How to develop AI-driven personal assistants tailored to automotive needs. Part 2

Making the chatbot more suitable
Recently we’ve built a simple chatbot , using an Azure-hosted GPT 4 Turbo instance. It’s a great starting point, but we definitely need more to fulfill any business requirements. Let’s try to talk with our bot.
Prompt:
Hi, I’d like to buy a new car. Can you assist me with a choice? I’m looking for a family car with a hybrid powertrain and all-wheel drive. I’m a fan of modern design and fancy features. My budget is around 70k euro.
Completion:
Absolutely, I’d be happy to help you find a suitable family car that meets your criteria! Given your preferences (…), there are several options across different brands that could be a great fit. (…):
1. Audi Q5 TFSI e
Powertrain: (…)
Features: (…)
Price Range: (…)
2. BMW X5 xDrive45e
Powertrain: (…)
Features: (…)
Price Range: (…)
3. Volvo XC90 Recharge
Powertrain: (…)
Features: (…)
Price Range: (…)
4. Mercedes-Benz GLE 450 4MATIC
Powertrain: (…)
Features: (…)
Price Range: (…)
5. Lexus RX 450h
Powertrain: (…)
Features: (…)
Price Range: (…)
When considering these options, it’s important to test drive the ones you’re most interested in to get a feel for their driving dynamics, comfort, and the user-friendliness of their tech features. Additionally, (…)
As you can see, the response is quite long, versatile, and absolutely useless.
If you’re working for one of those brands, you don’t want the chatbot to offer your competitors. Also, the knowledge base is a bit outdated, so the answer is unreliable. Besides that, the answer is too long to be shown on a mobile device or to be read. And you need to be aware that the user may misuse the chatbot to generate a master thesis, write a fairy tale or plan a trip to Rome.
Our job is to limit the bot possibilities. The way to achieve it is prompt engineering. Let’s try to add some system messages before the user prompt.
Messages=[
{"role": "system", "content": "You are a car seller working for X"},
{"role": "system", "content": "X offers following vehicles (…)"},
{"role": "system", "content": "Never recommend X competitors"},
{"role": "system", "content": "Avoid topics not related to X. e.g. If the user asks for weather, kindly redirect him to the weather service"},
{"role": "system", "content": "Be strict and accurate, avoid too long messages"},
{"role": "user", "content": "Hi, I’d like to buy a new car. Can you assist me with a choice? I’m looking for a family car with a hybrid powertrain and all-wheel drive. I’m a fan of modern design and fancy features. My budget is around 70k euro."},
]
Now the chatbot should behave much better, but it still can be tricked. Advanced prompt engineering, together with LLM hacking and ways to prevent it, is out of the scope of this article, but I strongly recommend exploring this topic before exposing your chatbot to real customers. For our purposes, you need to be aware that providing an entire offer in a prompt (“X offers following vehicles (…)”) may go way above the LLM context window. Which brings us to the next point.
Retrieval augmented generation
You often want to provide more information to your chatbot than it can handle. It can be an offer of a brand, a user manual, a service manual, or all of that put together, and much more. GPT 4 Turbo can work on up to 128 000 tokens (prompt + completion together), which is, according to the official documentation , around 170 000 of English words. However, the accuracy of the model decreases around half of it [source] , and the longer context processing takes more time and consumes more money. Google has just announced a 1M tokens model but generally speaking, putting too much into the context is not recommended so far. All in all, you probably don’t want to put there everything you have.
RAG is a technique of collecting proper input for the LLM that may contain information required to answer the user questions.
Let’s say you have two documents in your company knowledge base. The first one contains the company offer (all vehicles for sale), and the second one contains maintenance manuals. The user approaches your chatbot and asks the question: “Which car should I buy?”. Of course, the bot needs to identify user’s needs, but it also needs some data to work on. The answer is probably included in the first document but how can we know that?
In more detail, RAG is a process of comparing the question with available data sources to find the most relevant one or ones. The most common technique is vector search. This process converts your domain knowledge to vectors and stores them in a database (this process is called embedding). Each vector represents a piece of document – one chapter, one page, one paragraph, depending on your implementation. When the user asks his question, it is also converted to a vector representation. Then, you need to find the document represented by the most similar vector – it should contain the response to the question, so you need to add it to the context. The last part is the prompt, e.g. “Basic on this piece of knowledge, answer the question”.
Of course, the matter is much more complicated. You need to consider your embedding model and maybe improve it with fine-tuning. You need to compare search methods (vector, semantic, keywords, hybrid) and adapt them with parameters. You need to select the best-fitting database, polish your prompt, convert complex documents to text (which may be challenging, especially with PDFs), and maybe process the output to link to sources or extract images.
It's challenging but possible. See the result in one of our case studies: Voice-Driven Car Manual .
Good news is – you’re not the first one working on this issue, and there are some out-of-the-box solutions available.
The no-code one is Azure AI Search, together with Azure Cognitive Service and Azure Bot. The official manual covers all steps – prerequisites, data ingestion, and web application deployment. It works well, including OCR, search parametrization, and exposing links to source documents in chat responses. If you want a more flexible solution, the low-code version is available here .
I understand if you want to keep all the pieces of the application in your hands and you prefer to build it from scratch. At this point we need to move back to the language opting. The Langchain library, which was originally available for Python only, may be your best friend for this implementation.
See the example below.
From langchain.chains.question_answering import load_qa_chain
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Qdrant
from qdrant_client import QdrantClient
from langchain.chat_models import AzureChatOpenAI
from langchain.chains.retrieval_qa.base import RetrievalQA
client = QdrantClient(url="…", api_key="…")
embeddings = HuggingFaceEmbeddings(model_name="hkunlp/instructor-xl")
db = Qdrant(client= client, collection_name="…", embeddings=embeddings)
second_step = load_qa_chain(AzureChatOpenAI(
deployment_name="…",
openai_api_key="…",
openai_api_base="…",
openai_api_version="2023-05-15"
), chain_type="stuff", prompt="Using the context {{context}} answer the question: …")
first_step = RetrievalQA(
combine_documents_chain=second_step,
retriever=db.as_retriever(
search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5 }
),
)
first_step.run()
This is the entire searching application. It creates and executes a “chain” of operations – the first step is to look for data in the Qdrant database, using a model called instructor-xl for embedding. The second step is to put the output of the first step as a “context” to the GPT prompt. As you can see, the application is based on the Langchain library. There is a Java port for it, or you can execute each step manually in any language you want. However, using Langchain in Python is the most convenient way to follow and a significant advantage of using this language at all.
With this knowledge you can build a chatbot and feed it with company knowledge. You can aim the application for end users (car owners), internal employees, or potential customers. But LLM can “do” more.

Function calling
To “do” is the keyword. In this section we’ll teach the LLM to do something for us, not only to provide information or tell jokes . An operational chatbot can download more data if needed and decide which data is required for the conversation, but it can also execute real operations. Most modern vehicles are delivered with mobile applications that you can use to read data (localize the car, check the mileage, read warnings) or to execute operations (open doors, turn on air conditioning, or start charging process). Let’s do the same with the chatbot.
Function calling is a built-in functionality of GPT models. There is a field in the API model for tools (functions), and it can produce responses in a JSON format. You can try to achieve the same with any other LLM with a prompt like that.
In this environment, you have access to a set of tools you can use to answer the user's question.
You may call them like this:
<function_calls>
<invoke>
<tool_name>$TOOL_NAME</tool_name>
<parameters>
<$PARAMETER_NAME>$PARAMETER_VALUE</$PARAMETER_NAME>
</parameters>
</invoke>
</function_calls>
Here are the tools available:
<tools>
<tool_description>
<tool_name>unlock</tool_name>
<description>
Unlocks the car.
</description>
<parameters>
<parameter>
<name>vin</name>
<type>string</type>
<description>Car identifier</description>
</parameter>
</parameters>
</tool_description>
</tools>
This is a prompt from the user: ….
Unfortunately, LLMs often don’t like to follow a required structure of completions, so you might face some errors when parsing responses.
With the GPT, the official documentation recommends verifying the response format, but I’ve never encountered any issue with this functionality.
Let’s see a sample request with functions’ definitions.
{
"model": "gpt-4",
"messages": [
{ "role": "user", "content": "Unlock my car" }
],
"tools": [
{
"type": "function",
"function": {
"name": "unlock",
"description": "Unlocks the car",
"parameters": {
"type": "object",
"properties": {
"vin": {
"type": "string",
"description": "Car identifier"
},
"required": ["vin"]
}
}
}
],
}
To avoid making the article even longer, I encourage you to visit the official documentation for reference.
If the LLM decides to call a function instead of answering the user, the response contains the function-calling request.
{
…
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "unlock",
"arguments": "{\"vin\": \"ABC123\"}"
}
}
]
},
"logprobs": null,
"finish_reason": "tool_calls"
}
]
}
Based on the finish_reason value, your application decides to return the content to the user or to execute the operation. The important fact is – there is no magic that can be used to automatically call some API or execute a function in your code. Your application must find a function based on the name, and parse arguments from the JSON-formatted list. Then the response of the function should be sent to the LLM (not to the user), and the LLM makes the decision about next steps – to call another function (or the same with different arguments) or to write a response for the user. To send the response to the LLM, just add it to the conversation.
{
"model": "gpt-4",
"messages": [
{ "role": "user", "content": "Unlock my car" },
{"role": "assistant", "content": null, "function_call": {"name": "unlock", "arguments": "{\"vin\": \"ABC123\"}"}},
{"role": "function", "name": "unlock", "content": "{\"success\": true}"}
],
"tools": [
…
],
}
In the example above, the next response is more or less “Sure, I’ve opened your car”.
With this approach, you need to send with each request not only the conversation history and system prompts but also a list of all functions available with all parameters. Keep it in mind when counting your tokens.
Follow up
As you can see, we can limit the chatbot versatility by prompt engineering and boost its resourcefulness with RAG or external tools. It brings us to another level of LLMs usability but now we need to meld it together and not throw the baby out with the bathwater. In the last article we’ll consider the application architecture, plug some optimization, and evade common pitfalls. We’ll be right back!

Data powertrain in automotive: Complete end-to-end solution
We power your entire data journey, from signals to solutions
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
How to develop AI-driven personal assistants tailored to automotive needs. Part 1
Artificial Intelligence is everywhere - my laundry dryer is “powered by AI” (whatever it means), and I suppose there are some fridges on the market that take photos of their content to send you a shopping list and maybe even propose a recipe for your next dinner basing on the food you have. Some people say that generative AI and large language models (LLMs) are the most important inventions since the Internet, and we observe the beginning of the next industrial revolution.
However, household appliances and the newest history deliberation are not in our sphere of interest. The article about AI-based tools to support developers is getting old quickly due to the extremely fast development of new tools and their capabilities. But what can we, software makers, propose to our customers to keep up with the world changing?
Let’s talk about chatbots. Today, we try to break down an AI-driven personal assistants topic for the automotive industry. First, to create a chatbot, we need a language model.
The best-known LLM is currently OpenAI GPT4 that powers ChatGPT and thousands of different tools and applications, including a very powerful, widely available Microsoft Copilot. Of course, there are more similar models: Anthropic Claude with a huge context window, recently updated Google Bard, available for self-hosting Llama, code-completion tailored Tabnine, etc.
Some of them can give you a human-like conversation experience, especially combined with voice recognition and text-to-speech models – they are smart, advanced, interactive, helpful, and versatile. Is it enough to offer an AI-driven personal assistant for your automotive customers?
Well, as usual, it depends.
What is a “chatbot”?
The first step is to identify end-users and match their requirements with the toolkit possibilities. Let’s start with the latter point.
We’re going to implement a text-generating tool, so in this article, we don’t consider graphics, music, video, and all other generation models. We need a large language model that “understands” a natural language (or more languages) prompts and generates natural language answers (so-called “completions”).
Besides that, the model needs to operate on the domain knowledge depending on the use case. Hypothetically, it’s possible to create such a model from scratch, using general resources, like open-licensed books (to teach it the language) and your company resources (to teach it the domain), but the process is complex, very expensive in all dimensions (people, money, hardware, power, time, etc.) and at the end of the day - unpredictable.
Therefore, we’re going to use a general-purpose model. Some models (like gpt-4-0613) are available for fine-tuning – a process of tailoring the model to better understand a domain. It may be required for your use case, but again, the process may be expensive and challenging, so I propose giving a shot at a “standard” model first.
Because of the built-in function calling functionality and low price with a large context window, in this article, we use gpt-4-turbo. Moreover, you can have your own Azure-hosted instance of it, which is almost certainly significant to your customer privacy policy. Of course, you can achieve the same with some extra prompt engineering with other models, too.
OK, what kind of AI-driven personal assistant do you want? We can distinguish three main concepts: general chatbot, knowledge-based one, and one allowed to execute actions for a user.

Your first chatbot
Let’s start with the implementation of a simple bot – to talk about everything except the newest history.
As I’ve mentioned, it’s often required not to use the OpenAI API, but rather its own cloud-hosted model instance. To deploy one, you need an Azure account. Go to https://portal.azure.com/ , create a new resource, and select “Azure OpenAI”. Then go to your new resource, select “Keys and endpoints” from the left menu, and copy the endpoint URL together with one of the API keys. The endpoint should look like this one: https://azure-openai-resource-name.openai.azure.com/.
Now, you create a model. Go to “Model deployments” and click the “Manage deployments” button. A new page appears where you can create a new instance of the gpt-4 model. Please note that if you want to use the gpt-4-turbo model, you need to select the 1106 model version which is not available in all regions yet. Check this page to verify availability across regions.
Now, you have your own GPT model instance. According to Azure's privacy policy, the model is stateless, and all your data is safe, but please read the “Preventing abuse and harmful content generation” and “How can customers get an exemption from abuse monitoring and human review?” sections of the policy document very carefully before continuing with sensitive data.
Let’s call the model!
curl --location https://azure-openai-resource-name.openai.azure.com/openai/deployments/name-of-your-deployment/chat/completions?api-version=2023-05-15' \
--header 'api-key: your-api-key \
--header 'Content-Type: application/json' \
--data '{
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'
The response should be like the following one.
{
"id": "chatcmpl-XXX",
"object": "chat.completion",
"created": 1706991030,
"model": "gpt-4",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I assist you today?"
}
}
],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 9,
"total_tokens": 18
}
}
Generally speaking, we’re done! You are making a conversation with your own chatbot. See the official documentation for a comprehensive API reference. Note that 2023-05-15 is the latest stable version of the API when I’m writing this text – you can use a newer preview version, or maybe there is a newer stable version already available.
However, using cURL is not the best user experience. Most tutorials propose using Python to develop your own LLM-based application. It’s a good advice to follow – Python is simple, offers SDKs for most generative AI models, and Langchain – one library to rule them all. However, our target application will handle more enterprise logic and microservices integration than LLM API integration, so choosing a programming language based only on this criterion may result in a very painful misusage in the end.
At this stage, I’ll show you an example of a simple chatbot application using Azure OpenAI SDK in two languages: Python and Java. Make your decision based on your language knowledge and more complex examples from the following parts of the article.
The Python one goes first.
from openai import AzureOpenAI
client = AzureOpenAI(
api_key='your-api-key',
api_version="2023-05-15",
azure_endpoint= ‘https://azure-openai-resource-name.openai.azure.com/'
)
chat_completion = client.chat.completions.create(
model=" name-of-your-deployment ",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(chat_completion.choices[0].message.content)
Here is the same in Java:
package demo;
import com.azure.ai.openai.OpenAIClientBuilder;
import com.azure.ai.openai.models.ChatCompletionsOptions;
import com.azure.ai.openai.models.ChatRequestUserMessage;
import com.azure.core.credential.AzureKeyCredential;
import java.util.List;
class Main {
public static void main(String[] args) {
var openAIClient = new OpenAIClientBuilder()
.credential(new AzureKeyCredential("your-api-key"))
.endpoint("https://azure-openai-resource-name.openai.azure.com/ ")
.buildClient();
var chatCompletionsOptions = new ChatCompletionsOptions(List.of(new ChatRequestUserMessage("Hello!")));
System.out.println(openAIClient.getChatCompletions("name-of-your-deployment", chatCompletionsOptions)
.getChoices().getFirst().getMessage().getContent());
}
}
One of the above applications will be a base for all you’ll build with this article.
User interface and session history
We’ve learnt how to send a prompt and read a completion. As you can see, we send a list of messages with a request. Unfortunately, the LLM’s API is stateless, so we need to send an entire conversation history with each request. For example, the second prompt, “How are you?”, in Python looks like that.
messages=[
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "How can I help you"},
{"role": "user", "content": "How are you?"}
]
Therefore, we need to maintain the conversation history in our application, which brings us back to the user journey identification, starting with the user interface.
The protocol
The easy way is to create a web application with REST. The conversation history is probably shown on the page all the time, so it’s easy to send the entire history with each request from the frontend to the backend, and then from the backend to the LLM. On the other hand, you still need to add some system prompts to the conversation (we’ll discuss system prompts later) and sending a long conversation over the internet twice is a waste of resources. Moreover, LLMs may be slow, so you can easily hit a timeout for popular REST gateways, and REST offers just a single response for each request.
Because of the above, you may consider using an asynchronous communication channel: WebSocket or Server-Side Events. SSE is a one-way communication channel only, so the frontend still needs to send messages via the REST endpoint and may receive answers asynchronously. This way, you can also send more responses for each user query – for example, you can send “Dear user, we’re working hard to answer your question” before the real response comes from the LLM. If you don’t want to configure two communication channels (REST and SSE), go with WebSocket.
“I wish to know that earlier” advice: Check libraries availability for your target environment. For example, popular Swift libraries for WebSocket don’t support SockJS and require some extra effort to keep the connection alive.
Another use case is based on communicators integration. All companies use some communicators nowadays, and both Slack and Teams SDKs are available in many languages and offer asynchronous messaging. You can react to mentions, read entire channels, or welcome new members. However, some extra functionalities may be kind of limited.
Slack SDK doesn’t support “bot is typing” indicators, and Teams offers reading audio and video streams during meetings only for C# SDK. You should undeniably verify all the features you need availability before starting the integration. You need to consider all permissions you’ll need in your customer infrastructure to set up such a chatbot too.
The state
Regardless of what your frontend and communication channel are, you need to retain the history of the conversation. In a single-server environment, the job is easy – you can create a session-scope storage, perhaps a session-key dictionary, or a session Spring bean that stores the conversation. It’s even easier with both WebSocket and SSE because if the server keeps a session open, the session is sticky, and it should pass through any modern load balancer.
However, both WebSocket and SSE can easily scale up in your infrastructure but may break connections when scaling down – when a node that keeps the channel is terminated, the conversation is gone. Therefore, you may consider persistent storage: a database or a distributed cache.
Speech-to-text and text-to-speech
Another piece of our puzzle is the voice interface. It’s important for applications for drivers but also for mechanics who often can’t operate computers with busy (or dirty) hands.
For mobile devices, the task is easy – both iOS and Android offer built-in speech-to-text recognition and text-to-speech generation as a part of accessibility mechanisms, so you can use them via systems’ APIs. Those methods are fast and work on end devices, however their quality is discussable, especially in non-English environments.
The alternative is to use generative AI models. I haven’t conducted credible, trustworthy research in this area, but I can recommend OpenAI Whisper for speech-to-text and Eleven Labs for text-to-speech. Whisper works great in noisy environments (like a car riding on an old pavement), and it can be self-hosted if needed (but the cloud-hosted variant usually works faster). Eleven Labs allows you to control the emotions and delivery of the speaker. Both work great with many languages.
On the other hand, using server-side voice processing (recognition and generation) extends response time and overall processing cost. If you want to follow this way, consider models that can work on streams – for example, to generate voice at the same time when your backend receives the LLM response token-by-token instead of waiting for the entire message to convert.
Additionally, you can consider using AI talking avatars like Synthesia, but it will significantly increase your cost and response time, so I don’t recommend it for real-time conversation tools.
Follow up
This text covers just a basic tutorial on how to create bots. Now you know how to host a model, how to call it in three ways and what to consider when designing a communication protocol. In following parts of the article series, we’ll add some domain knowledge to the created AI-driven personal assistant and teach it to execute real operations. At the end, we’ll try to summarize the knowledge with a hybrid solution , we’ll look for the technology weaknesses and work on the product optimization.
How to develop AI-driven personal assistants tailored to automotive needs. Part 3
Blend AI assistant concepts together
This series of articles starts with a general chatbot description – what it is, how to deploy the model, and how to call it. The second part is about tailoring – how to teach the bot domain knowledge and how to enable it to execute actions. Today, we’ll dive into the architecture of the application, to avoid starting with something we would regret later on.
To sum up, there are three AI assistant concepts to consider: simple chatbot, RAG, and function calling.
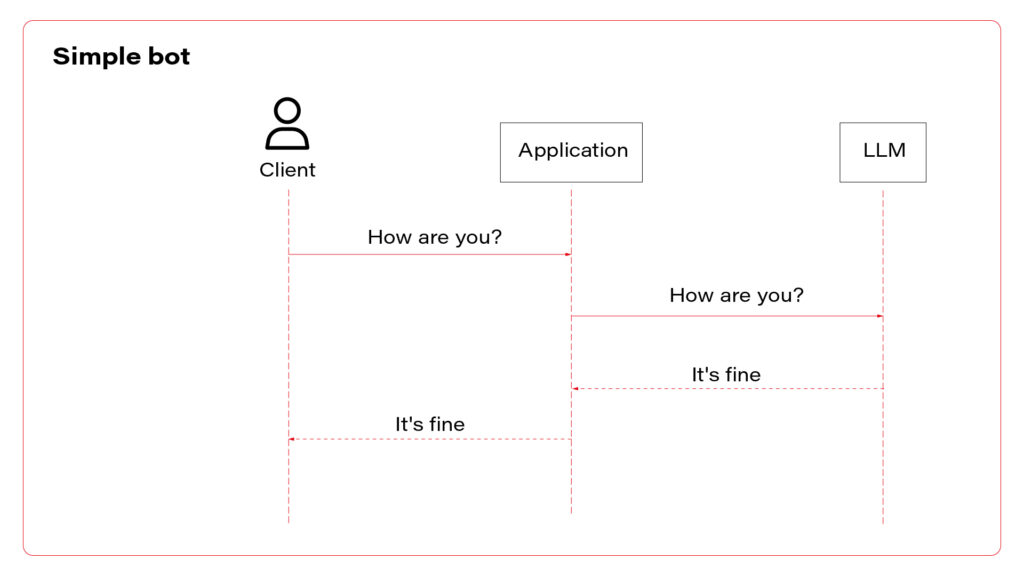
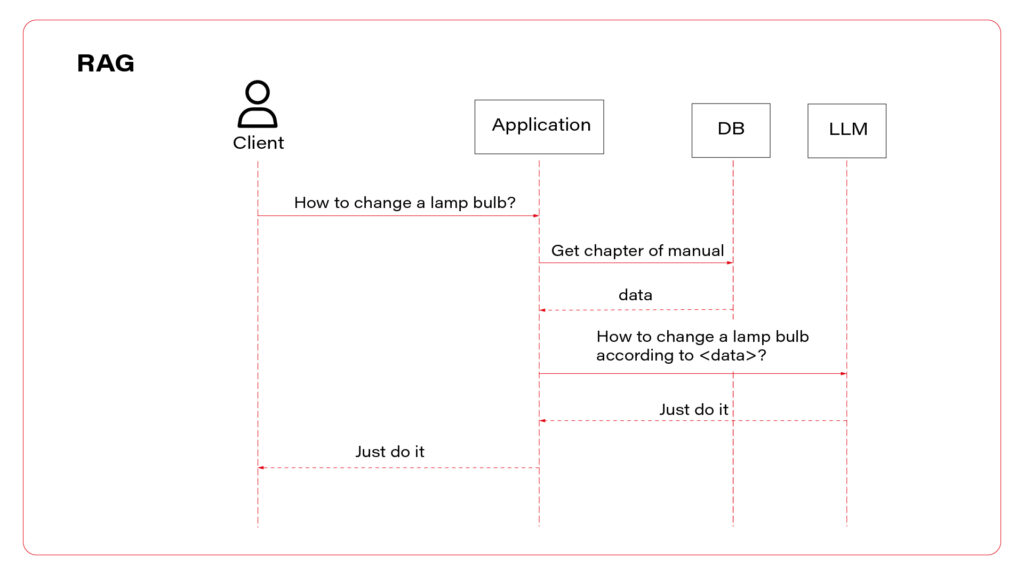
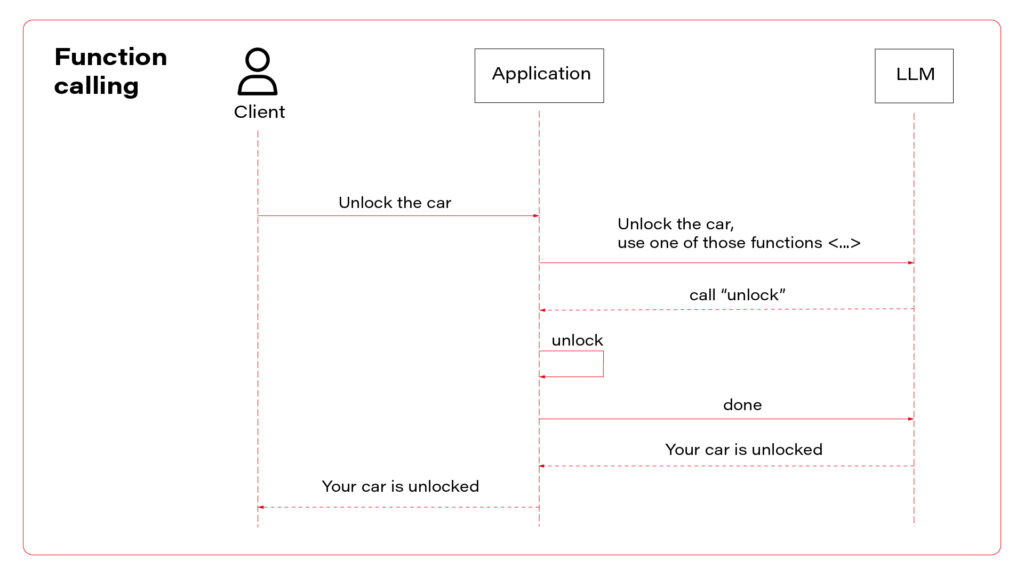
I propose to use them all at once. Let’s talk about the architecture. The perfect one may look as follows.
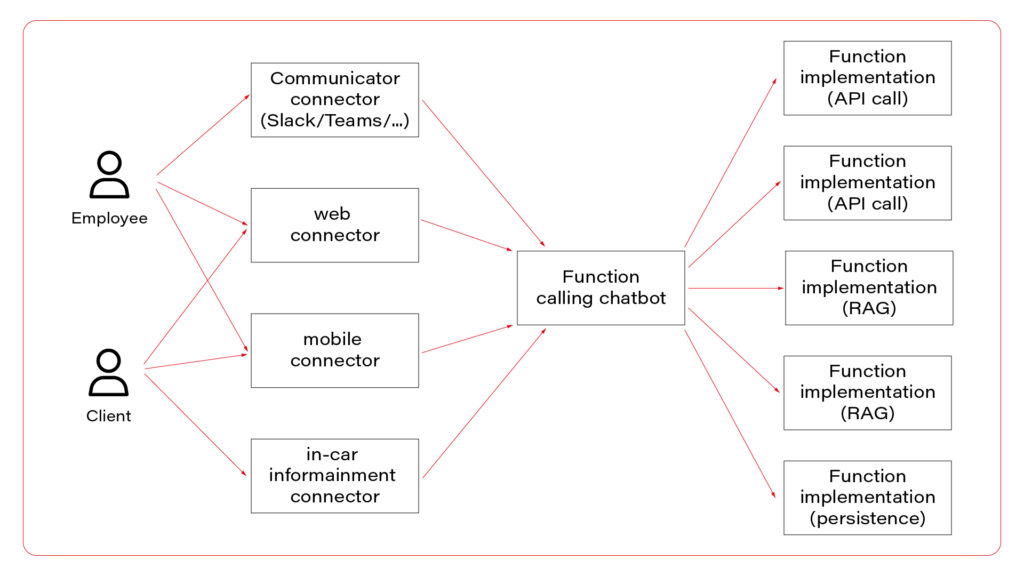
In the picture, you can see three layers. The first one, connectors, is responsible for session handling. There are some differences between various UI layers, so it’s wise to keep them small, simple, and separated. Members of this layer may be connected to a fast database, like Redis, to allow session sharing between nodes, or you can use a server-side or both-side communication channel to keep sessions alive. For simple applications, this layer is optional.
The next layer is the chatbot – the “main” application in the system. This is the application connected to the LLM, implementing the function calling feature. If you use middleware between users and the “main” application, this one may be stateless and receive the entire conversation from the middleware with each call. As you can see, the same application serves its capabilities both to employees and clients.
Let’s imagine a chatbot dedicated to recommending a car. Both a client and a dealer may use a very similar application, but the dealer has more capabilities – to order a car, to see stock positions, etc. You don’t need to create two different applications for that. The concept is the same, the architecture is the same, and the LLM client is the same. There are only two elements that differ: system prompts and the set of available functions. You can play it through a simple abstract factory pattern that will provide different prompts and function definitions for different users.
In a perfect world, the last layer is a set of microservices to handle different functions. If the LLM decides to use the function “store_order”, the “main” application calls the “store_order” function microservice that inserts data to an order database. Suppose the LLM decides to use the function “honk_and_flash” to localize a car in a crowded parking. In that case, the “main” application calls the “hong_and_flash” function microservice that handles authorization and calls a Digital Twin API to execute the operation in the car. If the LLM decides to use a function “check_in_user_manual”, the “main” application calls the “check_in_user_manual” function microservice, which is… another LLM-based application!
And that’s the point!
A side note before we move on – the world is never perfect so it’s understandable if you won’t implement each function as a separate microservice and e.g. keep everything in the same application.
The architecture proposed can combine all three AI assistant concepts. The “main” application may answer questions based on general knowledge and system prompts (“simple chatbot” concept) or call a function (“function calling” concept). The function may collect data based on the prompt (“RAG” concept) and do one of the following: call LLM to answer a question or return the data to add it to the context to let the “main” LLM answer the question. Usually, it’s better to follow the former way – to answer the question and not to add huge documents to the context. But for special use cases, like a long conversation about collected data, you may want to keep the document in the context of the conversation.
Which brings us to the last idea – mutable context. In general, each call contains the conversation history, including all data collected during the conversation, together with all available functions’ definitions.
First prompt:
System: You are a car seller, be nice to your customers
User: I’d like to buy a car
Functions: function1, function2, function3
Second prompt:
System: You are a car seller, be nice to your customers
User: I’d like to buy a car
Assistant: call function1
Function: function1 returned data
Assistant: Sure, what do you need?
User: I’m looking for a sports car.
Functions: function1, function2, function3
Third prompt:
System: You are a car seller, be nice to your customers
User: I’d like to buy a car
Assistant: call function1
Function: function1 returned data
Assistant: Sure, what do you need?
User: I’m looking for a sports car.
Assistant: I propose model A, it’s fast and furious
User: I like it!
Functions: function1, function2, function3
You can consider a mutation of the conversation context at this point.
Fourth prompt:
System: You are a sports car seller, be nice to your customers
System: User is looking for a sports car and he likes model A
Assistant: Do you want to order model A?
Functions: function1, function2, function3, function4
You can implement a summarization function in your code to shorten the conversation, or you can select different subsets of all functions available, depending on the conversation context. You can perform both those tasks with the same LLM instance you use to make the conversation but with totally different prompts, e.g. “Summarize the conversation” instead of “You are a car seller”. Of course, the user won’t even see that your application calls the LLM more often than on user prompts only.
Pitfalls
All techniques mentioned in the series of articles may be affected by some drawbacks.
The first one is the response time . When you put more data into the context, the user waits longer for the responses. It’s especially visible for voice-driven chatbots and may influence the user experience. Which means - it’s more important for customer-facing chatbots than the ones for internal usage only.
The second inhibition is cost . Today, the 1000 prompt tokens processed by GPT-4-Turbo cost €0,01, which is not a lot. However, a complex system prompts together with some user data may, let’s say, occupy 20000 tokens. Let’s assume that the first question takes 100 tokens, the first answer takes 150 tokens, and the second question takes 200 tokens. The cost of the conversation is calculated as follows.
First prompt: common data + first question = 20000 [tokens] + 100 [tokens] = 2100 [tokens]
Second prompt: common data + first question + first answer + second question = 20000 [tokens] + 100 [tokens] + 150 [tokens] + 200 [tokens] = 20450 [tokens]
This two-prompts conversation takes 40550 tokens in total so far, which costs €0,41, excluding completions. Be aware that users may play with your chatbot running up the bill.
The last risk is the security risk . In the examples in the part 2 article , the chatbot uses an “unlock” function that accepts a VIN. You are obliged to assume that the chatbot will try to call a function with the VIN parameter of a car that does not belong to the customer. Of course, you must implement various LLM-hacking prevention mechanisms (prompt engineering, prompt filtering, answer filtering, etc.), but you can never assume that it is sufficient. Therefore, the developer’s role is to secure the functions (function calling) and data sources (RAG). For example, if a user tries to call a vehicle-related function, the user should be identified by the OAuth2 token, and the function microservice should reject a call with a VIN argument that doesn’t match the user profile.
Outline
In this series of articles, I’ve given you a few examples of how to utilize the most significant invention of 2023 for your automotive clients. You can write a chatbot that analyses customers’ requirements, helps mechanics, automates maintenance visit scheduling, seeks answers in user manuals, or writes personalized emails. Large language models are powerful and may be customized with a little effort. On the other hand, you need to keep in mind their limitations and common pitfalls. At the end of the day, even if the engine of the application is a black box, there is still a lot to implement around it to meet the business requirements.
The era of LLM-based applications is started within the automotive industry too.
Interested in our services?
Reach out for tailored solutions and expert guidance.