Enterprise AI voice agents
Custom AI voice agents that go beyond keyword recognition -they reason over your enterprise data, execute tasks, and adapt in real time. Deployed in the cloud or embedded on-device, built for security, low latency, and seamless integration with your existing systems.

Replace scripted interactions with intelligent voice agents
Automate complex interactions at scale
Handle Tier-1 and Tier-2 customer inquiries that previously required human agents. AI voice agents resolve issues end-to-end - not just route calls - reducing cost-per-contact while maintaining high resolution rates.
Scale to demand without quality trade-offs
Cloud-native architecture handles massive spikes in call volume during peak events without degradation. No seasonal staffing, no hold times, no service gaps.
Own a voice experience built for your business
Unlike off-the-shelf assistants, our voice agents are engineered around your brand guidelines, domain terminology, and compliance requirements - not adapted from a generic template.
Turn conversations into structured insights
Analyze thousands of hours of voice interactions to extract actionable data on customer pain points, product feedback, and operational patterns - insights that stay locked in traditional call center recordings.
Custom AI voice agents designed for mission-critical operations
We combine deep expertise in cloud-native infrastructure with advanced AI engineering to build voice solutions tailored to specific industry contexts. From architecture design through deployment and optimization, every component is engineered for your operational requirements.

LLM-powered conversational intelligence
Voice agents powered by Large Language Models that understand context across conversation turns and reference user history for personalized, coherent interactions.

Enterprise data access via RAG
Agents retrieve answers from your enterprise knowledge base in real time using Retrieval-Augmented Generation, respecting user permissions and data access policies.

Flexible deployment - cloud, edge, or hybrid
Run voice agents in the cloud for global scale, fully embedded on-device for offline capability (e.g., in-car infotainment, aviation systems), or in a hybrid setup combining both.

Autonomous task execution
Beyond conversation, agents trigger APIs to perform actions - booking flights, processing claims, adjusting vehicle settings, updating records - without human handoff.
Key features
Low-latency response
Optimized inference pipelines and speech-to-speech models deliver near-instant responses, making interactions feel natural rather than transactional.
Contextual memory
The agent retains context across conversation turns and references past user history to deliver personalized, coherent interactions.
Dynamic tone adaptation
The system adjusts vocal tone and delivery style based on the situation - a capability unique to voice that text-based LLMs cannot replicate.
Complex tool use
Agents autonomously call APIs and execute multi-step workflows: booking, claims processing, system adjustments, data retrieval - all within the conversation flow.
Enterprise-grade security
Built with strict adherence to data privacy standards (GDPR, SOC2), ensuring sensitive corporate data remains protected throughout every interaction.
Hybrid and edge deployment
Flexible architecture supports cloud, on-device, or hybrid deployment - enabling offline capability for environments where connectivity is limited or latency-critical.
Every conversation is a transaction

In-vehicle voice assistant
Voice agents embedded in vehicle infotainment systems that control settings, provide navigation assistance, and access vehicle diagnostics - running on-device for low latency and offline reliability.

Crew and passenger support
Voice-enabled systems for crew task management, passenger service inquiries, and real-time operational updates — deployed on edge devices where connectivity is limited.

Customer Service automation
AI voice agents handling account inquiries, claims processing, fraud alerts, and transaction support — integrated with core banking systems and compliant with financial regulations.

Intelligent contact center
Enterprise-wide voice automation replacing traditional IVR systems with context-aware agents that resolve issues end-to-end, escalate intelligently, and generate structured interaction data.
Learn how we help our customers tackle their challenges
Explore how we redefine industry standards through innovation.

.jpeg)

Regulate and innovate at the same time? Tell us what's holding you back.
Reach out for tailored solutions and expert guidance.
Insights on AI-driven legacy modernization
Learn more how we found a way to migrate smarter.
Dead code analysis in legacy modernization: What we found in a 654,273-line codebase
On one of our client engagements, we ran a deep dead code analysis against a Java codebase of 654,273 lines. Roughly 275,000 of those lines sat in the business-logic layer that had been auto-translated from COBOL by a previous modernization vendor. After deep static and semantic analysis, we estimated that between 120,000 and 150,000 of those lines would not exist in a hand-written Java equivalent. Nearly half the code carried no semantic weight.
What matters more than the numbers is how we got to them, and why no off-the-shelf static analyzer would have produced the same answer. The ratios here are specific to this particular auto-translated project. Hand-written legacy systems behave very differently. Without structured understanding of the codebase before transformation, none of this would have surfaced, and the modernization plan would have been built around the wrong codebase.
Why understanding comes before transformation
Modernization teams routinely jump from "we have legacy code" to "let's prompt an AI to rewrite it." That approach fails at enterprise scale for a simple reason: the first question is not how do we migrate but what do we actually have.
This is also where the difference between prompt engineering and a modernization workflow becomes concrete. A prompt is a single instruction handed to a model. A workflow is a repeatable, governed sequence of operations with structured inputs, validated outputs, and traceable evidence. Prompts produce snippets. Workflows produce decisions that a CTO can defend in a steering committee.
Before any transformation, you need structured knowledge of the system you're working with: business documentation, dependency maps, architectural reconstruction, static and semantic findings. That knowledge becomes the substrate for every downstream change. Business logic reconstruction and dependency mapping answer what is worth migrating. Dead code analysis answers a related but different question: how much of what you see is actually real?
