Exploring Texas Instruments Edge AI: Hardware Acceleration for Efficient Computation


In recent years, the field of artificial intelligence (AI) has witnessed a transformative shift towards edge computing, enabling intelligent decision-making to occur directly on devices rather than relying solely on cloud-based solutions. Texas Instruments, a key player in the semiconductor industry, has been at the forefront of developing cutting-edge solutions for Edge AI. One of the standout features of their offerings is the incorporation of hardware acceleration for efficient computation, which significantly improves the performance of AI models on resource-constrained devices.
Pros and Cons of Running AI Models on Embedded Devices vs. Cloud
In the evolving landscape of artificial intelligence, the decision to deploy models on embedded devices or rely on cloud-based solutions is a critical consideration. This chapter explores the advantages and disadvantages of running AI models on embedded devices, emphasizing the implications for efficiency, privacy, latency, and overall system performance.
Advantages of Embedded AI
- Low Latency
One of the primary advantages of embedded AI is low latency. Models run directly on the device, eliminating the need for data transfer to and from the cloud. This results in faster response times, making embedded AI ideal for applications where real-time decision-making is crucial. - Privacy and Security
Embedded AI enhances privacy by processing data locally on the device. This mitigates concerns related to transmitting sensitive information to external servers. Security risks associated with data in transit are significantly reduced, contributing to a more secure AI deployment. - Edge Computing Efficiency
Utilizing embedded AI aligns with the principles of edge computing. By processing data at the edge of the network, unnecessary bandwidth usage is minimized, and only relevant information is transmitted to the cloud. This efficiency is especially beneficial in scenarios with limited network connectivity. What’s more, some problems are very inefficient to solve on cloud-based AI models, for example: video processing with real time output. - Offline Functionality
Embedded AI allows for offline functionality, enabling devices to operate independently of internet connectivity. This feature is advantageous in remote locations or environments with intermittent network access, as it expands the range of applications for embedded AI. - Reduced Dependence on Network Infrastructure
Deploying AI models on embedded devices reduces dependence on robust network infrastructure. This is particularly valuable in scenarios where maintaining a stable and high-bandwidth connection is challenging or cost ineffective. AI feature implemented on the cloud platform will be unavailable in the car after the connection is lost.
Disadvantages of Embedded AI
- Lack of Scalability
Scaling embedded AI solutions across a large number of devices can be challenging. Managing updates, maintaining consistency, and ensuring uniform performance becomes more complex as the number of embedded devices increases. - Maintenance Challenges
Updating and maintaining AI models on embedded devices can be more cumbersome compared to cloud-based solutions. Remote updates may be limited, requiring physical intervention for maintenance, which can be impractical in certain scenarios. - Initial Deployment Cost
The initial cost of deploying embedded AI solutions, including hardware and development, can be higher compared to cloud-based alternatives. However, this cost may be offset by long-term benefits, depending on the specific use case and scale. - Limited Computational Power
Embedded devices often have limited computational power compared to cloud servers. This constraint may restrict the complexity and size of AI models that can be deployed on these devices, impacting the range of applications they can support. - Resource Constraints
Embedded devices typically have limited memory and storage capacities. Large AI models may struggle to fit within these constraints, requiring optimization or compromising model size for efficient deployment.
The decision to deploy AI models on embedded devices or in the cloud involves careful consideration of trade-offs. While embedded AI offers advantages in terms of low latency, privacy, and edge computing efficiency, it comes with challenges related to scalability, maintenance, and limited resources.
However, chipset manufacturers are constantly engaged in refining and enhancing their products by incorporating specialized modules dedicated to hardware-accelerated model execution. This ongoing commitment to innovation aims to significantly improve the overall performance of devices, ensuring that they can efficiently run AI models. The integration of these hardware-specific modules not only promises comparable performance but, in certain applications, even superior efficiency.
Deploy AI model on embedded device workflow

1. Design Model
Designing an AI model is the foundational step in the workflow. This involves choosing the appropriate model architecture based on the task at hand, whether it’s classification, regression, or other specific objectives. This is out of the topic for this article.
2. Optimize for Embedded (Storage or RAM Memory)
Once the model is designed, the next step is to optimize it for deployment on embedded devices with limited resources. This optimization may involve reducing the model size, minimizing the number of parameters, or employing quantization techniques to decrease the precision of weights. The goal is to strike a balance between model size and performance to ensure efficient operation within the constraints of embedded storage and RAM memory.
3. Deploy (Model Runtime)
Deploying the optimized model involves integrating it into the embedded system’s runtime environment. While there are general-purpose runtime frameworks like TensorFlow Lite and ONNX Runtime, achieving the best performance often requires leveraging dedicated frameworks that utilize hardware modules for accelerated computations. These specialized frameworks harness hardware accelerators to enhance the speed and efficiency of the model on embedded devices.
4. Validate
Validation is a critical stage in the workflow to ensure that the deployed model performs effectively on the embedded device. This involves rigorous testing using representative datasets and scenarios. Metrics such as accuracy, latency, and resource usage should be thoroughly evaluated to verify that the model meets the performance requirements. Validation helps identify any potential issues or discrepancies between the model’s behavior in the development environment and its real-world performance on the embedded device.
Deploy model on Ti Edge AI and Jacinto 7
Deploying an AI model on Ti Edge AI and Jacinto 7 involves a series of steps to make the model work efficiently with both regular and specialized hardware. In simpler terms, we’ll walk through how the model file travels from a general Linux environment to a dedicated DSP core, making use of special hardware features along the way.
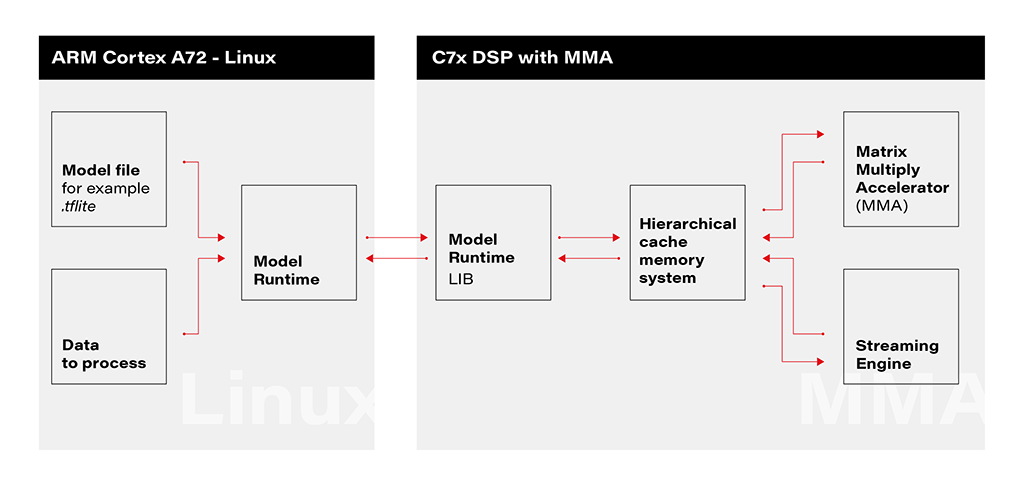
1. Linux Environment on A72 Core: The deployment process initiates within the Linux environment running on the A72 core. Here, a model file resides, ready to be utilized by the application’s runtime. The model file, often in a standardized format like .tflite, serves as the blueprint for the AI model’s architecture and parameters.
2. Runtime Application on A72 Core: The runtime application, responsible for orchestrating the deployment, receives the model file from the Linux environment. This runtime acts as a proxy between the user, the model, and the specialized hardware accelerator. It interfaces with the Linux environment, handling the transfer of input data to be processed by the model.
3. Connection to C7xDSP Core: The runtime application establishes a connection with its library executing on the C7xDSP core. This library, finely tuned for hardware acceleration, is designed to efficiently process AI models using specialized modules such as the Matrix Multiply Accelerator.
4. Loading Model and Data into Memory: The library on the C7x DSP core receives the model description and input data, loading them into memory for rapid access. This optimized memory utilization is crucial for achieving efficient inference on the dedicated hardware.
5. Computation with Matrix Multiply Accelerator: Leveraging the power of the Matrix Multiply Accelerator, the library performs the computations necessary for model inference. The accelerator efficiently handles matrix multiplications, a fundamental operation in many neural network models.
The matrix multiply accelerator (MMA) provides the following key features:
- Support for a fully connected layer using matrix multiply with arbitrary dimension
- Support for convolution layer using 2D convolution with matrix multiply with read panel Support for ReLU non-linearity layer OTF
- Support for high utilization (>85%) for a typical convolutional neural network (CNN), such as AlexNet, ResNet, and others
- Ability to support any CNN network topologies limited only by memory size and bandwidth
6. Result Return to User via Runtime on Linux: Upon completion of computations, the results are returned to the user through the runtime application on the Linux environment. The inference output, processed with hardware acceleration, provides high-speed, low-latency responses for real-time applications.
Object Recognition with AI Model on Jacinto 7: Real-world Challenges
In this chapter, we explore a practical example of deploying an AI model on Jacinto 7 for object recognition. The model is executed according to the provided architecture, utilizing the TVM-CL-3410-gluoncv-mxnet-mobv2 model from the Texas Instruments Edge AI Model Zoo. The test images capture various scenarios, showcasing both successful and challenging object recognition outcomes.
The deployment architecture aligns with the schematic provided, incorporating Jacinto 7’s capabilities to efficiently execute the AI model. The TVM-CL-3410-gluoncv-mxnet-mobv2 model is utilized, emphasizing its pre-trained nature for object recognition tasks.
Test Scenarios: A series of test images were captured to evaluate the model’s performance in real-world conditions. Notably:

Challenges and Real-world Nuances: The test results underscore the challenges of accurate object recognition in less-than-ideal conditions. Factors such as image quality, lighting, and ambiguous object appearances contribute to the intricacy of the task. The third and fourth images, where scissors are misidentified as a screwdriver, and a Coca-Cola glass is misrecognized as wine, exemplify situations where even a human might face difficulty due to limited visual information-
Quality Considerations: The achieved results are noteworthy, considering the less-than-optimal quality of the test images. The chosen camera quality and lighting conditions intentionally mimic challenging real-world scenarios, making the model’s performance commendable.
Conclusion: The real-world example of object recognition on Jacinto 7 highlights the capabilities and challenges associated with deploying AI models in practical scenarios. The successful identification of objects like a screwdriver, cup, and computer mouse demonstrates the model’s efficacy. However, misidentifications in challenging scenarios emphasize the need for continuous refinement and adaptation, acknowledging the intricacies inherent in object recognition tasks, especially in dynamic and less-controlled environments.
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles