Machine Learning at the edge – federated learning in the automotive industry


Machine Learning combined with edge computing gains a lot of interest in industries leveraging AI at scale - healthcare, automotive, or insurance. The proliferation of use cases such as autonomous driving or augmented reality, requiring low latency, real-time response to operating correctly, made distributed data processing a tempting solution. Computation offloading to edge IoT devices makes the distributed cloud systems smaller - and in this case, smaller is cheaper. That’s the first most obvious benefit of moving machine learning from the cloud to edge devices.
Why is this article worth reading? See what we provide here:
- Explaining why regular ML training flow might not be enough.
- Presenting the idea behind federated learning.
- Describing the advantages and risks associated with this technology.
- Introducing technical architecture of a similar solution.
How can federated learning be used in the automotive industry?
Using the automotive industry as an example, modern cars already contain the edge device with processors capable of making complex computations. All ADAS (Advanced Driver Assistance Systems) and autonomous driving calculations happen on-board and require rather significant compute power. Detecting obstacles, road lanes, other vehicles, or road signs happens right now using onboard vehicle systems. That’s why collaboration with companies like Nvidia becomes crucial for OEMs, as the need for better onboard SoCs does not stop.
Even though the prediction happens in the vehicle, the model is trained and prepared using regular, complex, and costly training systems built on-premises or in the cloud. The training data grows bigger and bigger making the training process computationally expensive, slower, and requiring significant storage, especially if incremental learning is not used. The updated model may take time to be passed to the vehicle, and storing the user driving patterns, or even images from the onboard camera, requires both user consent and adherence to local law regulations.
The possible solution for that problem is using a local dataset from each vehicle as small, distributed training sets and training the model in the form of “federated learning”, where the local model is trained using smaller data batches and then aggregated into a singular global model. This is both more computational and memory efficient.
What are the benefits of federated learning?
One of the important concepts highly associated with machine learning at edge is building Federated Learning on top of edge ML. The combination of federated learning and edge computing gives important, measurable advantages:
- Reduced training time - edge devices calculate simultaneously which improves velocity compared to a monolithic system.
- Reduced inference time - compared to the cloud, at the edge inference results are calculated immediately.
- Collaborative learning - instead of single, huge training dataset learning happens simultaneously using smaller datasets - which makes it both easier and more accurate enabling bigger training sets.
- Always up-to-date model in vehicle - the new model is propagated to the vehicle after validation which makes the learning process of the network automatic.
- Exceptional privacy - the omnipresent problem of secure channels for passing sensitive user data, anonymization, and storing personal user data for training purposes is now gone. The learning happens on local data in the edge device, and the data never leaves the vehicle. The weights which are being shared cannot be used to identify the user or even his driving patterns.
- Lack of single point of failure - the data loss of the training set is not a threat.
Benefits from these concepts contain both cost savings and accuracy improved, visible as an overall better user experience when using the vehicle systems. As autonomous driving and ADAS systems are critical, better model accuracy is also directly associated with better security. For example, if the system can identify pedestrians on the road in front of vehicles with accuracy higher by 10%, it can mean that an additional 10% of collisions with pedestrians can be avoided. That is a measurable and important difference.
Of course, the solution does not come only with benefits. There are certain risks that have to be taken into account when deciding to transition to federated learning. The main one is that compared to the regular training mechanisms, federated learning is based on heterogeneous training data - disconnected datasets stored on edge devices. This means the global model accuracy is hard to control, as the global model is derived based on local models and changes dynamically.
This can be solved by building a hybrid solution, where part of the model is built using safe, predefined data, and it is gradually enhanced by federated learning. This brings both worlds closer together - amounts of data impossible to handle by a singular training system and stable model based on a verified training set.
Architectural overview
To build this kind of system, we need to start with the overall architecture. Key assumptions are that the infrastructure is capable of running distributed, microservices-based systems and has queueing and load balancing capabilities. Edge devices have some kind of storage, sensors, and SoC with CPU, and GPU capable of training the ML model .
Let’s split it into multiple subsystems and consider them one by one:
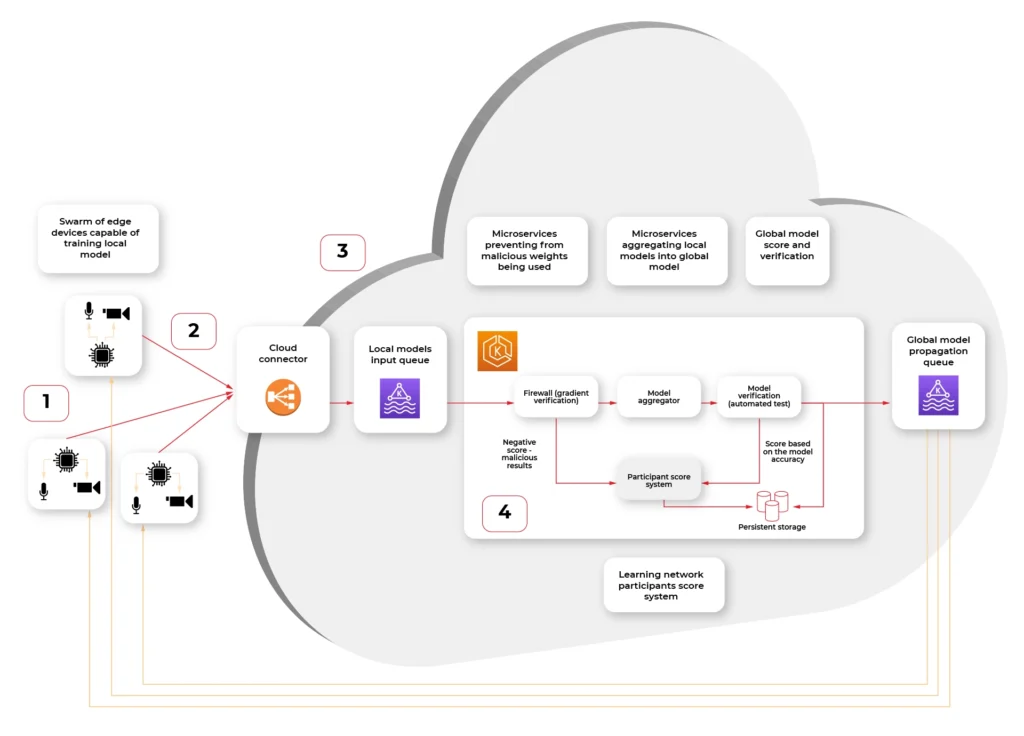
- Swarm of connected vehicle edge devices, each one with connected sensors and ability to recalculate model gradient (weights.)
- Connection medium, in this case fast, 5G network available in the car
- Cloud connector, being a secure, globally available public API where each of the vehicle IoT edge devices connect to.
- Kubernetes cluster with federated learning system split into multiple scalable microservices:
a) Gradient verification / Firewall - system rejecting the gradient that looks counterfeit - either manipulated by 3rd party or being based on fictional data.
b) Model aggregator - system merging the new weights into the existing model and creating an updated model.
c) Result verification automated test system - system verifying the new model on a predefined dataset with known predictions to score the model compared to the original.
d) Propagating queue connected to (S)OTA - automatic or triggered by user propagation of updated model in the form of an over-the-air update to the vehicle.
A firewall?
The firewall here, inside the system, is not a mistake. It is not guarding the network against attacks. It is guarding the model against being altered by cyber attacks.
Security is a very important aspect of AI, especially when the model can be altered by unverified data from the outside. There are multiple known attack vectors:
- Byzantine attack - regarding the situation, when some of the edge devices are compromised and uploading wrong weights. In our case, it is unlikely for the attacker to be omniscient (to know the data of all participants), so the uploaded weights are either randomized but plausible, like generated Gaussian noise, or flip-bit of result calculation. The goal is to make the model unpredictable.
- Model Poisoning - this attack is similar to the byzantine attack, but the goal is to inject the malicious model, which as a result alters the global model to misclassify objects. The dangerous example of such an attack is by injecting multiple fake vehicles into a model, which incorrectly identifies the trees as “stop” road signs. As a result, an autonomous car would not be able to operate correctly and stop near all trees as it would be a cross-section.
- Data Poisoning - this attack is the hardest to avoid and easiest to execute, as it does not require a vehicle to be compromised. The sensor, for example, camera, is fed with a fake picture, which contains minor, but present changes - for example, a set of bright green pixels, like on the picture:

This can be a printed picture or even a sticker on a regular road sign. If the network learns to treat those four pixels as a “stop” sign. This can be painted, for example, on another vehicle and cause havoc on the road when an autonomous car encounters this pattern.
As we can see, those attacks are specific to distributed learning systems or machine learning in general. Taking this into account is critical, as the malicious model may be impossible to identify by looking at the weights or even prediction results if the way of attack was not determined.
There are multiple countermeasures that can be used to mitigate those attacks. Median or distance to the global model can be calculated and quickly identify rogue data. The other defense is to check the score of the global model after merging and revert the change if the score is significantly worse.
In both cases, the notification about the situation should be notified, both to operators as a metric and to a service that gives scores to the vehicle edge devices. If the device gets repeatedly flagged as wrong-doing, it should be kicked out of the network, and investigation is required to figure out if this is a cyberattack and who is the attacker.
Model aggregation and test
As we know, taking care of the cybersecurity threats specific to our use case, now the important step is merging the new weights with the global model.
There is no one best function or algorithm that can be used to aggregate the local models into global models by merging the individual results (weights). In general, very often average, or weighted average gives sufficient results to start with.
The Aggregation step is not final. The versioned model is then tested in the next step using the predefined data with automated verification. This is a crucial part of the system, preventing the most obvious faults - like the lane assist system stopping to recognize roadside lines.
If the model passes the test with a score at least as good as the current model (or predefined value), it’s being saved.
Over-the-air propagation
The last step of the pipeline is enqueueing the updated model to be propagated back to vehicles. This can be either an automatic process as in continuous deployment directly to the car or may require a manual trigger if the system requires additional manual tests on the road.
A safe way of distributing the update is using the container image. The same image may be used for tests and then run in vehicles greatly reducing the chance of deploying failing updates. With this process, rollback is also simple as long as the device is able to store the previous version of the model.
The results
Moving from legacy, monolithic training method to federated learning gives promising results in both reduced overall system cost and improved accuracy. With quick expansion of 5G low-latency network and IoT edge devices into vehicles, this kind of system can move from theoretical discussions, scientific labs, and proofs of concepts to fully capable and robust production systems. The key part of building such a system is to consider the cybersecurity threats and crucial metrics like global model accuracy from the start.

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
8 examples of how AI drives the automotive industry
Just a few years ago, artificial intelligence stirred our imagination via the voice of Arnold Schwarzenegger from "Terminator" or agent Smith from "The Matrix". It wasn't long before the rebellious robots' film dialogue replaced the actual chats we have with Siri or Alexa over our morning cup of coffee. Nowadays, artificial intelligence is more and more boldly entering new areas of our lives. The automotive industry is one of those that are predicted to speed up in the coming years. By 2030, 95-98% of new vehicles are likely to use this technology.
What will you learn from this article?
- How to use AI in the production process
- How AI helps drivers to drive safely and comfortably
- How to use AI in vehicle servicing
- What companies from the AI industry should pay attention to if they want to introduce such innovations
- You will learn about interesting use cases of the major brands
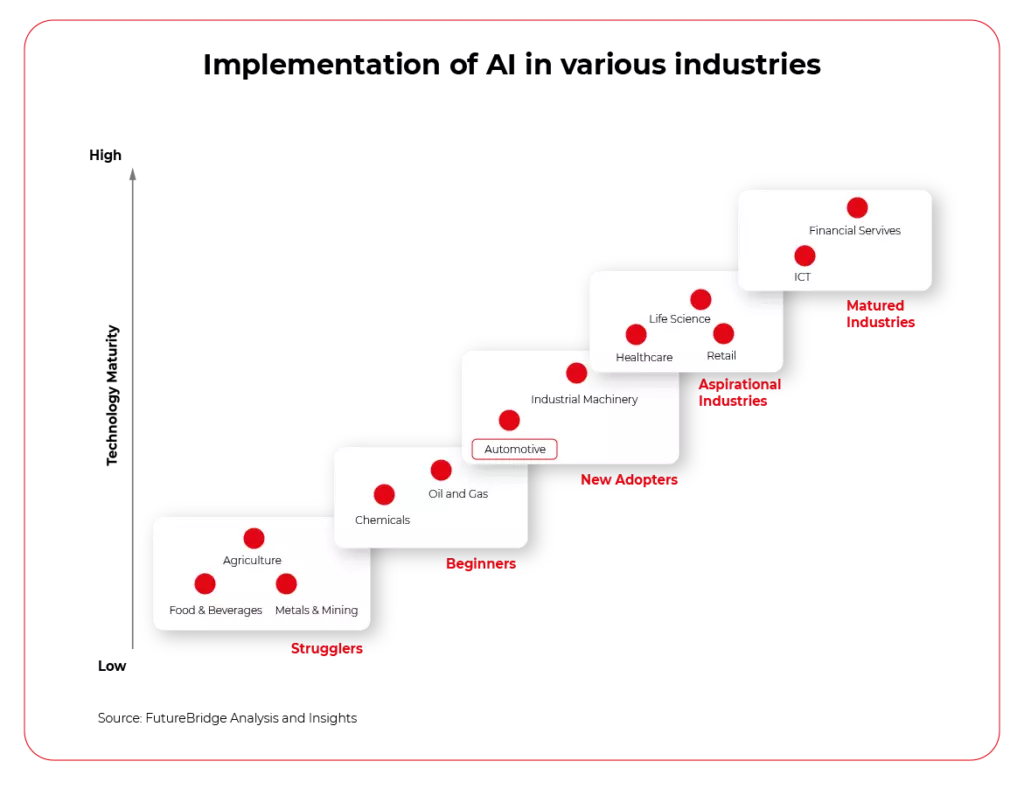
Looking at the application of AI in various industries, we can name five stages of implementation of such solutions. Today, companies from the Communication Technology (ICT) and Financial Services ("Matured Industries") sectors are taking the lead. Healthcare, Retail, Life Science ("Aspirational Industries") are following closely behind. Food & Beverages and Agriculture ("Strugglers") and companies from the Chemicals and Oil and Gas sectors ("Beginners") are bringing up the rear. The middle of the bunch is the domain of Automotive and, partly related to it, Industrial Machinery.
Although these days we choose a car mainly for its engine or design, it is estimated that over the next ten years, its software will be an equally significant factor that will impact our purchasing decision.
AI will not only change the way we use our vehicles, but also how we select, design, and manufacture them. Even now, leading brands avail of this type of technology at every stage of the product life cycle - from production through use, to maintenance and aftermarket.
Let's have a closer look at the benefits a vehicle manufacturing company can get when implementing AI in its operations.
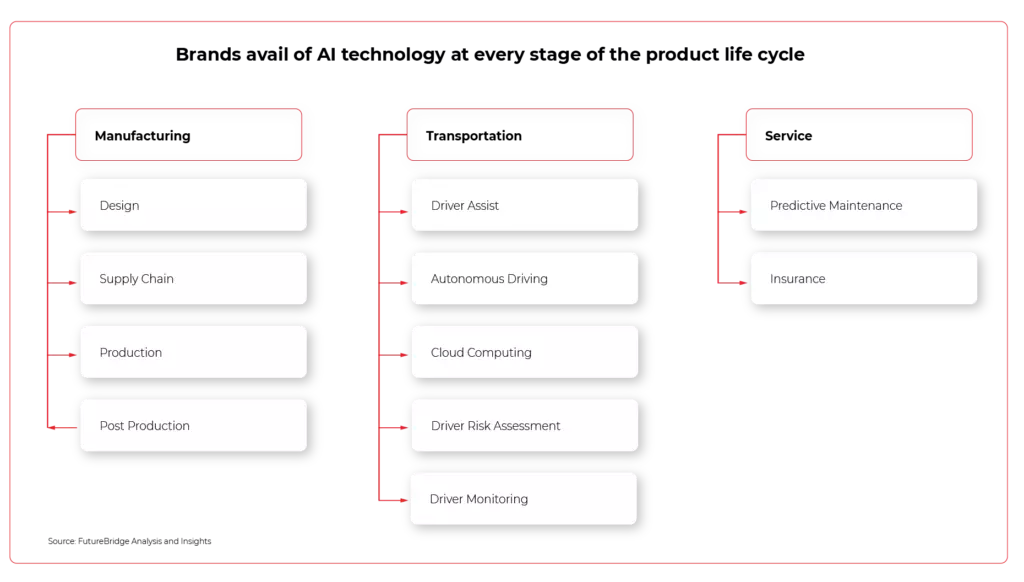
Manufacturing - how AI improves production
1. You will be able to work out complex operations and streamline supply chains
An average passenger car consists of around 30,000 separate parts, which interestingly enough, are usually ordered from various manufacturers in different regions of the world. If, on top of that, we add a complicated manufacturing process, increasingly difficult access to skilled workers and market dependencies, it becomes clear that potential delays or problems in the supply chain result in companies losing millions. Artificial intelligence can predict these complex interactions, automate processes, and prevent possible failures and mishaps
- Artificial intelligence complements Audi's supply chain monitoring. When awarding contracts, it is verified that the partners meet the requirements set out in the company's internal quality code. In 2020, over 13,000 suppliers provided the Volkswagen Group with a self-assessment of their own sustainability performance. Audi only works with companies that successfully pass this audit.
2. More efficient production due to intelligent co-robots working with people
For years, companies from the automotive industry have been trying to find ways to enhance work on the production line and increase efficiency in areas where people would get tired easily or be exposed to danger. Industrial robots have been present in car factories for a long time, but only artificial intelligence has allowed us to introduce a new generation of devices and their work in direct contact with people. AI-controlled co-bots move materials, perform tests, and package products making production much more effective.
- Hyundai Vest Exoskeleton (H-VEX) became a part of Kia Motors’ manufacturing process in 2018. It provides wearable robots for assembly lines. AI in this example helps in the overall production while sensing the work of human employees and adjusting their motions to help them avoid injuries.
- AVGs (Automated Guided Vehicles) can move materials around plants by themselves. They can identify objects in their path and adjust their route. In 2018, an OTTO Motors device carried a load of 750 kilograms in this way!
3. Quality control acquires a completely new quality
The power of artificial intelligence lies not only in analyzing huge amounts of data but also in the ability to learn and draw conclusions. This fact can be used by finding weak points in production, controlling the quality of car bodies, metal or painted surfaces, and also by monitoring machine overload and predicting possible failures. In this way, companies can prevent defective products from leaving the factories and avoid possible production downtime.
- Audi uses computer vision to find small cracks in the sheet metal in the vehicles. Thus, even at the production stage, it reduces the risk of damaged parts leaving the factory.
- Porsche has developed "Sounce", a digital assistant, using deep learning methods. AI is capable of reliably and accurately detecting noise, for example during endurance tests. This solution, in particular, takes the burden off development engineers who so far had to be present during such tests. Acoustic testing based on Artificial Intelligence (AI) increases quality and reduces production costs.
4. AI will configure your dream vehicle
In a competitive and excessively abundant market, selling vehicles is very difficult. Brands are constantly competing in services and technologies that are to provide buyers with new experiences and facilitate the purchasing process. Manufacturers use artificial intelligence services not only at the stage of prototyping and modeling vehicles, but also at the end of the manufacturing process, when the vehicle is eventually sold. A well-designed configurator based on AI algorithms is often the final argument, by which the customer is convinced to buy their dream vehicle. Especially when we are talking about luxury cars.
- The Porsche Car Configurator is nothing more than a recommendation engine powered by artificial intelligence. The luxury car manufacturer created it to allow customers to choose a vehicle from billions of possible options. The configurator works using several million data and over 270 machine learning modules. Effect? The customer chooses the vehicle of their dreams based on customised recommendations.
Transportation - how AI facilitates driving vehicles
5. Artificial intelligence will provide assistance in an emergency
A dangerous situation on the road, vehicle in the blind spot, power steering on a slippery surface. All those situations can be supported by artificial intelligence, which will calculate the appropriate driving parameters or correct the way the driver behaves on the road. Instead of making automatic decisions - which are often emotion-imbued or lack experience - brands increasingly hand them over to machines, thus reducing the number of accidents and protecting people's lives.
- Verizon Connect solutions for fleet management allow you to send speed prompts to your drivers as soon as your vehicle's wipers are turned on. This lets the driver know that they have to slow down due to adverse road conditions such as rain or snow. And the intelligent video recorder will help you understand the context of the accident - for instance, by informing you that the driver accelerated rapidly before the collision.
6. Driver monitoring and risk assessment increase driving safety and comfort
Car journeys may be exhausting. But not for artificial intelligence. The biggest brands are increasingly equipping vehicles with solutions aimed at monitoring fatigue and driver reaction time. By combining intelligent software with appropriate sensors, the manufacturer can fit the car with features that will significantly reduce the number of accidents on the road and discomfort from driving in difficult conditions.
- Tesla monitors the driver's eyes, thus checking the driver's level of fatigue and preventing them from falling asleep behind the wheel. It’s mainly used for the Autopilot system to prevent driver from taking short nap during travel.
- The BMW 3 Series is equipped with a personal assistant, the purpose of which is to improve driving safety and comfort. Are you tired of the journey? Ask for the "the vitalization program" that will brighten the interior, lower the temperature or select the right music. Are you cold? All you have to do is say the phrase "I'm cold" and the seats will be heated to the optimal temperature.
Maintenance - how AI helps you take care of your car
7. Predictive Maintenance prevents malfunctions before they even appear
Cars that we are driving today are already pretty smart. They can alert you whenever something needs your attention and they can pretty precisely say what they actually need – oil, checking the engine, lights etc. The Connected Car era however equipped with the possibilities given by AI brings a whole lot more – predictive maintenance. In this case AI monitors all the sensors within the car and is set to detect any potential problems even before they occur.
AI can easily spot any changes, which may indicate failure, long before it could affect the vehicle’s performance. To go even further with this idea, thanks to the Over-The-Air Update feature, after finding a bug that can be easily fixed by a system patch, such solution can be sent to the car Over-The-Air directly by the manufacturer without the need for the customer to visit the dealership.
- Predi (an AI software company from California) has created an intelligent platform that uses the service order history and data from the Internet of Things to prevent breakdowns and deal with new possible ones faster.
8. Insure your car directly from the cockpit
Driving a car is not only about operating costs and repairs, but also insurance that each of us is required to purchase. In this respect, AI can be useful not only for insurance companies ( see how AI can improve the claims handling process ), but also for drivers themselves. Thanks to the appropriate software, we will remember about expiring insurance or even buy it directly from the comfort of our car, without having to visit the insurer's website or a stationary point.
- The German company ACTINEO, specialising in personal injury insurance, processes and digitises 120,000. claims annually. Their ACTINEO Cockpit service is a digital manager that allows for the comprehensive management of this type of cases, control of billing costs, etc.
- In collaboration with Ford, Arity provides insurers - with the driver's consent, of course - data on the driving style of the vehicle owner. In return for sharing this information, the driver is offered personalised insurance that matches his driving style. The platform’s calculations are based on "more than 440 billion miles of historical driving data from more than 23 million active telematics connections and more than eight years of data directly from cars (source: Green Car Congress).
When will AI take over the automotive industry?
In 2015, it is estimated that only 5-10% of cars had some form of AI installed. The last five years have brought the dissemination of solutions such as parking assistance, driver assistance and cruise control. However, the real boom is likely to occur within the next 8-10 years.
From now on, artificial intelligence in the automotive industry will no longer be a novelty or wealthy buyers’ whims. The spread of the Internet of Things, consumer preferences and finding ways of saving money in the manufacturing process will simply force manufacturers to do this - not only in the vehicle cockpits, but also on the production and service lines.
To this end, they will be made to cooperate with manufacturers of sensors and ultrasonic solutions (cooperation between BMW and Mobileye, Daimler from Bosch or VW and Ford with Aurora) and IT companies providing software for AI. A dependable partner who understands the potential of AI and knows how to use its power to create the car of the future is the key to success for companies in this industry.
The future of autonomous driving connectivity – Quantum entanglement or 6G?
The title of the article is quite deceiving - both mentioned technologies are currently just distant concepts based on widely divergent connectivity mediums. It’s still a distant future, but let’s think for a while about where we are now, what awaits us in the very near future and where we are heading in the long term.
Autonomous driving and the whole Connected Car concept benefits greatly from internet connectivity. Traffic information, being able to request information about nearby cars, navigation, infrastructures like traffic lights, parking, or charging stations - all of that affects the decision about the actual path to be taken by the vehicle or driver.
Some of the systems are rather insensitive to the network bandwidth, for example, the layout of the roads does not require updates every second. On the other hand information about red light or vehicles losing traction nearby are critical and lowering latency directly affects the safety.
What technologies provide connectivity for autonomous driving?
These days cars mainly use the common mobile technology for connectivity: GPRS/EDGE, 3G/HSDPA, LTE, and 4G switching dynamically depending on network coverage. As the availability of 5G increases, the obvious next step is implementing it in the vehicle modems.
Can connected cars rely on 5G?
Obviously, 5G will never be available everywhere. The technology itself is a limitation here - it is millimeter-wave connectivity resulting in 2% of range compared to 4G (300-600m compared to 10-15km). Additionally, the latest Ericsson report predicts that by the end of 2026, 5G coverage is expected to reach 60 percent of the global population, while this still means mainly densely populated areas like cities and suburbs.
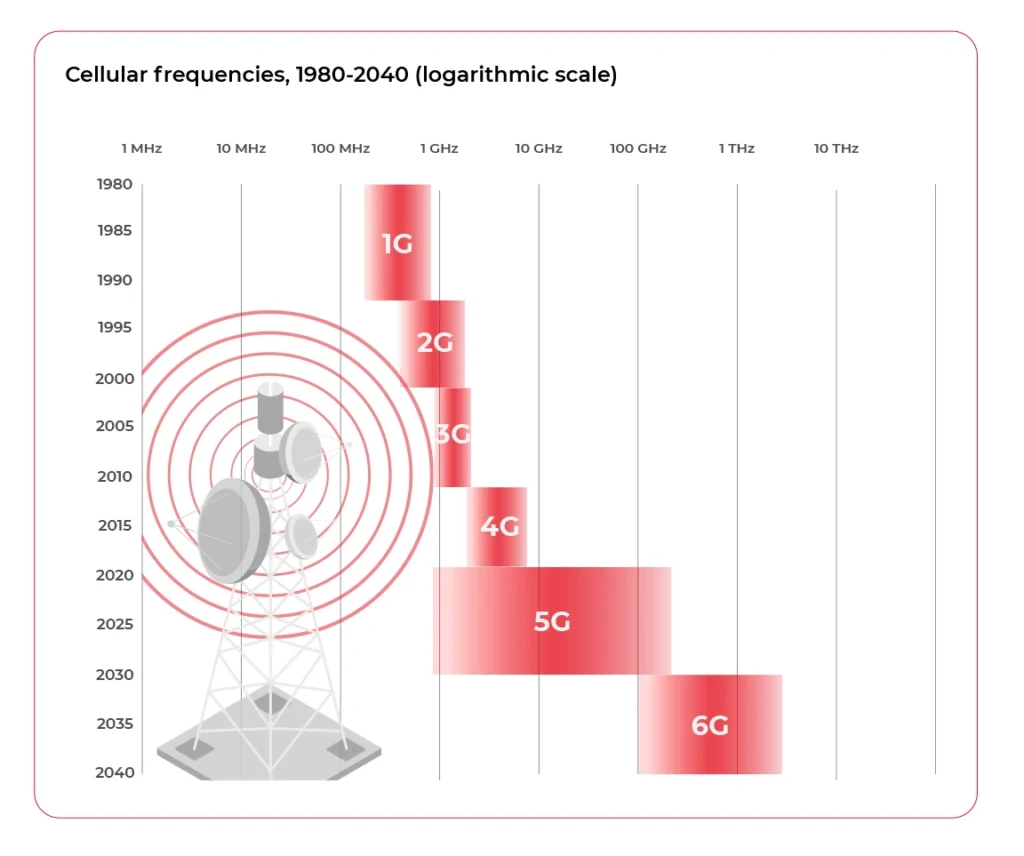
5G solves the latency and bandwidth problem but does not give full coverage, especially for rural areas and highways. Is there nothing more we can use to improve the situation? Not at all, multiple alternatives are being developed right now in parallel.
What are the alternatives to 5G?
There is IEE80211.p (WAVE - Wireless Access for the Vehicular Environment) based on the Wi-Fi WLAN standard focusing on improving the stability of the connection between high-speed vehicles. This is short-range, Vehicle2Vehicle and Vehicle2Infrarstructure communication.
While the 5G is not yet fully there, the 6G is starting to form. The successor of the 5th generation of the wireless cellular network is planned to increase the bandwidth, greatly allowing for extremely data consuming, real-time services to be built - like dynamic Virtual Reality streaming. The groups, like the Next G Alliance, are working on defining technical aspects and testing multiple possibilities, like THz wave frequencies as a physical medium for communication.
The other promising development is the LEO (Low Earth Orbit) satellite network, with a Starlink created by Elon Musk being the most popular currently available. This is no match in terms of latency to both 5G and 6G, but the unprecedented coverage and worldwide availability make it a great solution for situations, where the bandwidth is critical, while moderate latency is still sufficient.
The most futuristic medium, the quantum entanglement from the title of this article, seemed like the Holy Grail of communication - faster than light, meaning no latency at all. When the scientists announced that quantum entanglement works and was observed by comparing distant, entangled particles, the world held its breath. But in the end, there is currently no way to transmit anything this way - quantum entanglement breaks if one of the particles in the pair is forced to a particular quantum state. It’s disappointing but shows us that there may be a totally new way for communication still to be discovered.
Sum up: what connection type will be fueling Connected and Autonomous Cars
So what is the future of communication for Connected Cars and Autonomous Driving? 5G, 6G, satellite or wifi? The answer is all of them. As cars right now can dynamically switch between different kinds of mobile networks, in the future, they should also be able to pick the lowest latency connection available from a mobile network, satellite, wifi or whatever will be the future, or even use multiple simultaneously depending on the system requirements. Because there is no one best solution for all geographical regions, in-car systems, and conflicting requirements. Hybrid connectivity is the future of automotive connectivity.
How to achieve sustainable mobility using sustainable software development
Should the code be green?
Sustainable Mobility is the key goal for today and future vehicle manufacturers and mobility providers. Reducing the CO2 footprint of transportation contributes to building a better future for all of us. For the automotive industry, part of this goal is defined in the European Vehicle Emission Standards initiative, Euro 7 being the latest norm before all cars become fully zero-emission.
There are multiple paths leading into zero-emission transportation, most of which are being taken in parallel. Electric vehicles, especially charged using renewable energy sources such as solar energy. Fuel cells and hydrogen vehicles. Using recycled materials for both car interior and exterior. Car sharing, better urban transportation, and all kinds of initiatives leading to reducing the number of vehicles on the roads.
How software development companies can help us achieve sustainable mobility
Of course, software development companies can help with these kinds of initiatives by building software platforms for electric vehicles , efficient charging, and navigating to charging stations using renewable energy or making sure supply chains are fully invested in reducing CO2 emissions.
But is there anything, in general, we can do, or at least think about, to make software development more environment-aware?
One important aspect is the computational complexity of the code. More operations, assuming the same hardware, require more energy. This is especially important these days, as the microprocessors availability has become a huge bottleneck for the automotive industry. How can we mitigate this problem? Let’s look at two possibilities.
Building software for sustainable mobility with green coding
Firstly, does the programming language or code quality matter? Yes and yes. Let’s start by looking at the Energy Efficiency across Programming Languages paper from 2017 comparing the energy efficiency of programming languages (the lower, the better):
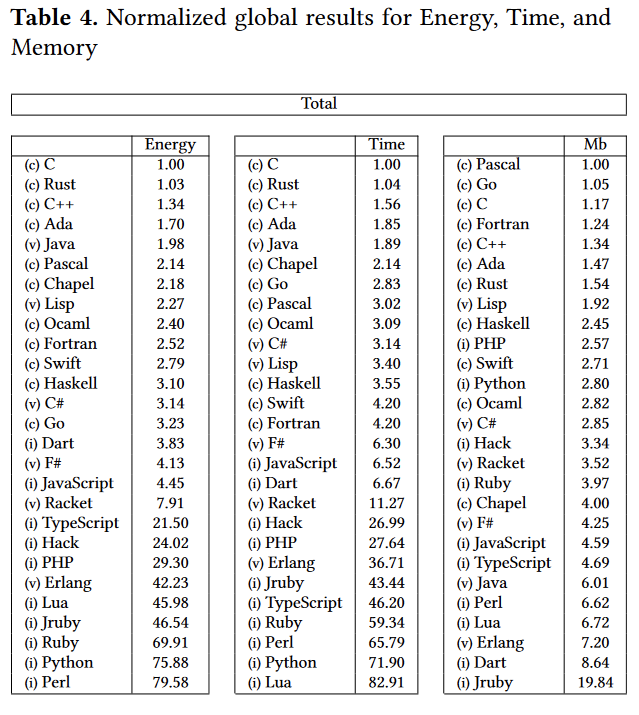
We can see that switching to a lower-level language can improve energy consumption. Is this the answer to the problem? Not directly. Procedural, statically typed languages are, in general, faster and have lower energy consumption, but at the same time are more complicated and require more time to write the same amount of code in easier to use ones. This is not a hard rule, as we can see Java gets a great result, although probably after optimizations.
Choosing energy-efficient computing resources
So one thing we can do is to think about the efficiency of the language when we choose the tech stack for our project. The other thing regarding the same problem is to optimize the code instead of adding more cores or GBs of memory - as it may be a cheaper solution initially.
The other improvement we can make comes to leveraging shared resources in the cloud for computation by building multi-layer computing systems, where results required immediately or in real-time can be computed on edge devices, while others can be computed at the edge of the cloud or in distributed cloud systems. Having those three layers, where two of them share resources between multiple vehicles or end-user devices, makes the computation both more cost-effective and requires less energy, as the bill is shared between multiple users.
Developers and software development departments can contribute to making the sustainable mobility goal achievable in the near future. Small steps and decisions regarding programming languages, frameworks, computing resources make a difference.
Interested in our services?
Reach out for tailored solutions and expert guidance.