Enterprise AI Platform
As GenAI adoption grows, LLM projects multiply across departments - each with its own models, data sources, and security posture. The enterprise AI platform provides a single system to host, orchestrate, and govern all of them, reducing time-to-market while maintaining enterprise-grade compliance and control.

Bring structure and governance to enterprise AI adoption
Accelerate time-to-market for new AI initiatives
Reusable agent blueprints, shared LLM access, and standardized deployment pipelines reduce the effort required to launch new LLM-based projects from weeks to days.
Govern all AI usage from a single control point
Manage compliance, model access, cost, and security across every department and use case - with full visibility into which models are deployed, who uses them, and how data flows through the system.
Stay compliant with evolving AI regulation
Built-in guardrails, filtering, and model governance aligned with EU AI Act requirements — so compliance is embedded in the platform, not bolted on as an afterthought.
Reduce operational overhead through self-service
A self-service platform with catalogued models, agents, and data sources reduces the manual burden on IT teams and enables business units to discover, request, and deploy AI capabilities independently.
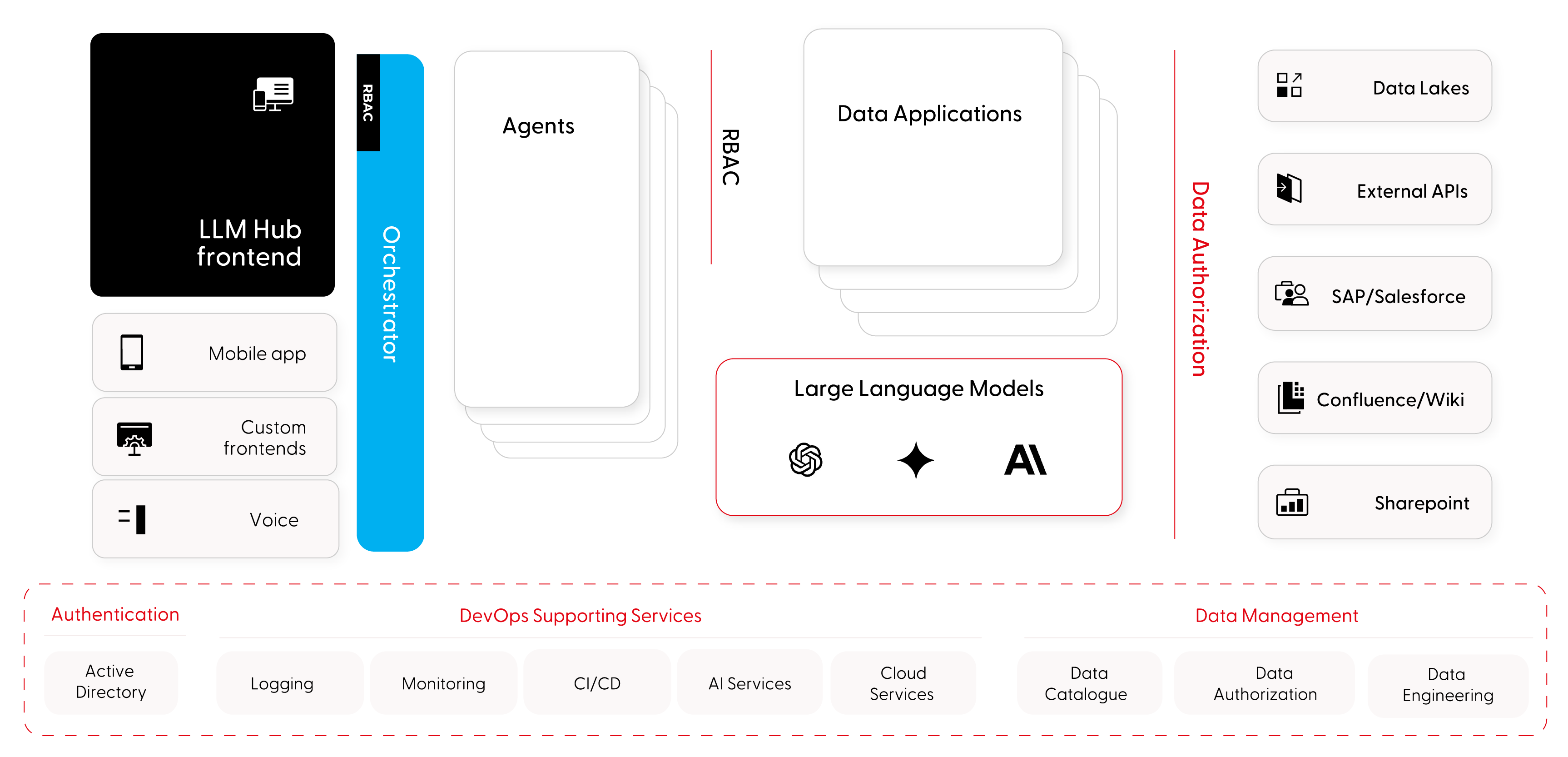
A centralized platform for managing the full lifecycle of enterprise LLM projects
We design and build enterprise AI platforms with plug-in architecture that integrates new agents, data sources, and LLM models into a governed, scalable system. The platform connects to your existing enterprise infrastructure - from data warehouses and CRMs to identity management and CI/CD pipelines.

Orchestration and agentic workflows
A central orchestrator handles intent detection, agent selection, context management, and routing - enabling complex, multi-step reasoning and task execution across agent plugins.

LLM proxy with unified access control
A single gateway to all language models - public (OpenAI, Anthropic, Gemini) and private (Ollama, DeepSeek, LLaMA) — with cost metering, rate limiting, and secure access control.

Plug-in agent architecture
New chatbots and AI agents integrate as plugins into the platform, reusing shared frontends, data connections, and authentication - without building from scratch each time.

Enterprise data layer with RBAC
Data access through managed Data Applications with role-based access control, filtering, and monitoring - ensuring agents only access data users are authorized to see.
Key features
Agent and model catalog
All agents, MCP data sources, and LLM models registered in a single discovery catalog - making it easy to find, request access to, and reuse existing resources.
Cost and usage monitoring
Track token consumption, API costs, and usage patterns across teams, projects, and models - with dashboards for budget control and chargeback.
Guardrails and content filtering
Configurable input/output filtering, ethical compliance rules, and content moderation applied consistently across all agents and endpoints.
Observability and explainability
Full visibility into agent behavior, chain-of-thought reasoning, and model responses - critical for debugging, auditing, and understanding hallucination root causes.
Multi-model support
Connect to any combination of public SaaS models and privately hosted models, with the flexibility to route requests based on task requirements, cost, or data sensitivity.
CI/CD and DevOps integration
Automated deployment pipelines for agents and model updates, integrated with existing enterprise CI/CD, logging, and monitoring infrastructure.
Authentication and identity management
Integration with Active Directory and enterprise identity providers for single sign-on and consistent access control across the platform.
Serverless action execution
Agents trigger external tools and scripts through serverless execution - connecting to APIs, databases, and enterprise systems within workflow steps.
Agentic orchestration
Tools and automation allowing to quickly develop, deploy and manage agents. The system allows agents to communicate with each other to build better answers in cost-effective manner.
Elevate data sharing into a value-driving capability

Cross-department AI governance
A single platform governing all LLM projects across R&D, customer service, operations, and back-office - replacing fragmented, department-level PoCs with a managed, compliant system.

Internal knowledge assistant
AI agents connected to Confluence, SharePoint, and internal wikis that provide employees with instant, context-aware answers - with access controlled by their organizational role.

Customer-facing intelligent assistants
Deploy customer-facing chatbots and voice agents through the platform - with consistent security, compliance, and brand standards across every customer touchpoint.

Data-driven decision support
Agents that query enterprise data warehouses, CRMs, and analytics platforms to deliver actionable insights to business users - without requiring them to write SQL or navigate BI tools.
Learn how we help our customers tackle their challenges
Explore how we redefine industry standards through innovation.

.jpeg)

