Train Your Computer with the Julia Programming Language – Machine Learning in Julia


Once we know the basics of Julia, we focus on its utilization in building machine learning software. We go through the most helpful tools and moving from prototyping to production.
How to do Machine Learning in Julia
Machine Learning tools dedicated to Julia have evolved very fast in the last few years. In fact, quite recently, we can say that Julia is production-ready! – as it was announced on JuliaCon2020.
Now, let’s talk about the native tools available in Julia’s ecosystem for Data Scientists. Many libraries and frameworks that serve machine learning models are available in Julia. In this article, we focus on a few the most promising libraries.
DataFrames.jl is a response to the great popularity of pandas – a library for data analysis and manipulation, especially useful for tabular data. DataFrames module plays a central role in the Julia data ecosystem and has tight integrations with a range of different libraries. DataFrames are essentially collections of aligned Julia vectors so they can be easily converted to other types of data like Matrix. Pandas.jl package provides binding to the pandas’ library if someone can’t live without it, but we recommend using a native DataFrames library for tabular data manipulation and visualization.
In Julia, usually, we don’t need to use external libraries as we do with numpy in Python to achieve a satisfying performance of linear algebra operations. Native Arrays and Matrices may perform satisfactorily in many cases. Still, if someone needs more power here there is a great library StaticArrays.jl implementing statically sized arrays in Julia. Potential speedup falls in a range from 1.8x to 112.9x if the array isn’t big (based on tests provided by the authors of the library).
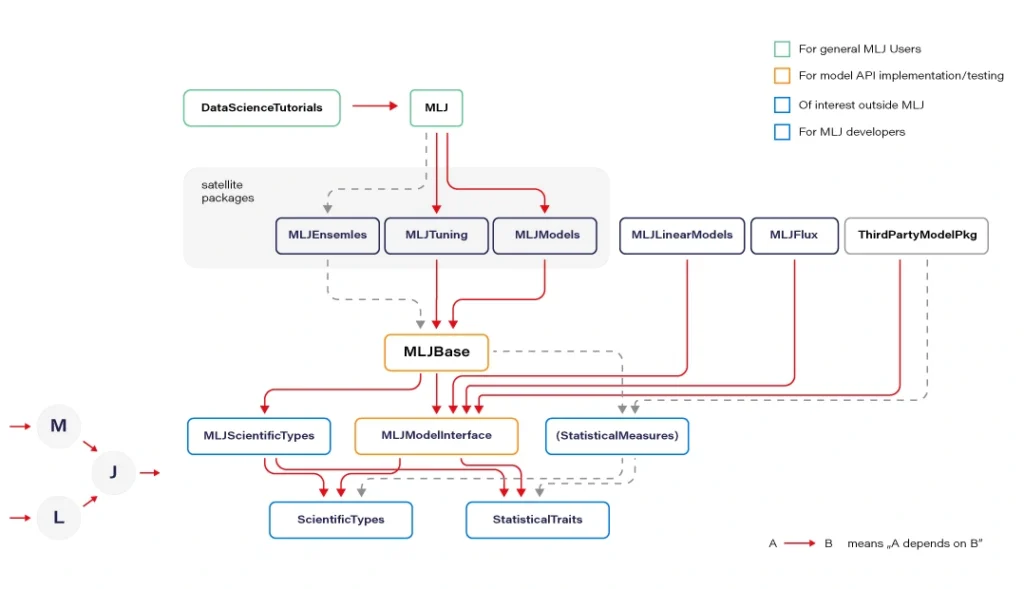
MLJ.jl created by Alan Turing Institute provides a common interface and meta-algorithms for selecting, tuning, evaluating, composing, and comparing over 150 machine learning models written in Julia and other languages. The library offers an API that lets you manage ML workflows in many aspects. Some parts of the API syntax may seem unfamiliar to the audience but remains clear and easy to use.
Flux.jl defines models just like mathematical notation. Provides lightweight abstractions on top of Julia’s native GPU and TPU – GPU kernels can be written directly in Julia via CUDA.jl. Flux has its own Model Zoo and great integration with Julia’s ecosystem.
MXNet.jl is a part of a big Apache MXNet project. MXNet brings flexible and efficient GPU computing and state-of-art deep learning to Julia. The library offers very efficient tensor and matrix computation across multiple CPUs, GPUs, and disturbed server nodes.
Knet.jl (pronounced “kay-net”) is the Koç University deep learning framework. The library supports GPU operations and automates differentiation using dynamic computational graphs for models defined in plain Julia.
AutoMLPipeline is a package that makes it trivial to create complex ML pipeline structures using simple expressions. AMLP leverages on the built-in macro programming features of Julia to symbolically process, manipulate pipeline expressions, and makes it easy to discover optimal structures for machine learning prediction and classification.
There are many more specific libraries like DecisionTree.jl, Transformers.jl, or YOLO.jl which are often immature but still can be utilized. Obviously, bindings to other popular ML frameworks exists, where many people may find TensorFlow.jl, Torch.jl, or ScikitLearn.jl as useful. We recommend using Flux or MLJ as the default choice for a new ML project.
Now let’s discuss the situation when Julia is not ready. And here, PyCall.jl comes to the rescue. The Python ecosystem is far greater than Julia’s. Someone could argue here that using such a connector loses all of the speed gained from using Julia and can even be slower than using Python standalone. Well, that’s true. But it’s worth to realize that we ask PyCall for help not so often because the number of native Julia ML libraries is quite good and still growing. And even if we ask, the scope is usually limited to narrow parts of our algorithms.
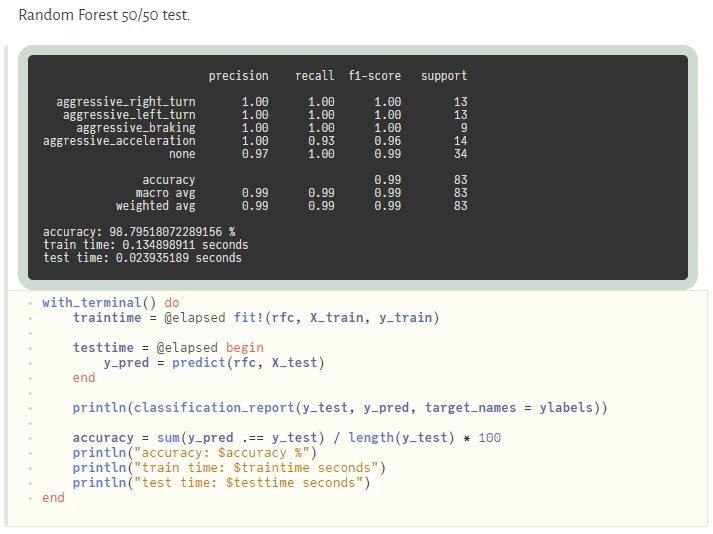
Sometimes sacrificing a part of application performance can be a better choice than sacrificing too much of our time, especially during prototyping. In a production environment, the better idea may be (but it’s not a rule) to call to a C or C++ API of some of the mature ML frameworks (there are many of them) if a Julia equivalent is not available. Here is an example of how easily one can use the famous python scikit-learn library during prototyping:
@sk_import ensemble: RandomForestClassifier; fit!(RandomForestClassifier(), X, y)
The powerful metaprogramming features (@sk_import macro via PyCall) take care of everything, exposing clean and functional style API of the selected package. On the other hand, because the Python ecosystem is very easily accessible from Julia (thanks to PyCall), many packages depend on it, and in turn, depend on Python, but that’s another story.
From Prototype to Production
In this section, we present a set of basic tools used in a typical ML workflow, such as writing a notebook, drawing a plot, deploying an ML model to a webserver or more sophisticated computing environments. I want to emphasize that we can use the same language and the same basic toolset for every stage of the machine learning software development process: from prototyping to production at full speed.
For writing notebooks, there are two main libraries available. IJulia.jl is a Jupyter language kernel and works with a variety of notebook user interfaces. In addition to the classic Jupyter Notebook, IJulia also works with JupyterLab, a Jupyter-based integrated development environment for notebooks and code. This option is more conservative.
For anyone who’s looking for something fresh and better, there is a great project called Pluto.jl – a reactive, lightweight and simple notebook with beautiful UI. Unlike Jupyter or Matlab, there is no mutable workspace, but an important guarantee: At any instant, the program state is completely described by the code you see. No hidden state, no hidden bugs. Changing one cell instantly shows effects on all other cells thanks to the reactive technologies used. And the most important feature: your notebooks are saved as pure Julia files! You can also export your notebook as HTML and PDF documents.
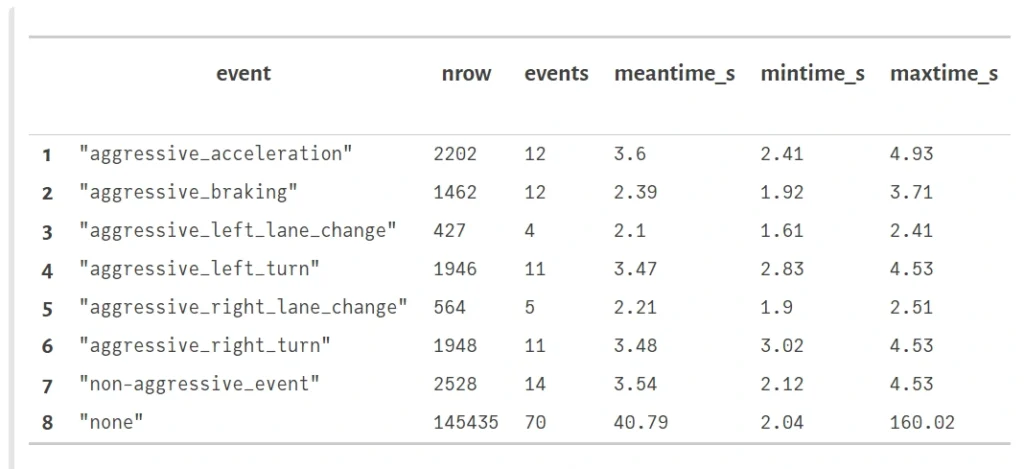
Visualization and plotting are essential parts of a typical machine learning workflow. We have several options here. For tabular data visualization there we can just simply use the DataFrame variable in a printable context. In Pluto, it looks really nice (and is interactive):
The primary option for plotting is Plots.jl, a plotting meta package that brings many different plotting packages under a single API, making it easy to swap between plotting “backends”. This is a mature package with a large number of features (including 3D plots). The downside is that it uses Python behind the scenes (but that’s not a severe issue here) and can cause problems with configuration.
Gadfly.jl is based largely on ggplot2 for R and renders high-quality graphics to SVG, PNG, Postscript, and PDF. The interface is simple and cooperates well with DataFrames.
There is an interesting package called StatsPlots.jl which is a replacement for Plots.jl that contains many statistical recipes for concepts and types introduced in the JuliaStats organization, including correlation plot, Andrew’s plot, MDS plot, and many more.

To expose the ML model as a service, we can establish a custom model server. To do so, we can use Genie.jl – a full-stack MVC web framework that provides a streamlined and efficient workflow for developing modern web applications and much more. Genie manages all of the virtual environments, database connectivity, or automatic deployment into docker containers (you just run one function, and everything works). It’s pure Julia and that’s important here because this framework manages the entire project for you. And it’s really very easy to use.
Apache Spark is a distributed data and computation engine that becomes more and more popular, especially among large companies and corporations. Hosted Spark instances offered by cloud service providers make it easy to get started and to run large, on-demand clusters for dynamic workloads.
While Scala, as the primary language of Spark, is not the best choice for some numerical computing tasks, being built for numerical computing, Julia is however perfectly suited to create fast and accurate numerical applications. Spark.jl is a library for that purpose. It allows you to connect to a Spark cluster from the Julia REPL and load data and submit jobs. It uses JavaCall.jl behind the scenes. This package is still in the initial development phase. Someone said that Julia is a bridge between Python and Spark – being simple like Python but having the big-data manipulation capabilities of Spark.
In Julia, we can do distributed computing effortlessly. We can do it with a useful JuliaDB.jl package, but straight Julia with distributed processes work well. We use it in production, distributed across multiple servers at scale. Implementation of distributed parallel computing is provided by module Distributed as part of the standard library shipped with Julia.
Machine Learning in Julia – Conclusions
We covered a lot of topics, but in fact, we only scratched the surface. Presented examples show that, under certain conditions, Julia can be considered as a serious option for your next machine learning project in an enterprise environment or scientific work. Some Rustaceans (Rust language users call themselves that) ask themselves in terms of machine learning capabilities in their loved language: Are we learning yet? Julia’s users can certainly answer yes! Are we production ready? Yes, but it doesn’t mean Julia is the best option for your machine learning projects. More often, the mature Python ecosystem will be the better choice. Is Julia the future of machine learning? We believe so, and we’re looking forward to see some interesting apps written with Julia.
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles