on all possible levels for us and expose easy-to-use API. For example, on a large scale, Spark or Metaflow are excellent tools for distributed computing; at the other end, NumPy enables Python users to do very efficient matrix operations on the CPU, something Python is not good at all, by integrating C, C++, and Fortran code with friendly snake_case API. Do you think it is worth learning how it is done behind the scenes if you have packages that do all this for you? I honestly believe this knowledge can only help you use these tools more effectively and will allow you to work much faster and better in an unknown environment.
The LHC lies in a tunnel 27 kilometers (about 16.78 mi) in circumference, 175 meters (about 574.15 ft) under a small city built for that purpose on the France–Switzerland border. It has four main particle detectors that collect enormous amounts of data: ALICE, ATLAS, LHCb, and CMS. The LHCb detector alone collects about 40 TB of raw data every second. Many data points come in the form of images since LHCb takes 41 megapixels resolution photos every 25 ns. Such a huge amount of data must be somehow compressed and filtered before permanent storage. From the initial 40 TB/s, only 10G GB/s are saved on disk – the compression ratio is 1:4000!
It was a surprise for me that about 90% of CPU usage in LHCb is done on simulation. One may wonder why they simulate the detector. One of the reasons is that a particle detector is a complicated machine, and scientists at CERN use, i.e., Monte Carlo methods to understand the detector and the biases. Monte Carlo methods can be suitable for massively parallel computing in physics.

Let us skip all the sophisticated techniques and algorithms used at CERN and focus on such aspects of parallel computing, which are common regardless of the problem being solved. Let us divide the topic into four primary areas:
- SIMD,
- multitasking and multiprocessing,
- GPGPU,
- and distributed computing.
The following sections will cover each of them in detail.
SIMD
The acronym SIMD stands for Single Instruction Multiple Data and is a type of parallel processing in Flynn's taxonomy .
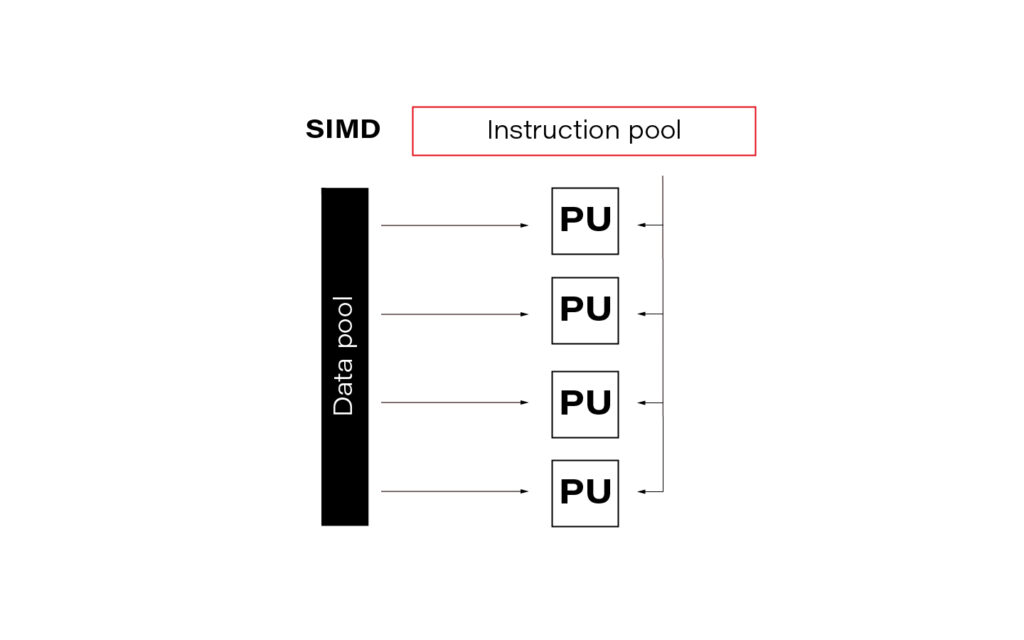
In the data science world, this term is often so-called vectorization. In practice, it means simultaneously performing the same operation on multiple data points (usually represented as a matrix). Modern CPUs and GPGPUs often have dedicated instruction sets for SIMD; examples are SSE and MMX. SIMD vector size has significantly increased over time.
Publishers of the SIMD instruction sets often create language extensions (typically using C/C++) with intrinsic functions or special datatypes that guarantee vector code generation. A step further is abstracting them into a universal interface, e.g., std::experimental::simd from C++ standard library. LLVM's (Low Level Virtual Machine) libcxx implements it (at least partially), allowing languages based on LLVM (e.g., Julia, Rust) to use IR (Intermediate Representation – code language used internally for LLVM's purposes) code for implicit or explicit vectorization. For example, in Julia, you can, if you are determined enough, access LLVM IR using macro @code_llvm and check your code for potential automatic vectorization.