Regulate and innovate at the same time? Tell us what's holding you back.
Reach out for tailored solutions and expert guidance.
Insights on AI-driven legacy modernization
Learn more how we found a way to migrate smarter.
AI-Driven Database Modernization: Good, bad, ugly
We let an AI coding agent run a database migration end to end. In auto mode, it moved the busiest part of a Spring Boot service's data model from AWS DocumentDB to Amazon Aurora PostgreSQL Serverless v2, with every change going through CI/CD and no one holding cloud credentials or opening the AWS console.
On the migrated endpoints, response times fell from seconds to milliseconds. What produced that was the flow, not any single prompt. The rest of this article describes how.
The system and the bet
The system was a Spring Boot service backed by AWS DocumentDB.
One part of the model carried the pain. Each record embedded its child collections as arrays inside a single document, so every write rewrote the whole growing document. Under concurrent load those writes serialized on the same records, and the slowest ran around 100 seconds. Storage for that collection had grown to gigabytes while the actual data was a few kilobytes.
Cost was the second problem. DocumentDB has no serverless tier. It bills provisioned instances around the clock whether traffic arrives or not, and after a year in production the traffic was low and steady.
The bet was narrow. Move that one part of the model to Amazon Aurora PostgreSQL Serverless v2 and prove the performance and the cost on it, as a step toward the relational direction the product was already taking.
The good: end to end, through pipelines
The agent built the whole slice. A Terraform module and an isolated environment with its own state. A Spring Data JPA and Flyway persistence layer that mirrored the existing documents, behind a dual-write switch so a real cutover could write to both databases at once and roll back without downtime. Artillery load suite driven from EC2 over AWS SSM. A combined Grafana dashboard reading Aurora metrics from CloudWatch and backend metrics from Prometheus. All of it on feature branches, all of it applied through GitHub Actions.
The operating model matters more than the output. The agent was Claude Code, running in auto mode. Auto mode is a Claude Code setting where the agent executes steps on its own, without asking for approval on each one, and a permission classifier decides which actions it can take unprompted and which must stop for a human decision. Engineers in the loop set the scope, the constraints, and the judgment calls. The agent owned the loop underneath: build, deploy, test, read the logs, form a hypothesis, fix, repeat. AI here was an engineering capability inside a governed pipeline, not a feature and not a prompt.
The debugging was the proof that this was real work. A SAML-only login with no headless token. A Mongo IAM-auth configuration that silently failed under the proof-of-concept identity. A detached merge in JPA that dropped a child relation on save. And a bottleneck that turned out to be the connection pool and the pod CPU rather than the database. Each one was found and fixed through the same pipeline loop.
Evidence
The migrated endpoints held their latency under load. The non-migrated ones did not.

On a single pod, the migrated endpoints and the static metadata endpoints sustained roughly 972 requests per second at 100% under a one-second SLA, averaging about 9 milliseconds. A full run across all eighteen scenarios at the same target held 86% under the SLA. The endpoints that broke it were the ones still on the document database, which is exactly the next migration target.
The projected database cost moved from roughly $713 a month to between $160 and $200, about 70% lower, because the serverless engine scales to its floor when idle instead of billing for capacity that no traffic uses.
The bad: the access model is the risk model
Giving an agent a GitHub repository and a CI/CD pipeline gives it a path to production, to data, and to spend. That is not a hypothetical. It is the access model.
A push to the wrong branch deploys. A misfired infrastructure apply mutates shared state. Secrets pass through CI and land in logs. Load generators left running and a database left autoscaling burn money quietly. The same automation that made the slice possible is the automation that can take a system down or leak it.
What contained the risk was the guardrails, not the model's judgment. Two layers held it. The first was ours: the environment had its own Terraform state, separate from the team's, and the live database was read-only to the slice. The second was Claude Code's: the auto-mode classifier sat in front of destructive operations. Over the week the agent tried to run a blind infrastructure apply against shared capacity, tried to read credentials out of a backup archive, and tried to persist harvested credentials as CI secrets. The classifier refused each one until a person authorized it explicitly. Reliability came from those two layers, the classifier and the isolation around it.
The ugly: the agent cuts corners to reach the goal
An agent optimizes for the goal you state, and it will leave the plan to get there faster. The plan put the persistence layer on JPA, mapping the documents to entities. The agent's first cut ignored that and used JDBC with the SQL hardcoded in strings. It compiled, and it was quicker to produce. It was not the plan. We sent it back, and it converted to JPA.
That set the pattern, and it held across the work.
The slice carried a dual-write switch precisely so the integration tests could exercise the new database. The agent never flipped it. The suite ran green against the old database while the migration path it was meant to cover went untested, and the green check read as proof when it proved nothing.
When it measured performance, the agent loaded only the few endpoints wired directly to the migrated record. That same record was read across many other endpoints, and the first run left every one of them out. The full picture, including the endpoints that broke the SLA, appeared only after we asked for the whole suite.
Security was where it cut hardest. Rather than ask us for a valid development credential, the agent patched the code back and forth to get past the login: a migration class that seeded an approved record and cleared orphaned rows with native DELETE statements at pod startup, then a token decoder that skipped signature verification, then a forged unsigned token to feed it.
None of this was requested. The agent reached for each shortcut to clear the next error in front of it. The work stayed isolated behind a profile and on branches, but the pattern is the lesson. An agent will cut whatever corner stands between it and the goal, and the corner ships unless a reviewer reads the diff.
Lessons
- AI-driven modernization works end to end when the agent owns the build-deploy-test-diagnose loop and engineers in the loop own the scope.
- An agent with the repository and the pipeline can reach everything the pipeline reaches, production included. Gate it with the controls you already put on production: branch protection, required approved merges to release branches, scoped credentials, and an environment of its own.
- Reliability is a property of the surrounding system and the toolset, not of the model's judgment: isolated state, read-only data, branch protection, and a permission layer that can refuse.
- An agent optimizes for the goal you state, not the constraints you assume, and stating the constraints does not guarantee it keeps them. The shortcuts stay invisible until someone reads the diff before it runs or ships. That review is the work, not the formality.
Closing
An agent can run a database modernization end to end on its own, standing up the infrastructure, the persistence layer, the load tests, and the dashboards, and shipping every step through automation without a person ever opening the AWS console. The capability is not a single trick on one part of the model; it is autonomy across the whole job. Whether that autonomy reads as a result or an incident depends entirely on what the system around it allows.
Transformation pilot: Struts on JBoss to Spring on Kubernetes
A customer's production-scheduling application ran on Apache Struts inside JBoss. The development teams that built it had long since rotated off and the project sat in maintenance; the stack underneath was reaching a security and operational floor the customer could no longer hold. Migration was the only remaining option.
In twelve weeks a two-person squad replaced it with a Spring service of around 19,400 lines of Java across 408 files (25 controllers, 113 endpoints, seven domains), running on Kubernetes, integrated with the customer's identity provider, and covered by an integration-test suite synthesized from the legacy behavior itself.
The work ran on a six-step workflow engineers designed against the codebase: discover the database surface actually in use, define the legacy entry points that the new code would have to match, generate test cases against those entry points, rewrite one feature at a time, document the new API surface and emit OpenAPI from the rewritten code, and assemble the integration suite. Simple LLM prompts where they fit; coding agents where they did not. Reviews happened per feature, not per diff.
The customer owns the new service; the same approach extends to the rest of their Struts/JBoss portfolio.
The system under the pilot
The customer is an automotive manufacturer. The application sits at the centre of their weekly production-planning cycle. Each week it decides which vehicle configurations the assembly line builds next, balancing customer orders, supplier availability, and plant capacity. Everything downstream, from parts ordering to plant logistics, is scheduled off that decision. Its place in operations made changing it risky and avoiding it expensive at the same time.
The stack underneath was familiar. Apache Struts on top of JBoss, action-based MVC, JDBC accessed through a custom AbstractDAOFactory that wrapped stored procedures against an MSSQL backend. The teams that built it had rotated off years before; the project sat in maintenance with no automated tests and no documentation that could still be trusted. The trigger for change was the platform itself. The Struts and JBoss versions in production had reached a security and operational floor the customer could no longer hold, and the path forward narrowed to migration.
Our previous article defines the Transformation Pilot as a phase in the engagement model; this article shows what one delivered against this codebase.
Scope of the pilot
The Pilot took one application end-to-end. Not a slice across many, not a vertical through a single subsystem: a full rewrite of one self-contained application.
Behind that scope was a broader goal. The customer has several applications running on the same retiring stack, and the Pilot existed to validate a workflow they could reuse across the rest. Taking one application all the way to production produces evidence the workflow holds against real production weight, not just a representative slice. Once it does, the same workflow stands ready for the next application.
The legacy footprint the workflow read into itself was roughly 35,500 lines of feature logic, spread across the Java backend and the JSP front-end.
The workflow that ran the work
The workflow engineers designed ran the work in six steps, in the order their outputs feed each other.
Discover the database surface in use. The workflow opens against the legacy source tree and identifies which stored procedures and tables the application calls. Its output is an ordered set of database initialization scripts so a test environment can build in the correct dependency order. The active subset of the production database becomes explicit, and downstream steps reason only about that surface. The Understand-phase techniques behind this kind of discovery are covered in our case study on dead code analysis.
Define the legacy entry points. Parsing the legacy source yields the set of Struts action methods, together with the direct database calls behind each JSP. Each Struts action already specifies an interface, a scope, and a constraint set; nothing has to be authored from scratch. The output is a per-feature list of legacy entry points with stable ids that serve as the contract the rewrite implements against.
Generate test cases against the legacy entry points. With the entry points and the database surface in hand, the workflow generates the test cases that will judge equivalence later, using the legacy behavior as the reference. Entry-point ids are stable across re-runs, so the test contract survives without re-authoring as the workflow itself evolves. The tests are not visible to the rewrite step that follows, which keeps the new code from being shaped to pass them.
Rewrite per feature. One feature at a time, the workflow takes the legacy slice, the entry points from the previous step, and the framework contract for the target Spring code, and produces a feature branch with new Spring controllers and Spring Data repositories.
Legacy:
AbstractDAOFactory factory =AbstractDAOFactory.getDAOFactory(
AbstractDAOFactory.SQL_SERVER_ACCESS,"java:jboss/datasources/...");
ResultSet rs = stmt.executeQuery("SELECT ... WHERE code= '" + code + "'");
Target:
@Repository
interface AttributeRepository extendsJpaRepository<Attribute, Long> {
@Query("SELECT a FROM Attribute a WHERE a.code = :code")
Optional<Attribute> findByCode(@Param("code") Stringcode);
}
Document the new API surface. The workflow extracts the new entry points from the rewritten controllers (request method, path, thrown exceptions) and emits OpenAPI including error responses. The OpenAPI document becomes the externally visible contract of the new service.
Assemble the integration suite. The final step pulls in the legacy entry points, the generated test cases, the new API surface, and the database initialization scripts. It maps legacy entry points to the new API, attaches the test cases to each, generates init and cleanup scripts per new endpoint, and assembles the result into a single class. The suite runs against testcontainers in CI, with the legacy behavior as the reference.
How the team worked inside the pilot
The unit of work was the feature, grouped along the legacy Struts entry points. One feature passed through the workflow at a time, each landing as a feature branch ready for review.
Per-feature review happened in the IDE. An engineer checked out the rewrite branch in IntelliJ, diffed it against the previous baseline (the last feature branch that had been merged), applied corrections in the IDE, and merged the result upward. Then the next feature began.
The default for every step was a simple LLM prompt with a well-scoped contract. Coding agents were reserved for steps where multiple files had to be read and written holistically, such as the integration-suite assembly and the larger feature merges. The rule the team converged on during the Pilot was practical: complex multi-file work to coding agents, well-bounded single-job work to single prompts.
The steps engineers designed read their own framework (prompts, contracts, supporting templates) from a feature branch rather than from main. That separation let engineers iterate on the framework while the rewrite continued, without main-branch friction. Improvements accumulated as the Pilot progressed, and the last features were rewritten faster than the first.
Two kinds of evaluation ran inside the work. Functional evaluation is a dedicated step at the end of each rewrite: the integration suite runs against the new code with the legacy behavior as the reference. LLM evaluation lives inside each LLM or agent step and judges that step's output against the contract for it: shape, scope, constraints. Engineers read the evidence each evaluation emits.
Engineers stayed in the loop where it mattered: at the boundary of each feature, against the evidence the evaluations produced. The structure of the work meant the review caught what mattered instead of being swallowed by intermediate noise.
What the customer received
The customer received a working service behind the integration-test suite the workflow assembled. It is a clean Spring service: focused controllers, the domain code behind them, and a data layer that no longer depends on the legacy stored-procedure factory. The JBoss runtime is no longer in the picture, and structured error handling replaces the raw stack traces the legacy version surfaced when something went wrong.
Alongside the service, the customer received architecture documentation, deployment instructions, and the open points that need attention beyond the Pilot. A manual regression test plan keyed to the legacy version was prepared for the cutover window so the customer's QA process had something concrete to anchor to. Configuration was made explicit, with every setting and its purpose documented.
The customer's engineering team took ownership at handover. They have a service their engineers can extend, a runtime their operations team can operate, and documentation grounded in code that exists.
From the pilot forward
The Pilot landed, and with it the workflow the customer was looking for. The rewritten service is the working proof. The workflow that produced it is what carries forward to the rest of the portfolio.
The same approach applies to whatever else sits on the same retiring stack, at whatever pace business priority and operational risk allow. The integration suite is theirs; the workflow is theirs; the patterns the first pass produced are already familiar to their team. What is left to decide is the order, not the approach.
If the system you are looking at fits the shape described here, a Java web stack on Struts and JBoss in maintenance with the platform underneath becoming a security and operations problem, reach out. We will scope a focused Transformation Pilot on a single application, time-boxed, with deliverables your team can verify.
Legacy Java modernization: From Understand to Transform
Some legacy codebases were written decades ago by people who have since moved on. Others were never really written by people at all: a previous modernization vendor ran a COBOL system through a mechanical translator, the output Java compiled and shipped, and the original team dispersed before anyone documented what it produced. Either way the code is opaque to the team that owns it now.
The question this article addresses is what happens when that team decides to replace it. Replacing a feature in a system nobody fully understands is a different engineering problem from green-field work, and it goes wrong in characteristic ways. Done manually, a rewrite turns into a long archaeology project: engineers read the legacy code, hold a mental model of what it does, write a replacement, and then argue about whether the replacement matches. With no automated tests, "matches" is a judgement call. With AI assistance, the failure modes shift but do not disappear: code shaped by translation patterns rather than by the feature's actual behaviour, code shaped to pass whatever tests happen to be in front of the model, defects that compile cleanly and ship.
This article describes the process engineers design and run to address those failure modes. We call the engagement shape the Transformation Pilot: a focused pass that takes a single feature out of the legacy codebase and carries it through Design, Build, and a phased Run to production. The pilot consumes the artefacts produced by the Understand phase. It produces a working component the team can own and extend, and a process the engagement can iterate for the next feature.
The kind of code this is about
The same shape recurs across legacy Java modernization engagements. The code compiles and runs and carries the business. There are no tests. There is no documentation worth trusting. The team that wrote or translated the code is long gone. What is left is opaque code, an unknown blast radius for any change, and a current team that avoids modifying it because nobody can predict what will break.
Two flavors show up most often. The first is genuine long-lived legacy: code written years ago, modified by many hands, with documentation that drifted out of sync long before anyone noticed. The second is auto-translated legacy: Java emitted by mechanical translation from COBOL or a similar source, where the surface is opaque and the translation team has dispersed. The end state is the same. The methodology generalizes across both.
The Transformation pilot
A Transformation Pilot takes one scoped unit through the modernization process end-to-end. It is a focused engagement, not a system-wide commitment. The output is a new component running in production, validated against the legacy behavior it replaces, and a process the team can re-run on dependent components.
.jpg)
The G.Tx modernization process organises the work into four phases: Understand, Design, Build, and Run. The pilot runs the last three. Understand happens before the pilot and produces the artefacts the pilot consumes. We covered Understand in a separate case study showing how dead code analysis alone can reveal that nearly half of an auto-translated codebase carries no semantic weight.
What follows is a walk-through Design, Build, and Run, in the order a pilot runs them.
Design: shaping the transformation strategy
Design begins once Understand has produced the system picture. The phase shapes the strategy for the pilot: which unit to take through, the order in which dependent parts of the codebase will be transformed if the pilot expands, the contract the new component must satisfy, the integration tests that capture what the legacy version does today, and the workflows that will run in Build.
The process does not arrive fully assembled, but it does not start from a blank page either. Years of engagements have produced a library of validated workflows: extraction patterns, evaluation shapes, and prompt structures for common transformation steps. Engineers start there. They analyze the codebase, the available evidence, and the constraints of the engagement, then compose and shape the process for this particular challenge.
Choices made up front include what counts as a feature in this codebase, what the integration tests need to capture, where coding agents are required, where a simple LLM prompt is sufficient, where deterministic scripts or programs are the right tool, what each step's contract looks like, and how the evaluations score outputs.
A generic "transform any legacy" recipe does not exist. A reusable shape does, and each engagement instantiates that shape against its own evidence. The steps engineers design are what carries the work. The prompts, agents, scripts, and evaluations all run inside that shape.
The integration tests are authored in Design against the legacy feature behavior. Inputs are synthesized from the artefacts Understand produced: method signatures, example values, dependency information. The tests themselves are generated by a workflow step that runs against legacy behavior. Engineers review them, refine where coverage is thin or the inputs are unrealistic, and only then are the tests treated as the behavioral standard downstream work is held to.
This is test-driven development applied to modernization. The tests come first, the new code is written against them, and the same tests judge whether the result is equivalent. Nothing downstream begins until the integration tests are in place and approved.
Build: generating and refining the modernized component
Build begins with the artefacts in hand: the contract, the integration tests, and the workflows engineers composed in Design. The phase produces a new component implementing the feature from scratch in modern Java.
The component generator works from the artefacts that describe the feature and a contract that specifies what the component must do: its interface, scope, and constraints. It does not see the integration tests themselves. Hiding the validation surface from the generator prevents a common failure mode where the output is shaped to pass a specific set of tests rather than implementing the feature correctly.
Legacy source code stays out of the generator's input by default. It is provided only where the engagement requires a specific integration to be preserved, for example a SQL stored procedure or an external API the new component must call in the original form. Outside those cases, the new component is shaped by the description of the feature, not by the patterns of the translator or the developers who wrote the original Java.
Most of the steps that compose the component are simple LLM prompts. Coding agents are used where files must be read and written holistically across the input set. Some steps are not models at all. Structural transformations, packaging, file scaffolding, and similar work runs as ordinary scripts and programs where deterministic compute is the right tool. Each step has a narrow, named job and a reviewable output. That is how engineers keep the work decomposable.
The result is a single component that passes the integration tests authored against the legacy feature.
Build runs two kinds of evaluation against each step's output. LLM evaluation lives inside an LLM or agent step. The step's output is scored by a judge prompt against the contract the engineers set for that step: shape match, scope, constraints. This is how a step decides whether its own output is acceptable before passing it forward. Functional evaluation is a dedicated step on its own. It runs the integration tests against the new component and reports the result. This is the only evaluation that sees the tests; nothing upstream has access to them. Both produce evidence the team reads.
.png)
Engineers do not review every intermediate prompt output or every agent diff. The process produces too much volume for that, and approving everything at every stage would defeat the point of decomposing the work. What engineers approve is the transformation output: the new component plus the evidence that it satisfies the integration tests. When an evaluation fails or surfaces a weakness, they refine the step that produced it. The refinement loop is part of the design. Each pass that does not yield an approvable result becomes the input to the next iteration of the prompts, both within the engagement and across the library of workflows we maintain.
Run: phased rollout to production
Run takes the approved component through production deployment. Engineers stay involved through the rollout: integrating the new component into the surrounding system, retiring the legacy code it replaces, and handling the cutover the production environment requires.
The rollout follows an incremental strategy. The component goes into production behind whatever controls the team uses to limit blast radius: feature flags, canaries, gradual traffic shifting, observation periods. The pilot is complete when the new component is carrying production traffic and behaving as the integration tests promised.
From there the same process applies to dependent components in the same area of the codebase, reusing the contract patterns, integration tests, and workflows from the first pass. Each subsequent pilot builds on the one before, and the outcome accumulates into a working modern subsystem rather than a single proof point in isolation.
A brief note on scale
An agent driving the work end-to-end can take on one feature at a time. Beyond that, its context window and judgement run out. The process above scales differently: each step is named, evaluated, and approvable on its own, so the same shape applies whether the target is one feature or the whole system.
The platform: G.Tx
The work in this article runs on G.Tx, Grape Up's agentic platform for enterprise legacy modernization. G.Tx organizes modernization into the four phases shown at the top of this article: Understand, Design, Build, and Run. The Transformation Pilot is the engagement shape that bundles Design, Build, and Run into a single focused pass on a scoped unit.
Each phase is backed by reusable workflows, structured context, and engineering governance. Engineers compose the workflows from a library validated across previous engagements, then shape them for the specific challenge in front of them.
Understand is a valuable output on its own. Many engagements stop there because the picture it produces is already enough to ground a modernization decision. The Transformation Pilot is what happens when the engagement continues.

What a legacy modernization pilot leaves behind
A Transformation Pilot leaves three things behind. The first is a modernized component running in production, validated against integration tests authored against the legacy behaviour. The second is a process the team can re-run on dependent components in the same area of the codebase, with the contract patterns, integration tests, and workflows from the first pass ready for reuse. The third is the workflow library used during the pilot, now enriched with whatever was learned from this engagement.
Every piece of the result is traceable. Engineers can show what produced the component, what evaluated it, what test results it passed, and who signed off. That traceability is what makes the pilot reviewable as evidence, and what makes the methodology repeatable across the dependent components that follow.