Building intelligent document processing systems - classification and validation

We continue our journey towards building Intelligent Document Processing Systems. In this article, we focus on document classification and validation.
This is the second part of the series about Intelligent Document Processing ( IDP ). The series consists of 3 parts:
- Problem definition and data
- Classification and validation
- Entities finders
If you are interested in data preparation, read the previous article. We describe there what we have done to get the data transformed into the form.
Classes
The detailed classification of document types shows that documents fall into around 80 types. Not every type is well-represented, and some of them have a minor impact or neglectable specifics that would force us to treat them as a distinct class.
After understanding the specifics, we ended up with 20 classes of documents. Some classes are more general, such as Assignment, some are as specific as Bankruptcy. The types we classify are: Assignment, Bill, Deed, Deed Of Separation, Deed Of Subordination, Deed Of Trust, Foreclosure, Deed In Lieu Foreclosure, Lien, Mortgage, Trustees Deed, Bankruptcy, Correction Deed, Lease, Modification, Quit Claim Deed, Release, Renunciation, Termination.
We chose these document types after summarizing the information present in each type. When the following services and routing are the same for similar documents, we do not distinguish them in target classes. We abandoned a few other types that do not occur in the real world often.
Classification
Our objective was to classify them for the correct next routing and for the application of the consecutive services. For example, when we are looking for party names, dealing with the Bankruptcy type of document, we are not looking for more than one legal entity.
The documents are long and various. We can now start to think about the mathematical representation of them. Neural networks can be viewed as a complex encoders with classifier on top. These encoders are usually, in fact, powerful systems that can comprehend a lot of content and dependencies in text. However, the longer the text, the harder for a network to focus on a single word or single paragraph. There was a lot of research that confirms our intuition, which shows that the responsibility of classification of long documents on huge encoders is on the final layer and embeddings could be random to give similar results.
Recent GPT-3 (2020) is obviously magnificent, and who knows, maybe such encoders have the future for long texts. Even if it comes with a huge cost – computational power, processing time. Because we do not have a good opinion on representing long paragraphs of text in a low dimensional embedding made up by a neural network, we made ourselves a favor leaning towards simpler methods.
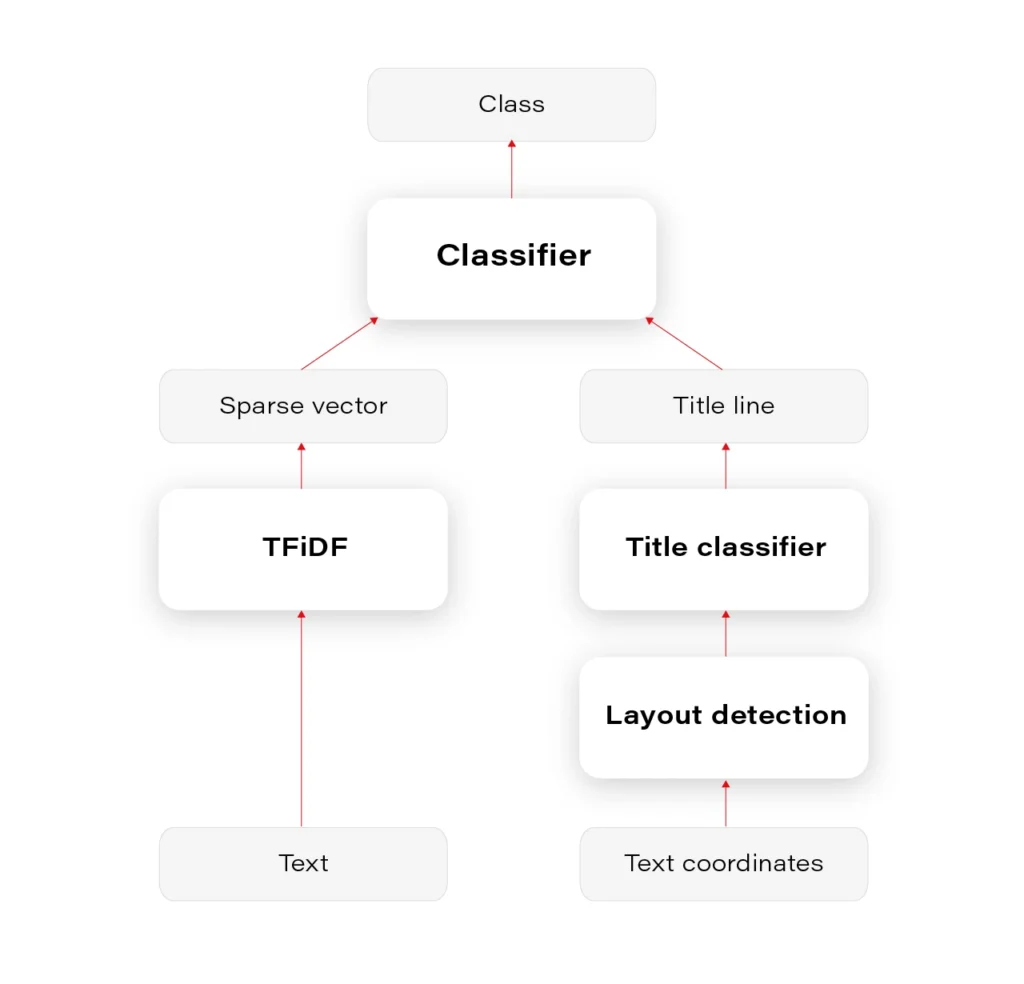
We had to prepare a multiclass-multilabel classifier that doesn’t smooth the probability distribution in any way on the layer of output classes, to be able to interpret and tune classes' thresholds correctly. This is often a necessary operation to unsmooth the output probability distribution. Our main classifier was Logistic Regression on TFiDF (Term Frequency - Inverse Document Frequency). We tuned mainly TFiDF but spent some time on documents themselves – number of pages, stopwords, etc.
Our results were satisfying. In our experiments, we are above 95% accuracy, which we find quite good, considering ambiguity in the documents and some label noise.
It is, however, natural to estimate whether it wouldn’t be enough to classify the documents based on the heading – document title, the first paragraph, or something like this. Whether it’s useful for a classifier to emphasize the title phrase or it’s enough to classify only based on titles – it can be settled after the title detection.
Layout detection
Document Layout Analysis is the next topic we decided to apply in our solution.
First of all, again, the variety of layouts in our documents is tremendous. The available models are not useful for our tasks.
The simple yet effective method we developed is based on the DBSCAN algorithm. We derived a specialized custom distance function to calculate the distances between words and lines in a way that blocks in the layout are usefully separated. The custom distance function is based on Euclidean distance but smartly uses the fact that text is recognized by OCR in lines. The function is dynamic in terms of proportion between the width and height of a line.
You can see the results in Figure 1. We can later use this layout information for many purposes.
Based on the content, we can decide whether any block in a given layout contains the title. For document classification based on title, it seems that predicting document class based only on the detected title would be as good as based on the document content. The only problem occurs when there are no document titles, which unfortunately happens often.
Overall, mixing layout information with the text content is definitely a way to go, because layout seems to be an integral part of a document, fulfilling not only the cosmetic needs but also storing substantive information. Imagine you are reading these documents as plain text in notepad - some signs, dates, addresses, are impossible to distinguish without localizations and correctly interpreted order of text lines.
The entire pipeline of classification is visualized in Figure 2.
Validation
We incorporated the Metaflow python package for this project. It is a complicated technology that does not always work fluently but overall we think it gave us useful horizontal scalability (some time-consuming processes) and facilitated the cooperation between team members.
The interesting example of Metaflow usage is as follows: at some time, we had to assure that the number of jurisdictions that we had in our trainset is enough for the model to generalize over all jurisdictions.
Are we sure the mortgage from some small jurisdiction in Alaska will work even though most of our documents come from, let’s say, West Side?
The solution to that was to prepare the “leave-one-out" cross-validation in a way that we hold documents from one jurisdiction as a validation set. Having a lot of jurisdictions, we had to choose N of them. Each fold was tested on a remote machine independently and in parallel, which was largely facilitated thanks to Metaflow. Check the Figure 3.

Next
Classification is a crucial component of our system and allows us to take further steps. Having solid fundamentals, after the classifier routing, we can run the next services – the finders .

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
Building intelligent document processing systems – entity finders
Our journey towards building Intelligent Document Processing systems will be completed with entity finders, components responsible for extracting key information.
This is the third part of the series about Intelligent Document Processing (IDP). The series consists of 3 parts:
- Problem definition and data
- Classification and validation
- Entity finders
Entity finders
After classifying the documents, we focus on extracting some class-specific information. We pose the main interests in the jurisdiction, property address, and party names. We called the components responsible for their extraction simply “finders”.
Jurisdictions showed they could be identified based on dictionaries and simple rules. The same applies to file dates.
Context finders
The next 3 entities – addresses, parties, and document dates, provide us with a challenge.
Let us note the fact that:
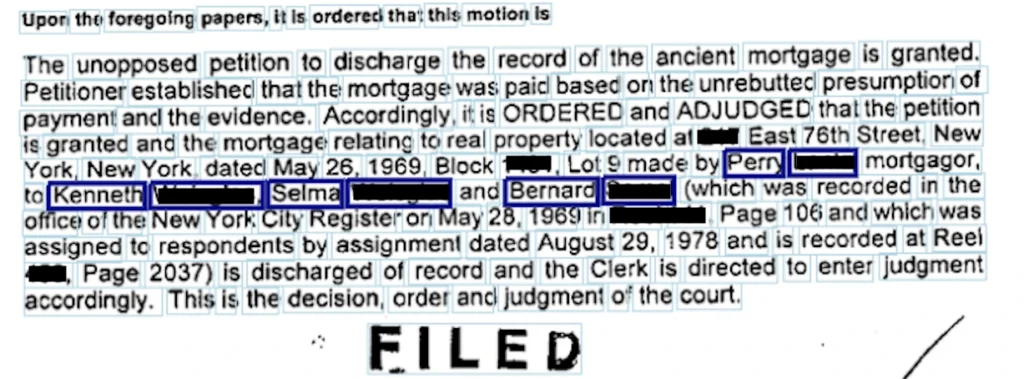
- Considering addresses. There may be as many as 6 addresses on a first page on its own. Some belong to document parties, some to the law office, others to other entities engaged in a given process. Somewhere in this maze of addresses, there is this one that we are interested in – property address. Or there isn’t - not every document has to have the address at all. Some have, often, only the pointers to the page or another document (which we need to extract as well).
- The case with document dates is a little bit simpler. Obviously, there are often a few dates in the document not mentioning any numbers, dates are in every format possible, but generally, the document date occurs and is possible to distinguish.
- Party names – arguably the hardest entities to find. Depending on the document, there may be one or more parties engaged or none. The difficulty is that virtually any name that represents a person, company, or institution in the document is a potential candidate for the party. The variability of contexts indicating that a given name represents a party is huge, including layout and textual contexts.
Generally, our solutions are based on three mechanisms.
- Context finders: We search for the contexts in which the searched entities may occur.
- Entity finders: We are estimating the probability that a given string is the search value.
- Managers: we merge the information about the context with the information About the values and decide whether the value is accepted
Address finder
Addresses are sometimes multi-line objects such as:
“LOT 123 OF THIS AND THIS ESTATES, A SUBDIVISION OF PART OF THE SOUTH HALF OF THE NORTHEAST QUARTER AND THE NORTH HALF OF THE SOUTHEAST QUARTER OF SECTION 123 (...)”.
It is possible that the address is written over more than one or a few lines. When such expression occurs, we are looking for something simpler like :
“The Institution, P.O. Box 123 Cheyenne, CO 123123”
But we are prepared for each type of address.
In the case of addresses, our system is classifying every line in a document as a possible address line. The classification is based on n-grams and other features such as the number of capital letters, the proportion of digits, proportion of special signs in a line. We estimate the probability of the address occurring in the line. Then we merge lines into possible address blocks.
The resulting blocks may be found in many places. Some blocks are continuous, but some pose gaps when a single line in the address is not regarded as probable enough. Similarly, there may occur a single outlier line. That’s why we smooth the probabilities with rules.
After we construct possible address blocks, we filter them with contexts.
We manually collected contexts in which addresses may occur. We can find them in the text later in a dictionary-like manner. Because contexts may be very similar but not identical, we can use Dynamic Time Warping.
An example of similar but not identical context may be:
“real property described as follows:”
“real property described as follow:”
Document date finder
Document dates are the easiest entities to find thanks to a limited number of well-defined contexts, such as “dated this” or “this document is made on”. We used frequent pattern mining algorithms to reveal the most frequent document date context patterns among training documents. After that, we marked every date occurrence in a given document using a modified open-source library from the python ecosystem. Then we applied context-based rules for each of them to select the most likely date as document date. This solution has an accuracy of 82-98% depending on the test set and labels quality.

Parties finder
It’s worth mentioning that this part of our solution together with the document dates finder is implemented and developed in the Julia language . Julia is a great tool for development on the edge of science and you can read about views on it in another blog post here.
The solution on its own is somehow similar to the previously described, especially to the document date finder. We omit the line classifier and emphasize the impact of the context. Here we used a very generic name finder based on regular expression and many groups of hierarchical contexts to mark potential parties and pick the most promising one.
Summary
This part concludes our project focused on delivering an Intelligent Document Processing system. As we also, AI enables us to automate and improve operations in various areas.
The processes in banks are often labor bound, meaning they can only take on as much work as the labor force can handle as most processes are manual and labor-intensive. Using ML to identify, classify, sort, file, and distribute documents would be huge cost savings and add scalability to lucrative value streams where none exists today.
Introduction to building intelligent document processing systems
Building Intelligent Document Processing systems for financial institutions is challenging. In this article, we share our approach to developing an IDP solution that goes far beyond a simple NLP task.
The series about Intelligent Document Processing (IDP) consists of 3 parts:
- Problem definition and data
- Classification and validation
- Entities finders
Building intelligent document processing systems - problem introduction
The selected domain that could be improved with AI was mortgage filings . These filings are required for mortgages to be serviced or transferred and are jurisdiction-specific. When a loan is serviced, many forms are filed with jurisdictions, banks, servicing companies, etc. These forms must be filed promptly, correctly, and accurately. Many of these forms are actual paper as only a relatively small number of jurisdictions allow for e-sign.
The number of types of documents is immense. For example, we are looking at MSR Transfers, lien release, lien perfection, servicing transfer, lien enforcement, lien placement, foreclosure, forbearance, short sell, etc. All of these procedures have more than one form and require specific timeframes for not only filing but also follow-up. Most jurisdictions are extremely specific on the documents and their layout. Ranging from margins to where the seals are placed to a font to sizing to wording. It can change between geographically close jurisdictions.
What may be surprising, these documents, usually paper, are sent to the centers to be sorted and scanned. The documents are visually inspected by a human. They decide not only further processing of the documents but sometimes need to extract or tag some knowledge at the stage of routing. This process seems incredibly laborious considering the fact that a large organization can process up to tens of thousands of documents per day!
AI technology, as its understanding and trust grows, naturally finds a place in similar applications, automating subsequent tasks, one by one. There are many places waiting for technological advancement, and here are some ideas on how it can be done.
Overview
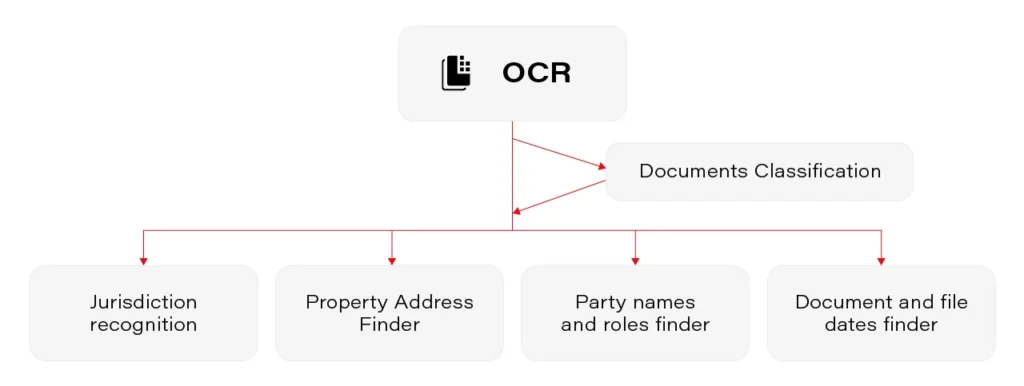
There are a few crucial components in the prepared solution
- OCR
- Documents classification
- Jurisdiction recognition
- Property addresses
- Party names and roles
- Document and file date
Each of them has some specific aspects that have to be handled, but all of them (except OCR) fall into one of 2 classical Natural Language Processing tasks: classification and Named Entity Recognition (NER).
OCR
There are a lot of OCRs that can transcribe the text from a document. Contrary to what we know after working on VIN Recognition System , the available OCRs are probably designed and are doing well on random documents of various kinds.
On the other hand, having some possibilities – Microsoft Computer Vision, AWS Textract, Google Cloud Vision, open-source Tesseract, naming a few, how to choose the best one? Determining the solution that fits best in our needs is a tough decision on its own. It requires well-structured experiments.
- We needed to prepare test sets to benchmark overall accuracy
- We needed to analyze the performance on handwriting
The results showed huge differences between the services, both in terms of accuracy on regular and hand-written text.
The best services we found were Microsoft Computer Vision, AWS Textract, and Google Cloud Vision. On 3 sets, they achieved the following results:
AWS Textract Microsoft CV Google CV Set 1 66.4 95.8 93.1 Set 2 87.2 96.5 91.8 Set 3 78.0 92.6 93.8 % of OCR results on different benchmarks
Hand-written text works on its own terms. As often in the real world, any tool has weaknesses, and the performance on printed text is somehow opposite to the performance on the hand-written text. In summary, OCRs have different characteristics in terms of output information, recognition time, detection, and recognition accuracy. There are at best 8% errors, but some services work as badly as recognizing 25% of words wrongly.
After selecting OCR, we had to generate data for classifiers. Recognizing tons of documents is a time-consuming process (the project team spent an extra month on the character recognition itself.) After that step, we could collect the first statistics and describe the data.
Data diversity
We collected over 80000 documents. The average file had 4.3 pages. Some of them longer than 10 pages, with a record holder of 96 pages.
Take a look at the following documents – Document A and Document B. They are both of the same type – Bill of Sale!

- Half of document A is hand-written, while the other has only signatures
- There is just a brief detail about the selling process on Doc A, whereas on the other there are a lot of details about the truck inspection
- The sold vehicle in document B is described in the table
- Only the day in the document date of document B is hand-written
- There is a barcode on the Doc A
- The B document has 300% more words than the A
Also, we find a visual impression of these documents much different.
How can the documents be so different? The types of documents are extremely numerous and varied, but also are constantly being changed and added by the various jurisdictions. Sometimes they are sent together with the attachments, so we have to distinguish the attachment from the original document.
There are more than 3000 jurisdictions in the USA. Only a few administrative jurisdictions share mortgage fillings. Fortunately, we could focus on present-day documents, but it happens that some of the documents have to be processed that are more than 30 years old.
Some documents were well structured: each interesting value was annotated with a key, everything in tables. It happened, however, that a document was entirely hand-written. You can see some documents in the figures. Take a note that some information on the first is just a work marked with a circle!


Next steps
The obtained documents were just the fundamentals for the next research. Such a rich collection enabled us to take the next steps , even though the variety of documents was slightly frightening. Did we manage to use the gathered documents for a working system?
Interested in our services?
Reach out for tailored solutions and expert guidance.