Apache Kafka Fundamentals


Nowadays, we have plenty of unique architectural solutions. But all of them have one thing in common – every single decision should be done after a solid understanding of the business case as well as the communication structure in a company. It is strictly connected with famous Conway’s Law:
“Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.”
In this article, we go deeper into the Event-Driven style, and we discover when we should implement such solutions. This is when Kafka comes to play.
The basic definition taken from the Apache Kafka site states that this is an open-source distributed event streaming platform. But what exactly does it mean? We explain the basic concepts of Apache Kafka, how to use the platform, and when we may need it.
Apache Kafka is all about events
To understand what the event streaming platform is, we need to have a prior understanding of an event itself. There are different ways of how the services can interact with each other – they can use Commands, Events, or Queries. So, what is the difference between them?
- Command – we can call it a message in which we expect something to be done – like in the army when the commander gives an order to soldiers. In computer science, we are making requests to other services to perform some action, which causes a system state change. The crucial part is that they are synchronous, and we expect that something will happen in the future. It is the most common and natural method for communication between services. On the other hand, you do not really know if your expectation will be fulfilled by the service. Sometimes we create commands, and we do not expect any response (it is not needed for the caller.)
- Event – the best definition of an event is a fact. It is a representation of the change which happened in the service (domain). It is essential that there is no expectation of any future action. We can treat an event as a notification of state change. Events are immutable. In other words – it is everything necessary for the business. This is also a single source of truth, so events need to precisely describe what happened in the system.
- Query – in comparison to the others, the query is only returning a response without any modifications in the system state. A good example of how it works can be an SQL query.
Below there is a small summary which compares all the above-mentioned ways of interaction:

Now we know what the event is in comparison to other interaction styles. But what is the advantage of using events? To understand why event-driven solutions are better than synchronous request-response calls, we have to learn a bit about software architecture history.
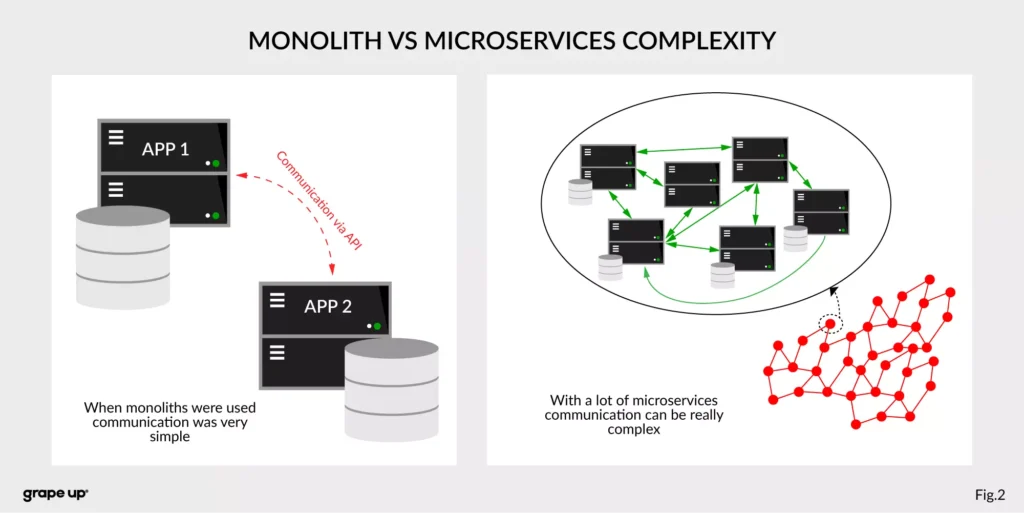
The figure describes a difference between a system that has old monolith architecture and a system with new modern microservice architecture.
The left side of the figure presents an API communication between two monoliths. In this case, communication is straightforward and easy. There is a different problem though such monolith solutions are very complex and hard to maintain.
The question is, what happens if we want to use, instead of two big services, a few thousands of small microservices. How complex will it be? The directed graph on the right side is showing how quickly the number of calls in the system can grow, and with it, the number of shared resources. We can have a situation when we need to use data from one microservice in many places. That produces new challenges regarding communication.
What about communication style?
In both cases, we are using a request-response style of communication (figure below), and we need to know how to use API provided by the server from the caller perspective. There must be some kind of protocol to exchange messages between services.
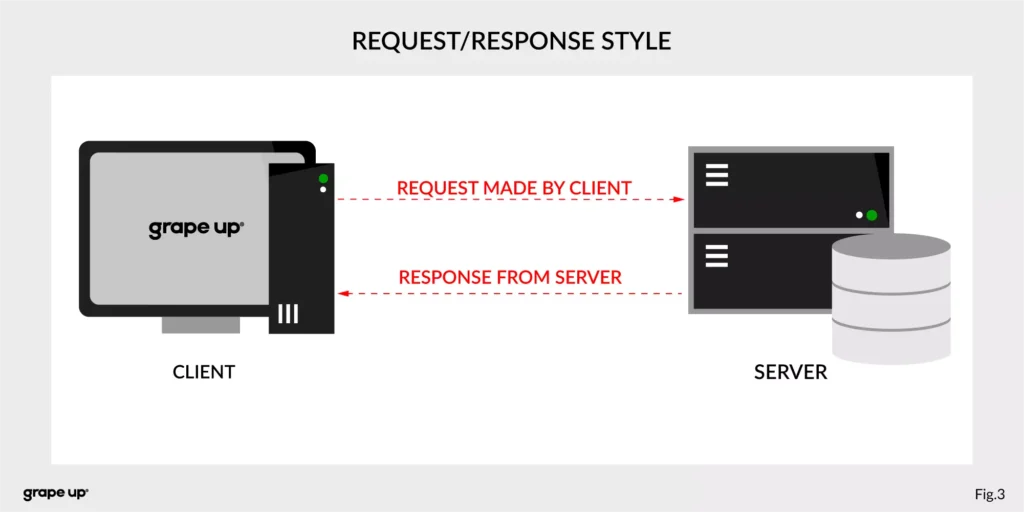
So how to reduce the complexity and make an integration between services easier? To answer this – look at the figure below.
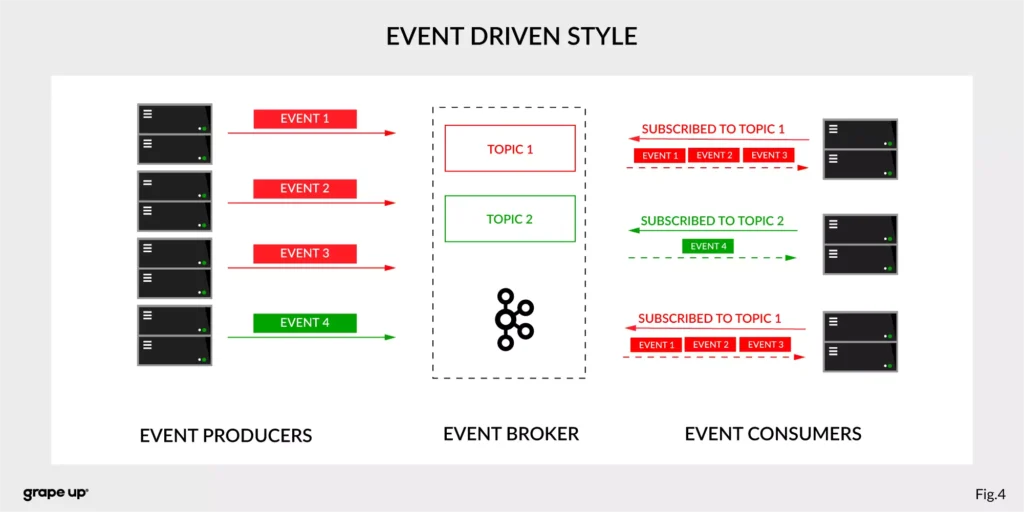
In this case, interactions between event producers and consumers are driven by events only. This pattern supports loose coupling between services, and what is more important for us, the event producer does not need to be aware of the event consumer state. It is the essence of the pattern. From the producer’s perspective, we do not need to know who or how to use data from the topic.
Of course, as usual, everything is relative. It is not like the event-driven style is always the best. It depends on the use case. For instance, when operations should be done synchronously, then it is natural to use the request-response style. In situations like user authentication, reporting AB tests, or integration with third-party services, it is better to use a synchronous style. When the loose coupling is a need, then it is better to go with an event-driven approach. In larger systems, we are mixing styles to achieve a business goal.
The name of Kafka has its origins in the word Kafkaesque which means according to the Cambridge dictionary something extremely unpleasant, frightening, and confusing, and similar to situations described in the novels of Franz Kafka.
The communication mess in the modern enterprise was a factor to invent such a tool. To understand why – we need to take a closer look at modern enterprise systems.
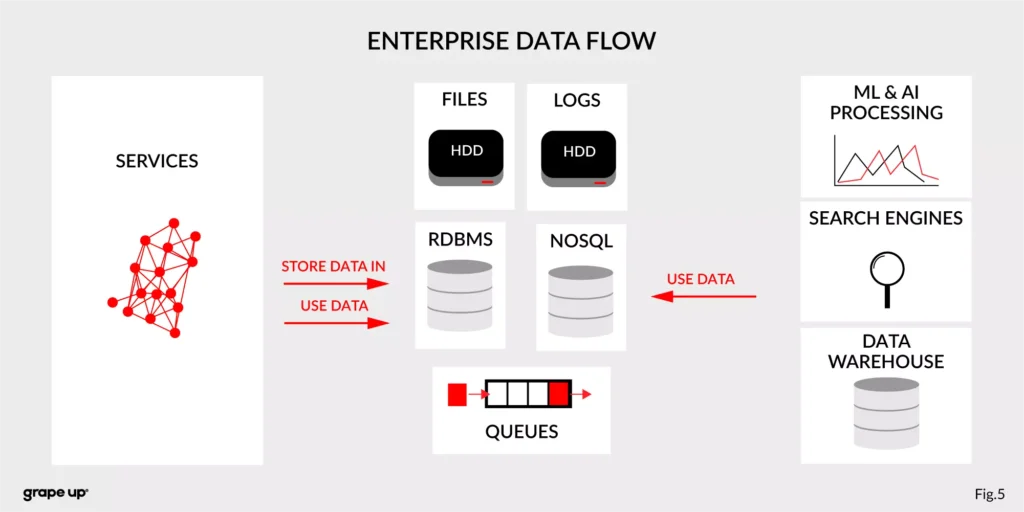
The modern enterprise systems contain more than just services. They usually have a data warehouse, AI and ML analytics, search engines, and much more. The format of data and the place where data is stored are various – sometimes a part of the data is stored in RDBMS, a part in NoSQL, and other in file bucket or transferred via a queue. They can have different formats and extensions like XML, JSON, and so on. Data management is the key to every successful enterprise. That is why we should care about it. Tim O’Reilly once said:
„We are entering a new world in which data may be more important than software.”
In this case, having a good solution for processing crucial data streams across an enterprise is a must to be successful in business. But as we all know, it is not always so easy.
How to tame the beast?
For this complex enterprise data flow scenario, people invented many tools/methods. All to make this enterprise data distribution possible. Unfortunately, as usual, to use them, we have to make some tradeoffs. Here we have a list of them:
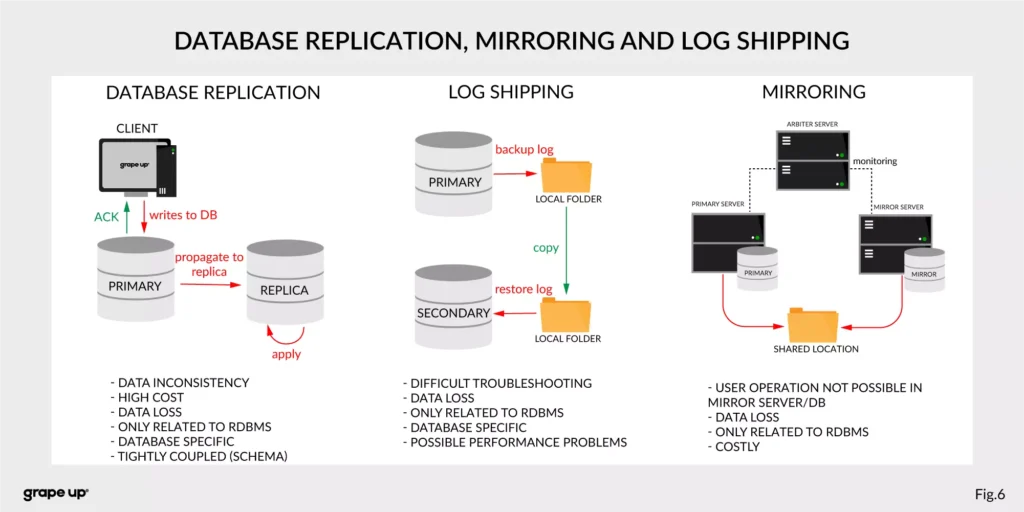
- Database replication, Mirroring, and Log Shipping – used to increase the performance of an application (scaling) and backup/recovery.
