Dependency injection in Cucumber-JVM: Sharing state between step definition classes

It's an obvious fact for anyone who's been using Cucumber for Java in test automation that steps need to be defined inside a class. Passing test state from one step definition to another can be easily achieved using instance variables, but that only works for elementary and small projects. In any situation where writing cucumber scenarios is part of a non-trivial software delivery endeavor, Dependency Injection (DI) is the preferred (and usually necessary!) solution. After reading the article below, you'll learn why that's the case and how to implement DI in your Cucumber-JVM tests quickly.
Preface
Let's have a look at the following scenario written in Gherkin:
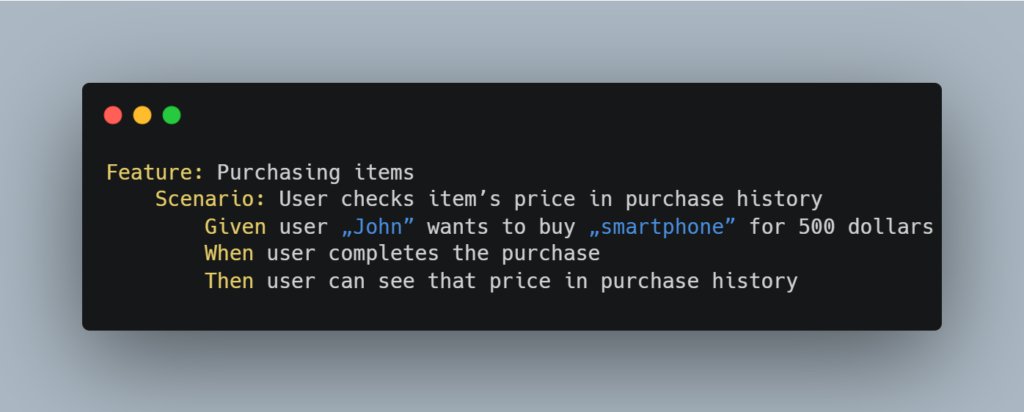
If we assume that it's part of a small test suite, then its implementation using step definitions within the Cucumber-JVM framework could look like this:
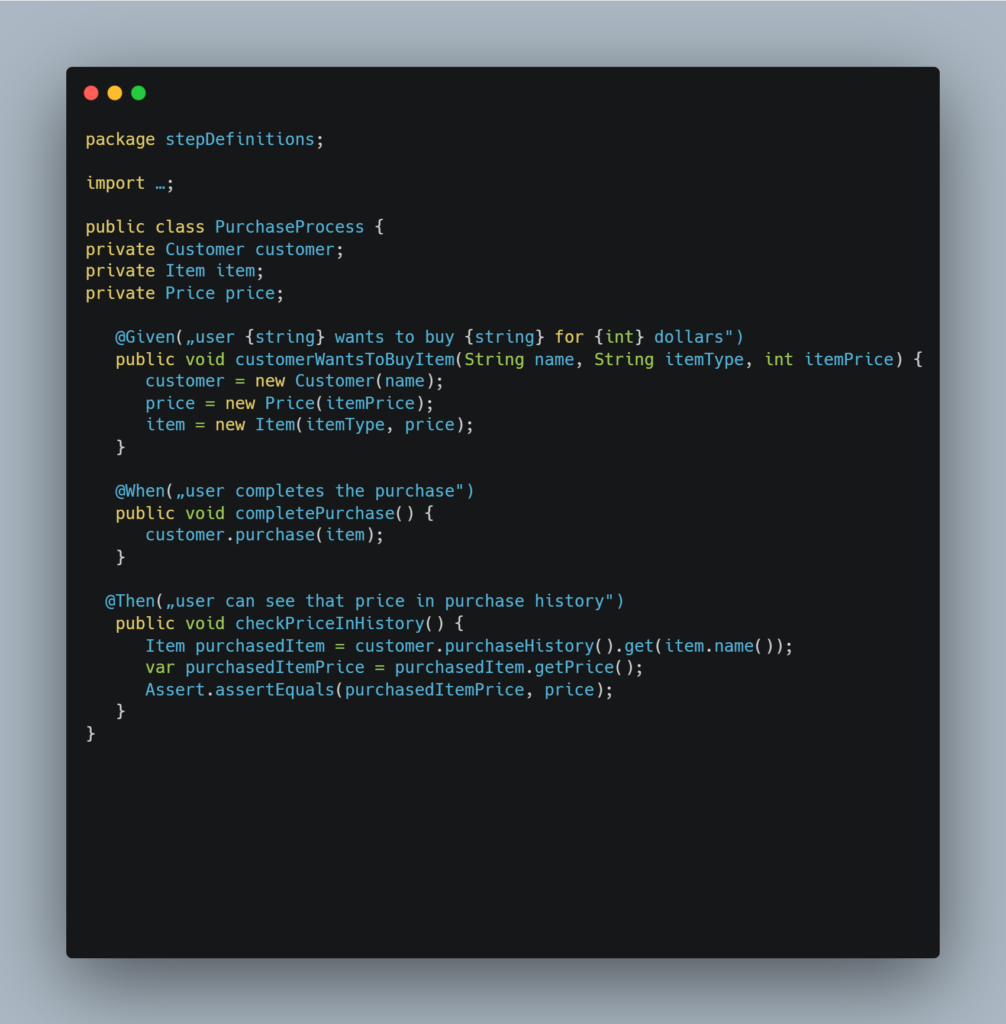
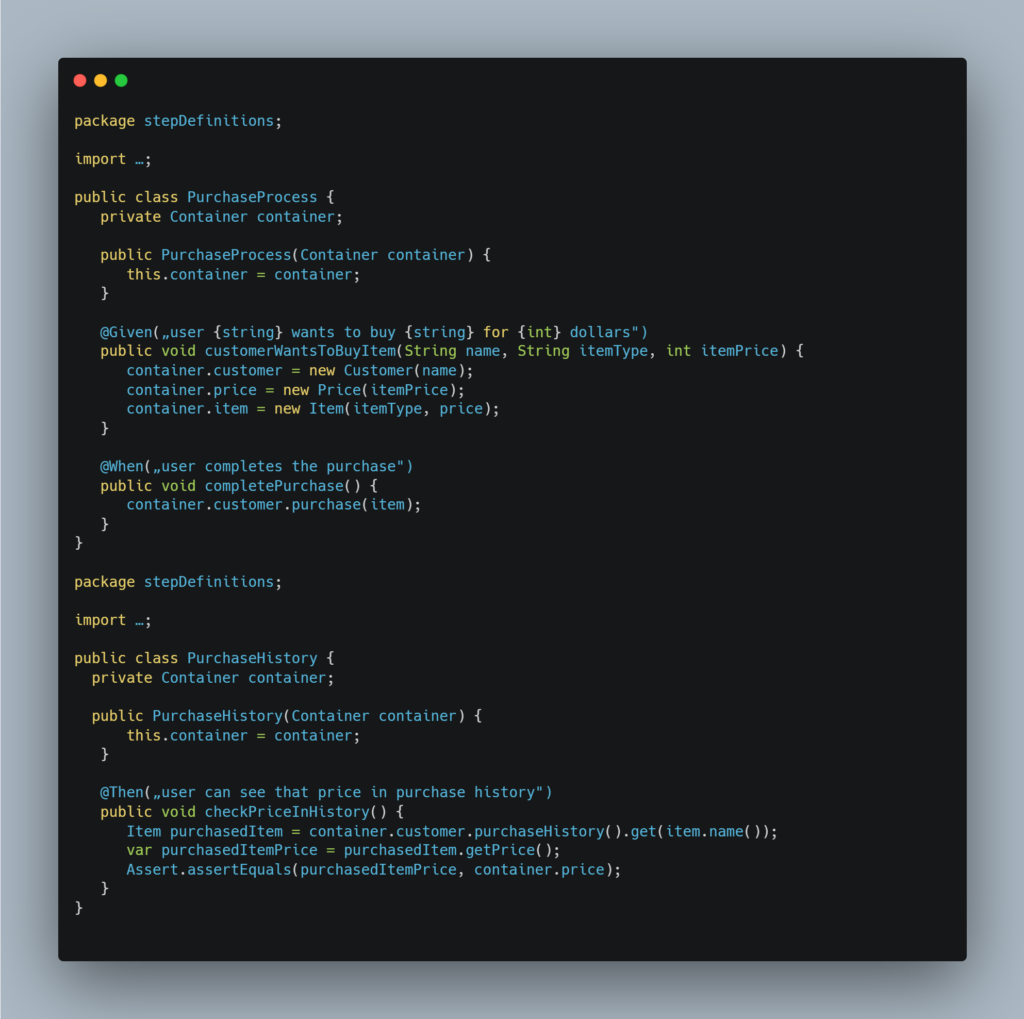
In the example above, the data is passed between step definitions (methods) through instance variables. This works because the methods are in the same class – PurchaseProcess, since instance variables are generally accessible only inside the same class that declares them.
Problem
The number of step definitions grows when the number of Cucumber scenarios grows. Sooner or later, this forces us to split our steps into multiple classes - to maintain code readability and maintainability, among other reasons. Applying this truism to the previous example might result in something like this:
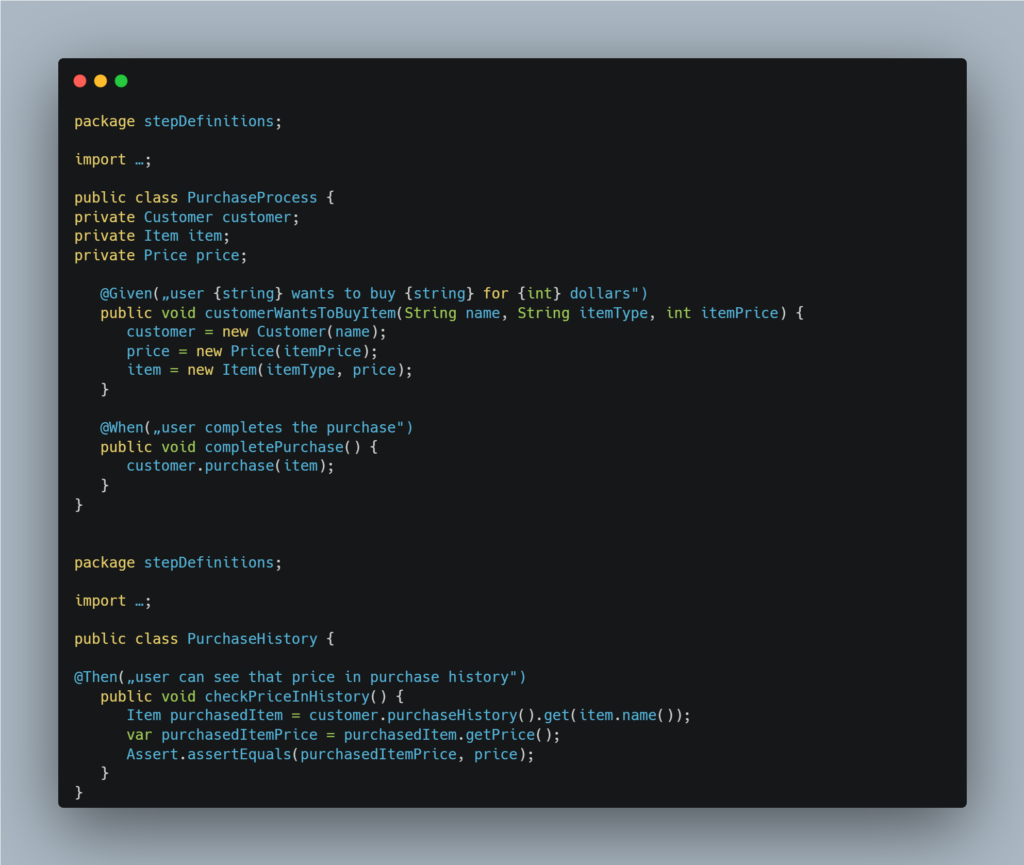
But now we face a problem: the checkPriceInHistory method moved into the newly created PurchaseHistory class can't freely access data stored in instance variables of its original PurchaseProcess class.
Solution
So how do we go about solving this pickle? The answer is Dependency Injection (DI) – the recommended way of sharing the state between steps in Cucumber-JVM.
If you're unfamiliar with this concept, then go by Wikipedia's definition:
"In software engineering , dependency injection is a design pattern in which an object or function receives other objects or functions that it depends on. A form of inversion of control , dependency injection aims to separate the concerns of constructing and using objects, leading to loosely coupled programs. [1] [2] [3] The pattern ensures that an object or function which wants to use a given service should not have to know how to construct those services. Instead, the receiving ' client ' (object or function) is provided with its dependencies by external code (an 'injector'), which it is not aware of." [1]
In the context of Cucumber, to use dependency injection is to "inject a common object in each class with steps. An object that is recreated every time a new scenario is executed." [2]
Thus Comes PicoContainer
JVM implementation of Cucumber supports several DI modules: PicoContainer, Spring, Guice, OpenEJB, Weld, and Needle. PicoContainer is recommended if your application doesn't already use another one. [3]
The main benefits of using PicoContainer over other DI modules steam from it being tiny and simple:
- It doesn't require any configuration
- It doesn't require your classes to use any APIs
- It only has a single feature – it instantiates objects [4]
Implementation
To use PicoContainer with Maven, add the following dependency to your pom.xml :
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-picocontainer</artifactId>
<version>7.8.1</version>
<scope>test</scope>
</dependency>
If using Gradle, add:
compile group: 'io.cucumber', name: 'cucumber-picocontainer', version: ‚7.8.1’
To your build.gradle file.
Now let's go back to our example code. The implementation of DI using PicoContainer is pretty straightforward. First, we have to create a container class that will hold the common data:
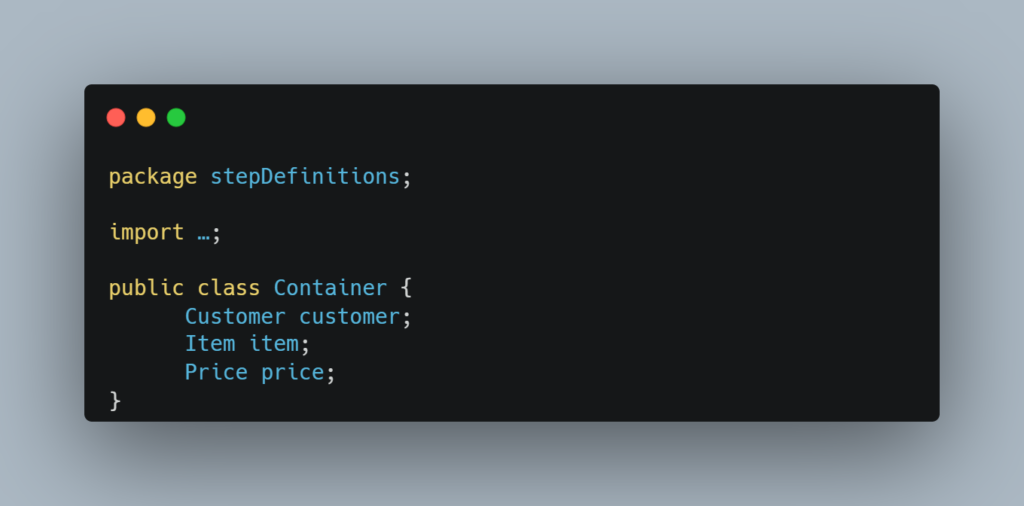
Then we need to add a constructor injection to implement the PurchaseProcess and PurchaseHistory classes. This boils down to the following:
- creating a reference variable of the Container class in the current step classes
- initializing the reference variable through a constructor
Once the changes above are applied, the example should look like this:
Conclusion
PicoContainer is lightweight and easy to implement. It also requires minimal changes to your existing code, helping to keep it lean and readable. These qualities make it a perfect fit for any Cucumber-JVM project since sharing test context between classes is a question of 'when' and not 'if' in essentially any test suite that will grow beyond a few scenarios.