A transformation pipeline applied to a codebase you don't understand is a parallel waste machine. It will faithfully migrate every dead branch, every ceremonial wrapper, every empty-string initializer into your modern stack. An AI agent asked to migrate tens of thousands of lines of structural boilerplate will produce tens of thousands of lines of structural boilerplate in the target language. The waste survives the transformation. This is also why "can AI agents migrate legacy code reliably?" is the wrong question. Reliability is a property of the workflow surrounding the agent, not of the agent itself.
Two categories of waste
Dead code analysis splits findings into two categories.
Strict dead code is lines whose execution has no observable effect. The IDE will usually flag these.
Translation overhead is lines that are syntactically alive but exist only because a mechanical translator emitted them. The IDE cannot see this because the surface code is well-formed; every statement looks like real work.
Static analysis tools handle the first category. The second is where the volume hides - and where modernization budgets quietly evaporate. Detecting it requires semantic reasoning, codebase-wide context, and pattern recognition that no IDE inspection provides.
The legacy codebase under analysis
The client owned a large back-office system originally written in COBOL. A prior modernization vendor had performed a mechanical COBOL-to-Java translation through a decompilation toolchain. The output Java code compiled and ran in production. There were no automated tests. The only validation performed at the time of translation was manual, and it had happened years before we arrived. By the time the system reached us, nobody on the team could fully describe what the code did - the institutional memory of the translation effort had moved on, and the surface code was opaque enough that no one was confident enough to touch it.
We began with the Understand phase, the first step of our modernization process, focused on reconstructing what the codebase actually does before any migration is scoped. The process runs on G.Tx, Grape Up's agentic platform for enterprise legacy modernization, which models Understand as a set of reusable workflows backed by AI agents, structured context, and engineering governance. The dead code analysis workflow produced the findings the rest of this article is built on.
What static analysis caught
Some of the dead weight was syntactically obvious: indicator-variable boilerplate left over from COBOL host-variable conventions, redundant explicit casts preserved from the bytecode, discarded DAO results, duplicate branches in if-chains, redundant re-initializations of locals. The IDE could see all of it. In this codebase the relevant inspections had been silenced because the warning count was unusable. A finding technically visible to static analysis behaved, in practice, as if it were invisible.
Integer stationOutInd = 0;
// ... no writes anywhere ...
if (stationOutInd != 0) { stationOut = ""; } // always false
Even with the IDE's help, the visible findings explained only a small fraction of the auto-translated layer. The bigger story sat behind what the IDE could not see.
What semantic analysis revealed
The architectural patterns were harder. Each one looked like ordinary Java to an analyzer. Each line allocated, called, or assigned something. The waste was architectural, not syntactic, and only became visible once we looked at the codebase as a whole.
The ValueHolder marshalling dance. Wrapper-class boilerplate emulating COBOL's BY REFERENCE. Every multi-output call became three lines of wrap-call-unwrap, often on the same variable repeatedly:
copyCountHolder = new ValueHolder(Integer.class, (Object) copyCount);
returnCode = printFilter.searchStationCopyCount(
stationPrint, "DOCUMENT_TYPE_A", (ValueHolder<Integer>) copyCountHolder
);
copyCount = (Integer) copyCountHolder.getValue();
In idiomatic Java the same sites collapse to a return value, a record, or a small result class.
Section-global state emulation. COBOL paragraphs share state through working storage, a flat namespace visible to every paragraph. The translator preserved that model by giving each service module its own Context class and turning every former local variable into a context field accessed through a wrapping getter on every term of every expression.
this.getServiceContext().setBrand(this.getServiceContext().getBrandCode());
this.getServiceContext().getInvoice().setBrandCode(this.getServiceContext().getBrand());
The deeper finding came from cross-referencing reads and writes: many context fields were written by exactly one paragraph and read by exactly that same paragraph. They had no business being state at all. They were locals masquerading as state because the translator did not know the difference.
DTO bloat. COBOL PIC X(n) working-storage fields default to spaces, not null. The translator preserved the equivalent by initializing every Java string field to `""`. Every COBOL 01-level record became a Java DTO with one field, one getter, one setter, and one empty-string initializer per string field.
The IDE's redundant-initializer inspection only fires when the explicit value matches the JVM default. "" is not the default for String (which is null), so the inspection treated every empty-string initializer as intentional.
A few smaller patterns followed the same logic: identity assignments via UxRuntime.assign for COBOL MOVE statements that needed no coercion, and UxRuntime.memset calls on Java objects that did nothing. Each was invisible to static analysis because each looked like a real method call.
The same translator habits also produced latent correctness bugs, not just overhead. Methods that take a String parameter and reassign it across dozens of lines (a literal translation of COBOL BY REFERENCE) silently lose every write at return, because Java is pass-by-value for object references:
public void formatLetterMessage(Long period, Long invoiceId, String message) {
// 50+ lines of work, repeatedly reassigning `message`
message = StringUtils.replaceCharAt(message, charPos, ' ');
// method ends — every write is lost
}Elsewhere in the same codebase, the translator used ValueHolder precisely to emulate pass-by-reference correctly. The pattern of forgetting to wrap is the bug. Try/catch blocks that perform conditional database lookups and write a result through a setter, only to be overwritten by an unconditional setter immediately after the block, fall in the same category: dead code at the line level, latent defect at the behaviour level. In a system without automated tests, neither shape had any chance of being noticed.
Aggregate picture of the dead code
In this particular auto-translated codebase, strict dead code accounted for roughly 5–10% of the 275,000-line business-logic layer. Translation overhead accounted for another 35–45%. Together, roughly 45–55% of the auto-translated layer would not exist in a hand-written Java equivalent - between 120,000 and 150,000 lines of code carrying no semantic weight.
The bulk of that volume came from a small number of patterns:
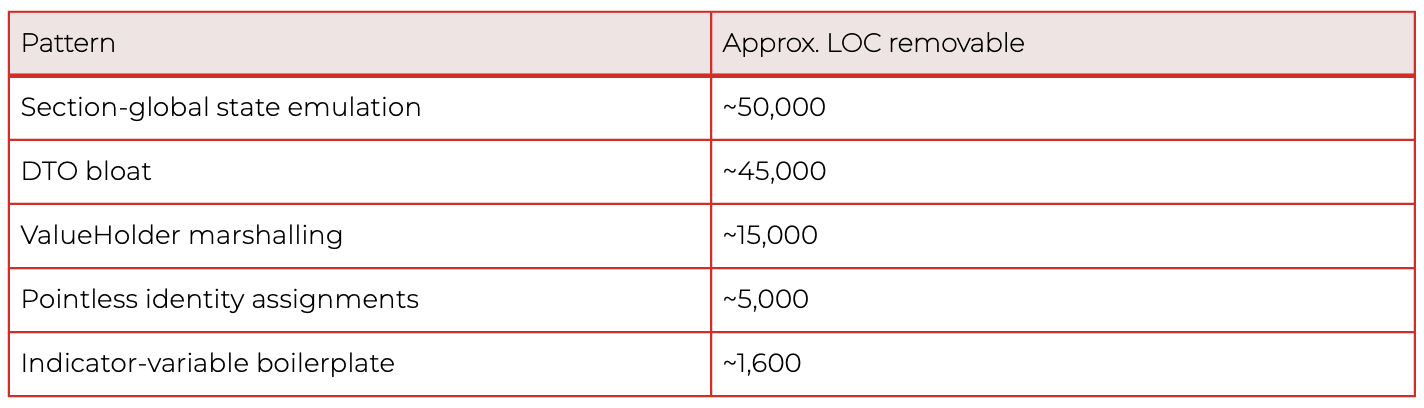
These ratios reflect this specific auto-translated project. Other codebases, especially hand-written legacy systems, distribute their waste very differently. The methodology generalizes; the percentages do not.
In the worst-affected individual methods, 30–50% of the body was dead or boilerplate at the line level. A developer reading those methods was spending up to one line out of every two on mechanical noise before reaching anything that described the actual business behaviour.
Why this changes the modernization conversation
- Migration cost estimation collapses by half when overhead is removed. Quoting "275,000 lines to migrate" anchors the budget. Quoting "approximately 130,000 lines of real logic, plus 145,000 lines of removable overhead" reframes the engagement entirely — both in scope and in sequencing. This is, in concrete terms, the ROI of a feasibility analysis for legacy modernization: half the scope you were about to budget for is not real.
- AI-assisted transformation amplifies whatever you feed it. An agent asked to migrate the ValueHolder dance will faithfully migrate the ValueHolder dance. The Understand phase puts the cleanup before the migration, not after.
- Test generation is more reliable on real code than on boilerplate. Auto-generated tests for dead branches and clobbered setters pass but verify nothing. Understand-phase outputs allow downstream test-generation workflows to skip dead surface area entirely — which matters even more in systems like this one, where no test suite existed and behaviour had to be reconstructed from code rather than from assertions.
- Static analysis alone is insufficient. The IDE saw a small fraction of the problem here. The remaining required semantic analysis aware of the translator's idioms.
- Modernizing in place is a real option. Not every legacy system needs to be rewritten or replatformed. Once dead code and hidden dependencies are mapped, in-place hardening like removing overhead, recovering documentation, restoring testability, is often the higher-ROI path. The decision to migrate, modernize in place, or split the system between the two should follow the analysis, not precede it.
- Human-in-the-loop validation remains mandatory. Several findings were latent correctness bugs hiding behind dead code. Auto-deleting them without engineering review would be reckless. The output of a dead code analysis workflow is a curated, traceable finding set, not a green-light-to-delete list.
How the G.Tx Understand operationalizes this
The dead code analysis workflow produces, for each finding, a classification of what is dead, the location in the codebase, and the rationale explaining why it qualifies as dead. Aggregate counts per classification are available as well, so engineering teams can see both the individual evidence and the overall distribution of waste across the codebase. Every classification is traceable back to source locations or runtime evidence.
And dead code is not only a code-level phenomenon. The same analytical lens applies one layer up: endpoints that no client has called in years, scheduled jobs that nobody remembers writing, service modules whose only consumer was decommissioned long ago, infrastructure quietly burning budget for traffic that no longer exists. Code-level dead code is a maintainability and correctness problem. Functionality-level dead code is a cost and risk problem. Both belonging the Understand phase, because both shape the same decision: what is worth migrating, what is worth hardening in place, and what should simply be turned off.