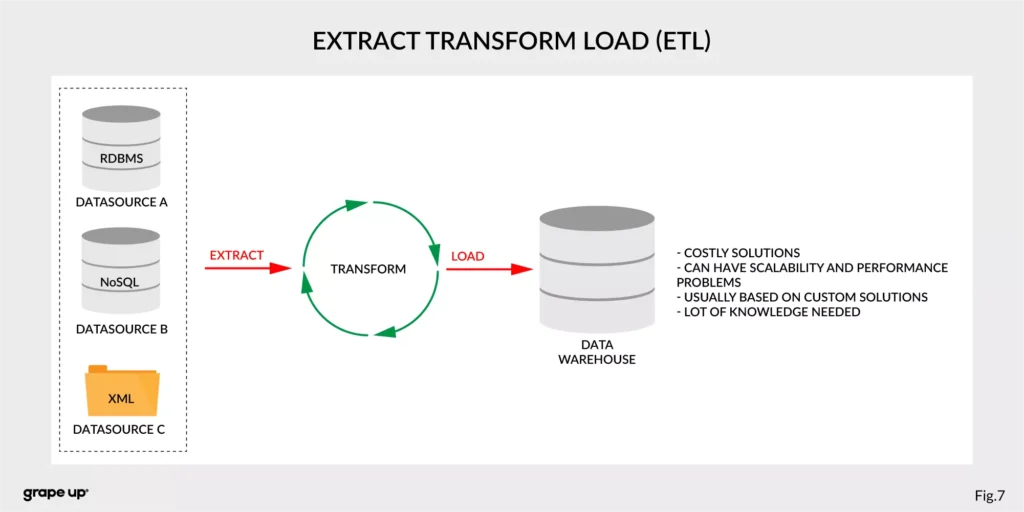
- ETL – Extract, Transform, Load – used to copy data from different sources for analytics/reports.
- Messaging systems – provide asynchronous communication between systems.

As you can see, we have a lot of problems that we need to take care of to provide correct data flow across an enterprise organization. That is why Apache Kafka was invented. One more time we have to go to the definition of Apache Kafka. It is called a distributed event streaming platform. Now we know what the event is and how event-driven style looks like. So as you probably can guess, event streaming, in our case, means capturing, storing, manipulating, processing, reacting, and routing event streams in real-time. It is based on three main capabilities – publishing/subscribing, storing, and processing. These three capabilities make this tool very successful.
- Publishing/Subscribing provides an ability to read/write to streams of events and even more – you can continuously import/export data from different sources/systems.
- Storing is also very important here. It solves the abovementioned problems in messaging. You can store streams of events for as long as you want without being afraid that something will be gone.
- Processing allows us to process streams in real-time or use history to process them.
But wait! There is one more word to explain – distributed. Kafka system internally consists of servers and clients. It uses a high-performance TCP Protocol to provide reliable communication between them. Kafka runs as a cluster on one or multiple servers which can be easily deployed in the cloud or on-prem in single or multiple regions. There are also Kafka Connect servers used for integration with other data sources and other Kafka Clusters. Clients that can be implemented in many programming languages have a special role to read/write and process event streams. The whole ecosystem of Kafka is distributed and of course like every distributed system has a lot of challenges regarding node failures, data loss, and coordination.
What are the basic elements of Apache Kafka?
To understand how Apache Kafka works let first explain the basic elements of the Kafka ecosystem.
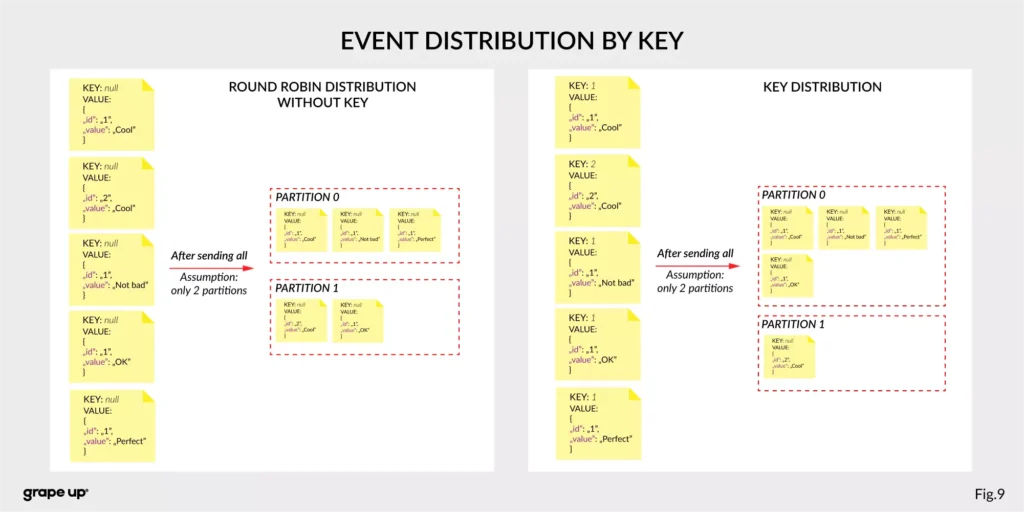
Firstly, we should take a look at the event. It has a key, value, timestamp, and optional metadata headers. A key is used not only for identification, but it is used also for routing and aggregation operations for events with the same key.
As you can see in the figure below – if the message has no key attached, then data is sent using a round-robin algorithm. The situation is different when the event has a key attached. Then the events always go to the partition which holds this key. It makes sense from the performance perspective. We usually use ids to get information about objects, and in that case, it is faster to get it from the same broker than to look for it on many brokers.
The value, as you can guess, stores the essence of the event. It contains information about the business change that happened in the system.
There are different types of events:
- Unkeyed Event – event in which there is no need to use a key. It describes a single fact of what happened in the system. It could be used for metric purposes.
- Entity Event – the most important one. It describes the state of the business object at a given point in time. It must have a unique key, which usually is related to the id of the business object. They are playing the main role in event-driven architectures.
- Keyed Event – an event with a key but not related to any business entity. The key is used for aggregation and partitioning.
Topics –storage for events. The analogy to a folder in a filesystem, where the topic is like a folder that organizes what is inside. An example name of the topic, which keeps all orders events in the e-commerce system can be “orders”. Unlike in other messaging systems, the events stay on the topic after reading. It makes it very powerful and fault-tolerant. It also solves a problem when the consumer will process something with an error and would like to process it again. Topics can always have zero, single, and multiple producers and subscribers.
They are divided into smaller parts called partitions. A partition can be described as a “commit log”. Messages can be appended to the log and can be read only in the order from the beginning to the end. Partitions are designed to provide redundancy and scalability. The most important fact is that partitions can be hosted on different servers (brokers), and that gives a very powerful way to scale topics horizontally.
Producer – client application responsible for the creation of new events on Kafka Topic. The producer is responsible for choosing the topic partition. By default, as we mentioned earlier round-robin is used when we do not provide any key. There is also a way of creating custom business mapping rules to assign a partition to the message.
Consumer – client application responsible for reading and processing events from Kafka. All events are being read by a consumer in the order in which they were produced. Each consumer also can subscribe to more than one topic. Each message on the partition has a unique integer identifier (offset) generated by Apache Kafka which is increased when a new message arrives. It is used by the consumer to know from where to start reading new messages. To sum up the topic, partition and offset are used to precisely localize the message in the Apache Kafka system. Managing an offset is the main responsibility for each consumer.