In general, there are two main ways to apply vectorization to the program:
- auto-vectorization handled by compilers,
- and rewriting algorithms and data structures.
For a dev team at CERN, the second option turned out to be better since auto-vectorization did not work as expected for them. One of the CERN software engineers claimed that "vectorization is a killer for the performance." They put a lot of effort into it, and it was worth it. It is worth noting here that in data teams at CERN, Python is the language of choice, while C++ is preferred for any performance-sensitive task.
How to maximize the advantages of SIMD in everyday practice? Difficult to answer; it depends, as always. Generally, the best approach is to be aware of this effect every time you run heavy computation. In modern languages like Julia or best compilers like GCC, in many cases, you can rely on auto-vectorization. In Python, the best bet is the second option, using dedicated libraries like NumPy. Here you can find some examples of how to do it.
Below you can find a simple benchmarking presenting clearly that vectorization is worth attention.
import numpy as np
from timeit import Timer
# Using numpy to create a large array of size 10**6
array = np.random.randint(1000, size=10**6)
# method that adds elements using for loop
def add_forloop():
new_array = [element + 1 for element in array]
# Method that adds elements using SIMD
def add_vectorized():
new_array = array + 1
# Computing execution time
computation_time_forloop = Timer(add_forloop).timeit(1)
computation_time_vectorized = Timer(add_vectorized).timeit(1)
# Printing results
print(execution_time_forloop) # gives 0.001202600
print(execution_time_vectorized) # gives 0.000236700
Multitasking and Multiprocessing
Let us start with two confusing yet important terms which are common sources of misunderstanding:
- concurrency: one CPU, many tasks,
- parallelism: many CPUs, one task.
Multitasking is about executing multiple tasks concurrently at the same time on one CPU. A scheduler is a mechanism that decides what the CPU should focus on at each moment, giving the impression that multiple tasks are happening simultaneously. Schedulers can work in two modes:
- preemptive,
- and cooperative.
A preemptive scheduler can halt, run, and resume the execution of a task. This happens without the knowledge or agreement of the task being controlled.
On the other hand, a cooperative scheduler lets the running process decide when the processes voluntarily yield control or when idle or blocked, allowing multiple applications to execute simultaneously.
Switching context in cooperative multitasking can be cheap because parts of the context may remain on the stack and be stored on the higher levels in the memory hierarchy (e.g., L3 cache). Additionally, code can stay close to the CPU for as long as it needs without interruption.
On the other hand, the preemptive model is good when a controlled task behaves poorly and needs to be controlled externally. This may be especially useful when working with external libraries which are out of your control.
Multiprocessing is the use of two or more CPUs within a single Computer system. It is of two types:
- Asymmetric - not all the processes are treated equally; only a master processor runs the tasks of the operating system.
- Symmetric - two or more processes are connected to a single, shared memory and have full access to all input and output devices.
I guess that symmetric multiprocessing is what many people intuitively understand as typical parallelism.
Below are some examples of how to do simple tasks using cooperative multitasking, preemptive multitasking, and multiprocessing in Python. The table below shows which library should be used for each purpose.
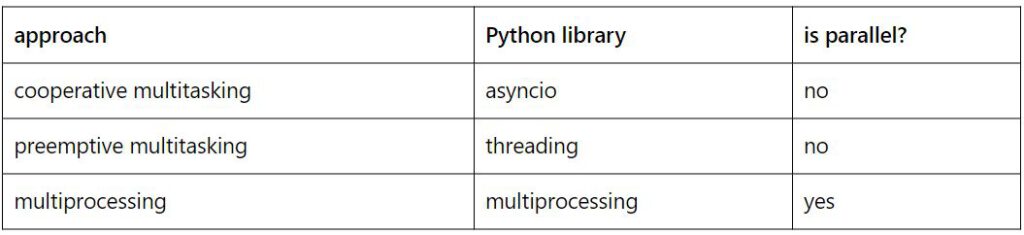
- Cooperative multitasking example:
import asyncio
import sys
import time
# Define printing loop
async def print_time():
while True:
print(f"hello again [{time.ctime()}]")
await asyncio.sleep(5)
# Define stdin reader
def echo_input():
print(input().upper())
# Main function with event loop
async def main():
asyncio.get_event_loop().add_reader(
sys.stdin,
echo_input
)
await print_time()
# Entry point
asyncio.run(main())
Just type something and admire the uppercase response.
- Preemptive multitasking example:
import threading
import time
# Define printing loop
def print_time():
while True:
print(f"hello again [{time.ctime()}]")
time.sleep(5)
# Define stdin reader
def echo_input():
while True:
message = input()
print(message.upper())
# Spawn threads
threading.Thread(target=print_time).start()
threading.Thread(target=echo_input).start()
The usage is the same as in the example above. However, the program may be less predictable due to the preemptive nature of the scheduler.
- Multiprocessing example:
import time
import sys
from multiprocessing import Process
# Define printing loop
def print_time():
while True:
print(f"hello again [{time.ctime()}]")
time.sleep(5)
# Define stdin reader
def echo_input():
sys.stdin = open(0)
while True:
message = input()
print(message.upper())
# Spawn processes
Process(target=print_time).start()
Process(target=echo_input).start()
Notice that we must open stdin for the echo_input process because this is an exclusive resource and needs to be locked.
In Python, it may be tempting to use multiprocessing anytime you need accelerated computations. But processes cannot share resources while threads / asyncs can. This is because a process works with many CPUs (with separate contexts) while threads / asyncs are stuck to one CPU. So, you must use synchronization primitives (e.g., mutexes or atomics), which complicates source code. No clear winner here; only trade-offs to consider.
Although that is a complex topic, I will not cover it in detail as it is uncommon for data projects to work with them directly. Usually, external libraries for data manipulation and data modeling encapsulate the appropriate code. However, I believe that being aware of these topics in contemporary software is particularly useful knowledge that can significantly accelerate your code in unconventional situations.
You may find other meanings of the terminology used here. After all, it is not so important what you call it but rather how to choose the right solution for the problem you are solving.
GPGPU
General-purpose computing on graphics processing units (GPGPU) utilizes shaders to perform massive parallel computations in applications traditionally handled by the central processing unit.
In 2006 Nvidia invented Compute Unified Device Architecture (CUDA) which soon dominated the machine learning models acceleration niche. CUDA is a computing platform and offers API that gives you direct access to parallel computation elements of GPU through the execution of computer kernels.
Returning to the LHCb detector, raw data is initially processed directly on CPUs operating on detectors to reduce network load. But the whole event may be processed on GPU if the CPU is busy. So, GPUs appear early in the data processing chain.
GPGPU's importance for data modeling and processing at CERN is still growing. The most popular machine learning models they use are decision trees (boosted or not, sometimes ensembled). Since deep learning models are harder to use, they are less popular at CERN, but their importance is still rising. However, I am quite sure that scientists worldwide who work with CERN's data use the full spectrum of machine learning models.
To accelerate machine learning training and prediction with GPGPU and CUDA, you need to create a computing kernel or leave that task to the libraries' creators and use simple API instead. The choice, as always, depends on what goals you want to achieve.
For a typical machine learning task, you can use any machine learning framework that supports GPU acceleration; examples are TensorFlow, PyTorch, or cuML , whose API mirrors Sklearn's. Before you start accelerating your algorithms, ensure that the latest GPU driver and CUDA driver are installed on your computer and that the framework of choice is installed with an appropriate flag for GPU support. Once the initial setup is done, you may need to run some code snippet that switches computation from CPU (typically default) to GPU. For instance, in the case of PyTorch, it may look like that:
import torch
torch.cuda.is_available()
def get_default_device():
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
device = get_default_device()
device
Depending on the framework, at this point, you can process as always with your model or not. Some frameworks may require, e. g. explicit transfer of the model to the GPU-specific version. In PyTorch, you can do it with the following code:
net = MobileNetV3()
net = net.cuda()
At this point, we usually should be able to run .fit(), .predict(), .eval(), or something similar. Looks simple, doesn't it?
Writing a computing kernel is much more challenging. However, there is nothing special about computing kernel in this context, just a function that runs on GPU.
Let's switch to Julia; it is a perfect language for learning GPU computing. You can get familiar with why I prefer Julia for some machine learning projects here . Check this article if you need a brief introduction to the Julia programming language.
Data structures used must have an appropriate layout to enable performance boost. Computers love linear structures like vectors and matrices and hate pointers, e. g. in linked lists. So, the very first step to talking to your GPU is to present a data structure that it loves.
using Cuda
# Data structures for CPU
N = 2^20
x = fill(1.0f0, N) # a vector filled with 1.0
y = fill(2.0f0, N) # a vector filled with 2.0
# CPU parallel adder
function parallel_add!(y, x)
Threads.@threads for i in eachindex(y, x)
@inbounds y[i] += x[i]
end
return nothing
end
# Data structures for GPU
x_d = CUDA.fill(1.0f0, N)
# a vector stored on the GPU filled with 1.0
y_d = CUDA.fill(2.0f0, N)
# a vector stored on the GPU filled with 2.0
# GPU parallel adder
function gpu_add!(y, x)
CUDA.@sync y .+= x
return
end
GPU code in this example is about 4x faster than the parallel CPU version. Look how simple it is in Julia! To be honest, it is a kernel imitation on a very high level; a more real-life example may look like this:
function gpu_add_kernel!(y, x)
index = (blockIdx().x - 1) * blockDim().x + threadIdx().x
stride = gridDim().x * blockDim().x
for i = index:stride:length(y)
@inbounds y[i] += x[i]
end
return
end
The CUDA analogs of threadid and nthreads are called threadIdx and blockDim. GPUs run a limited number of threads on each streaming multiprocessor (SM). The recent NVIDIA RTX 6000 Ada Generation should have 18,176 CUDA Cores (streaming processors). Imagine how fast it can be even compared to one of the best CPUs for multithreading AMD EPYC 7773X (128 independent threads). By the way, 768MB L3 cache (3D V-Cache Technology) is amazing.
