How to Develop AI-Driven Personal Assistants Tailored to Automotive Needs. Part 3


Blend AI assistant concepts together
This series of articles starts with a general chatbot description – what it is, how to deploy the model, and how to call it. The second part is about tailoring – how to teach the bot domain knowledge and how to enable it to execute actions. Today, we’ll dive into the architecture of the application, to avoid starting with something we would regret later on.
To sum up, there are three AI assistant concepts to consider: simple chatbot, RAG, and function calling.
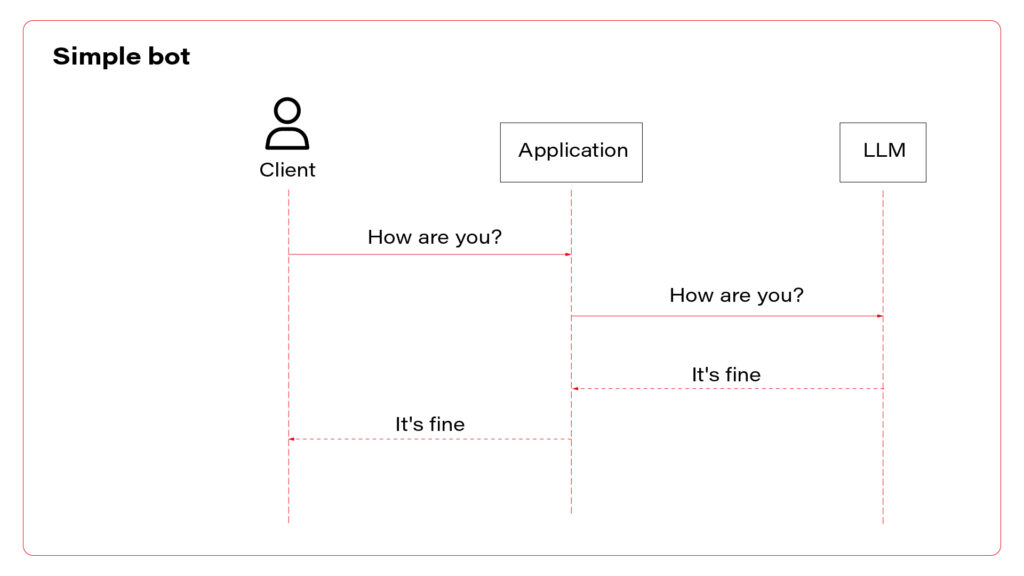
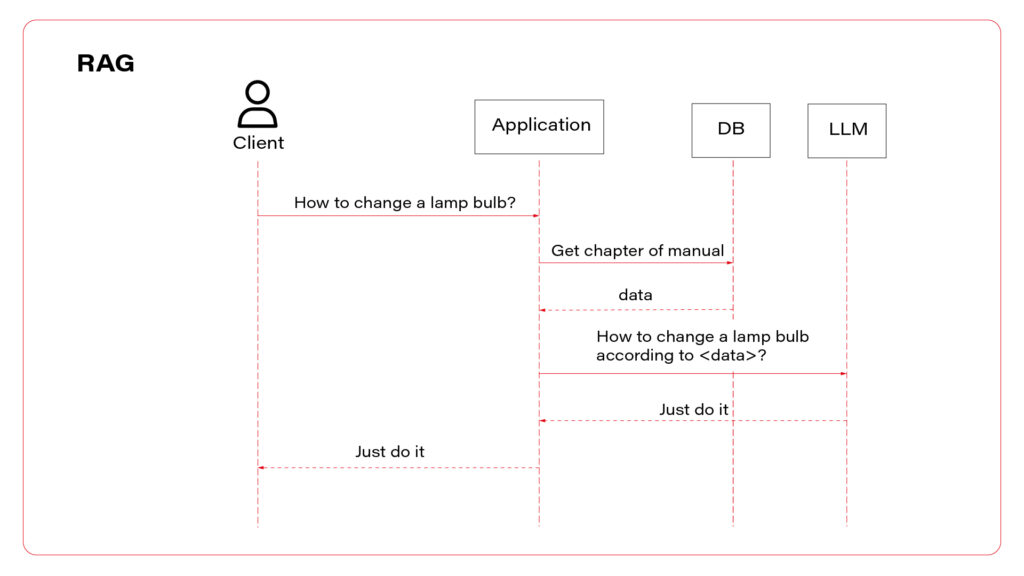
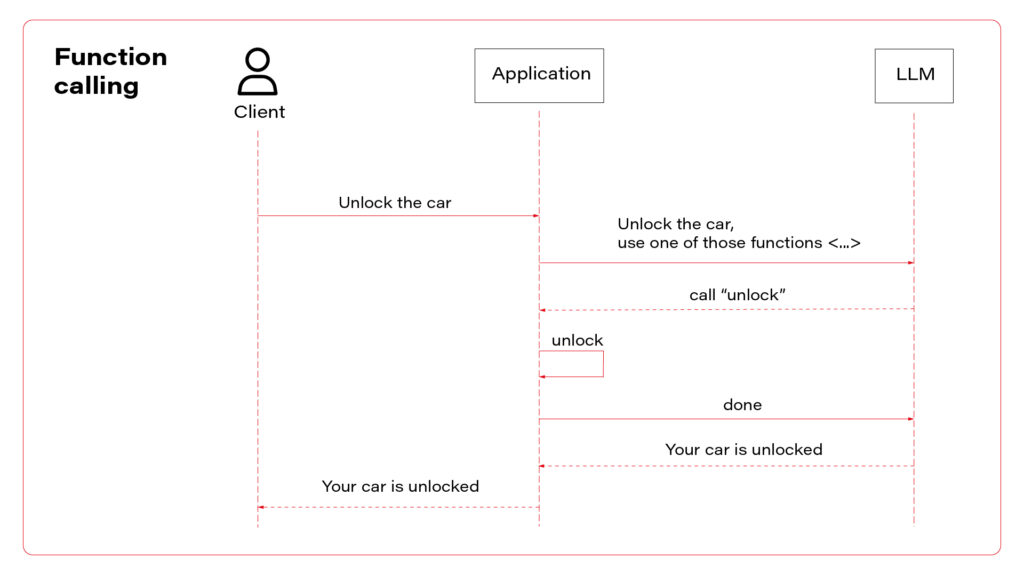
I propose to use them all at once. Let’s talk about the architecture. The perfect one may look as follows.
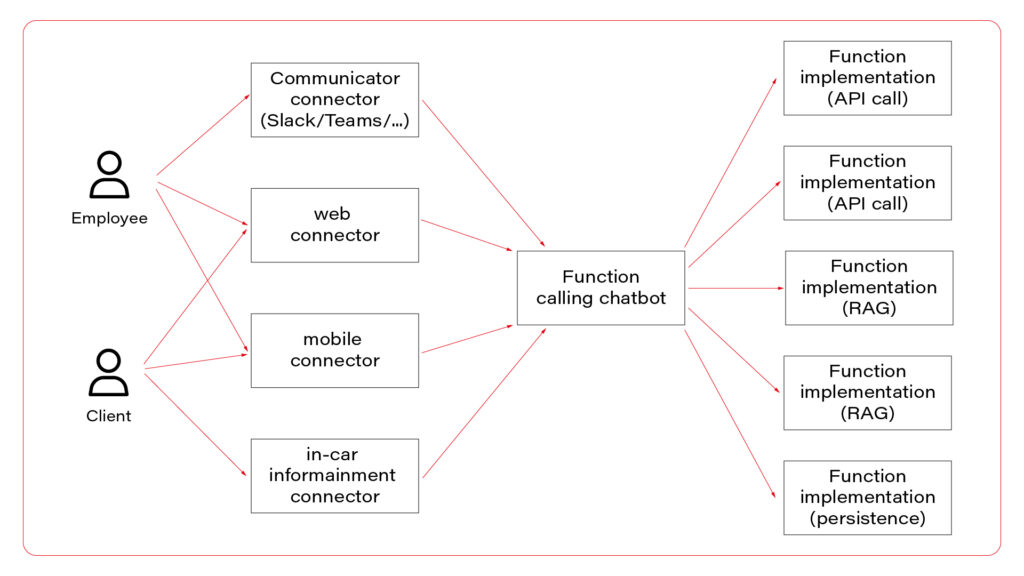
In the picture, you can see three layers. The first one, connectors, is responsible for session handling. There are some differences between various UI layers, so it’s wise to keep them small, simple, and separated. Members of this layer may be connected to a fast database, like Redis, to allow session sharing between nodes, or you can use a server-side or both-side communication channel to keep sessions alive. For simple applications, this layer is optional.
The next layer is the chatbot – the “main” application in the system. This is the application connected to the LLM, implementing the function calling feature. If you use middleware between users and the “main” application, this one may be stateless and receive the entire conversation from the middleware with each call. As you can see, the same application serves its capabilities both to employees and clients.
Let’s imagine a chatbot dedicated to recommending a car. Both a client and a dealer may use a very similar application, but the dealer has more capabilities – to order a car, to see stock positions, etc. You don’t need to create two different applications for that. The concept is the same, the architecture is the same, and the LLM client is the same. There are only two elements that differ: system prompts and the set of available functions. You can play it through a simple abstract factory pattern that will provide different prompts and function definitions for different users.