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
Testing iOS applications using Appium, Cucumber, and Serenity - a recipe for quality
iOS devices still claim a significant part of the mobile market, taking up to 22 percent of the sales globally. As many devoted clients come back for new Apple products, there is also a great demand for iOS applications. In this article, we are going to look at ensuring the quality of iOS apps striving for the usage of best practices using Appium, Cucumber and Serenity tools.
Structure
The Page Object Model is one of the best approaches to testing that QA engineers can apply to a test automation project. It is such a way of structuring the code in an automation project that improves code quality and readability, test maintenance and on top of that, it is a great way of avoiding chaos. The basic idea behind it comes to keeping all references to mobile elements and methods performing operations on them in one class file for each page or screen of the app (or web page for non-native web applications).
What are the benefits of this approach, you may ask? Firstly, it makes automation really straightforward. Basically, it means finding elements in our iOS app via inspector and then performing operations on them. Another main advantage is the coherent structure of the project that allows anyone to navigate through it quickly.
Let's take an example of an app that contains recipes. It shows the default cookbook with basic recipes on startup, which will be our first page. From there, a user can navigate to any available recipe, thus marking a second page. On top of that, the app also allows to browse other cookbooks or purchase premium ones, making it the third page and consequently - a page object file.
Similarly, we should create corresponding step definition files. This is not an obligatory practice, but keeping all step definitions in one place causes unnecessary chaos.
While creating your pages and step definition class files it is advised to choose names that are related to the page (app screen) which contents you are going to work on. Naming these files after a feature or scenario can seem right at first glance, but as the project expands, you will notice more and more clutter in its structure. Adopting the page naming convention ensures that anyone involved in the project can get familiar with it straight away and start collaboration on it in no time. Such practice also contributes to reusability of code - either step definitions or methods/functions.
Contrary to the mentioned step and step definition files, the Cucumber feature files should be named after a feature they verify. Clever, isn’t it? And again, structuring them into directories named in relation to a particular field of the application under test will make the structure more meaningful.
Serenity’s basic concept is to be a 'living documentation'. Therefore, giving test scenarios and feature files appropriate names helps the team and stakeholders understand reports and the entire project better.
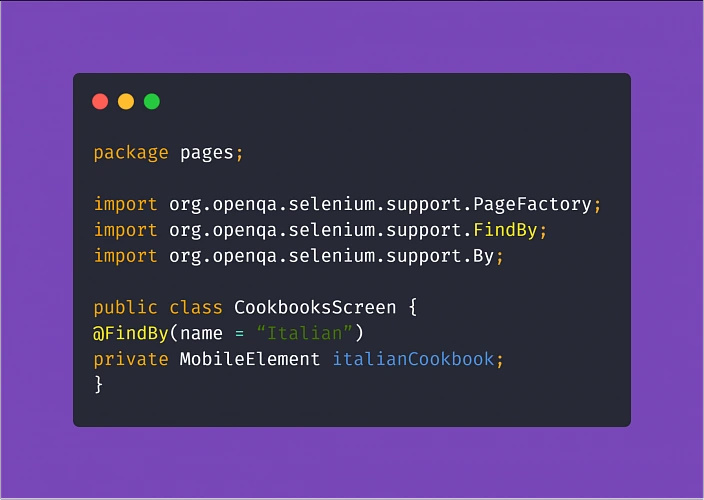
Another ingredient expanding the benefits of the Page Object Model in the test automation project is PageFactory. It is a tool that helps you reduce the coding work and easily put MobileElements locators in code, using @FindBy notation. From there, finding elements for Appium to interact with them in tests is much simpler.
Assertion
Running tests via Appium can be very resource-consuming. To make things easier for your MacOS machine running tests on your iOS device, make sure you are not constantly asserting the visibility of all objects on a page. This practice significantly increases the test execution time, which usually is not the most desirable thing.
What is more, when you do have to check if an element is visible, enabled, clickable, or anything in between - try to avoid locating mobile elements using Xpath. The Appium inspector tip has a valid point! You should do what you can to convince the development team to make an extra effort and assign unique IDs and names to the elements in the app. This will not only make automation testing easier and quicker, consequently making your work as a tester more effective, ultimately resulting in increasing the overall quality of the product. And that is why we are here. Not to mention that the maintenance of the tests (e.g. switching to different locators when necessary) will become much more enjoyable.
Understanding the steps
Another aspect of setting up this kind of project comes down to taking advantage of Cucumber and using Gherkin language.
Gherkin implements a straightforward approach with Given, When, Then notation with the help of the additional And and But which seems fairly easy to use. You could write pretty much anything you want in the test steps of your feature files. Ultimately, the called methods are going to perform actions.
But the reason for using the Behavior Driven Development approach and Cucumber itself is enabling the non-tech people involved in the project to understand what is going on in the tests field. Not only that, writing test scenarios in Given/When/Then manner can also act in your advantage. Such high-level test descriptions delivered by the client or business analyst will get you coding in no time, provided that they are written properly. Here are some helpful tips:
Test scenarios written in Gherkin should focus on the behavior of the app (hence Behavior Driven Development).
Here's an example of how NOT to write test scenarios in Gherkin, further exploring the theme of cookbook application:
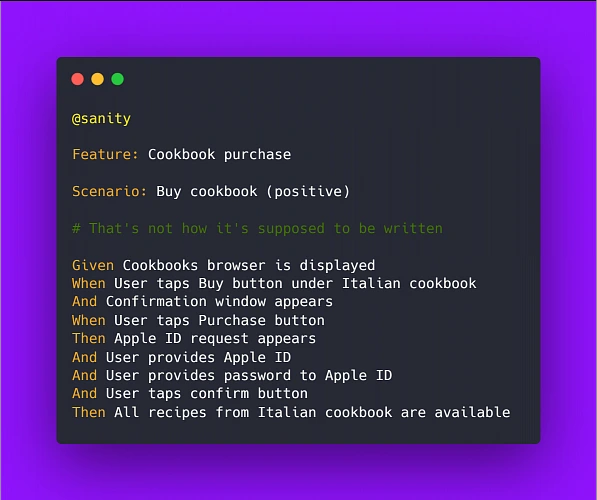
Above example illustrates two bad practices we should avoid: It focuses on the implementation instead of behavior and it uses hard-coded values rather than writing test steps in such a way to enable reusability by changing values within a step.
Therefore, a proper scenario concerning purchasing a cookbook in our example app should look like:
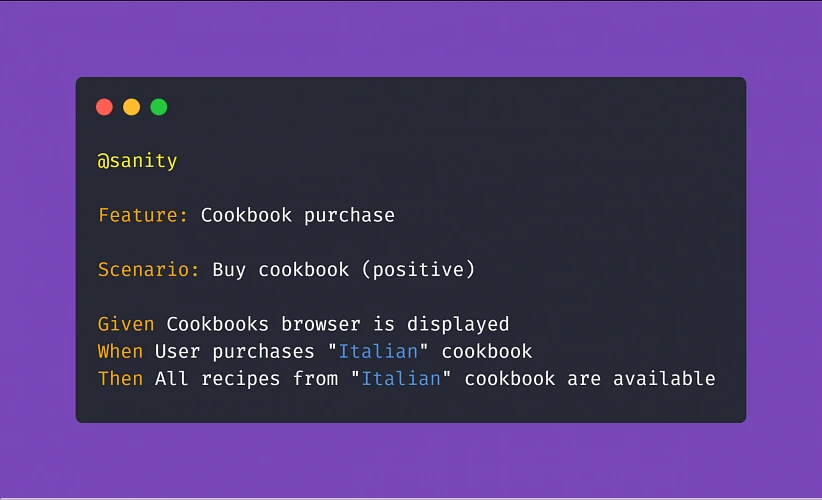
Another example:
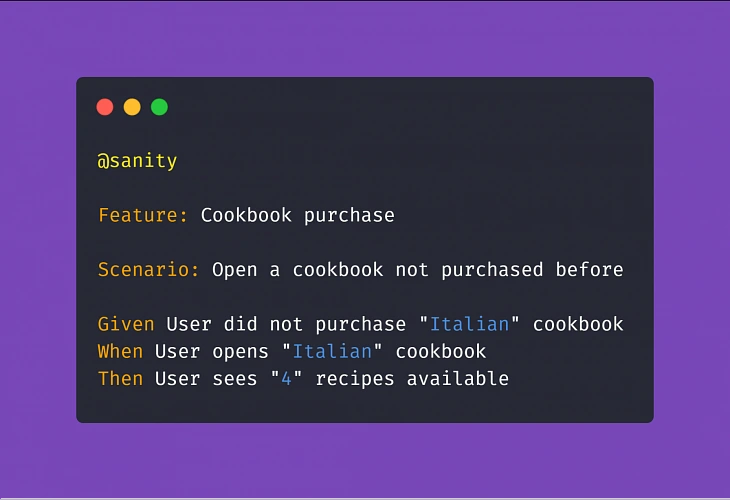
Adopting this approach means less work creating and coding the test steps whenever the implementation of a particular feature changes.
Apart from the main notation of Given/When/Then , Cucumber supports usage of conjunction steps. Using And and But step notations will make the test steps more general and reusable, which results in writing less code and maintaining order within the project. Here is a basic example:
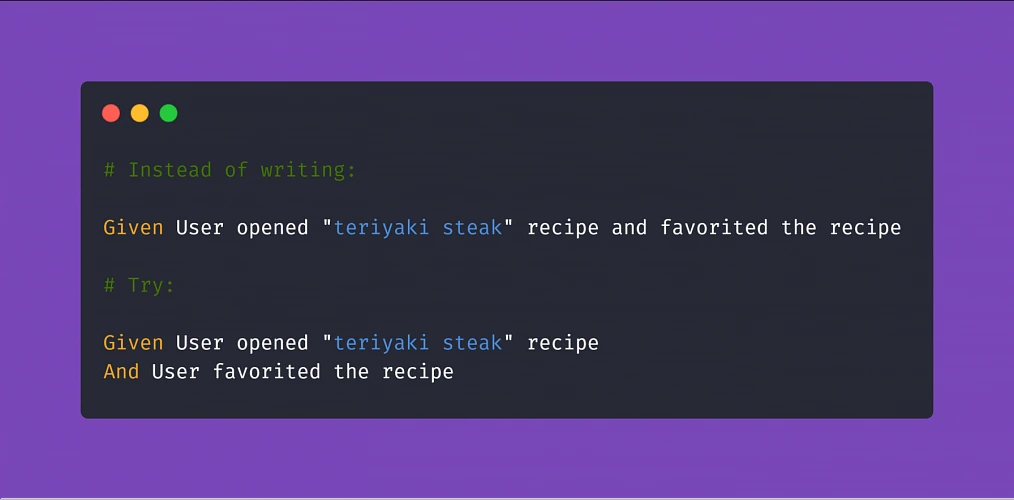
Doing so, if you code the above 'Given' step to locate our recipe element by searching its name, you can reuse it many times just changing the string value in the step (provided that you code the step definition properly later on). On top of that, The 'And' step can be a part of any test scenario that involves such action.
Putting it all together
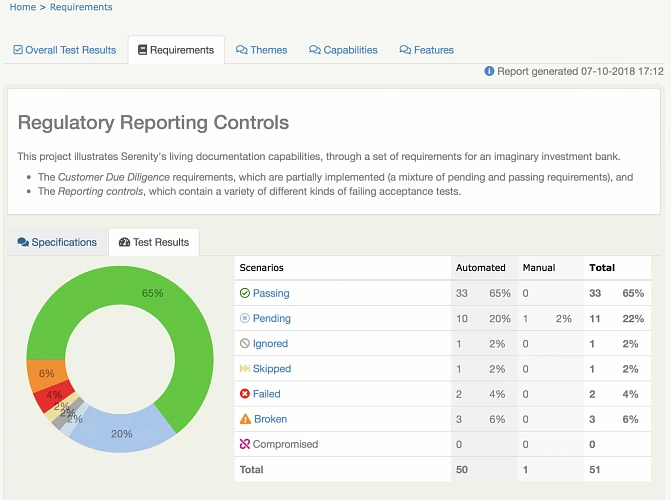
After setting up a project utilizing the practices described above, the most visible parts of using Serenity are the generated test reports. After adopting the @RunWith(CucumberWithSerenity.class) tag in your TestRunner class file, running the test suite will result in Serenity generating an aggregated test results report, which can be useful in evaluating the quality of the app under test and presenting the status of the product to the stakeholders or the development team.
Appium, Cucumber, Serenity - summary
As you can see, the concept of best practices in automation testing can be summarized in three words: reusability, readability, and performance. Reusability means fewer coding, consequently diminishing the time needed to finish the job. Readability improves understanding, which is crucial to ensure that the product does what it needs to do. Finally, performance saves execution time and improves stability. All three contributing not only to the quality of the test automation project but have a significant role in enhancing the overall quality of the delivered app.
Sources:
Should UI testing and API testing go together?
If you have ever worked on writing UI automation tests, you probably came to the point when your test suite is so extensive that it takes a long time to run all the cases. And if the suite keeps on expanding, the situation won't look better. Applications are growing and the number of tests will constantly increase. Luckily, there is a solution to speed up test runs. In this article, we present the advantages of using some help in the form of API testing in the UI test suite, focusing on the aspect of test execution time.
How can API Requests help you?
- Tests will be easier to maintain - UI is constantly changing when API requests are persistent (for the most part)
- You will get immediate tests result from the business logic side
- You can find bugs and solve problems faster and in a more effective way
- You will see a significant improvement in the test execution time
If there are some unwanted issues in the application, we want to be able to discover them as fast as possible. That’s why test execution time is significant in the development cycle. Before we focus on the API requests, first let’s take a small step back and take a look at the test from the UI side only.
Customer path
UI testing is literally the path that the customer is taking through the app, and it is crucial to write automation tests for these workflows. Sometimes we need to repeat the same steps in many feature files (especially if we are taking care of data independence ) and it is not necessary to go over them again on UI side in each test.
Imagine that as a customer you can configure your car through the app. You can start with choosing a basic model and then add some extra equipment for your vehicle. Let’s take a look at this example written in Gherkin:
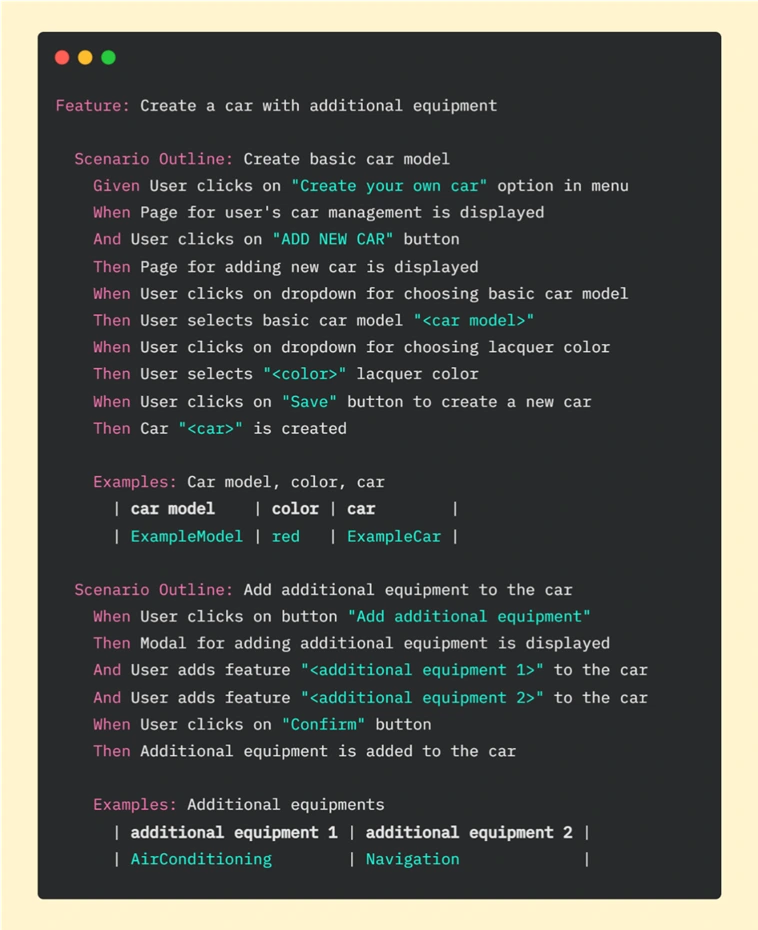
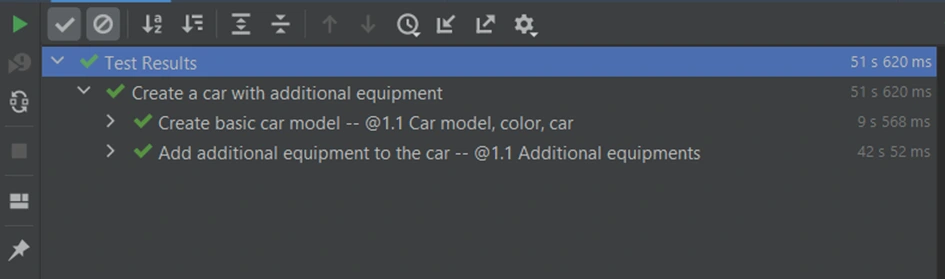
It is basic functionality, so we went through this workflow step by step on the UI side. In this test, we have many components that need to be fully loaded - pages, buttons, modals, and dropdowns. Every action takes some time - loading individual elements and clicking on them. It takes 51.63s. in total to run this scenario in PyCharm:
API enters the stage
Let’s now consider another case. What if customers change their minds about the color of the vehicle or they want to add or delete extra equipment? We need to be able to edit the order. Let's create an additional test for this workflow.
If we want to edit the vehicle, first we need to have one. We can start the Edit car test by creating a new vehicle using all the steps from the previous feature file, but we can also use API help here. Replacing repeatable steps with API requests will allow us to focus on the new functionality on the UI side. Let’s look at the Gherkin file for editing a car:
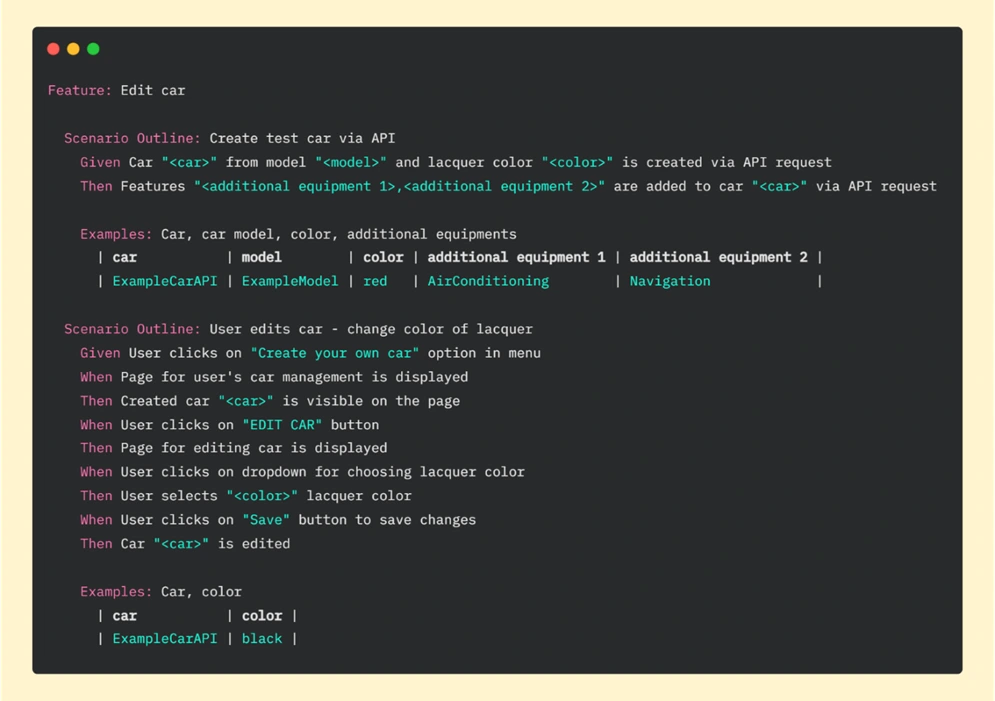
In the first scenario of this feature, we are creating a car (via API) and in the second one editing the vehicle (through UI). In scenario “Create test car via API” we created the same car as in the previous feature “Create a car with additional equipment” , where everything was done on the UI side. If we look at the result now, we can see that the whole test (creating and editing a car) took less than 17 seconds:
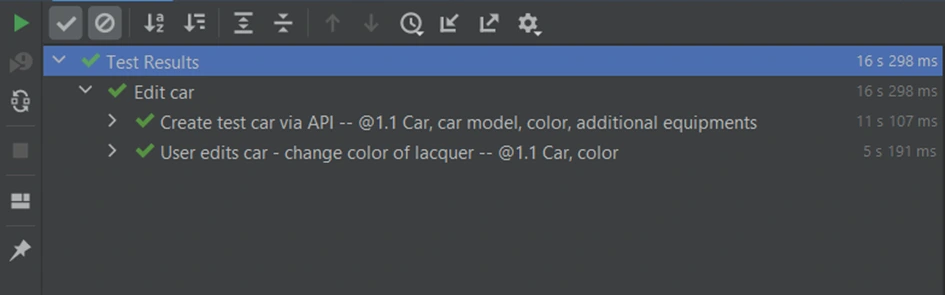
Part for creating a vehicle by API took 11.107 seconds. To run these steps on the UI side we needed more than 50 seconds. To be precise we’ve just saved 40.513 seconds in one test! Imagine that we have another 10 or more tests that need that functionality - it can be a big time saver.
A request for help
Key for benefit from API in UI test suite is to use popular Python library called Requests – it allows us to easily send HTTP requests. Basic POST requests can take the following form:
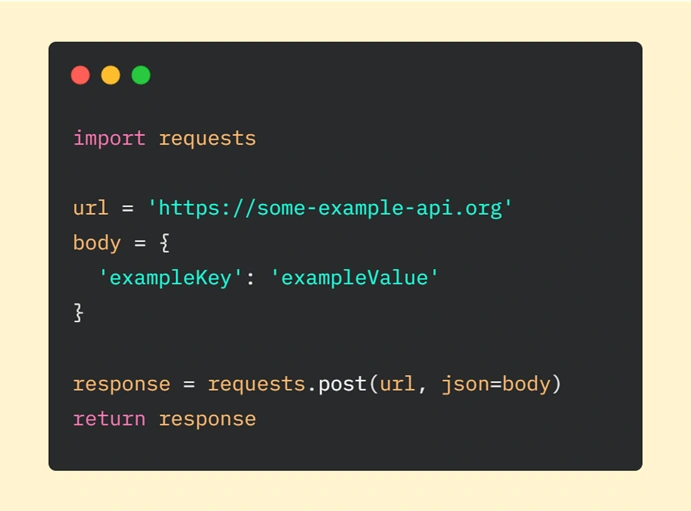
We have to start with importing the ‘requests’ module. Then we are declaring the URL of the request and data we want to send (provided as a dictionary). The next step is to make an HTTP request where we are passing our parameters (url is required, json – optional - it’s a JSON object which will be sent to the mentioned URL). In the end, we are returning the response from the server.
In our car application, this example will be a little expanded. What exactly is hidden behind lines of code responsible for creating a vehicle via API requests? I will focus on the first step of this scenario: 'Car “<car> from the model “<model>” and lacquer color “<color>” is created via API request’ . If we look deeper, we can see step implementation:

And then if we go further to the car_is_created_via_api function, we can analyze requests sent to API:

In car_is_created_via_api method, we are calling function _create_car which is responsible for requesting API. We are also passing parameters: car, model, and color. They will be used in the body of our request.
As in the basic example, in _create_car function we are declaring URL (our car API) and body. Then we are making a POST request and in the final step, we are returning the response.
After getting the response from the server, at the end of the car_is_created_function , we want to use assertion to check if we got the correct status code. Getting code 201 means that everything went as we hoped. Another result will tell us that something is wrong and we will be able to quickly (hopefully) find the gap in the code.
Good Team
We went together through the advantages of using API help in the UI automation tests suite and a comparison of two approaches to testing. We also focused on speeding up tests suite execution time using Python library Requests . We believe that after reading this article you can see that API requests can be great companions and you are encouraged to start using this concept in your test automation projects.
Interested in our services?
Reach out for tailored solutions and expert guidance.