What Is an exit strategy and why do you need one?

Cloud is everywhere these days. There is no doubt about that. Everyone already did or is about to make an important decision - which cloud provider to choose?
For enterprise solutions, the first thought goes to the big players: Amazon, Microsoft, Google. They provide both private and public cloud solutions using their own set of APIs, command-line tools and of course pricing.
It is very easy to get in, but is it the same with getting out? All your services may already benefit from great tools and services shared by your provider. Awesome tools, but specific to the company. Does Amazon CLI work with Azure? Not really.
The important part is that the scale of your infrastructure you can manage. The software can be optimized, to some point, but still, it may be a viable choice. Resources can be hosted using CDN to better manage bandwidth and storage cost. But what can be done if the provider increased the prices? How this can be mitigated?
The exit strategy
This is why you need an exit strategy. The plan to move all your resources safely and possibly without any interruptions from one warehouse to another. Or even the plan to migrate from one provider to the another. The reasons for the change may be very different. Pricing change, network problems, low latency or even a law change. All this may push your company against the wall. It is fine when you are prepared, but how to do this?
It may seem more on the paranoic side or catastrophic thinking, but in reality, it is not so uncommon. Even worse case, which is a provider shut down, happened a lot lately. It is especially visible with an example of cloud storage startups. $15 million dollars CloudMine startup filed for bankruptcy last year. A few years ago the same thing happened to Nirvanix and Megacloud. Nobody expected that and a lot of companies has been facing that problem - how can we safely move all the data if everything can disappear in 2 weeks?
Does it mean AWS will go down tomorrow? Probably not, but would you like to bet if it will be there in 10 years? A few years ago nobody even heard about Alibaba Cloud, and now they have 19 datacenters worldwide. The world is moving so fast that nobody can say what tomorrow brings.
How to mitigate the problem?
So we have established what the problem is. Now let’s move to the solutions. In the following paragraphs, I will briefly paint a picture of what consists of an exit strategy and may help you move towards it.
One of them is to use a platform like Cloud Foundry or Kubernets which can enable you to run your services on any cloud. All big names offer some kind of hosted Kubernetes solutions: Amazon ECS, Microsoft AKS and Google GKE. Moving workloads from one Kubernetes deployment to another, even private hosted, is easy.
This may not be enough though. Sometimes you have more than containers deployed. The crucial part then will be to have infrastructure as a config. Consider if the way you deploy your platform to IaaS is really transferable? Do you use provider-specific databases, storage or services? Maybe you should change some solutions to more universal ones?
Next part will be to make sure services your write, deploy and configure are truly cloud-native. Are they really portable in a way you can get the same source code or docker image and run on the different infrastructure? Are all external services loosely coupled and bounded to your application so you can easily exchange them? Or if all your microservices platforms are independent?
Last, but not least is to backup everything. Really, EVERYTHING. Not just all your data, but also the configuration of services, infrastructure, and platforms. If you can restore everything from the ground up to the working platform in 24 hours you are better than most of your competitors.
So why do I need one?
Avoiding provider lock-in may not be easy, especially when your company just started to use AWS or Azure. You may not feel very comfortable creating an exit strategy for different providers or just don’t know where to start. There are solutions, like Grape Up’s Cloudboostr, that manage backups and multi-cloud interoperability out of the box. Using this kind of platform may save you a lot of pain.
An exit strategy gives you a lot of freedom. New, small cloud provider comes to the market and gives you a very competitive price? You can move all your services to their infrastructure. Especially when we consider that small cloud providers can be more flexible and more keen to adapt to their client needs.
An exit plan gives safety, freedom, and security. Do not think of it as optional. The whole world goes toward the multi-cloud and the hybrid cloud . According to Forbes, this is what 2019 will matter most in the cloud ecosystem. Do you want to stay behind? Or are you already prepared for the worse?

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
Automating your enterprise infrastructure. Part 1: Introduction to cloud infrastructure as code (AWS Cloud Formation example)
This is the first article of the series that presents the path towards automated infrastructure deployment. In the first part, we focus on what Infrastructure as Code actually means, its main concepts and gently fill you in on AWS Cloud Formation. In the next part , we get some hands-on experience building and spinning up Enterprise Level Infrastructure as Code.
With a DevOps culture becoming a standard, we face automation everywhere. It is an essential part of our daily work to automate as much as possible. It simplifies and shortens our daily duties, which de facto leads to cost optimization. Moreover, respected developers, administrators, and enterprises rely on automation because it eliminates the probability of human error (which btw takes 2nd place when it comes to security breach causes ).
Additionally, our infrastructure gets more and more complicated as we evolve towards cloud-native and microservice architectures. That is why Infrastructure as code (IaC) came up. It’s an answer to the growing complexity of our systems.
What you’ll find in this article:
- We introduce you to the IaC concept - why do we need it?
- You’ll get familiar with the AWS tool for IaC: Cloud Formation
Why do we need to automate our enterprise infrastructure?
Let’s start with short stories. Close eyes and imagine this:
Sunny morning, your brand new startup service is booming. A surge of dollars flows into Your bank account. The developers have built nice microservice-oriented infrastructure, they’ve configured AWS infrastructure, all pretty shiny. Suddenly, You receive a phone call from someone who says that Amazon's cleaning lady slipped into one of the AWS data centers, fall on the computing rack, therefore the whole Availability Zone went down. Your service is down, users are unhappy.
You tell your developers to recreate the infrastructure in a different data center as fast as they can. Well, it turns out that it’s not possible as fast as you would wish. Last time, it took them a week to spin up the infrastructure, which consists of many parts… you’re doomed.
The story is an example of Disaster Recovery , or rather a lack of it. No one thought that anything might go wrong. But as Murphy’s law says: Anything that can go wrong will go wrong
The other story:
As a progressive developer, you’re learning bleeding-edge cloud technologies to keep up with changing requirements for your employer. You decided to use AWS. Following Michal's tutorial , you happily created your enterprise-level infrastructure. After a long day, you cheerfully lay down to bed. The horror begins when you enter your bank account at the end of the month. Seems that Amazon charged you, for the resources you didn’t delete.
You think these scenarios are unreal? Get to know these stories:
How do You avoid these scenarios? The simple answer to that is IaC.
Infrastructure as Code
Infrastructure as Code is a way to create a recipe for your infrastructure. Normally, a recipe consists of two parts: ingredients and directions/method on how to turn ingredients into the actual dish. IaC is similar, except the narration is a little bit different.
In practice, IaC says:
Keep your IaC scripts (infrastructure components definition) right next to your application code in the Git repository. Think about those definitions as simple text files containing descriptions of your infrastructure. In comparison to the metaphor above, IaC scripts (infrastructure components definitions) are ingredients .
IaC also tells you this:
Use or build tools that will seamlessly turn your IaC scripts into actual cloud resources. So translating that: use or build tools that will seamlessly turn your ingredients (IaC scripts) into a dish (cloud resources).
Nowadays, most IaC tools do the infrastructure provisioning for you and keep it idempotent . So, you just have to prepare the ingredients. Sounds cool, right?
Technically speaking, IaC states that similarly to the automated application build & deployment processes and tools, we should have processes and tools targeted for automated infrastructure deployment .
An important thing to note here is that the approach described above leans you towards GitOps and trunk-based CICD . It is not a coincidence that these concepts are often listed one next to the other. Eventually, this is a big part of what DevOps is all about.
Still not sure how IoC is beneficial to you? See this:
During the HacktOberFest conference, Michal has been setting up the infrastructure manually - live during his lecture. It took him around 30 minutes - even though Michal is an experienced player.
Using cloud formation scripts, the same infrastructure is up and running in ~5 minutes , besides it doesn’t mean that we have to continuously watch over the script being processed. We can just fire and forget, go, have a coffee for the remaining 4 minutes and 50 seconds.
To sum up:
30/5 = 6
Your infrastructure boots up 6 times faster and you have some extra free time. Eventually, it boils down only to the question if you can afford such a waste.
With that being said, we can clearly see that IaC is the foundation on top of which enterprises may implement:
- Highly Available systems
- Disaster recovery
- predictable deployments
- faster time to prod
- CI/CD
- Cost optimization
Note that IaC is just a guideline, and IaC tools are just tools that enable you to achieve the before-mentioned goals faster and better. No tool does the actual work for you.
Regardless of your specific needs, either you build enterprise infrastructure and want to have HA and DR or you just deploy your first application to the cloud and reduce the cost of it, IoC is beneficial for you.
Which IaC tool to use?
There are many IaC tool offerings on the market. Each claim to be the best one. Only to satisfy our AWS deployment automation, we can go with Terraform, AWS Cloud Formation, Ansible and many many more. Which one to use? There is no straight answer, as always in IT: it depends . We recommend doing a few PoC, try out various tools and afterward decide which one fits you best.
How do we do it? Cloud Formation
As aforementioned we need to transcribe our infrastructure into code. So, how do we do it?
First, we need a tool for that. So there it is, the missing piece of Enterprise level AWS Infrastructure - Cloud Formation . It’s an AWS native IaC tool commonly used to automate infrastructure deployment.
Simply put, AWS Cloud Formation scripts are simple text files containing definitions of AWS resources that your infrastructure utilizes (EC2, S3, VPC, etc.). In Cloud Formation these text files are called Templates.
Well… ok, actually Cloud Formation is a little bit more than that. It’s also an AWS service that accepts CF scripts and orchestrates AWS to spin up all of the resources you requested in the right order (simply, automates the clicking in the console). Besides, it gives you live insight into the requested resource status.
Cloud formation follows the notion of declarative infrastructure definitions. On the contrary to an imperative approach in which You say how to provision infrastructure, declaratively you just specify what is the expected result. The knowledge of how to spin up requested resources lies on the AWS side.
If You followed Michal Kapiczynski’s tutorials , the Cloud Formation scripts presented underneath are just all his heavy work, written down to ~500 lines of yml file that you can keep in the repository right next to your application.
Note: Further reading requires you to either see Michals articles before or basic knowledge of AWS.
Enterprise Level Infrastructure Overview
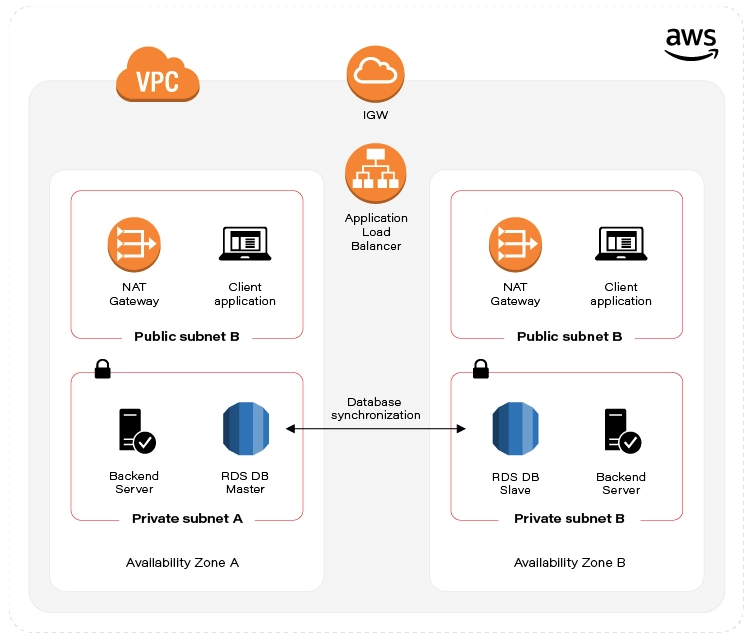
There are many expectations from Enterprise Level infrastructure. From our use case standpoint, we’ll guarantee High Availability, by deploying our infrastructure in two separate AWS Data Centers (Availability Zones) and provide data redundancy by database replication. The picture presented above visualizes the target state of our Enterprise Level Infrastructure.
TLDR; If You’re here just to see the finished Cloud Formation script, please go ahead and visit this GitHub repository .
We've decided to split up our infrastructure setup into two parts (scripts) called Templates . The first part includes AWS resources necessary to construct a network stack. The latter collects application-specific resources: virtual machines, database, and load balancer. In cloud formation nomenclature, each individual set of tightly related resources is called Stack .
Stack usually contains all resources necessary to implement planned functionality. It can consist of: VPC, Subnets, EC2 instances, Load Balancers, etc. This way, we can spin up and tear down all of the resources at once with just one click (or one CLI command).
Each Template can be parametrized. To achieve easy scaling capabilities and disaster recovery, we’ll introduce the Availability Zone parameter. It will allow us to deploy the infrastructure in any AWS data center all around the world just by changing the parameter value.
As you will see through the second part of the guide , Cloud Formation scripts include a few extra resources in comparison to what was originally shown in Michal’s Articles . That’s because AWS creates these resources automatically for you under the hood when you create the infrastructure manually. But since we’re doing the automation, we have to define these resources explicitly.
Sources:
- https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/gettingstarted.templatebasics.html
- https://martinfowler.com/bliki/InfrastructureAsCode.html
- https://docs.microsoft.com/en-us/azure/devops/learn/what-is-infrastructure-as-code
Interested in our services?
Reach out for tailored solutions and expert guidance.