Practical tips to testing React apps with Selenium

If you ever had to write some automation scripts for an app with the frontend part done in React and you used Selenium Webdriver to get it to work, you’ve probably noticed that those two do not always get along very well. Perhaps you had to ‘hack’ your way through the task, and you were desperately searching for solutions to help you finish the job. I’ve been there and done that – so now you don’t have to. If you’re looking for a bunch of tricks which you can learn and expand your automation testing skillset, you’ve definitely come to the right place. Below I’ll share with you several solutions to problems I’ve encountered in my experience with testing against React with Selenium . Code examples will be presented for Python binding.
They see me scrolling
First, let’s take a look at scrolling pages. To do that, the solution that often comes to mind in automation testing is using JavaScript. Since we’re using Python here, the first search result would probably suggest using something like this:
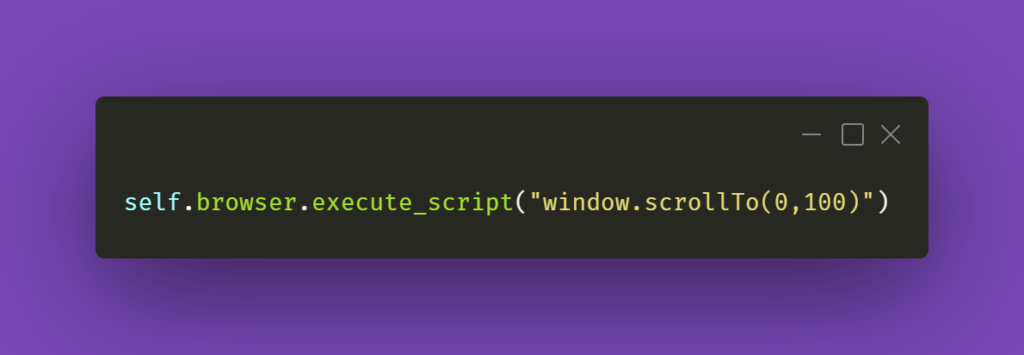
The first argument in the JS part is the number of pixels horizontally, and the second one is the number of pixels vertically. If we just paste window.scrollTo(0,100) into browsers’ console with some webpage opened, the result of the action will be scrolling the view vertically to the pixel position provided.
You could also try the below line of code:
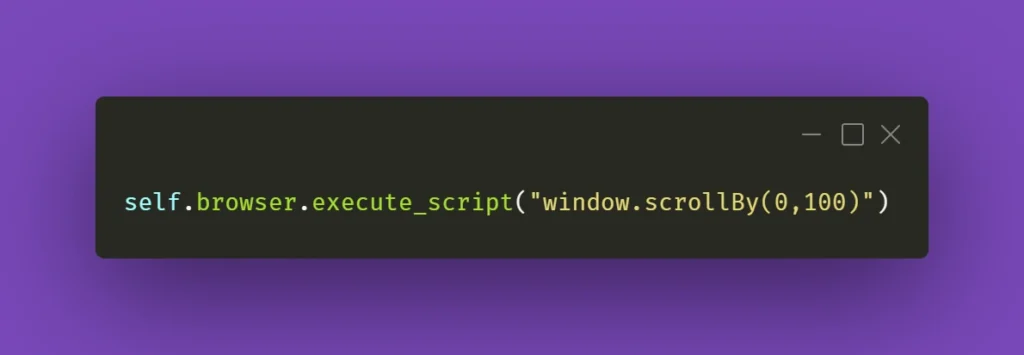
And again, you can see how it works by pasting window.scrollBy(0,100) into browsers’ console – the page will scroll down by the number of pixels provided. If you do this repeatedly, you’ll eventually reach the bottom of the page.
However, that might not always work wonders for you. Perhaps you do not want to scroll the whole page, but just a part of it – the scrollbars might be confusing, and when you think it’s the whole page you need to scroll, it might be just a portion of it. In that case, here’s what you need to do. First, locate the React element you want to scroll. Then, make sure it has an ID assigned to it. If not, do it yourself or ask your friendly neighborhood developer to do it for you. Then, all you have to do is write the following line of code:
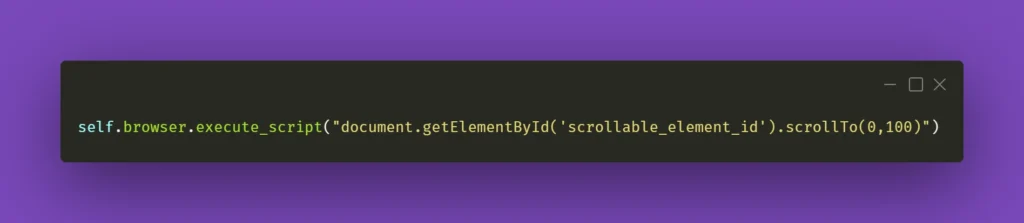
Obviously, don’t forget to change ‘scrollable_element_id’ to an ID of your element. That will perform a scroll action within the selected element to the position provided in arguments. Or, if needed, you can try .scrollBy instead of .scrollTo to get a consistent, repeatable scrolling action.
To finish off, you could also make a helper method out of it and call it whenever you need it:
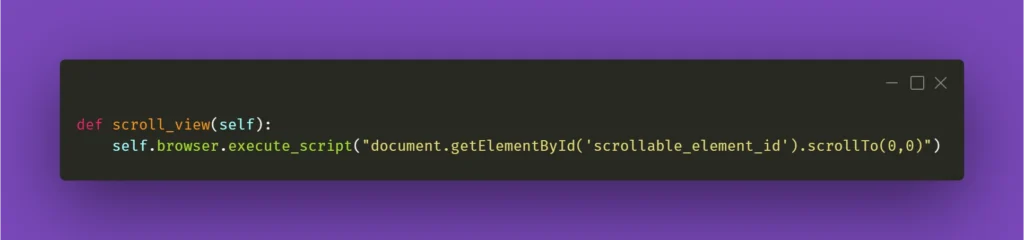
I’ll be mentioning the above method in the following paragraph, so please keep in mind what scroll_view is about.
Still haven’t found what you were looking for
Now that you have moved scrolling problems out of the way, locating elements and interacting with them on massive React pages should not bother you anymore, right? Well, not exactly. If you need to perform some action on an element that exists within a page, it has to be scrolled into view so you can work with it. And Selenium does not automatically do that. Let’s assume that you’re working on a web app that has various sub-pages, or tabs. Each of those tabs contains elements of a different sort but arranged in similar tables with search bars on top of each table at the beginning of the tab. Imagine the following scenario: you navigate to the first tab, scroll the view down, then navigate to the second tab, and you want to use the search bar at the top of the page. Sounds easy, doesn’t it?
What you need to be aware of is the React’s feature which does not always move the view to the top of the page after switching subpages of the app. In this case, to interact with the aforementioned search box you need to scroll the view to the starting position. That’s why scroll_view method in previous paragraph took (0,0) as .scrollTo arguments. You could use it before interacting with an element just to make sure it’s in the view and can be found by Selenium. Here’s an example:
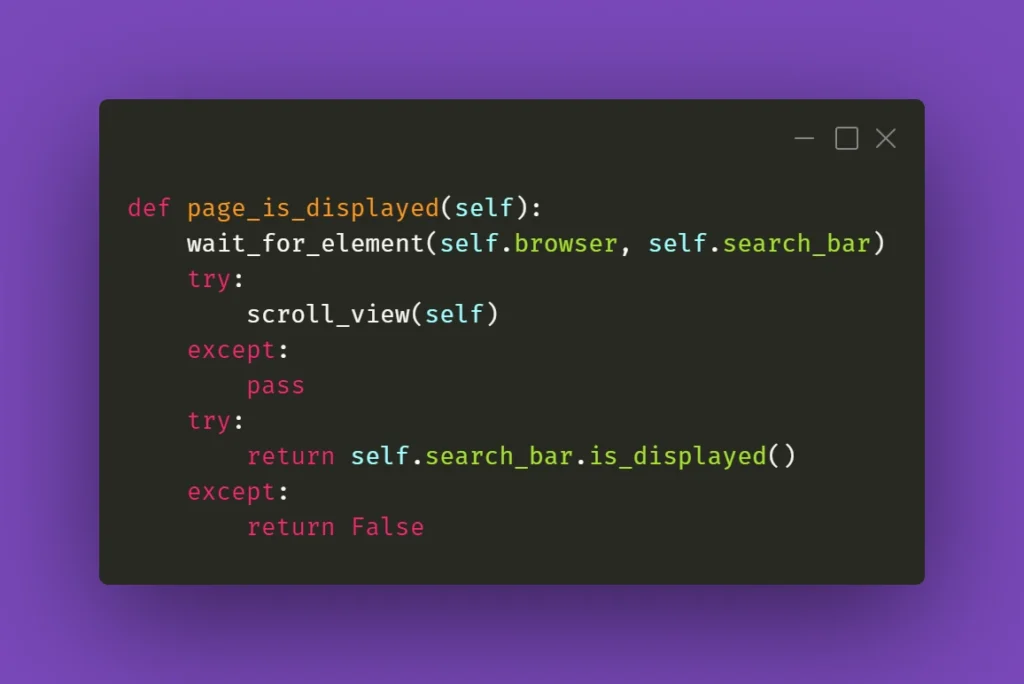
When it doesn’t click
Seems like a basic action like clicking on an element should be bulletproof and never fail. Yet again, miracles happen and if you’re losing your mind trying to find out what’s going on, remember that Selenium doesn’t always work great with React. If you have to deal with some stubborn element, such as a checkbox, for example, you could just simply make the code attempt the action several times:
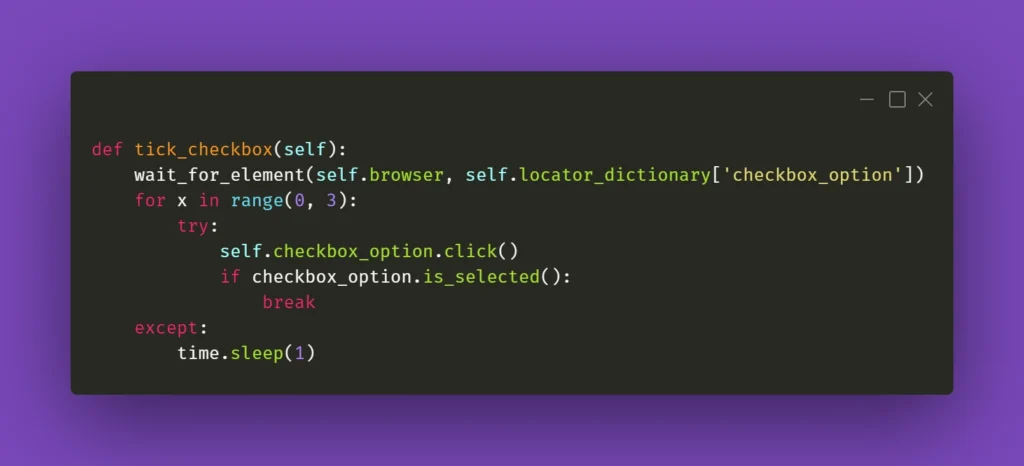
The key here is the if statement; it has to verify whether the requested action had actually taken place. In the above case, a checkbox is selected, and Selenium has a method for verifying that. In other situations, you could just provide a specific selector which applies to a particular element when it changes its state, eg., an Xpath similar to this:
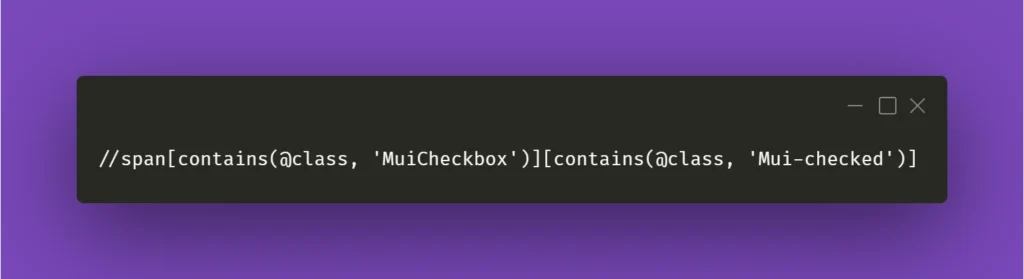
In the above example, Xpath contains generic Material-UI classes, but it could be anything as long as it points out the exact element you needed when it changed its state to whichever you wanted.
Clear situation
Testing often includes dealing with various forms that we need to fill and verify. Fortunately, Selenium’s send_keys() method usually does the job. But when it doesn’t, you could try clicking the text field before inputting the value:
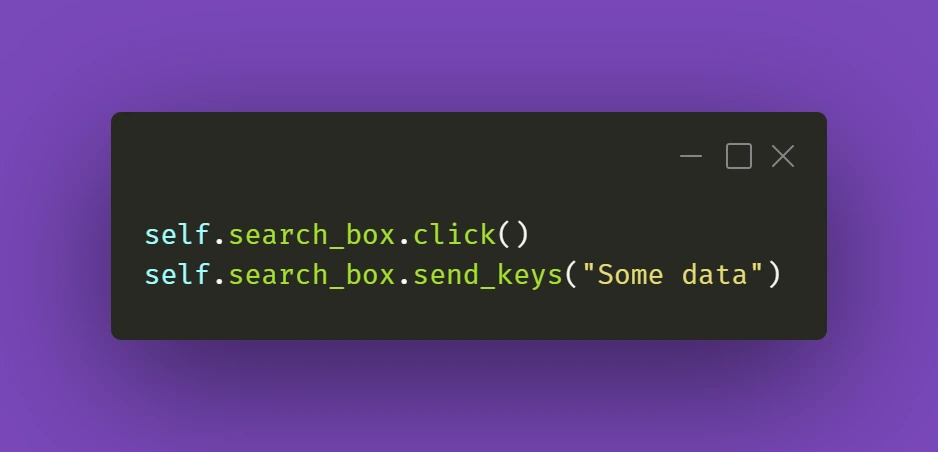
It's a simple thing to do, but we might sometimes have the tendency to forget about such trivial solutions. Anyway, it gets the job done.
The trickier part might actually be getting rid of data in already filled out forms. And Selenium's .clear() method doesn't cooperate as you would expect it to do. If getting the field into focus just like in the above example doesn't work out for you:
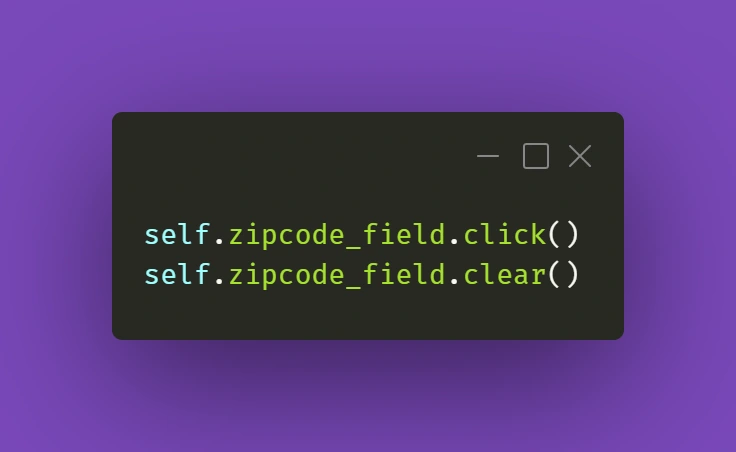
there is a solution that uses some JavaScript (again!). Just make sure your cursor is focused on the field you want to clear and use the following line:
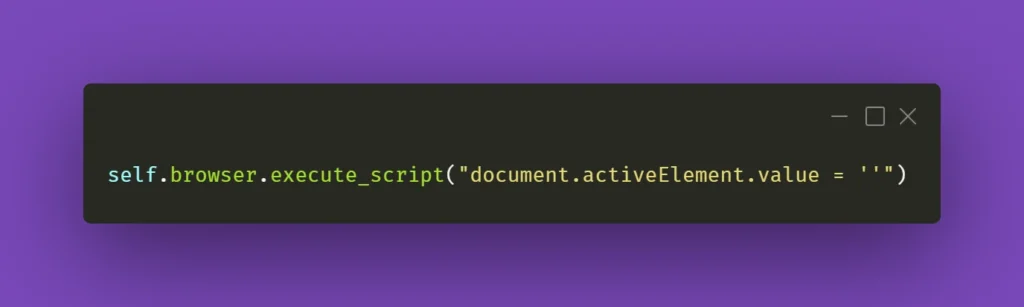
You can also wrap it into a nifty little helper as I did:
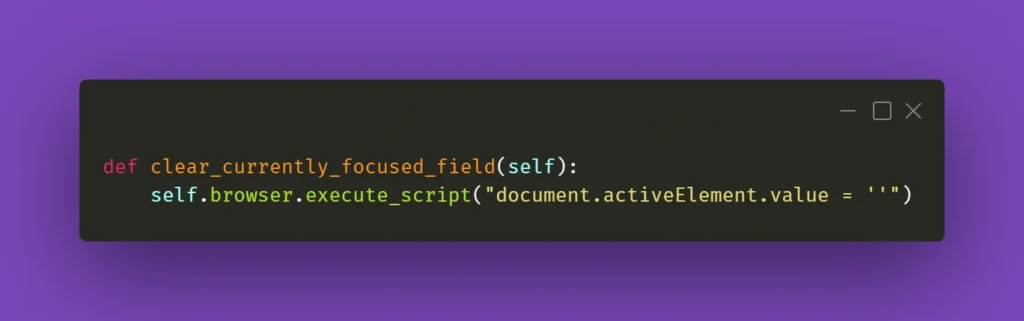
While this should work fine 99% of the time, there might be a situation with a stubborn text field where React quickly restores the previous value. What you can do in such a situation is experiment with sending an empty string to that field right after clearing it or sending some whitespace to it:
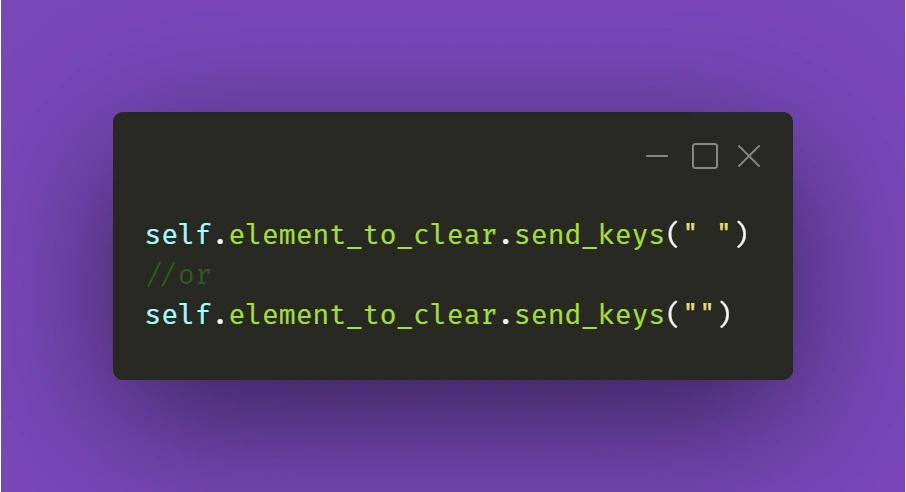
Just make sure it works for you!
Continuing the topic of the text in various fields, which sometimes have to be verified or checked after particular conditions are met, sometimes you need to make sure you're using the right method to extract the text value of an element. They might come in different forms, but the ones below are used quite often. Text in element could be extracted by Selenium with .get_attribute() method:
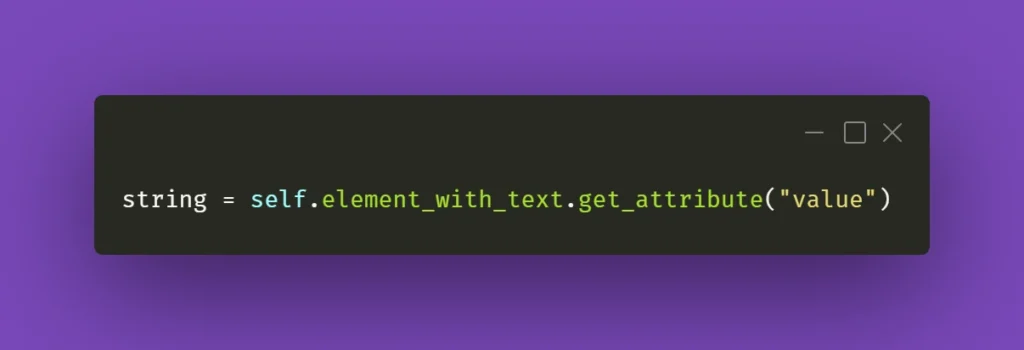
Or sometimes it's just enough to use .text() method:

It all depends on the context and the element you're working with. So don't fall into the trap of assuming that all forms and elements in the app are exactly the same. Always check twice, you'll thank yourself for that, and in the end, you'll save tons of time!
React Apps - Keep on testing!
Hopefully, the tips and tricks I presented above will prove most useful for you in your testing projects. There's definitely more to share within the testing field, so make sure you stay tuned in for other articles on our blog!

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
Testing iOS applications using Appium, Cucumber, and Serenity - a recipe for quality
iOS devices still claim a significant part of the mobile market, taking up to 22 percent of the sales globally. As many devoted clients come back for new Apple products, there is also a great demand for iOS applications. In this article, we are going to look at ensuring the quality of iOS apps striving for the usage of best practices using Appium, Cucumber and Serenity tools.
Structure
The Page Object Model is one of the best approaches to testing that QA engineers can apply to a test automation project. It is such a way of structuring the code in an automation project that improves code quality and readability, test maintenance and on top of that, it is a great way of avoiding chaos. The basic idea behind it comes to keeping all references to mobile elements and methods performing operations on them in one class file for each page or screen of the app (or web page for non-native web applications).
What are the benefits of this approach, you may ask? Firstly, it makes automation really straightforward. Basically, it means finding elements in our iOS app via inspector and then performing operations on them. Another main advantage is the coherent structure of the project that allows anyone to navigate through it quickly.
Let's take an example of an app that contains recipes. It shows the default cookbook with basic recipes on startup, which will be our first page. From there, a user can navigate to any available recipe, thus marking a second page. On top of that, the app also allows to browse other cookbooks or purchase premium ones, making it the third page and consequently - a page object file.
Similarly, we should create corresponding step definition files. This is not an obligatory practice, but keeping all step definitions in one place causes unnecessary chaos.
While creating your pages and step definition class files it is advised to choose names that are related to the page (app screen) which contents you are going to work on. Naming these files after a feature or scenario can seem right at first glance, but as the project expands, you will notice more and more clutter in its structure. Adopting the page naming convention ensures that anyone involved in the project can get familiar with it straight away and start collaboration on it in no time. Such practice also contributes to reusability of code - either step definitions or methods/functions.
Contrary to the mentioned step and step definition files, the Cucumber feature files should be named after a feature they verify. Clever, isn’t it? And again, structuring them into directories named in relation to a particular field of the application under test will make the structure more meaningful.
Serenity’s basic concept is to be a 'living documentation'. Therefore, giving test scenarios and feature files appropriate names helps the team and stakeholders understand reports and the entire project better.
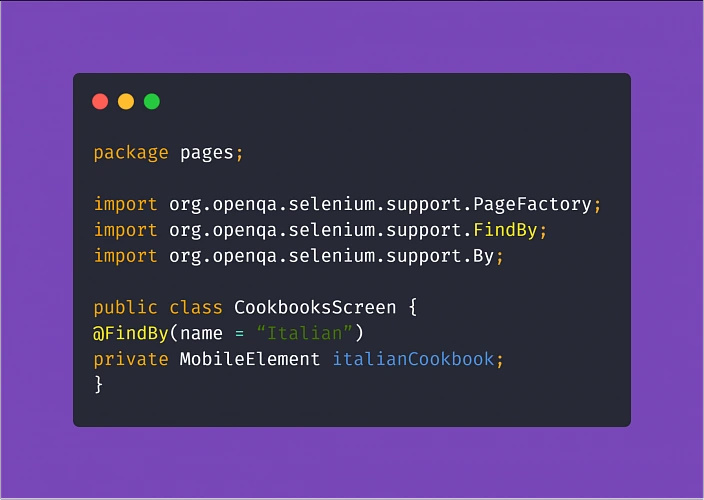
Another ingredient expanding the benefits of the Page Object Model in the test automation project is PageFactory. It is a tool that helps you reduce the coding work and easily put MobileElements locators in code, using @FindBy notation. From there, finding elements for Appium to interact with them in tests is much simpler.
Assertion
Running tests via Appium can be very resource-consuming. To make things easier for your MacOS machine running tests on your iOS device, make sure you are not constantly asserting the visibility of all objects on a page. This practice significantly increases the test execution time, which usually is not the most desirable thing.
What is more, when you do have to check if an element is visible, enabled, clickable, or anything in between - try to avoid locating mobile elements using Xpath. The Appium inspector tip has a valid point! You should do what you can to convince the development team to make an extra effort and assign unique IDs and names to the elements in the app. This will not only make automation testing easier and quicker, consequently making your work as a tester more effective, ultimately resulting in increasing the overall quality of the product. And that is why we are here. Not to mention that the maintenance of the tests (e.g. switching to different locators when necessary) will become much more enjoyable.
Understanding the steps
Another aspect of setting up this kind of project comes down to taking advantage of Cucumber and using Gherkin language.
Gherkin implements a straightforward approach with Given, When, Then notation with the help of the additional And and But which seems fairly easy to use. You could write pretty much anything you want in the test steps of your feature files. Ultimately, the called methods are going to perform actions.
But the reason for using the Behavior Driven Development approach and Cucumber itself is enabling the non-tech people involved in the project to understand what is going on in the tests field. Not only that, writing test scenarios in Given/When/Then manner can also act in your advantage. Such high-level test descriptions delivered by the client or business analyst will get you coding in no time, provided that they are written properly. Here are some helpful tips:
Test scenarios written in Gherkin should focus on the behavior of the app (hence Behavior Driven Development).
Here's an example of how NOT to write test scenarios in Gherkin, further exploring the theme of cookbook application:
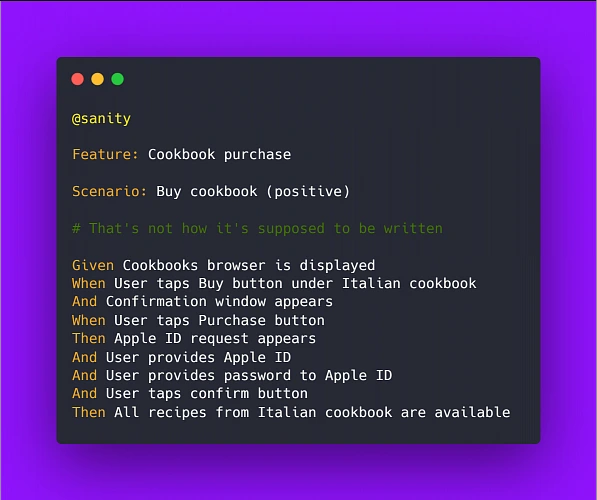
Above example illustrates two bad practices we should avoid: It focuses on the implementation instead of behavior and it uses hard-coded values rather than writing test steps in such a way to enable reusability by changing values within a step.
Therefore, a proper scenario concerning purchasing a cookbook in our example app should look like:
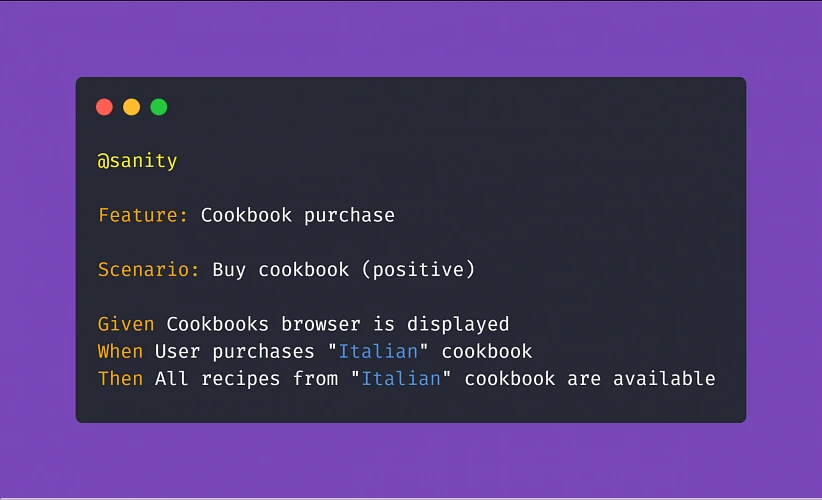
Another example:
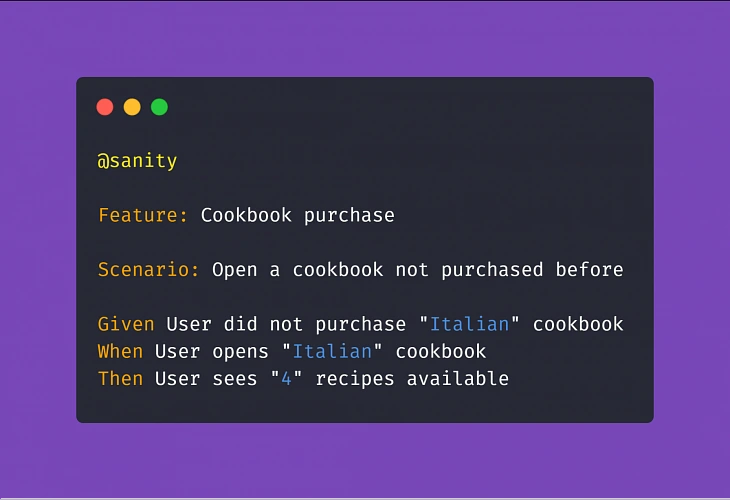
Adopting this approach means less work creating and coding the test steps whenever the implementation of a particular feature changes.
Apart from the main notation of Given/When/Then , Cucumber supports usage of conjunction steps. Using And and But step notations will make the test steps more general and reusable, which results in writing less code and maintaining order within the project. Here is a basic example:
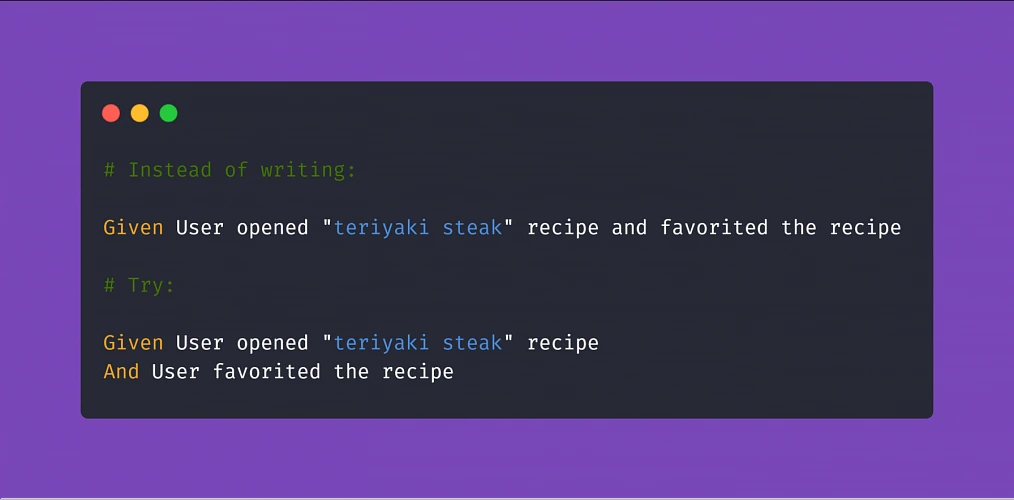
Doing so, if you code the above 'Given' step to locate our recipe element by searching its name, you can reuse it many times just changing the string value in the step (provided that you code the step definition properly later on). On top of that, The 'And' step can be a part of any test scenario that involves such action.
Putting it all together
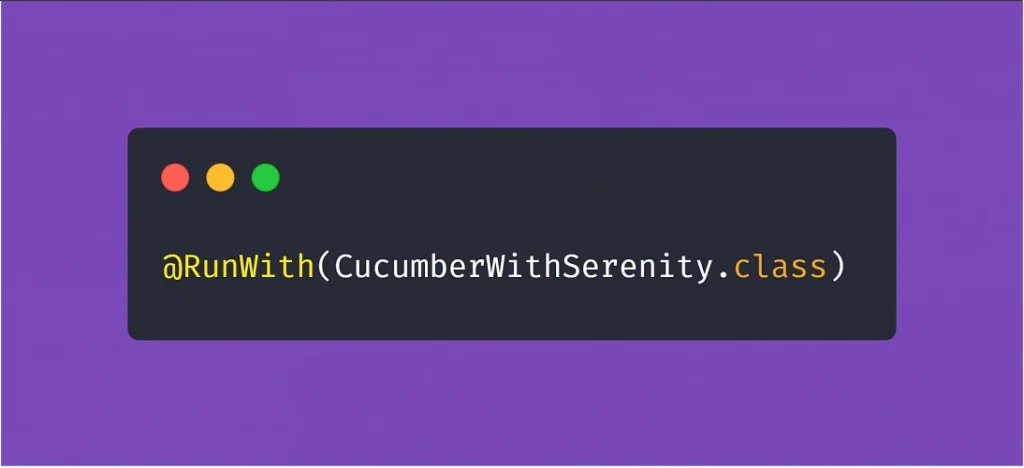
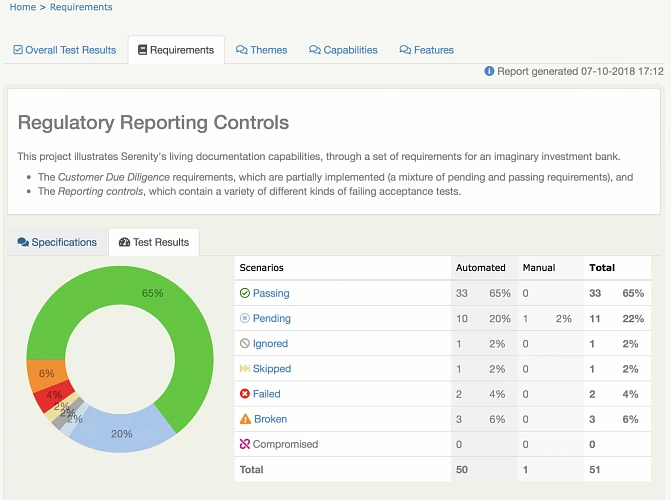
After setting up a project utilizing the practices described above, the most visible parts of using Serenity are the generated test reports. After adopting the @RunWith(CucumberWithSerenity.class) tag in your TestRunner class file, running the test suite will result in Serenity generating an aggregated test results report, which can be useful in evaluating the quality of the app under test and presenting the status of the product to the stakeholders or the development team.
Appium, Cucumber, Serenity - summary
As you can see, the concept of best practices in automation testing can be summarized in three words: reusability, readability, and performance. Reusability means fewer coding, consequently diminishing the time needed to finish the job. Readability improves understanding, which is crucial to ensure that the product does what it needs to do. Finally, performance saves execution time and improves stability. All three contributing not only to the quality of the test automation project but have a significant role in enhancing the overall quality of the delivered app.
Sources:
Benefits of using Immutable.js with React & Redux apps
Have you ever struggled with complex and unreadable redux reducers? If yes, this article will show you how Immutable.js can help you keep reducers easy and clean. It fits perfectly with the redux & react application, so you might try to use it in your app.
Immutable.js is a library that supports an immutable data structure. It means that once created data cannot be changed. It makes maintaining immutable data structures easier and more efficient. The tool supports data structure like: List, Map, Set and also structures that are not implemented in .js by default but can be very useful: OrderedMap, OrderedSet and Record.
Methods such as push, unshift, slice in .js are based on reference and mutate the object directly. In the case of Immutable.js, there are no methods that change the object directly, a new object is always returned.
How using Immutable.js is supposed to help in Redux applications?
Before using Immutable.js, the biggest issue with the Redux library often comes to returning a new object, which is nested in another object. In this case, using the Object.assign and spread operator syntax is not readable and may increase app complexity.
Some may suggest keeping your reducer's state as flat as possible. That could be right, but sometimes, even if your state is flat, you would have to set something in a nested object. So, if you also struggle because of that, the immutable library comes to make your life easier.
How does it look in practice?
Let’s start by showing some examples of how the code looks like with and without using our solution in a reducer. In most of the cases in reducers, you will use method .set , which takes two arguments; the first one is a key which you would like to change and the second one is a new value. For setting nested properties, you can use method .setIn , which instead of a key as the first argument takes a key path as an array. Worth noting here is that if the key does not exist, a new one will be created. Thanks to this, you don't have to make conditions to handle it.
Here is a very simple reducer:
export const initialState ={
loaded: false,
disabled: false
};
export default function bookReducer(state = initialState, { type, payload }) {
switch (type) {
case ActionTypes.setLoadedState:
return {
...state,
loaded: payload
}
}
return state;
}
This is the simplest reducer you can imagine, let's see what it looks like with immutable.js:
export const initialState = from.js({
loaded: false,
disabled: false
});
export default function bookReducer(state = initialState, { type, payload }) {
switch (type) {
case ActionTypes.setLoadedState:
return state.set('loaded', payload)
}
return state;
}
Here, there is no big difference because the reducer is very simple, but we already can see a small improvement, code becomes more readable.
The second example without our solution:
export const initialState = {
students: {},
selectedStudent: null
};
export default function studentReducer(state = initialState, { type, payload }) {
switch (type) {
case ActionTypes.setStudentStatus:
return {
...state,
students: {
...state.students,
[payload.studentId]: {
...state.students[payload.studentId],
status: payload.status
}
}
}
}
return state;
}
With Immutable.js:
export const initialState = {
students: {},
selectedStudent: null
};
export default function studentReducer(state = initialState, { type, payload }) {
switch (type) {
case ActionTypes.setStudentStatus:
return state.setIn(['students', payload.studentId, 'status'], payload.status)
}
return state;
}
In the example above, we can see a huge difference between using and not using the tool:
- The code is much shorter (10 lines to just 1 line).
- With the Immutable.js you can easily see at first glance what data in reducer has changed.
- Without the Immutable.js, it’s not that literal and obvious what’s changed.
In these examples, we provide only 2 methods of using Immutable.js - .set and .setIn , but there are numerous use cases, not only to set values. Actually, Immutable objects have the same methods which native .js has and a lot more which can speed up your development.
We also recommend checking the .update and .updateIn methods in the documentation, because, in reducers, they can be invaluable in more complex cases.
Other benefits of using Immutable.js
The main benefits of this library are easy and simple to maintain reducers. Besides this, we also get other advantages:
- The library provides data structures that are not natively implemented in .js, but it makes your life easier (e.g., Ordered Map, Record).
- The tool offers numerous ways to simplify your work, for example sortBy, groupBy, reverse, max, maxBy, flatten and many more. You can even stop using the lodash library, as most of the methods from lodash have their equivalents in immutable.js. It is easier to use as we can use chaining by default.
- Immutable.js does a lot of things under the hood, which improves performance. Immutable data structures usually consume a lot of RAM, because this approach requires creating new copies of objects constantly. Among other things, our solution optimizes this, by sharing the state cleverly.
- Empty collections are always equal, even if they were created separately. Look at the example below:

Compared to native .js:

There is always the other side of the coin, what are the cons?
Expensive converting to regular JavaScript
To convert Immutable collection to regular .js, you have to use .to.js() on an Immutable Collection. This method is very expensive when it comes to performance and always returns a new reference of an object even if nothing has been changed in the object. It affects PureComponent and React.memo, because these components would detect something has been changed, but actually, nothing has changed.
In most of the cases, you should avoid using to.js() and pass to components Immutable collections. However, sometimes you will have to use to.js, e.g. if you use an external library that requires props.
If you are developing generic components that will be used in other projects, you should avoid using an Immutable Collection in them, because it would force you to use Immutable in all projects that use these components.
There is no destructing operator
If you like getting properties using a destructing operator like this:
const { age, status } = student;
You won’t be happy, because, in Immutable.js, it is impossible to do. The get property from an immutable collection you have to use method .get or getIn, but I think it should not be a bit deal.
Debugging
Immutable collections are difficult to read in the browser console. Fortunately, you can easily solve this problem by using the tool. Object Formatter browser plugin, but it is not available in all browsers.

The above comparison shows what it looks like without and with the plugin. As you can see, the log is completely unreadable without the plugin.
Conclusion
Accordingly to our experiences, the immutable.js library is worth trying out in React applications with Redux applications. Thanks to immutable.js, your application will be more efficient, easier to develop, maintain and more resistant to errors . Because, as you’ve seen above in a comparison of reducers. It's definitely easier to make a mistake without using Immutable.js. In the long term project, you should definitely consider it.
How to run Selenium BDD tests in parallel with AWS Lambda
Have you ever felt annoyed because of the long waiting time for receiving test results? Maybe after a few hours, you’ve figured out that there had been a network connection issue in the middle of testing, and half of the results can go to the trash? That may happen when your tests are dependent on each other or when you have plenty of them and execution lasts forever. It's quite a common issue. But there’s actually a solution that can not only save your time but also your money - parallelization in the Cloud.
How it started
Developing UI tests for a few months, starting from scratch, and maintaining existing tests, I found out that it has become something huge that will be difficult to take care of very soon. An increasing number of test scenarios made every day led to bottlenecks. One day when I got to the office, it turned out that the nightly tests were not over yet. Since then, I have tried to find a way to avoid such situations.
A breakthrough was the presentation of Tomasz Konieczny during the Testwarez conference in 2019. He proved that it’s possible to run Selenium tests in parallel using AWS Lambda. There’s actually one blog that helped me with basic Selenium and Headless Chrome configuration on AWS. The Headless Chrome is a light-weighted browser that has no user interface. I went a step forward and created a solution that allows designing tests in the Behavior-Driven Development process and using the Page Object Model pattern approach, run them in parallel, and finally - build a summary report.
Setting up the project
The first thing we need to do is signing up for Amazon Web Services. Once we have an account and set proper values in credentials and config files (.aws directory), we can create a new project in PyCharm, Visual Studio Code, or in any other IDE supporting Python. We’ll need at least four directories here. We called them ‘lambda’, ‘selenium_layer’, ‘test_list’, ‘tests’ and there’s also one additional - ‘driver’, where we keep a chromedriver file, which is used when running tests locally in a sequential way.
In the beginning, we’re going to install the required libraries. Those versions work fine on AWS, but you can check newer if you want.
requirements.txt
allure_behave==2.8.6
behave==1.2.6
boto3==1.10.23
botocore==1.13.23
selenium==2.37.0
What’s important, we should install them in the proper directory - ‘site-packages’.
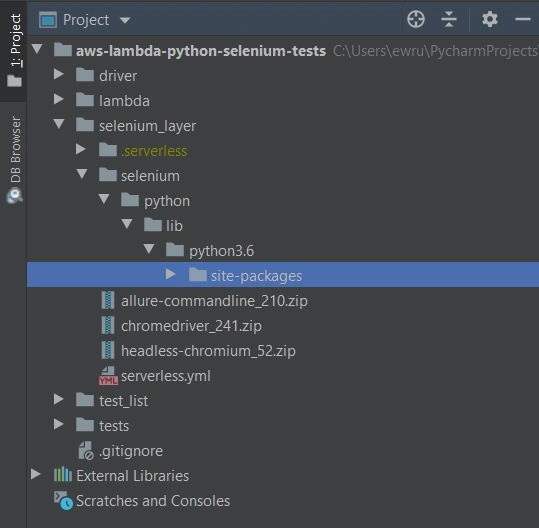
We’ll need also some additional packages:
Allure Commandline ( download )
Chromedriver ( download )
Headless Chromium ( download )
All those things will be deployed to AWS using Serverless Framework, which you need to install following the docs . The Serverless Framework was designed to provision the AWS Lambda Functions, Events, and infrastructure Resources safely and quickly. It translates all syntax in serverless.yml to a single AWS CloudFormation template which is used for deployments.
Architecture - Lambda Layers
Now we can create a serverless.yml file in the ‘selenium-layer’ directory and define Lambda Layers we want to create. Make sure that your .zip files have the same names as in this file. Here we can also set the AWS region in which we want to create our Lambda functions and layers.
serverless.yml
service: lambda-selenium-layer
provider:
name: aws
runtime: python3.6
region: eu-central-1
timeout: 30
layers:
selenium:
path: selenium
CompatibleRuntimes: [
"python3.6"
]
chromedriver:
package:
artifact: chromedriver_241.zip
chrome:
package:
artifact: headless-chromium_52.zip
allure:
package:
artifact: allure-commandline_210.zip
resources:
Outputs:
SeleniumLayerExport:
Value:
Ref: SeleniumLambdaLayer
Export:
Name: SeleniumLambdaLayer
ChromedriverLayerExport:
Value:
Ref: ChromedriverLambdaLayer
Export:
Name: ChromedriverLambdaLayer
ChromeLayerExport:
Value:
Ref: ChromeLambdaLayer
Export:
Name: ChromeLambdaLayer
AllureLayerExport:
Value:
Ref: AllureLambdaLayer
Export:
Name: AllureLambdaLayer
Within this file, we’re going to deploy a service consisting of four layers. Each of them plays an important role in the whole testing process.
Creating test set
What would the tests be without the scenarios? Our main assumption is to create test files running independently. This means we can run any test without others and it works. If you're following clean code, you'll probably like using the Gherkin syntax and the POM approach. Behave Framework supports both.
What gives us Gherkin? For sure, better readability and understanding. Even if you haven't had the opportunity to write tests before, you will understand the purpose of this scenario.
01.OpenLoginPage.feature
@smoke
@login
Feature: Login to service
Scenario: Login
Given Home page is opened
And User opens Login page
When User enters credentials
And User clicks Login button
Then User account page is opened
Scenario: Logout
When User clicks Logout button
Then Home page is opened
And User is not authenticated
In the beginning, we have two tags. We add them in order to run only chosen tests in different situations. For example, you can name a tag @smoke and run it as a smoke test, so that you can test very fundamental app functions. You may want to test only a part of the system like end-to-end order placing in the online store - just add the same tag for several tests.
Then we have the feature name and two scenarios. Those are quite obvious, but sometimes it’s good to name them with more details. Following steps starting with Given, When, Then and And can be reused many times. That’s the Behavior-Driven Development in practice. We’ll come back to this topic later.
Meantime, let’s check the proper configuration of the Behave project.
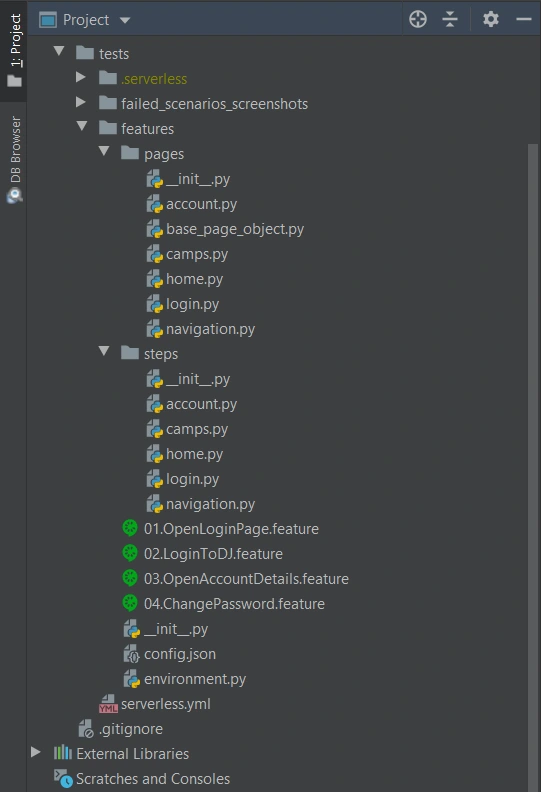
We definitely need a ‘feature’ directory with ‘pages’ and ‘steps’. Make the ‘feature’ folder as Sources Root. Just right-click on it and select the proper option. This is the place for our test scenario files with .feature extension.
It’s good to have some constant values in a separate file so that it will change only here when needed. Let’s call it config.json and put the URL of the tested web application.
config.json
{
"url": "http://drabinajakuba.atthost24.pl/"
}
One more thing we need is a file where we set webdriver options.
Those are required imports and some global values like, e.g. a name of AWS S3 bucket in which we want to have screenshots or local directory to store them in. As far as we know, bucket names should be unique in whole AWS S3, so you should probably change them but keep the meaning.
environment.py
import os
import platform
from datetime import date, datetime
import json
import boto3
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
REPORTS_BUCKET = 'aws-selenium-test-reports'
SCREENSHOTS_FOLDER = 'failed_scenarios_screenshots/'
CURRENT_DATE = str(date.today())
DATETIME_FORMAT = '%H_%M_%S'
Then we have a function for getting given value from our config.json file. The path of this file depends on the system platform - Windows or Darwin (Mac) would be local, Linux in this case is in AWS. If you need to run these tests locally on Linux, you should probably add some environment variables and check them here.
def get_from_config(what):
if 'Linux' in platform.system():
with open('/opt/config.json') as json_file:
data = json.load(json_file)
return data[what]
elif 'Darwin' in platform.system():
with open(os.getcwd() + '/features/config.json') as json_file:
data = json.load(json_file)
return data[what]
else:
with open(os.getcwd() + '\\features\\config.json') as json_file:
data = json.load(json_file)
return data[what]
Now we can finally specify paths to chromedriver and set browser options which also depend on the system platform. There’re a few more options required on AWS.
def set_linux_driver(context):
"""
Run on AWS
"""
print("Running on AWS (Linux)")
options = Options()
options.binary_location = '/opt/headless-chromium'
options.add_argument('--allow-running-insecure-content')
options.add_argument('--ignore-certificate-errors')
options.add_argument('--disable-gpu')
options.add_argument('--headless')
options.add_argument('--window-size=1280,1000')
options.add_argument('--single-process')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
capabilities = webdriver.DesiredCapabilities().CHROME
capabilities['acceptSslCerts'] = True
capabilities['acceptInsecureCerts'] = True
context.browser = webdriver.Chrome(
'/opt/chromedriver', chrome_options=options, desired_capabilities=capabilities
)
def set_windows_driver(context):
"""
Run locally on Windows
"""
print('Running on Windows')
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--window-size=1280,1000')
options.add_argument('--headless')
context.browser = webdriver.Chrome(
os.path.dirname(os.getcwd()) + '\\driver\\chromedriver.exe', chrome_options=options
)
def set_mac_driver(context):
"""
Run locally on Mac
"""
print("Running on Mac")
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--window-size=1280,1000')
options.add_argument('--headless')
context.browser = webdriver.Chrome(
os.path.dirname(os.getcwd()) + '/driver/chromedriver', chrome_options=options
)
def set_driver(context):
if 'Linux' in platform.system():
set_linux_driver(context)
elif 'Darwin' in platform.system():
set_mac_driver(context)
else:
set_windows_driver(context)
Webdriver needs to be set before all tests, and in the end, our browser should be closed.
def before_all(context):
set_driver(context)
def after_all(context):
context.browser.quit()
Last but not least, taking screenshots of test failure. Local storage differs from the AWS bucket, so this needs to be set correctly.
def after_scenario(context, scenario):
if scenario.status == 'failed':
print('Scenario failed!')
current_time = datetime.now().strftime(DATETIME_FORMAT)
file_name = f'{scenario.name.replace(" ", "_")}-{current_time}.png'
if 'Linux' in platform.system():
context.browser.save_screenshot(f'/tmp/{file_name}')
boto3.resource('s3').Bucket(REPORTS_BUCKET).upload_file(
f'/tmp/{file_name}', f'{SCREENSHOTS_FOLDER}{CURRENT_DATE}/{file_name}'
)
else:
if not os.path.exists(SCREENSHOTS_FOLDER):
os.makedirs(SCREENSHOTS_FOLDER)
context.browser.save_screenshot(f'{SCREENSHOTS_FOLDER}/{file_name}')
Once we have almost everything set, let’s dive into single test creation. Page Object Model pattern is about what exactly hides behind Gherkin’s steps. In this approach, we treat each application view as a separate page and define its elements we want to test. First, we need a base page implementation. Those methods will be inherited by all specific pages. You should put this file in the ‘pages’ directory.
base_page_object.py
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import *
import traceback
import time
from environment import get_from_config
class BasePage(object):
def __init__(self, browser, base_url=get_from_config('url')):
self.base_url = base_url
self.browser = browser
self.timeout = 10
def find_element(self, *loc):
try:
WebDriverWait(self.browser, self.timeout).until(EC.presence_of_element_located(loc))
except Exception as e:
print("Element not found", e)
return self.browser.find_element(*loc)
def find_elements(self, *loc):
try:
WebDriverWait(self.browser, self.timeout).until(EC.presence_of_element_located(loc))
except Exception as e:
print("Element not found", e)
return self.browser.find_elements(*loc)
def visit(self, url):
self.browser.get(url)
def hover(self, element):
ActionChains(self.browser).move_to_element(element).perform()
time.sleep(5)
def __getattr__(self, what):
try:
if what in self.locator_dictionary.keys():
try:
WebDriverWait(self.browser, self.timeout).until(
EC.presence_of_element_located(self.locator_dictionary[what])
)
except(TimeoutException, StaleElementReferenceException):
traceback.print_exc()
return self.find_element(*self.locator_dictionary[what])
except AttributeError:
super(BasePage, self).__getattribute__("method_missing")(what)
def method_missing(self, what):
print("No %s here!", what)
That’s a simple login page class. There’re some web elements defined in locator_dictionary and methods using those elements to e.g., enter text in the input, click a button, or read current values. Put this file in the ‘pages’ directory.
login.py
from selenium.webdriver.common.by import By
from .base_page_object import *
class LoginPage(BasePage):
def __init__(self, context):
BasePage.__init__(
self,
context.browser,
base_url=get_from_config('url'))
locator_dictionary = {
'username_input': (By.XPATH, '//input[@name="username"]'),
'password_input': (By.XPATH, '//input[@name="password"]'),
'login_button': (By.ID, 'login_btn'),
}
def enter_username(self, username):
self.username_input.send_keys(username)
def enter_password(self, password):
self.password_input.send_keys(password)
def click_login_button(self):
self.login_button.click()
What we need now is a glue that will connect page methods with Gherkin steps. In each step, we use a particular page that handles the functionality we want to simulate. Put this file in the ‘steps’ directory.
login.py
from behave import step
from environment import get_from_config
from pages import LoginPage, HomePage, NavigationPage
@step('User enters credentials')
def step_impl(context):
page = LoginPage(context)
page.enter_username('test_user')
page.enter_password('test_password')
@step('User clicks Login button')
def step_impl(context):
page = LoginPage(context)
page.click_login_button()
It seems that we have all we need to run tests locally. Of course, not every step implementation was shown above, but it should be easy to add missing ones.
If you want to read more about BDD and POM, take a look at Adrian’s article
All files in the ‘features’ directory will also be on a separate Lambda Layer. You can create a serverless.yml file with the content presented below.
serverless.yml
service: lambda-tests-layer
provider:
name: aws
runtime: python3.6
region: eu-central-1
timeout: 30
layers:
features:
path: features
CompatibleRuntimes: [
"python3.6"
]
resources:
Outputs:
FeaturesLayerExport:
Value:
Ref: FeaturesLambdaLayer
Export:
Name: FeaturesLambdaLayer
This is the first part of the series covering running Parallel Selenium tests on AWS Lambda. More here !
Interested in our services?
Reach out for tailored solutions and expert guidance.