In a perfect world, the last layer is a set of microservices to handle different functions. If the LLM decides to use the function “store_order”, the “main” application calls the “store_order” function microservice that inserts data to an order database. Suppose the LLM decides to use the function “honk_and_flash” to localize a car in a crowded parking. In that case, the “main” application calls the “hong_and_flash” function microservice that handles authorization and calls a Digital Twin API to execute the operation in the car. If the LLM decides to use a function “check_in_user_manual”, the “main” application calls the “check_in_user_manual” function microservice, which is… another LLM-based application!
And that’s the point!
A side note before we move on – the world is never perfect so it’s understandable if you won’t implement each function as a separate microservice and e.g. keep everything in the same application.
The architecture proposed can combine all three AI assistant concepts. The “main” application may answer questions based on general knowledge and system prompts (“simple chatbot” concept) or call a function (“function calling” concept). The function may collect data based on the prompt (“RAG” concept) and do one of the following: call LLM to answer a question or return the data to add it to the context to let the “main” LLM answer the question. Usually, it’s better to follow the former way – to answer the question and not to add huge documents to the context. But for special use cases, like a long conversation about collected data, you may want to keep the document in the context of the conversation.
Which brings us to the last idea – mutable context. In general, each call contains the conversation history, including all data collected during the conversation, together with all available functions’ definitions.
First prompt:
System: You are a car seller, be nice to your customers
User: I’d like to buy a car
Functions: function1, function2, function3
Second prompt:
System: You are a car seller, be nice to your customers
User: I’d like to buy a car
Assistant: call function1
Function: function1 returned data
Assistant: Sure, what do you need?
User: I’m looking for a sports car.
Functions: function1, function2, function3
Third prompt:
System: You are a car seller, be nice to your customers
User: I’d like to buy a car
Assistant: call function1
Function: function1 returned data
Assistant: Sure, what do you need?
User: I’m looking for a sports car.
Assistant: I propose model A, it’s fast and furious
User: I like it!
Functions: function1, function2, function3
You can consider a mutation of the conversation context at this point.
Fourth prompt:
System: You are a sports car seller, be nice to your customers
System: User is looking for a sports car and he likes model A
Assistant: Do you want to order model A?
Functions: function1, function2, function3, function4
You can implement a summarization function in your code to shorten the conversation, or you can select different subsets of all functions available, depending on the conversation context. You can perform both those tasks with the same LLM instance you use to make the conversation but with totally different prompts, e.g. “Summarize the conversation” instead of “You are a car seller”. Of course, the user won’t even see that your application calls the LLM more often than on user prompts only.

Pitfalls
All techniques mentioned in the series of articles may be affected by some drawbacks.
The first one is the response time. When you put more data into the context, the user waits longer for the responses. It’s especially visible for voice-driven chatbots and may influence the user experience. Which means – it’s more important for customer-facing chatbots than the ones for internal usage only.
The second inhibition is cost. Today, the 1000 prompt tokens processed by GPT-4-Turbo cost €0,01, which is not a lot. However, a complex system prompts together with some user data may, let’s say, occupy 20000 tokens. Let’s assume that the first question takes 100 tokens, the first answer takes 150 tokens, and the second question takes 200 tokens. The cost of the conversation is calculated as follows.
First prompt: common data + first question = 20000 [tokens] + 100 [tokens] = 2100 [tokens]
Second prompt: common data + first question + first answer + second question = 20000 [tokens] + 100 [tokens] + 150 [tokens] + 200 [tokens] = 20450 [tokens]
This two-prompts conversation takes 40550 tokens in total so far, which costs €0,41, excluding completions. Be aware that users may play with your chatbot running up the bill.
The last risk is the security risk. In the examples in the part 2 article, the chatbot uses an “unlock” function that accepts a VIN. You are obliged to assume that the chatbot will try to call a function with the VIN parameter of a car that does not belong to the customer. Of course, you must implement various LLM-hacking prevention mechanisms (prompt engineering, prompt filtering, answer filtering, etc.), but you can never assume that it is sufficient. Therefore, the developer’s role is to secure the functions (function calling) and data sources (RAG). For example, if a user tries to call a vehicle-related function, the user should be identified by the OAuth2 token, and the function microservice should reject a call with a VIN argument that doesn’t match the user profile.
Outline
In this series of articles, I’ve given you a few examples of how to utilize the most significant invention of 2023 for your automotive clients. You can write a chatbot that analyses customers’ requirements, helps mechanics, automates maintenance visit scheduling, seeks answers in user manuals, or writes personalized emails. Large language models are powerful and may be customized with a little effort. On the other hand, you need to keep in mind their limitations and common pitfalls. At the end of the day, even if the engine of the application is a black box, there is still a lot to implement around it to meet the business requirements.
The era of LLM-based applications is started within the automotive industry too.
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles

