Serverless – Why, When and How?

This is the first article of the mini-series that will get you started with a Serverless architecture and the Function-as-a-Service execution model – whose popularity is constantly growing. In this part, you will get answers to some of the most popular questions regarding Serverless, including: what is it, why it’s worth your attention, how does it work under the hood and which cloud provider meets your needs.
No servers at all?
Not really, your code has to be executed somewhere. Okay, so what is it all about then?
Serverless is a cloud computing execution model in which computer resources are dynamically allocated and managed by a cloud provider of your choice. Among serverless databases, storages, analytic tools, and many others, there is also Function-as-a-Service that we will focus on in this article.
FaaS is a serverless backend service that lets you execute and manage your code without bothering about the infrastructure that used to run your apps on it. In simple terms, you can order a function call without caring about how and where it is performed.
Why?
For money, as Serverless is extremely cost-effective in cases described in the next paragraph. In the serverless cloud execution model, you pay only for used resources, you don’t pay a penny when your code is not being executed!
Moreover, neither actual hardware nor public cloud infrastructure costs a company as much as software engineers’ time. Employees are the most cost-consuming resources. Serverless lets developers focus on functionalities instead of server provisioning, hardening and maintaining infrastructure.
Serverless services scale automatically when needed. You can control their performance by toggling memory and throughput. Furthermore, you don’t have to worry about thunderstorms or any other issues! Serverless services come with built-in high availability and fault tolerance features, meaning your function will be executed even if the primary server has blown up.
When to consider serverless?
Whenever you are preparing a proof of concept or prototyping application… Serverless functions do not generate costs at low workloads and are always ready to deal with the situations they increase. Combining this feature with no server management, it significantly accelerates the delivery of MVP.
When it comes to production, a Serverless architecture fits stateless applications like REST / GraphQL APIs very well. It is much easier, faster and cheaper to get such applications up and running. Services with unpredictable load pikes and inactivity periods, as well as cron jobs (running periodically) are also a great use case examples of FaaS.
Imagine the management of an application for ordering lunch. It has very high load peaks around noon, and it is unused for the rest of the day. Why pay for servers hosting such an application 24 hours a day, instead of paying just for the time when it is really used?
A Serverless architecture is often used for data processing, video streaming and handling IoT events. It is also very handy when it comes to integrating multiple SaaS services. Implementing a facade on top of a running application, for the purpose of migrating it or optimization can also be done much easier using this approach. FaaS is like cable ties and insulating tape in a DIY toolbox.
Where’s the catch?
It would be too good if there weren’t any catches. Technically, you could get a facebook-like application up and running using Serverless services, but it would cost a fortune! It turns out that such a solution would cost thousands of times more than hosting it on regular virtual machines or your own infrastructure. Serverless is also a bad choice for applications using sockets to establish a persistent connection with a server described in Rafal’s article about RSocket. Such a connection would need to be reestablished periodically as Lambda stays warmed-up for about 10 minutes after the last call. In this approach, you would be billed for the time of established connection.
Moreover, your whole solution becomes vendor bound. There are situations when a vendor raises prices, or another cloud provider offers new cool features. It is harder to switch between them, once you have your application up and running. The process takes time, money and the other vendor may not offer all the services that you need.
Furthermore, It is harder to troubleshoot your function, and almost every vendor enforces you to use some additional services to monitor logs from the execution – that generate extra costs. There is also a bit less comfortable FaaS feature that we have to take into account – “Cold start”. From time to time, it makes your function work much longer than usual. Depending on the vendor, there are different constraints on function execution time, which might be exceeded because of it. The following paragraph will explain this FaaS behavior in detail.
How does it work?
It is a kind of a mystery what can we find under the hood of FaaS. There are many services and workers that are responsible for orchestrating function invocations, concurrency management, tracking containers busy and idle states, scheduling incoming invocations appropriately, etc. The technology stack differs between vendors, but the general scheme is the same and you can find it below.

Hypervisor which emulates real devices is the first layer of isolation. The second one consists of containers and OS separation that comes with it. Our code is executed on a sandbox container with an appropriate runtime installed on it. A sandbox is being set up (so-called “Cold start” mentioned above) whenever a function is called for the first time after making changes or hasn’t been invoked for 5 – 15 minutes (depending on the vendor). It means that containers persist between calls, which accelerates execution but is also a bit tricky sometimes. For example, if we choose one of the interpreted languages as a runtime, all invocations are being performed on the same interpreter instance as long as the container lives. That means global variables and context are cached in memory between function executions, so keeping there sensitive data like tokens or passwords is a bad idea.
Containers’ load is balanced similarly to CPU resource allocation, which means they are not loaded equally. The workload is concentrated as much as possible, so runtime consumes the maximum capacity of a container. Thanks to that, other containers in the pool are unused and ready to run another function in the meantime.
Which vendor to pick?
Serverless services are offered by many cloud providers like AWS, GCP, Microsoft Azure, and IBM among others. It’s hard to say which one to choose, as it depends on your needs. The main differences between them are: pricing, maximum execution time, supported runtimes and concurrency. Let’s take a brief look at the comparison below.
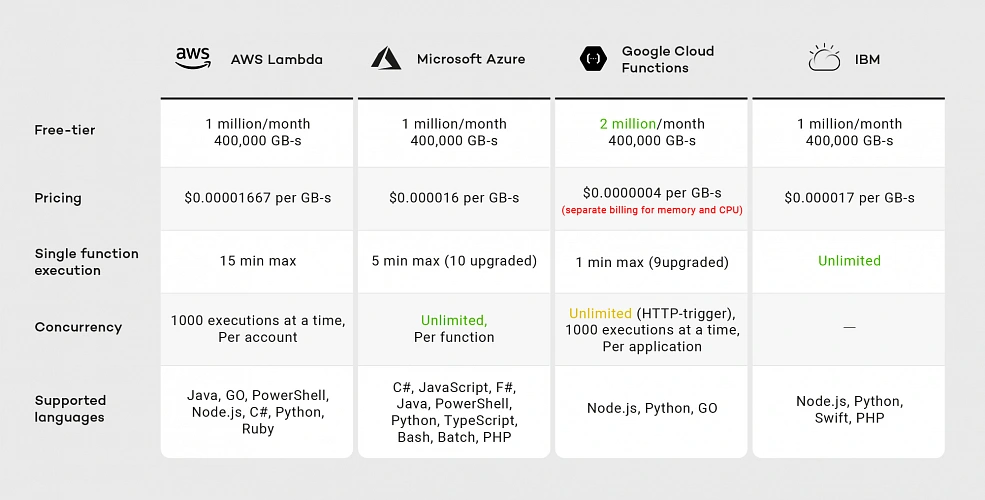
As of the second half of 2019, you can see that all vendors provide similar pricing except Google. Although Google’s free-tier offer seems promising because of the doubled number of free requests, when we exceed this limit, we have two separate billings for memory and CPU, meaning Google’s pricing model is the most expensive.
Considering execution time IBM and AWS Lambda are the best choices. Although IBM has no time limit for single-function execution, it’s concurrency rate remains unclear. IBM documentation does not guarantee that functions will run concurrently. Google provides 1000 executions at a time per project, while AWS provides the same limit per account. That means you can run multiple Google Cloud Functions with the same concurrency, while on AWS you have to divide this limitation between all your functions.
If you look for a wide variety of supported runtimes, AWS and Azure are the best choices. While AWS supported languages list has not changed much since 2014, Google was providing only JavaScript runtime until June 2019. That means AWS runtimes may be more reliable than Google’s.
In the next article in the series, I will focus on AWS, which has a wide range of services that can be integrated with AWS Lambda for the purpose of building more complete applications. Moreover, AWS has a large community around it, which helps when a problem arises.
Summary
In this article, I tried to address the most common questions regarding Serverless architecture and the Function-as-a-Service execution model. I suggested when to use it, and when not to. We took a brief tour of what lays under the hood of FaaS and compared its vendors.
In the next articles, we will explore AWS. I will guide you through Amazon serverless services and help you create your first serverless application using them.
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles


Automating Your Enterprise Infrastructure. Part 1: Introduction to Cloud Infrastructure as Code (AWS Cloud Formation example)
Read the article