
As an experienced and innovative DevOps engineer, I specialize in working with various cloud technologies to streamline and optimize development processes for AI projects in automotive area. My passion for cutting-edge technology and continuous improvement drives my ability to deliver great results in the rapidly evolving tech landscape. Outside of work, I find balance in pursuing my hobbies, which include honing my skills in archery and indulging my love for vintage motorcycles. This blend of interests allows me to approach complex challenges with creativity and precision.
Read articles
3 questions to Tomasz Ćwięk, DevOps Engineer at Grape Up
DevOps engineers have a diverse and unique skill set and the profile of the DevOps engineer is evolving. I asked Tomasz Ćwięk who is a DevOps Engineer at Grape Up to explain in more detail what it's like to be in that role.
1. What is the real impact that you have on the product, the processes and the team as a DevOps Engineer?
Since a DevOps Engineer is a person who operates in a wider IT area than a programmer or an operator, it is easier for him to see the “bigger picture”. Thanks to this, it is easier for him to predict the potential problems faster and determine in advance whether an idea is going in the right direction.
If a given solution requires a test or a proof of concept (PoC), a DevOps engineer is able to quickly and effectively run without involving more people. Then, using knowledge and appropriate tools, such as the CI/CD pipeline, monitoring, metrics, they can immediately draw conclusions, and save many hours or even days of work of the rest of the team.
2. Who can become a DevOps Engineer? Is there an ideal candidate profile?
Well, I used to work as a developer. Then one day, I felt that my work has slowly become “not-so-exciting” (not to call it boring) and monotonous. I felt the urge to change something back then. Now, the variety of tasks and problems that I encounter and have to deal with on a daily basis makes my day so much more exciting. Personally, I think that becoming a DevOps engineer is perfect for people who are good problem solvers. Additional experience as a system administrator and a programmer, is a nice to have.
3. What does a day in the life of a DevOps Engineer look like?
Currently, I work on several projects which differ from one another. Some of them are support projects, which is why it is very difficult to predict what the next day will look like. For example, one day we design the network infrastructure for new tools, the next day we debug the problem of updating the platform or installing a new tool. We wear many hats. Quite often we work as consultants, advising the client on how to best solve the problem, design a new solution or even reasonably plan tasks for the team.
When it comes to my daily tasks — there are plenty of them and all of them are different. The key to mastering this chaos is establishing a good relationship with the client, properly planned stand-up meetings, and effective use of tools.
Bringing visibility to cloud-native applications
Working with cloud-native applications entails continuously tackling and implementing solutions to cross-cutting concerns. One of these concerns that every project is bound to run into comes to deploying highly scalable, available logging, and monitoring solutions.
You might ask, “how do we do that? Is it possible to find "one size fits all" solution for such a complex and volatile problem?” You need to look no further!
Taking into account our experience based on working with production-grade environments , we propose a generic architecture, built totally from open source components, that certainly provide you with the highly performant and maintainable workload. To put this into concrete terms, this platform is characterized by its:
- High availability - every component is available 24/7 providing users with constant service even in the case of a system failure.
- Resiliency - crucial data are safe thanks to redundancy and/or backups.
- Scalability - every component is able to be replicated on demand accordingly to the current load.
- Performance - ability to be used in any and all environments.
- Compatibility - easily integrated into any workflows.
- Open source - every component is accessible to anyone with no restrictions.
To build an environment that enables users to achieve outcomes described above, we decided to look at Elastic Stack, fully open source logging solution, structured in a modular way.
Elastic stack
Each component has a specific function, allowing it to be scaled in and out as needed. Elastic stack is composed of:
- Elasticsearch - RESTful, distributed search and analytics engine built on Apache Lucene able to index copious amount of data.
- Logstash - server-side data processing pipeline, able to transform, filter and enrich events on the fly.
- Kibana – a feature-rich visualization tool, able to perform advanced analysis on your data.
While all this looks perfect, you still need to be cautious while deploying your Elastic Stack cluster. Any downtime or data loss caused by incorrect capacity planning can be detrimental to your business value. This is extremely important, especially when it comes to production environments. Everything has to be carefully planned, including worst-case scenarios. Concerns that may weigh on the successful Elastic stack configuration and deployment are described below.
High availability
When planning any reliable, fault-tolerant systems, we have to distribute its critical parts across multiple, physically separated network infrastructures. It will provide redundancy and eliminate single points of failure.
Scalability
ELK architecture allows you to scale out quickly. Having good monitoring tools setup makes it easy to predict and react to any changes in the system's performance. This makes it resilient and helps you optimize the cost of maintaining the solution.
Monitoring and alerts
A monitoring tool along with a detailed set of alerting rules will save you a lot of time. It lets you easily maintain the cluster, plan many different activities in advance, and react immediately if anything bad happens to your software.
Resource optimization
In order to maximize the stack performance, you need to plan the hardware (or virtualized hardware) allocation carefully. While data nodes need efficient storage, ingesting nodes will need more computing power and memory. While planning this take into consideration the number of events you want to process and amount of data that has to be stored to avoid many problems in the future.
Proper component distribution
Make sure the components are properly distributed across the VMs. Improper setup may cause high CPU and memory usage, can introduce bottlenecks in the system and will definitely result in lower performance. Let's take Kibana and ingesting node as an example. Placing them on one VM will cause poor user experience since UI performance will be affected when more ingesting power is needed and vice-versa.
Data replication
Storing crucial data requires easy access to your data nodes. Ideally, your data should be replicated across multiple availability zones which will guarantee redundancy in case of any issues.
Architecture
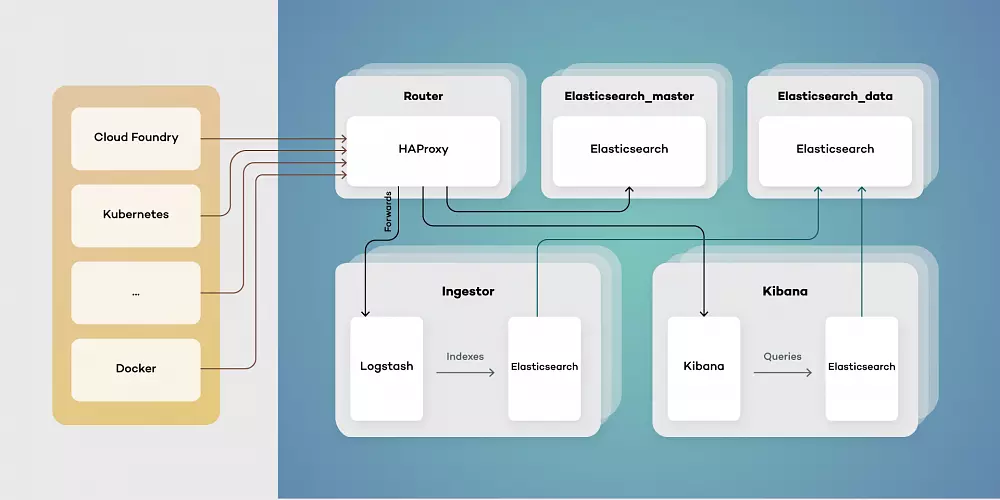
Our proposed architecture consists of five types of virtual machines - Routers, elastic masters, elastic data, ingestors, and Kibana instances. This toolset simplifies scaling of components while separating their responsibilities. Each of them has a different function:
- Elasticsearch_master - controls indexes and Elasticsearch master. Responsible for creating new indexes, rolling updates and monitoring clusters health.
- Elasticsearch_data - stores data and retrieves it as needed. Can be run both as hot and warm storage, as well as provides redundancy on data.
- Ingestor - exposes input endpoints for events both while transforming and enriching data stored in Elasticsearch.
- Kibana - provides users with visualizations by querying Elasticsearch data.
- Router - serves as a single point of entry, both for users and services producing data events.
Architecting your Elastic Stack deployment in this way allows for the simple upgrade procedure. Thanks to using a single point of entry, switching to a new version of Elastic Stack is as simple as pointing HAProxy to an upgraded cluster.
Using a clustered structure also allows for freely adding data nodes as needed when your traffic inevitably grows.
5 Tips on how to deal with common problems when running large production environments
Working as a platform operator with cloud-native technologies, L2 technical support , and participating in CF installations give a unique opportunity to observe how different companies implement new technologies in their works and how they deal with running large production environments. Among various bad experiences, imperfect ideas, and the most reprehensible habits related to running and maintaining cloud infrastructures those listed below can generate the most complicated problems.
Bad practices often occur when it comes to productive CF infrastructures. However, these guidelines should help everyone who runs or uses any of the production-ready workloads.
Neglected capacity planning
Let’s start with this: you have to be aware that you will run out of resources eventually. Then you should plan how to scale up. If you run on-premises software, you should consider hardware and virtualization layer’s requirements. Proper sizing of the availability zones will always save you many problems.
On top of IaaS there is always a PaaS or some container orchestrator. The key to success here is to optimize all the limits, quotas and other configurations (like application scaling rules, etc.) so the microservices never consume available resources, even under high load.
It’s obvious that both hardware and virtualized capacity planning requires a buffer. You need to be prepared for issues, maintenance and infrastructure changes. There is no best configuration. It always depends on many factors but nevertheless, it is always worth taking into consideration.
Capacity and resources have to be monitored. A good monitoring tool with decent alerting rules will help you predict possible problems and react quickly if anything bad happens to your infrastructure.
Poor or no CI/CD
If you want to maintain any piece of software, don’t forget how valuable is automation. Many times people quit on CI/CD implementation because of the deadline or tasks formally more important. In most cases, it doesn't end up well.
It's hard to build, test and deploy software without automation. The manual process is highly exposed to the risk of human error. Apart from that, it is almost impossible to keep track of deployed software (version, updates, hotfixes, security patches, etc.) in large production environments. Sometimes you have to maintain CF platforms hosting 1K+ applications. Consider how problematic would be the migration process if there is a business decision to switch to a different solution.
For operators maintaining the infrastructures, platforms, and services used by developers it’s critical to keep everything up to date, take care of security patches and configuration changes. It is impossible to handle this manually with minimal or zero downtime of the services. That is why automated pipelines are so important, and you should never give up on implementing them in the first place.
Poor or no backup/restore procedures
Backup/restore is another important process that people often put in the background. You may think that your applications are safe if your IaaS offers you a highly available environment or containers you run have an auto-healing function. This is not true. Any disaster can happen, and in order to recover quickly, you have to create a well-defined backup and restore procedures that work. That’s not all, as the procedures have to be tested periodically. You need to be sure that backup/restore works fine since the process may depend on some external services that might have changed or just brake.
No periodic updates
Every software has to be updated regularly in order to keep it secure. It is also much safer to perform minor updates with a little chance of failure or downtime than doing ‘big jumps’. Major updates introduce higher risk, and it is hard to catch up with versions especially if there is no automation implemented.
You may see cloud infrastructures that were just installed and never upgraded and that generates a lot of issues for platform operators (users can’t see any difference). It is not a problem until everything works correctly. But after some time people may start escalating issues related to the versioning of the services. Unfortunately, it is too late to upgrade smoothly. It becomes a big spider’s web of dependencies. It may take weeks to plan the upgrade process and months to execute it.
Flawed architecture
Defective architecture generates serious problems. Many times developers are not aware of the issue until it shows up in production. After that, it’s really hard to admit the architecture needs to be changed and people often try to get rid of the effect instead of fixing the cause of the problem.
Let’s take a real-life example often faced. You may be receiving Prometheus alerts saying that ELK stack is overloaded. After investigating the issue, it may turn out that microservices are so verbose that they generate thousands of log messages per second. What if you raise the possible architecture problem, but nobody cares? As a result, you’ll have to scale ELK. In those cases, it may waste hundreds of CPUs and terabytes of memory and storage. That makes somebody spend money just to store 90% of useless data and maybe 10% of valuable information. This is really a simple way to put yourself in a situation without a way out.
Conclusion
Following these guidelines will definitely not be easy. Sometimes people responsible for making decisions are just not aware of the consequences of taking some actions. The role of every technically skilled person in the project is to spread the knowledge and make people aware of what may happen if they ignore those basic rules that matter. You can’t step back if you encounter such practices in the future. Be an example for others and drive change - it’s always worth trying.