Distributed Computing
The term distributed computing, in simple words, means the interaction of computers in a network to achieve a common goal. The network elements communicate with each other by passing messages (welcome back cooperative multitasking). Since every node in a network usually is at least a standalone virtual machine, often separate hardware, computing may happen simultaneously. A master node can split the workload into independent pieces, send them to the workers, let them do their job, and concatenate the resulting pieces into the eventual answer.
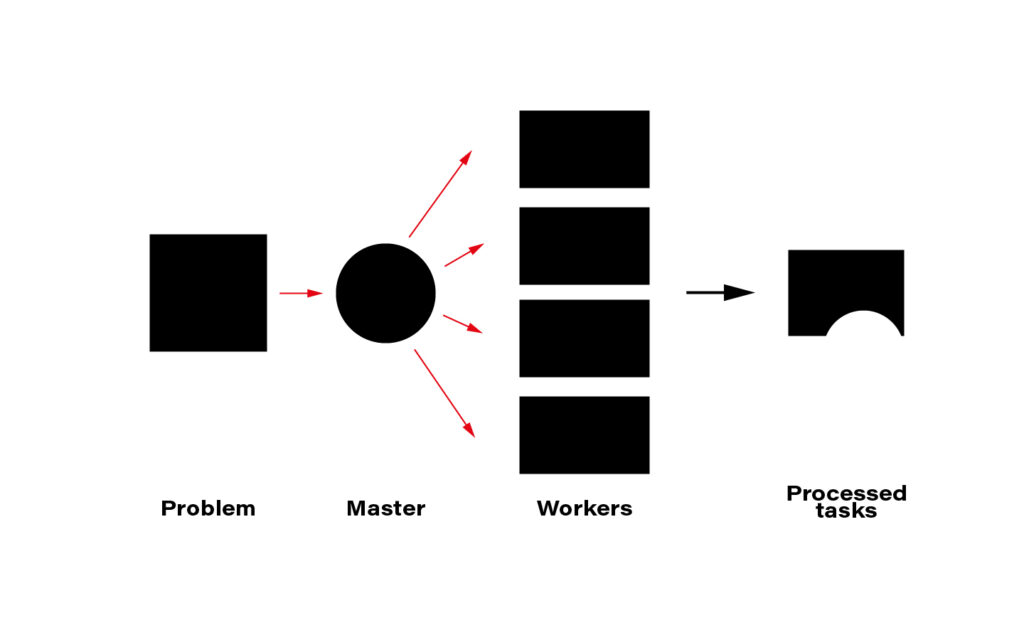
The computer case is the symbolic border line between the methods presented above and distributed computing. The latter must rely on a network infrastructure to send messages between nodes, which is also a bottleneck. CERN uses thousands of kilometers of optical fiber to create a huge and super-fast network for that purpose. CERN's data center offers about 300,000 physical and hyper-threaded cores in a bare-metal-as-a-service model running on about seventeen thousand servers. A perfect environment for distributed computing.
Moreover, since most data CERN produces is public, LHC experiments are completely international - 1400 scientists, 86 universities, and 18 countries – they all create a computing and storage grid worldwide. That enables scientists and companies to run distributed computing in many ways.

Although this is important, I will not cover technologies and distributed computing methods here. The topic is huge and very well covered on the internet. An excellent framework recommended and used by one of the CERN scientists is Spark + Scala interface. You can solve almost every data-related task using Spark and execute the code in a cluster that distributes computation on nodes for you.
Ok, the only piece of advice: be aware of how much data you send to the cluster - transferring big data can ruin all the profit from distributing the calculations and cost you a lot of money.
Another excellent tool for distributed computation on the cloud is Metaflow. I wrote two articles about Metaflow: introduction and how to run a simple project . I encourage you to read and try it.
Conclusions
CERN researchers have convinced me that wise parallelization is crucial to achieving complex goals in the contemporary Big Data world. I hope I managed to infect you with this belief. Happy coding!
Interested in our services?
Reach out for tailored solutions and expert guidance.