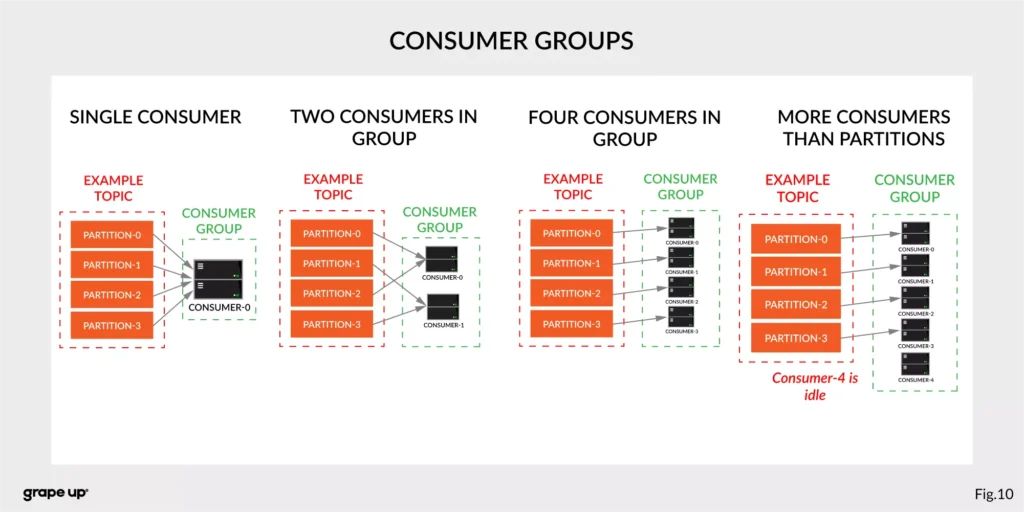
The concept of consumers is easy. But what about the scaling? What if we have many consumers, but we would like to read the message only once? That is why the concept of consumer group was designed. The idea here is when consumer belongs to the same group, it will have some subset of partitions assigned to read a message. That helps to avoid the situation of duplicated reads. In the figure below, there is an example of how we can scale data consumption from the topic. When a consumer is making time-consuming operations, we can connect other consumers to the group, which helps to process faster all new events on the consumer level. We have to be careful though when we have a too-small number of partitions, we would not be able to scale it up. It means if we have more consumers than partitions, they are idle.
But you can ask – what will happen when we add a new consumer to the existing and running group? The process of switching ownership from one consumer to another is called “rebalance.” It is a small break from receiving messages for the whole group. The idea of choosing which partition goes to which consumer is based on the coordinator election problem.
Broker – is responsible for receiving and storing produced events on disk, and it allows consumers to fetch messages by a topic, partition, and offset. Brokers are usually located in many places and joined in a cluster. See the figure below.