That last point matters for hallucination control. Models hallucinate when they infer from incomplete context. The artifacts produced during Understand, classified findings, traceable evidence, mapped dependencies, are exactly the grounding downstream agents need during transformation. Hallucination is reduced before any code is touched, because the model has real evidence to work with instead of having to guess at the codebase.
Lessons for legacy modernization
- Quantify before you migrate. The single most valuable artifact in a modernization engagement is a defensible number for real code volume. Without it, every estimate is fiction.
- Auto-translation defers cost; it does not eliminate it. A clean compile is not evidence of a maintainable codebase. In this engagement, half the code was overhead, and the only thing keeping that overhead in production was that nobody was confident enough to touch it. The code was unreadable, undocumented, and unverified. Removing anything felt riskier than leaving everything.
- The IDE is not enough. Roughly 90% of the waste in this codebase was invisible to off-the-shelf static analysis. Semantic, codebase-aware analysis closed the gap.
- Dead code is a correctness signal, not just a hygiene problem. Several of the patterns we found were latent bugs the team did not know they had.
- Modernization is an orchestration problem. No single prompt, agent, or tool produces findings of this kind. It takes reusable workflows, curated context, structured outputs, and disciplined human review.
Modernization decisions made without an Understand phase are decisions made about the wrong codebase. In this engagement, the "wrong codebase" was roughly twice the size of the real one, and the real one was the only one worth migrating.
---
If you suspect your own auto-translated or long-lived legacy system is carrying overhead nobody has measured, the G.Tx Understand phase exists precisely for that conversation. Reach out - we'll start with a focused feasibility analysis for legacy modernization and produce a defensible picture of what you actually have.
Sybase migration to Azure: What nobody tells you before you start
If you’re running Sybase in 2026, you already know the uncomfortable truth: the platform still works, but the ecosystem around it is quietly contracting: SAP patches ASE, yet engineering investment, tooling innovation, and community momentum are all flowing toward HANA and the cloud. ASE gets maintenance. Everything else moves on.
For most IT managers and DBA teams, the question is no longer whether to migrate. It’s how to do it without breaking things that have run reliably for 20 years.
The migration is bigger than “move the database”
When leadership hears “database migration”, they picture moving tables. What’s actually in a Sybase estate looks more like this:
.jpg)
- Database logic - Business logic written in T-SQL or Watcom SQL (SQL Anywhere), deeply embedded across stored procedures, functions and other database structures is the largest workstream.
- Connected applications - Every app querying data, and other Sybase products like IQ, and PowerBuilder. Each carries a distinct risk profile and should be scoped independently.
- Integration layer - CIS federation, proxy tables, driver stacks, ETL pipelines, BI connections: the glue between systems, frequently undocumented.
- Sync and replication - Replication Server is its own infrastructure layer, SQL Anywhere adds niche sync tools like SQL Remote and MobiLink. None of it has a modern equivalent - this requires redesign, not conversion.
- Operations and monitoring - scheduled jobs, alert rules, maintenance, performance monitoring, and backup strategies built on sp_sysmon, mon* tables, Backup Server, and dbcc. The knowledge transfers, the implementation doesn't.
- In-database services - Extended stored procedures, encryption, LOB handling, and in some estates SOAP endpoints or Java-in-DB. Most need external replacements on the target platform.
Where Sybase ASE migrations to Azure break
The most dangerous category isn’t missing features - it’s features that look identical but behave differently across platforms. ASE and SQL Server share a T-SQL lineage, which creates a false sense of safety. The syntax compiles - but the runtime behavior diverges in ways that pass testing and surface under production load. Here are some of the most common examples:
- Transactions: ASE's chained mode and nested transaction semantics differ from both SQL Server and Oracle. Error handling, rollback behavior, and transaction scoping each work differently across all three platforms.
- Identity: ASE isolates @@identity inside stored procedures and triggers. SQL Server's @@identity leaks across scopes, potentially returning wrong values from nested calls.
- Locking: ASE's per-table locking schemes (allpages, datapages, datarows) and lock promotion thresholds have no equivalent on SQL Server or Oracle. Concurrency patterns tuned for ASE risk deadlocks post-cutover.
- LOB access: Data types map cleanly (unitext to nvarchar(max) or NCLOB). The pointer-based access model (readtext, writetext, textptr) does not and must be rewritten.
- NULLs: In Oracle, an empty string is NULL. Code checking for empty strings silently returns wrong results without any error.
- Collation: ASE sets sort order at server level only and defaults to case-sensitive binary. SQL Server and Oracle support multiple collation levels with different defaults, changing JOIN cardinality, GROUP BY grouping, and UNIQUE constraint behavior.
Beyond syntax, cross-database patterns compound the problem: USE, db..object references, and CIS passthrough are everywhere in ASE estates and break the moment the engine changes. Migration tools like Microsoft's SSMA handle syntax conversion, but they don't detect behavioral divergence. The dangerous gaps aren't in what fails to convert - they're in what converts cleanly but runs differently.
The actual risk picture (by the numbers)
A full feature mapping of ASE (versions 15,16) against SQL Server and Oracle on Azure across all deployment tiers gives a clearer picture: (Based on Grape Up G.Tx internal analysis across enterprise migration assessments.)
- ~90% of ASE features have a clear migration path - low or medium risk
- SQL Server carries ~20% fewer high-risk items than Oracle across every ASE version - the shared T-SQL lineage makes a measurable difference
- PowerBuilder pushes the high-risk share to ~19% and should be scoped and phased independently
In ASE alone, roughly 30 features have no direct equivalent or workaround, but every one of those has a modern replacement approach on Azure, although some require significant architectural redesign rather than direct substitution.
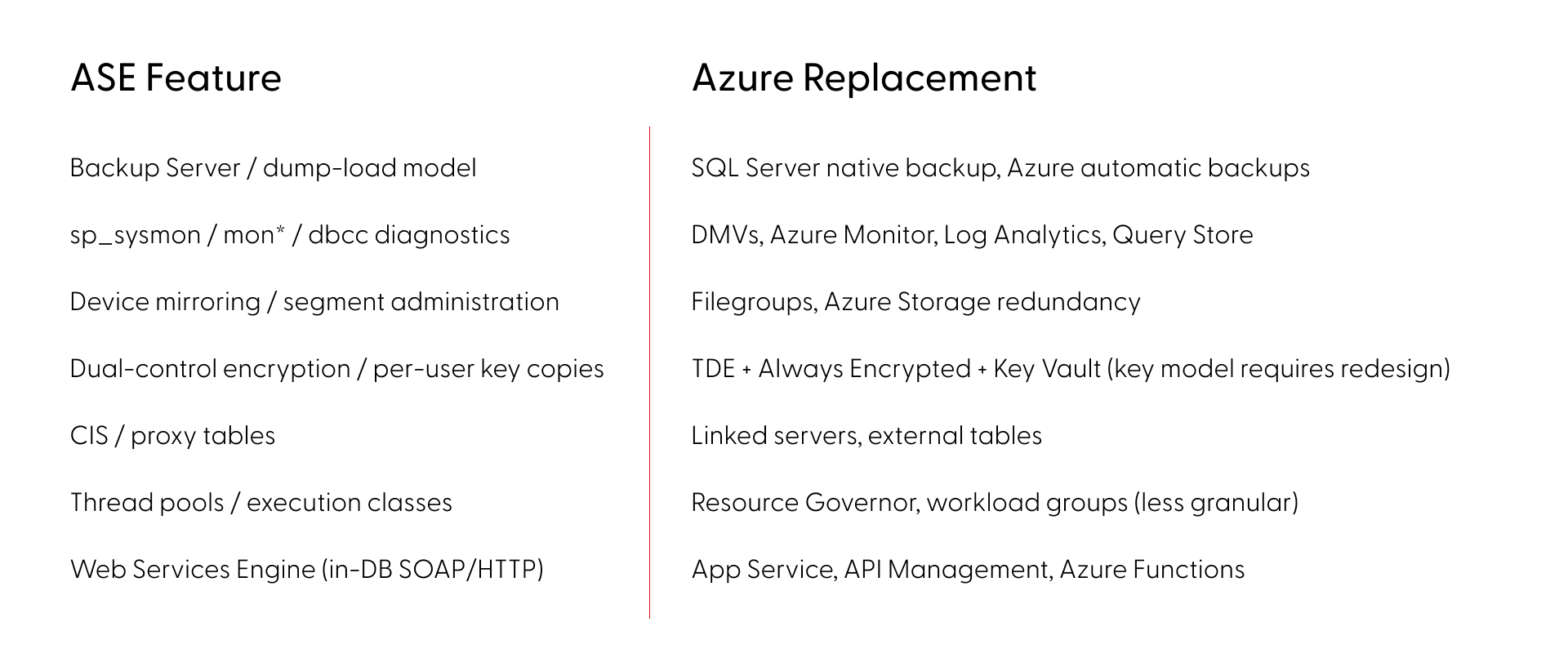
SQL Server or Oracle on Azure - how to choose
The right target depends on what’s actually in your codebase.
SQL Server has the shorter path for most ASE estates. The T-SQL lineage reduces rewrite volume, and the platform carries fewer high-risk items across the board. Thirty years of divergence still mean real work, particularly around transaction semantics and locking behavior.
Oracle carries higher effort by default - PL/SQL vs. T-SQL is a language rewrite, NULL handling differs, and no direct replace for ASE’s nested transaction rollback semantics.
Deployment tier matters too. Azure VM, Managed Instance, and SQL Database each involve different trade-offs on compatibility, operational overhead, and cost. The right answer depends on your specific feature usage.
The operational risk of waiting
The engineers who know the platform deeply - who understand the undocumented behaviors, the operational quirks, the edge cases in the locking model - are retiring. That institutional knowledge compounds the migration effort every year it walks out the door.
Starting your Sybase migration to Azure: assessment before assumptions
A reliable migration starts with knowing exactly what you have. That means automated discovery across your live codebase - versions, features, dependencies, behavioral edge cases - not a manual audit based on what the team remembers.
This is what Grape Up’s G.Tx platform does in the assessment phase. G.Tx runs automated inventory against your environment, maps features against the target platform, identifies behavioral differences that won’t surface in standard testing, and produces a high-level risk report. The same platform then powers execution - code conversion, schema migration, test generation, and validation - so the assessment and the migration run on a single consistent picture of your estate, not on handover documents.
The engagement runs in four phases. Each ends with a deliverable and a client sign-off before the next begins:
- Assessment (1–2 weeks) - free, no commitment. Automated discovery of your system, delivered as a risk report with a next steps recommendation.
- Feasibility (2–4 weeks) - full migration plan with identified blockers, mitigations, and timeline.
- Proof of Concept - a representative subset of your codebase migrated on real data, against agreed acceptance criteria.
- Scale- full migration, AI-accelerated, with phased cutover and operational handover.
You control the pace. Nothing moves to the next phase without your approval.
Frequently Asked Questions: Sybase Migration to Azure
Is migration to another SQL database the only option?
For most estates, a like-for-like migration is the most pragmatic path — it preserves existing logic and minimizes rewrite scope. But depending on your goals and architectural dependencies, a full redesign may be the better long-term investment. This means decomposing the monolithic database into independent components that communicate with each other rather than relying on shared database logic. The result is a more flexible, extensible, and maintainable architecture that is no longer constrained by the boundaries of a single database engine. The best approach can be decided during the Feasibility phase.
What is the best migration target for Sybase ASE - SQL Server or Oracle on Azure?
SQL Server on Azure is the recommended target for most Sybase ASE estates. The shared T-SQL lineage reduces rewrite volume and lowers the share of high-risk migration items by approximately 20% compared to Oracle. Oracle remains viable for estates where PL/SQL integration or Oracle-specific features are already part of the architecture, but it carries higher baseline effort. The final choice depends on your codebase - a G.Tx assessment will map your specific feature usage against both targets before you commit.
How long does a Sybase migration to Azure take?
Timeline depends on estate size and complexity, but the structured phases give reliable checkpoints: Assessment runs 1–2 weeks, Feasibility 2–4 weeks, Proof of Concept varies by scope, and full scale migration is planned during Feasibility. The phased approach is designed to migrate and validate the most business-critical functionality first, progressively offloading the original system only as each phase proves stable on the target platform. Feasibility analysis is the most reliable way to get an accurate estimate for your specific environment.
What are the biggest risks in a Sybase ASE migration?
The highest-risk category is not missing features - it's behavioral divergence: code that converts cleanly but runs differently in production. Transaction semantics, identity scoping, locking behavior, NULL handling in Oracle, and collation defaults are examples of gaps that may not be caught in testing and only surface under real load. Standard migration tools like SSMA automate schema conversion but are not designed to detect behavioral differences. Automated analysis of your codebase can surface these discrepancies early, making sure they never reach production.
Is Sybase ASE still supported in 2026?
SAP ASE 16.0 reached End of Mainstream Maintenance on December 31, 2025, meaning SAP no longer provides new security patches or fixes for this version. ASE 16.1 retains mainstream support until December 31, 2030, giving organizations on that version more runway, but there are no new ASE versions on SAP's roadmap. New capabilities, cloud-native features, and tooling investment are being directed at HANA and cloud products. The surrounding ecosystem is contracting in measurable ways. The practical risk is not that ASE will stop working, but that maintaining it becomes increasingly expensive as the specialist talent pool shrinks, integration tooling is deprecated, and the burden of filling those gaps falls on internal teams — as unpatched vulnerabilities quietly accumulate.
How do Sybase ASE stored procedures migrate to SQL Server?
ASE stored procedures are written in T-SQL, which shares a lineage with SQL Server T-SQL - but decades of platform divergence mean direct conversion is rarely clean. Syntax differences are mostly handled by automated tools. The harder problems are behavioral: code that converts cleanly can still run differently in production, and standard conversion tools are not designed to catch them. Stored procedures rarely exist in isolation — understanding their true migration scope requires analysis in the context of the full system.
What does a Sybase migration assessment include?
An initial assessment covers automated discovery of a representative part of your system — architectural overview, feature usage, stored procedures, connected applications mapped against your target platform. The result is a report covering system health (including security findings), AI transformation feasibility, and top risks ranked by severity and impact — identifying behavioral differences that standard tools miss, with concrete next steps and PoC proposals. Grape Up’s G.Tx Assessment runs in 1–2 weeks, is free with no commitment, and becomes the foundation for all subsequent migration phases.
Challenges of the legacy migration process and best practices to mitigate them
Legacy software is the backbone of many organizations, but as technology advances, these systems can become more of a burden than a benefit. Migrating from a legacy system to a modern solution is a daunting task fraught with challenges, from grappling with outdated code and conflicting stakeholder interests to managing dependencies on third-party vendors and ensuring compliance with stringent regulatory standards.
However, with the right strategies and leveraging advanced technologies like Generative AI, these challenges can be effectively mitigated.
Challenge #1: Limited knowledge of the legacy solution
The average lifespan of business software can vary widely depending on several factors, such as the type of software or the industry it serves. Nevertheless, no matter if the software is 5 or 25 years old, it is highly possible its creators and subject matter experts are not accessible anymore (or they barely remember what they built and how it really works), the documentation is incomplete, the code messy and the technology forgotten a long time ago.
Lack of knowledge of the legacy solution not only blocks its further development and maintenance but also negatively affects its migration – it significantly slows down the analysis and replacement process.
Mitigation:
The only way to understand what kind of functionality, processes and dependencies are covered by the legacy software and what really needs to get migrated is in-depth analysis. An extensive discovery phase initiating every migration project should cover:
- interviews with the key users and knowledge keepers,
- observations of the employees and daily operations performed within the system,
- study of all the available documentation and resources,
- source code examination.
The discovery phase, although long (and boring!), demanding, and very costly, is crucial for the migration project’s success. Therefore, it is not recommended to give in to the temptation to take any shortcuts there.
At Grape Up , we do not. We make sure we learn the legacy software in detail, optimizing the analytical efforts at the same time. We support the discovery process by leveraging Generative AI tools . They help us to understand the legacy spaghetti code, forgotten purpose, dependencies, and limitations. GenAI enables us to make use of existing incomplete documentation or to go through technologies that nobody has expertise in anymore. This approach significantly speeds the discovery phase up, making it smoother and more efficient.
Challenge #2: Blurry idea of the target solution & conflicting interests
Unfortunately, understanding the legacy software and having a complete idea of the target replacement are two separate things. A decision to build a new solution, especially in a corporate environment, usually encourages multiple stakeholders (representing different groups of interests) to promote their visions and ideas. Often conflicting, to be precise.
This nonlinear stream of contradicting requirements leads to an uncontrollable growth of the product backlog, which becomes extremely difficult to manage and prioritize. In consequence, efficient decision-making (essential for the product’s success) is barely possible.
Mitigation:
A strong Product Management community with a single product leader - empowered to make decisions and respected by the entire organization – is the key factor here. If combined with a matching delivery model (which may vary depending on a product & project specifics), it sets the goals and frames for the mission and guides its crew.
For huge legacy migration projects with a blurry scope, requiring constant validation and prioritization, an Agile-based, continuous discovery & delivery process is the only possible way to go. With a flexible product roadmap (adjusted on the fly), both creative and development teams work simultaneously, and regular feedback loops are established.
High pressure from the stakeholders always makes the Product Leader’s job difficult. Bold scope decisions become easier when MVP/MDP (Minimum Viable / Desirable Product) approach & MoSCoW (must-have, should-have, could-have, and won't-have, or will not have right now) prioritization technique are in place.
At Grape Up, we assist our clients with establishing and maintaining efficient product & project governance, supporting the in-house management team with our experienced consultants such as Business Analysts, Scrum Masters, Project Managers, or Proxy Product Owners.
Challenge #3: Strategical decisions impacting the future
Migrating the legacy software gives the organization a unique opportunity to sunset outdated technologies, remove all the infrastructural pain points, reach out for modern solutions, and sketch a completely new architecture.
However, these are very heavy decisions. They must not only address the current needs but also be adaptable to future growth. Wrong choices can result in technical debt, forcing another costly migration – much sooner than planned.
Mitigation:
A careful evaluation of the current and future needs is a good starting point for drafting the first technical roadmap and architecture. Conducting a SWOT analysis (Strengths, Weaknesses, Opportunities, Threats) for potential technologies and infrastructural choices provides a balanced view, helping to identify the most suitable options that align with the organization's long-term plan. For Grape Up, one of the key aspects of such an analysis is always industry trends.
Another crucial factor that supports this difficult decision-making process is maintaining technical documentation through Architectural Decision Records (ADRs). ADRs capture the rationale behind key decisions, ensuring that all stakeholders understand the choices made regarding technologies, frameworks, or architectures. This documentation serves as a valuable reference for future decisions and discussions, helping to avoid repeating past mistakes or unnecessary changes (e.g. when a new architect joins the team and pushes for his own technical preferences).

Challenge #4: Dependencies and legacy 3 rd parties
When migrating from a legacy system, one of the significant challenges is managing dependencies with numerous other applications and services which are integrated with the old solution, and need to remain connected with the new one. Many of these are often provided by third-party vendors that may not be willing or able to quickly respond to our project’s needs and adapt to any changes, posing a significant risk to the migration process. Unfortunately, some of the dependencies are likely to be hidden and spotted not early enough, affecting the project’s budget and timeline.
Mitigation:
To mitigate this risk, it's essential to establish strong governance over third-party relationships before the project really begins. This includes forming solid partnerships and ensuring that clear contracts are in place, detailing the rules of cooperation and responsibilities. Prioritizing demands related to third-party integrations (such as API modifications, providing test environments, SLA, etc.), testing the connections early, and building time buffers into the migration plan are also crucial steps to reduce the impact of potential delays or issues.
Furthermore, leveraging Generative AI, which Grape Up does when migrating the legacy solution, can be a powerful tool in identifying and analyzing the complexities of these dependencies. Our consultants can also help to spot potential risks and suggest strategies to minimize disruptions, ensuring that third-party systems continue to function seamlessly during and after the migration.
Challenge #5: Lack of experience and sufficient resources
A legacy migration requires expertise and resources that most organizations lack internally. It is 100% natural. These kinds of tasks occur rarely; therefore, in most cases, owning a huge in-house IT department would be irrational.
Without prior experience in legacy migrations, internal teams may struggle with project initiation; for that reason, external support becomes necessary. Unfortunately, quite often, the involvement of vendors and contractors results in new challenges for the company by increasing its vulnerability (e.g., becoming dependent on externals, having data protection issues, etc.).
Mitigation:
To boost insufficient internal capabilities, it's essential to partner with experienced and trusted vendors who have a proven track record in legacy migrations. Their expertise can help navigate the complexities of the process while ensuring best practices are followed.
However, it's recommended to maintain a balance between internal and external resources to keep control over the project and avoid over-reliance on external parties. Involving multiple vendors can diversify the risk and prevent dependency on a single provider.
By leveraging Generative AI, Grape Up manages to optimize resource use, reducing the amount of manual work that consultants and developers do when migrating the legacy software. With a smaller external headcount involved, it is much easier for organizations to manage their projects and keep a healthy balance between their own resources and their partners.
Challenge #6: Budget and time pressure
Due to their size, complexity, and importance for the business, budget constraints and time pressure are always common challenges for legacy migration projects. Resources are typically insufficient to cover all the requirements (that keep on growing), unexpected expenses (that always pop up), and the need to meet hard deadlines. These pressures can result in compromised quality, incomplete migrations, or even the entire project’s failure if not managed effectively.
Mitigation:
Those are the other challenges where strong governance and effective product ownership would be helpful. Implementing an iterative approach with a focus on delivering an MVP (Minimum Viable Product) or MDP (Minimum Desirable Product) can help prioritize essential features and manage scope within the available budget and time.
For tracking convenience, it is useful to budget each feature or part of the system separately. It’s also important to build realistic time and financial buffers and continuously update estimates as the project progresses to account for unforeseen issues. There are multiple quick and sufficient (called “magic”) estimation methods that your team may use for that purpose, such as silent grouping.
As stated before, at Grape Up, we use Generative AI to reduce the workload on teams by analyzing the old solution and generating significant parts of the new one automatically. This helps to keep the project on track, even under tight budget and time constraints.
Challenge #7: Demanding validation process
A critical but typically disregarded and forgotten aspect of legacy migration is ensuring the new system meets not only all the business demands but also compliance, security, performance, and accessibility requirements. What if some of the implemented features appear to be illegal? Or our new system lets only a few concurrent users log in?
Without proper planning and continuous validation, these non-functional requirements can become major issues shortly before or after the release, putting the entire project at risk.
Mitigation:
Implementation of comprehensive validation, monitoring, and testing strategies from the project's early stages is a must. This should encompass both functional and non-functional requirements to ensure all aspects of the system are covered.
Efficient validation processes must not be a one-time activity but rather a regular occurrence. It also needs to involve a broad range of stakeholders and experts, such as:
- representatives of different user groups (to verify if the system covers all the critical business functions and is adjusted to their specific needs – e.g. accessibility-related),
- the legal department (to examine whether all the planned features are legally compliant),
- quality assurance experts (to continuously perform all the necessary tests, including security and performance testing).
Prioritizing non-functional requirements, such as performance and security, is essential to prevent potential issues from undermining the project’s success. For each legacy migration, there are also individual, very project-specific dimensions of validation. At Grape Up, during the discovery phase our analysts empowered by GenAI take their time to recognize all the critical aspects of the new solution’s quality, proposing the right thresholds, testing tools, and validation methods.
Challenge #8: Data migration & rollout strategy
Migrating data from a legacy system is one of the most challenging tasks of a migration project, particularly when dealing with vast amounts of historical data accumulated over many years. It is complex and costly, requiring meticulous planning to avoid data loss, corruption, or inconsistency.
Additionally, the release of the new system can have a significant impact on customers, especially if not handled smoothly. The risk of encountering unforeseen issues during the rollout phase is high, which can lead to extended downtime, customer dissatisfaction, and a prolonged stabilization period.
Mitigation:
Firstly, it is essential to establish comprehensive data migration and rollout strategies early in the project. Perhaps migrating all historical data is not necessary? Selective migration can significantly reduce the complexity, cost, and time involved.
A base plan for the rollout is equally important to minimize customer impact. This includes careful scheduling of releases, thorough testing in staging environments that closely mimic production, and phased rollouts that allow for gradual transition rather than a big-bang approach.
At Grape Up, we strongly recommend investing in Continuous Integration and Continuous Delivery (CI/CD) pipelines that can streamline the release process, enabling automated testing, deployment, and quick iterations. Test automation ensures that any changes or fixes (that are always numerous when rolling out) are rapidly validated, reducing the risk of introducing new issues during subsequent releases.
Post-release, a hypercare phase is crucial to provide dedicated support and rapid response to any problems that arise. It involves close monitoring of the system’s performance, user feedback, and quick deployment of fixes as needed. By having a hypercare plan in place, the organization can ensure that any issues are addressed promptly, reducing the overall impact on customers and business operations.
Summary
Legacy migration is undoubtedly a complex and challenging process, but with careful planning, strong governance, and the right blend of internal and external expertise, it can be navigated successfully. By prioritizing critical aspects such as in-depth analysis, strategic decision-making, and robust validation processes, organizations can mitigate the risks involved and avoid common pitfalls.
Managing budgets and expenses effectively is crucial, as unforeseen costs can quickly escalate. Leveraging advanced technologies like Generative AI not only enhances the efficiency and accuracy of the migration process but also helps control costs by streamlining tasks and reducing the overall burden on resources.
At Grape Up, we understand the intricacies of legacy migration and are committed to helping our clients transition smoothly to modern solutions that support future growth and innovation. With the right strategies in place, your organization can move beyond the limitations of legacy systems, achieving a successful migration within budget while embracing a future of improved performance, scalability, and flexibility.