GrapeChat – the LLM RAG for Enterprise


LLM is an extremely hot topic nowadays. In our company, we drive several projects for our customers using this technology. There are more and more tools, researches, and resources, including no-code, all-in-one solutions.
The topic for today is RAG – Retrieval Augmented Generation. The aim of RAG is to retrieve necessary knowledge and generate answers to the users’ questions based on this knowledge. Simply speaking, we need to search the company knowledge base for relevant documents, add those documents to the conversation context, and instruct an LLM to answer questions using the knowledge. But in detail, it’s nothing simple, especially when it comes to permissions.
Before you start
There are two technologies that take the current software development sector by storm, taking advantage of the LLM revolution: Microsoft Azure cloud platform, along with other Microsoft services, and Python programming language.
If your company uses Microsoft services, and SharePoint and Azure are within your reach, you can create a simple RAG application fast. Microsoft offers a no-code solution and application templates with source code in various languages (including easy-to-learn Python) if you require minor customizations.
Of course, there are some limitations, mainly in the permission management area, but you should also consider how much you want your company to rely on Microsoft services.
If you want to start from scratch, you should start by defining your requirements (as usual). Do you want to split your users into access groups, or do you want to assign access to resources for individuals? How do you want to store and classify your files? How deeply do you want to analyze your data (what about dependencies)? Is Python a good choice, after all? What about the costs? How to update permissions? There are a lot of questions to answer before you start. In Grape Up, we went through this process and implemented GrapeChat, our internal RAG-based chatbot using our Enterprise data.
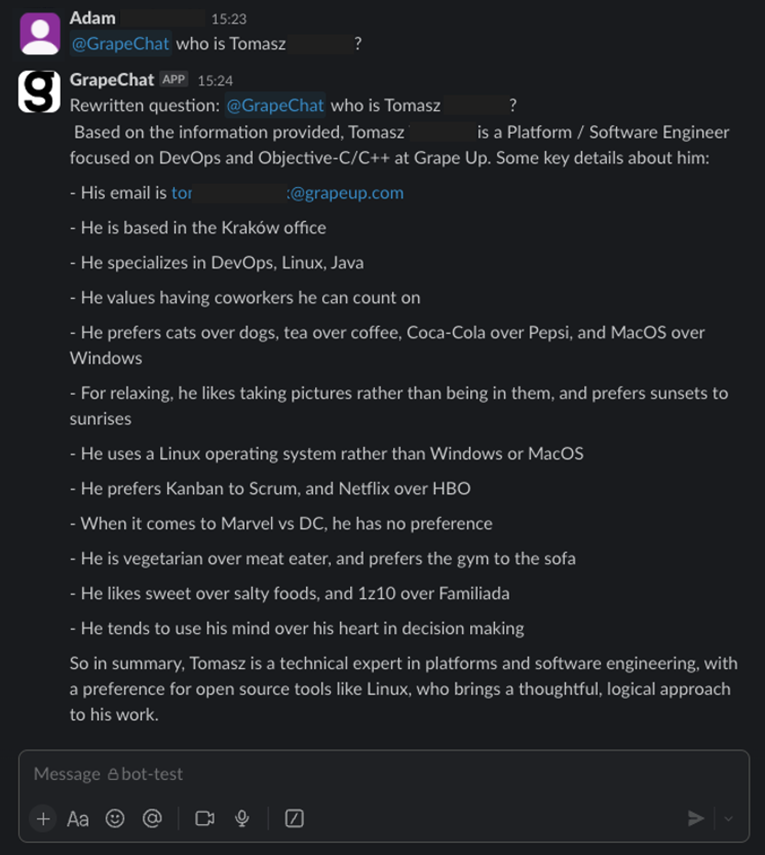
Now, I invite you to learn more from our journey.
The easy way

Source: https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/use-your-data-securely
The most time-efficient way to create a chatbot using RAG is to use the official manual from Microsoft. It covers everything – from pushing data up to the front-end application. However, it’s not very cost-efficient. To make it work with your data, you need to create an AI Search resource, and the simplest one costs 234€ per month (you will pay for the LLM usage, too). Moreover, SharePoint integration is not in the final stage yet, which forces you to manually upload data. You can lower the entry threshold by uploading your data to Blob storage instead of using SharePoint directly, and then you can use Power Automate to do it automatically for new files, but it requires more and more hard to troubleshoot UI-created components, with more and more permission management by your Microsoft-care team (probably your IT team) and a deeper integration between Microsoft and your company.
And then there is the permission issue.
When using Microsoft services, you can limit access to the documents being processed during RAG by using Azure AI Search security filters. This method requires you to assign a permission group when adding each document to the system (to be more specific, during indexing), and then you can add a permission group as a parameter to the search request. Of course, there is much more offered by Microsoft in terms of security of the entire application (web app access control, network filtering, etc.).
To use those techniques, you must have your own implementation (say bye-bye to no-code). If you like starting a project from a blueprint, go here. Under the link, you’ll find a ready-to-use Azure application, including the back-end, front-end, and all necessary resources, along with scripts to set it up. There are also variants linked in the README file, written in other languages (Java, .Net, JavaScript).
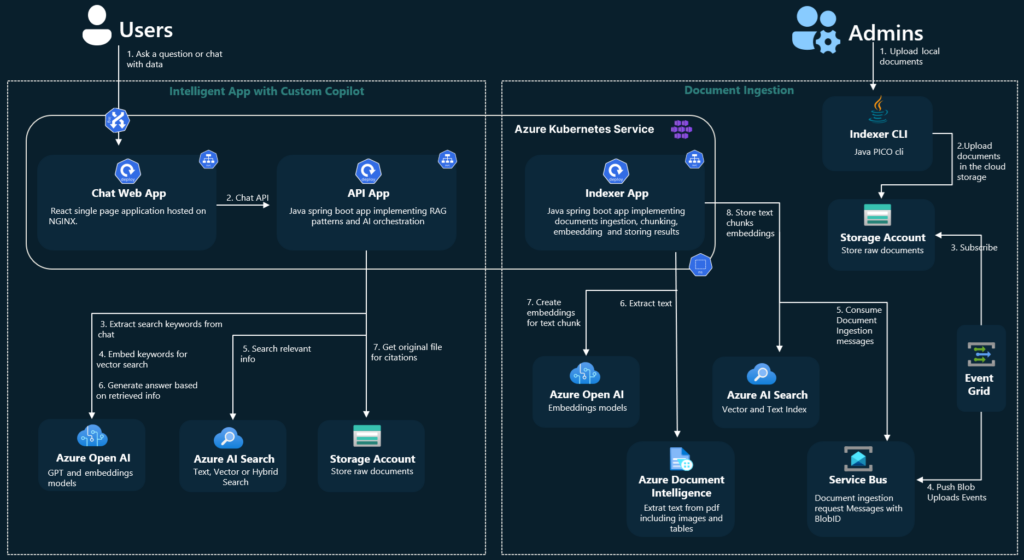
Source: https://github.com/Azure-Samples/azure-search-openai-demo-java/blob/main/docs/aks/aks-hla.png
However, there are still at least three topics to consider.
1) You start a new project, but with some code already written. Maybe the quality of the code provided by Microsoft is enough for you. Maybe not. Maybe you like the code structure. Maybe not. From my experience, learning the application to adjust it may take more time than starting from scratch. Please note that this application is not a simple CRUD, but something much more complex, making profits from a sophisticated toolbox.
2) Permission management is very limited. “Permission” is a keyword that distinguishes RAG and Enterprise-RAG. Let’s imagine that you have a document (for example, the confluence page) available to a limited number of users (for example, your company’s board). One day, the board member decides to grant access to this very page to one of the non-board managers. The manager is not part of the “board” group, the document is already indexed, and Confluence uses a dual-level permission system (space and document), which is not aligned with external SSO providers (Microsoft’s Entra ID).
Managing permissions in this system is a very complex task. Even if you manage to do it, there are two levels of protection – the Entra ID that secures your endpoint and the filter parameter in the REST request to restrict documents being searched during RAG. Therefore, the potential attack vector is very wide – if somebody has access to the Entra ID (for example, a developer working on the system), she/he can overuse the filtering API to get any documents, including the ones for the board members’ eyes only.
3) You are limited to Azure AI Search. Using Azure OpenAI is one thing (you can use OpenAI API without Azure, you can go with Claude, Gemini, or another LLM), but using Azure AI Search increases cost and limits your possibilities. For example, there is no way to utilize connections between documents in the system, when one document (e.g. an email with a question) should be linked to another one (e.g. a response email with the answer).
All in all, you couple your company with Microsoft very strict – using Entra ID permission management, Azure resources, Microsoft Storage (Azure Blob or SharePoint), etc. I’m not against Microsoft, but I’m against a single point of failure and addiction to a single service provider.
The hard way
I would say a “better way”, but it’s always a matter of your requirements and possibilities.
The hard way is to start the project with a blank page. You need to design the user’s touch point, the backend architecture, and the permission management.
In our company, we use SSO – the same identity for all resources: data storage, communicators, and emails. Therefore, the main idea is to propagate the user’s identity to authorize the user to obtain data.

Let’s discuss the data retrieval part first. The user logs into the messaging app (Slack, Teams, etc.) with their own credentials. The application uses their token to call the GrapeChat service. Therefore, the user’s identity is ensured. The bot decides (using LLM) to obtain some data. The service exchanges the user’s token for a new user’s token, allowed to call the database. This process is allowed only for the service with the user logged in. It’s impossible to access the database without both the GrapeChat service and the user’s token. The database verifies credentials and filters data. Let me underline this part – the database is in charge of data security. It’s like a typical database, e.g. PostgreSQL or MySQL – the user uses their own credentials to access the data, and nobody challenges its permission system, even if it stores data of multiple users.
Wait a minute! What about shared credentials, when a user stores data that should be available for other users, too?
It brings us to the data uploading process and the database itself.
The user logs into some data storage. In our case, it may be a messaging app (conversations are a great source of knowledge), email client, Confluence, SharePoint, shared SMB resource, or a cloud storage service (e.g. Dropbox). However, the user’s token is not used to copy the data from the original storage to our database.
There are three possible solutions.
- The first one is to actively push data from its original storage to the database. It’s possible in just a few systems, e.g. as automatic forwarding for all emails configured on the email server.
- The second one is to trigger the database to download new data, e.g. with a webhook. It’s also possible in some systems, e.g. Contentful to send notifications about changes this way.
- The last one is to periodically call data storages and compare stored data with the origin. This is the worst idea (because of the possible delay and comparing process) but, unfortunately, the most common one. In this approach, the database actively downloads data based on a schedule.
Using those solutions requires separate implementations for each data origin.
In all those cases, we need a non-user’s account to process user’s data. The solution we picked is to create a “superuser” account and restrict it to non-human access. Only the database can use this account and only in an isolated virtual network.
Going back to the group permission and keeping in mind that data is acquired with “superuser” access, the database encrypts each document (a single piece of data) using the public keys of all users that should have access to it. Public keys are stored with the Identity (in our case, this is a custom field in Active Directory), and let me underline it again – the database is the only entity that process unencrypted data and the only one that uses “superuser” access. Then, when accessing the data, a private key (obtained from an Active Directory using the user’s SSO token) of each allowed user can be used for decryption.
Therefore, the GrapeChat service is not part of the main security processes, but on the other hand, we need a pretty complex database module.
The database and the search process
In our case, the database is a strictly secured container running 3 applications – SQL database, vector database, and a data processing service. Its role is to acquire and embed data, update permissions, and execute search. The embedding part is easy. We do it internally (in the database module) with the Instructor XL model, but you can choose a better one from the leaderboard. Allowed users’ IDs are stored within the vector database (in our case – Qdrant) for filtering purposes, and the plain text content is encrypted with users’ public keys.

When the DB module searches for a query, it uses the vector DB first, including metadata to filter allowed users. Then, the DB service obtains associated entities from the SQL DB. In the next steps, the service downloads related entities using simple SQL relations between them. There is also a non-data graph node, “author”, to keep together documents created by the same person. We can go deeper through the graph relation-by-relation if the caller has rights to the content. The relation-search deepness is a parameter of the system.
We do use a REST field filter like the one offered by the native MS solution, too, but in our case, we do the permission-aware search first. So, if there are several people in the Slack conversation and one of them mentions GrapeChat, the bot uses his permission in the first place and then, additionally, filters results not to expose a document to other channel members if they are not allowed to see it. In other words, the calling user can restrict search results according to teammates but is not able to extend the results above her/his permissions.
What happens next?
The GrapeChat service is written in Java. This language offers a nice Slack SDK, and Spring AI, so we’ve seen no reason to opt for Python with the Langchain library. The much more important component is the database service, built of three elements described above. To make the DB fast and smalll, we recommend using Rust programming language, but you can also use Python, according to the knowledge of your developers.
Another important component is a document parser. The task is easy with simple, plain text messages, but your company knowledge includes tons of PDFs, Word docs, Excel spreadsheets, and even videos. In our architecture, parsers are external, replaceable modules written in various languages working with the DB in the same isolated network.
RAG for Enterprise
With all the achievements of recent technology, RAG is not rocket science anymore. However, when it comes to the Enterprise data, the task is getting more and more complex. Data security is one of the biggest concerns in the LLM era, so we recommend starting small – with a limited number of non-critical documents, with limited access, and a wisely secured system.
In general, the task is not impossible, and can be easily handled with a proper application design. Working on an internal tool is a great opportunity to gain experience and prepare better for your next business cases, especially when the IT sector is so young and immature. This way we, here at GrapeUp, use our expertise to serve our customers in a better way.
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles