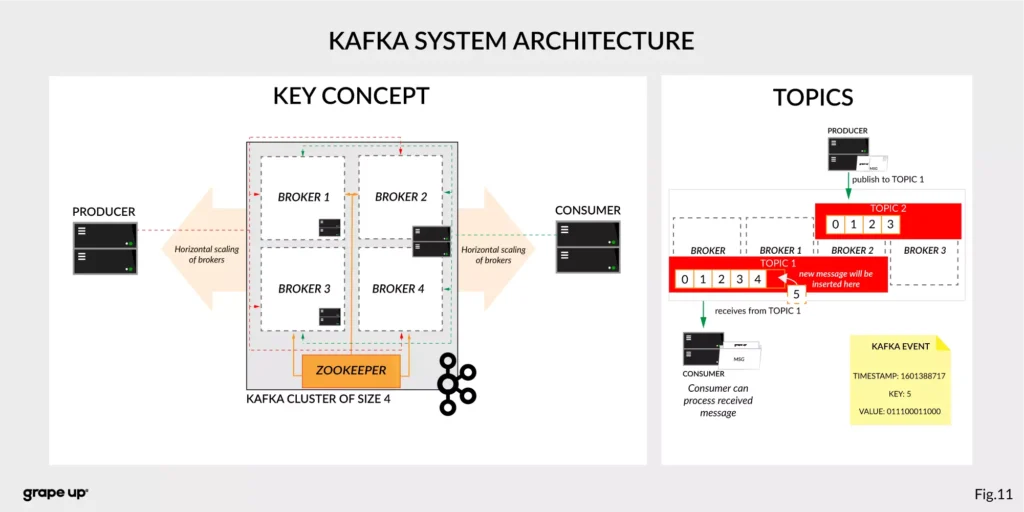
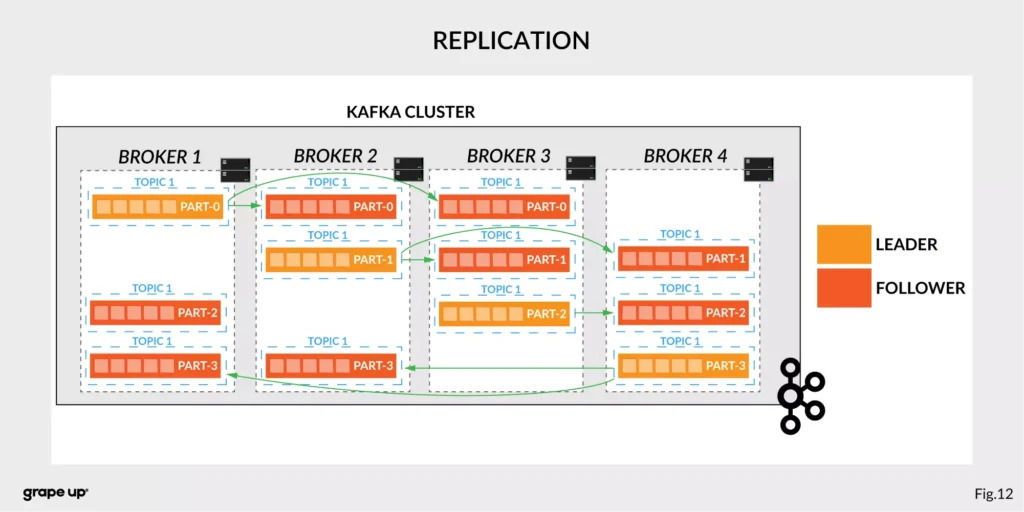
Like in every distributed system, when we use brokers we need to have some coordination. Brokers, as you can see, can be run on different servers (also it is possible to run many on a single server). It provides additional complexity. Each broker contains information about partitions that it owns. To be secure, Apache Kafka introduced a dedicated replication for partitions in case of failures or maintenance. The information about how many replicas do we need for a topic can be set for every topic separately. It gives a lot of flexibility. In the figure below, the basic configuration of replication is shown. The replication is based on the leader-follower approach.
Everything is great! We have found all advantages of using Kafka in comparison to more traditional approaches. Now it is time to say something when to use it.
When to use Apache Kafka?
Apache Kafka provides a lot of use cases. It is widely used in many companies, like Uber, Netflix, Activision, Spotify, Slack, Pinterest, Coursera, LinkedIn, etc. We can use it as a:
- Messaging system – it can be a good alternative to the existing messaging systems. It has a lot of flexibility in configuration, better throughput, and low end-to-end latency.
- Website Activity tracking – it was the original use case for Kafka. Activity tracking on the website generates a high volume of data that we have to process. Kafka provides real-time processing for event-streams, which can be sometimes crucial for the business.
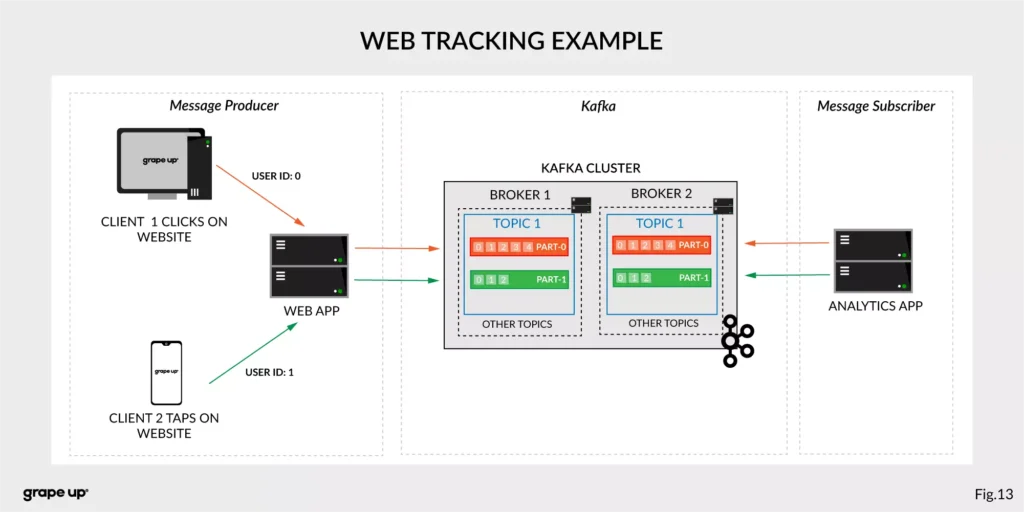
Figure 13 presents a simple use case for web tracking. The web application has a button that generates an event after each click. It is used for real-time analytics. Clients’ events that are gathered on TOPIC 1. Partitioning is using user-id so client 1 events (user-id = 0) are stored in partition 0 and client 2 (user-id = 1) are stored in partition 1. The record is appended and offset is incremented on a topic. Now, a subscriber can read a message, and present new data on a dashboard or even use older offset to show some statistics.
- Log aggregation – it can be used as an alternative to existing log aggregation solutions. It gives a cleaner way of organizing logs in form of the event streams and what is more, gives a very easy and flexible way to gather logs from many different sources. Comparing to other tools is very fast, durable, and has low end-to-end latency.
- Stream processing – is a very flexible way of processing data using data pipelines. Many users are aggregating, enriching, and transforming data into new topics. It is a very quick and convenient way to process all data in real-time.
- Event sourcing – is a system design in which immutable events are stored as a single source of truth about the system. A typical use case for event sourcing can be found in bank systems when we are loading the history of transactions. The transaction is represented by an immutable event which contains all data describing what exactly happened in our account.
- Commit log – it can be used as an external commit-log for distributed systems. It has a lot of mechanisms that are useful in this use case (like log-compaction, replication, etc.)
Summary
Apache Kafka is a powerful tool used by leading tech enterprises. It offers a lot of use cases, so if we want to use a reliable and durable tool for our data, we should consider Kafka. It provides a loose coupling between producers and subscribers, making our enterprise architecture clean and open to changes. We hope you enjoyed this basic introduction to Apache Kafka and you will try to dig deeper into how it works after this article.
Looking for guidance on implementing Kafka or other event-driven solutions?
Get in touch with us to discuss how we can help.
Sources:
- kafka.apache.org/intro
- confluent.io/blog/journey-to-event-driven-part-1-why-event-first-thinking-changes-everything/
- hackernoon.com/by-2020-50-of-managed-apis-projected-to-be-event-driven-88f7041ea6d8
- ably.io/blog/the-realtime-api-family/
- confluent.io/blog/changing-face-etl/
- infoq.com/articles/democratizing-stream-processing-kafka-ksql-part2/
- cqrs.nu/Faq
- medium.com/analytics-vidhya/apache-kafka-use-cases-e2e52b892fe1
- confluent.io/blog/transactions-apache-kafka/
- martinfowler.com/articles/201701-event-driven.html
- pluralsight.com/courses/apache-kafka-getting-started#
- jaceklaskowski.gitbooks.io/apache-kafka/content/kafka-brokers.html
Bellemare, Adam. Building event-driven microservices: leveraging distributed large-scale data. O’Reilly Media, 2020.
Narkhede, Neha, et al. Kafka: the Definitive Guide: Real-Time Data and Stream Processing at Scale. O’Reilly Media, 2017.
Stopford, Ben. Designing Event-Driven Systems, Concepts and Patterns for Streaming Services with Apache Kafka, O’Reilly Media, 2018.
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles

