Leveraging AI To Improve VIN Recognition – How To Accelerate and Automate Operations in the Insurance Industry


Here we share our approach to automatic Vehicle Identification Number (VIN) detection and recognition using Deep Neural Networks. Our solution is robust in many aspects such as accuracy, generalization, and speed, and can be integrated into many areas in the insurance and automotive sectors.
Our goal is to provide a solution allowing us to take a picture using a mobile app and read the VIN that is present in the image. With all the similarities to any other OCR application and common features, the differences are colossal.
Our objective is to create a reliable solution and to do so we jumped directly into analysis of the real domain images.
VINs are located in many places on a car and its parts. The most readable are those printed on side doors and windshields. Here we focus on VINs from windshields.

OCR doesn’t seem to be rocket science now, does it? Well, after some initial attempts, we realized we’re not able to use any available commercial tools with success, and the problem was much harder than we had thought.
How do you like this example of KerasOCR?

Despite many details, like the fact that VINs don’t contain the characters ‘I’, ‘O’, ‘Q’, we have very specific distortions, proportions, and fonts.
Initial approach
How can we approach the problem? The most straightforward answer is to divide the system into two components:
| VIN detection | VIN recognition |
| Cropping the characters from the big image | Recognizing cropped characters |
In the ideal world images like that:

Will be processed this way:

After we have the intuition how the problem looks like, we can we start solving it. Needless to say, there is no “VIN reading” task available on the internet, therefore we need to design every component of our solution from scratch. Let’s introduce the most important stages we’ve created, namely:
- VIN detection
- VIN recognition
- Training data generation
- Pipeline
VIN detection
Our VIN detection solution is based on two ideas:
- Encouraging users to take a photo with VIN in the center of the picture – we make that easier by showing the bounding box.
- Using Character Region Awareness for Text Detection (CRAFT) – a neural network to mark VIN precisely and be more error-prone.
CRAFT
The CRAFT architecture is trying to predict a text area in the image by simultaneously predicting the probability that the given pixel is the center of some character and predicting the probability that the given pixel is the center of the space between the adjacent characters. For the details, we refer to the original paper.
The image below illustrates the operation of the network:

Before actual recognition, it had sound like a good idea to simplify the input image vector to contain all the needed information and no redundant pixels. Therefore, we wanted to crop the characters’ area from the rest of the background.
We intended to encourage a user to take a photo with a good VIN size, angle, and perspective.
Our goal was to be prepared to read VINs from any source, i.e. side doors. After many tests, we think the best idea is to send the area from the bounding box seen by users and then try to cut it more precisely using VIN detection. Therefore, our VIN detector can be interpreted more like a VIN refiner.
It would be remiss if we didn’t note that CRAFT is exceptionally unusually excellent. Some say every precious minute communing with it is pure joy.
Once the text is cropped, we need to map it to a parallel rectangle. There are dozens of design dictions such as the affine transform, resampling, rectangle, resampling for text recognition, etc.
Having ideally cropped characters makes recognition easier. But it doesn’t mean that our task is completed.
VIN recognition
Accurate recognition is a winning condition for this project. First, we want to focus on the images that are easy to recognize – without too much noise, blur, or distortions.
Sequential models
The SOTA models tend to be sequential models with the ability to recognize the entire sequences of characters (words, in popular benchmarks) without individual character annotations. It is indeed a very efficient approach but it ignores the fact that collecting character bounding boxes for synthetic images isn’t that expensive.
As a result, we devaluated supposedly the most important advantage of the sequential models. There are more, but are they worth watching out all the traps that come with them?
First of all, training attention-based model is very hard in this case because of
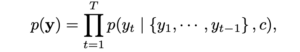
As you can see, the target characters we want to recognize are dependent on history. It could be possible only with a massive training dataset or careful tuning, but we omitted it.
As an alternative, we can use Connectionist Temporal Classification (CTC) models that in opposite predict labels independently of each other.
More importantly, we didn’t stop at this approach. We utilized one more algorithm with different characteristics and behavior.
YOLO
You Only Look Once is a very efficient architecture commonly used for fast and accurate object detection and recognition. Treating a character as an object and recognizing it after the detection seems to be a definitely worth trying approach to the project. We don’t have the problem and there are some interesting tweaks that can allow even more precise recognition in our case. Last but not least, we are able to have a bigger control of the system as much of the responsibility is transferred from the neural network.
However, the VIN recognition requires some specific design of YOLO. We used YOLO v2 because the latest architecture patterns are more complex in areas that do not fully address our problem.
- We use 960 x 32 px input (so images cropped by CRAFT are usually resized to meet this condition). Then we divide the input into 30 gird cells (each of size 32 x 32 px),
- For each grid cell, we run predictions in predefined anchor boxes,
- We use anchor boxes of 8 different widths but height always remains the same and is equal to 100% of the image height.
As the results came, our approach proved to be effective in recognizing individual characters from VIN.

Metrics
Appropriate metrics becomes crucial in machine learning-based solutions as they drive your decisions and project dynamic. Fortunately, we think simple accuracy fulfills the demands of a precise system and we can omit the research in this area.
We just need to remember one fact: a typical VIN contains 17 characters, and it’s enough to miss one of them to classify the prediction as wrong. At any point of work, we measure Character Recognition Rate (CER) to understand the development better. CERs at a level 5% (5% of wrong characters) may result in accuracy lower than 75%.
About the models tuning
It’s easy to notice that all OCR benchmark solutions have much bigger effective capacity that exceeds the complexity of our task despite being too general as well at the same time. That itself emphasizes the danger of overfitting and directs our focus to generalization ability.
It is important to distinguish hyperparameters tuning from architectural design. Apart from ensuring information flow through the network extracts correct features, we do not dive into extended hyperparameters tuning.
Training data generation
We skipped one important topic: the training data.
Often, we support our models with artificial data with reasonable success but this time the profit is huge. Cropped synthetized texts are so similar to the real images that we suppose we can base our models on them, and only finetune it carefully with real data.
Data generation is a laborious, tricky job. Some say your model is as good as your data. It feels like the craving and any mistake can break your material. Worse, you can spot it as late as after the training.
We have some pretty handy tools in arsenal but they are, again, too general. Therefore we had to introduce some modifications.
Actually, we were forced to generate more than 2M images. Obviously, there is no point nor possibility of using all of them. Training datasets are often crafted to resemble the real VINs in a very iterative process, day after day, font after font. Modeling a single General Motors font took us at least a few attempts.
But finally, we got there. No more T’s as 1’s, V’s as U’s, and Z’s as 2’s!
We utilized many tools. All have advantages and weaknesses and we are very demanding. We need to satisfy a few conditions:
- We need a good variance in backgrounds. It’s rather hard to have a satisfying amount of windshields background, so we’d like to be able to reuse those that we have, and at the same time we don’t want to overfit to them, so we want to have some different sources. Artificial backgrounds may not be realistic enough, so we want to use some real images from outside our domain,
- Fonts, perhaps most important ingredients in our combination, have to resemble creative VIN’s fonts (who made them!?) and cannot interfere with each other. At the same time, the number of car manufacturers is much higher than our collector’s impulses, so we have to be open to unknown shapes.
The below images are the example of VIN data generation for recognizers:


Putting everything together
It’s the art of AI to connect so many components into a working pipeline and not mess it up.
Moreover, we have a lot of traps here. Mind these images:

VIN labels often consist of separated strings, two rows, logos and bar codes present near the caption.
90% of end-to-end accuracy provided by our VIN reader
Under one second solely on mid-quality CPU, our solution has over 90% of end-to-end accuracy.
This result depends on the problem definition and test dataset. For example, we have to decide what to do with the images that are impossible to read by a human. Nevertheless, not regarding the dataset, we approached human-level performance which is a typical reference level in Deep Learning projects.
We also managed to develop a mobile offline version of our system with similar inference accuracy but a bit slower processing time.
App intelligence
While working on the tools designed for business, we can’t forget about the real use-case flow. With the above pipeline, we’re absolutely unresistant to photos that are impossible to read, even though we want it to be. Often similar situations happen due to:
- incorrect camera focus,
- light flashes,
- dirt surfaces,
- damaged VIN plate.
Usually, we can prevent these situations by asking users to change the angle or retake a photo, before we send it to the further processing engines.
However, the classification of these distortions is a pretty complex task! Nevertheless, we implemented a bunch of heuristics and classifiers that allow us to ensure that VIN, if recognized, is correct. For the details, you have to wait for the next post.
Last but not least, we’d like to mention that, as usual, there are a lot of additional components built around our VIN Reader. Apart from a mobile application, offline on-device recognition, we’ve implemented remote backend, pipelines, tools for tagging, semi-supervised labeling, synthesizers, and more.
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles