Capturing objects in closures: why you’re doing it wrong? – Part 1

The basics of closures
Many modern programming languages have a closure concept. Closures are self-contained blocks of functionalities which can be passed around and called. Additionally, they can work with environmental data (variables, functions, types etc.) captured from the outer lexical context in which the closure is defined. A closure may be bound to a variable (constant, parameter, etc.) and called through it.
With that said, there are two main aspects: the code of the closure itself and the data captured from the context. When talking about closures, we usually mean the code. However, the context isn’t any less important and, most often, it is the trickiest part of closures.
Retain cycles
Each programming language or runtime environment may determine a different way of handling and storing the closure’s context. Nevertheless, special attention should be paid to languages which use the reference counting semantic to deal with objects. With such languages, we have a retain cycle problem. Let’s quickly refresh and go through what we already know about reference counting as well as retain cycles, and how to deal with them.
In reference counting environment each object has associated a reference counter which shows how many objects use it by a strong reference. If the object is assigned to a variable representing a strong reference to the object, its reference (retain) count is increased. When such variable goes out of scope, the reference count decreases. As soon as the count comes to a 0, the object is deallocated. Therefore, in case the sequence of the objects cyclically reference each other, all of those objects will never be deallocated. Why? Because even if there will be no references which would point to a chosen object outside the cycle, each of these objects will still have a strong reference from inside the cycle which “retains” them. Such situation is known as “a memory leak” and is called a retain cycle.
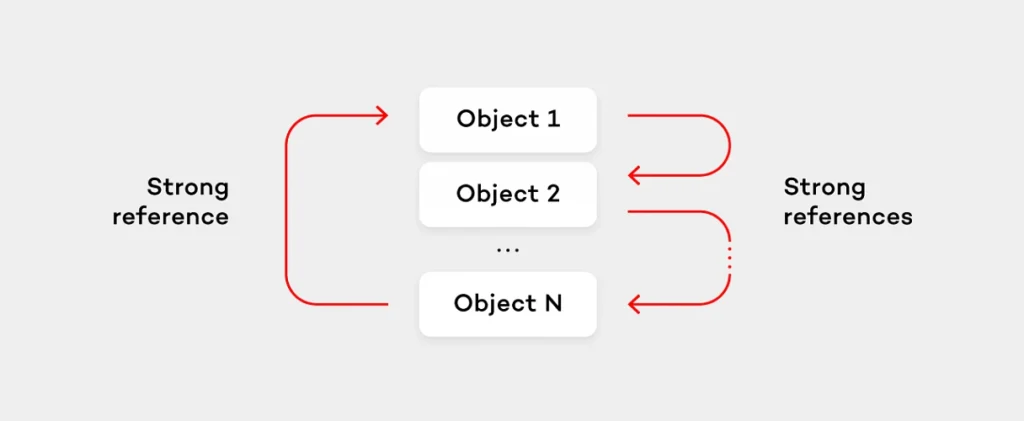
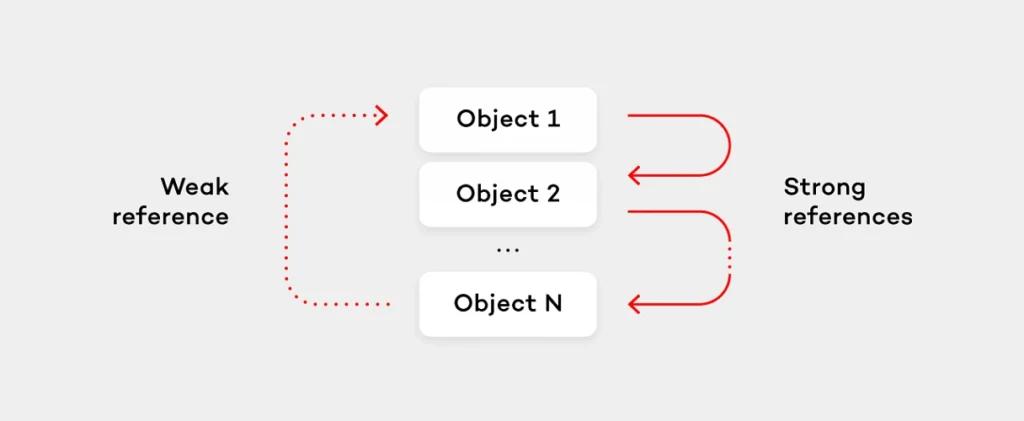
Usually, languages in a reference counting environment provide a special type of references called weak references which don’t increase the retain count of the object they point to. Instead, when the object is deallocated, each weak reference is nilled in runtime. The right way to avoid retain cycles is to use weak references. In order to break the retain cycle in the previously mentioned object sequence it would be enough to make one object (for simplicity, let’s assume the last one in sequence) hold the weak reference to the next object (the first one).
However, let’s go back to closures and their context. We will use Swift to show certain examples of the code, but keep in mind that all solutions are applicable to any language that has closures and a reference counting environment. In case a closure uses objects from the closure’s outer context, that closure will capture the reference to those objects. The most common case when a retain cycle happens is when the object stores a closure while the closure (directly or through the reference chain with other objects) references the object itself using a strong reference. Take a look at the following example:
database.observeChanges(recordID) { snapshot in
// Some code...
database.stopObserving(recordID)
// Doing other stuff...
}
In the example above, the closure is retained inside the method which will be called later. On the other hand, the closure retains a database object since the object is used inside it.
Note that in simple situations when the closure is not stored by the object, (like closures passed to forEach() method of Sequences in Swift) or when the closure is removed from the object after the call (like with DispatchQueue.async() method), the retain cycle does not occur. Therefore, we’ll not consider such cases and instead we will focus on situations when the retain cycle takes place. The language/environment should provide a mechanism to deal with retain cycles for objects captured by the closure. That is, we should have a way to specify how the object should be captured – by means of weak or strong reference. In Swift closures, we have a capture list that allows us to specify how each object should be captured. Let’s take a look at the following example.
let completion = { [weak dataBaseAccessor, someController] (error: Error?) -> Void in
otherController.someAction()
// Doing other stuff
}
The capture list allows to explicitly specify what variables are captured and what reference type (weak or strong) should be used to capture them. In the example above, the capture list is defined at the beginning of the closure header: [weak dataBaseAccessor, someController] . In the given code, dataBaseAccessor is captured by weak reference. While someController and otherController (which is not explicitly specified in the capture list) are captured by strong reference. Note that apart from weak and strong references, Swift has a concept of unowned reference for the capture list. But its usage is strictly limited to the case when the captured object’s lifetime is guaranteed not to be shorter than the lifetime of the closure. Otherwise, its usage is unsafe. We won’t consider this type of references here.
Let’s show an example with retain cycles caused by closures. Commonly, in the example below we avoid the retain cycle by specifying that self should be captured as weak reference.
class DatabaseController: DatabaseAccessorDelegate {
// Some code ...
var requestCompletion: (([String : Any]?, Error?) -> Void)?
func requestData(query: Query, completion: @escaping ([String : Any]?, Error?) -> Void) {
requestCompletion = completion
dataBaseAccessor.performQuery(query)
}
// DatabaseAccessorDelegate
func accessor(_ acessor: DatabaseAccessor, didRetrieveData data: [String : Any], error: Error?) {
requestCompletion?(data, error)
}
}
class ViewController {
let databaseController = DatabaseController()
var cachedData: [String : Any]?
// Other code ...
@IBAction func dataRequestButtonAction(_ sender: UIButton) {
databaseController.requestData(query: query) { [weak self] dataSnapshot, error in
guard let strongSelf = self else {
return
}
strongSelf.cachedData = dataSnapshot
strongSelf.updateUI()
}
}
}
When calling a databaseController.requestData() in completion self has weak modifier. To ensure that self won’t be deallocated during the completion execution, we assign it to strong reference strongSelf at the beginning. Otherwise, if self was already deallocated before the completion closure called, we’d simply exit the closure. Why is this trick needed here? Let’s show the relations between our objects in terms of retaining/not retaining. ViewController retains the DatabaseController . In turn, the DatabaseController retains the completion closure in requestData() . If completion retained the ViewController via self variable, we would get the retain cycle here.
Such approach is often described in terms of “weakifying” and ”strongifying”. Suppose you need to use some object inside closure but it can lead to retain cycle. Capture weak reference to the object when defining closure (“weakifying”), then check if it still exists (reference not nil) at the beginning of closure. If it’s still there assign it to a reference with strong semantic (“strongifying”). Otherwise exit the closure. This pattern is what we actually do in 99% of cases when it comes to closures with potential retain cycles.
Well, programmers try to find (and in most cases reasonably) the “golden rule” for almost anything. However, when it comes to closure context it’s not so simple as it seems to be. The pattern is often overestimated and overused. It’s not a silver bullet (as it is considered to be by many programmers). As a matter of fact, it may completely break the logic of your closure when used unwarily.
A Closer Look
Our previous example is a simple case so the pattern described is pretty useful and works well. But let’s go further. As a matter of fact, some areas are more complicated than they look. To demonstrate this, we’ll extend a bit our implementation of the ViewController .
class ViewController {
// Other code ...
@IBAction func dataRequestButtonAction(_ sender: UIButton) {
databaseController.requestData(query: query) { [weak self] dataSnapshot, error in
guard let strongSelf = self else {
return
}
strongSelf.cachedData = dataSnapshot
strongSelf.updateUI()
let snapshot = dataSnapshot ?? [:]
NotificationCenter.default.post(name: kDataWasUpdatedNotification,
object: nil,
userInfo: [kDataSnapshotKey : snapshot])
}
}
}
We are now notifying about the data that is being retrieved using notification mechanism. In this case, if self was deallocated we’re just returning from closure. But this will skip posting the notification. So despite the data was successfully retrieved observers of the notification won’t get it just because the ViewController instance was deallocated. Thus, the approach with exiting from the closure creates an unnecessary and – what is more important – implicit dependency between the presence of the ViewController in memory and sending the notification. In this case, we should try to obtain self and, if it’s there, proceed with calls on it. And then independently of the self object state, post the notification. See improved code below:
@IBAction func dataRequestButtonAction(_ sender: UIButton) {
databaseController.requestData(query: query) { [weak self] dataSnapshot, error in
if let strongSelf = self {
strongSelf.cachedData = dataSnapshot
strongSelf.updateUI()
}
let snapshot = dataSnapshot ?? [:]
NotificationCenter.default.post(name: kDataWasUpdatedNotification,
object: nil,
userInfo: [kDataSnapshotKey : snapshot])
}
}
This allows us to make an important step towards understanding how context in closures is used. We should separate code that depends on self (and may cause the retain cycle) from code that doesn't depend on it.
It’s all about associating
Choosing which part of the closure code really depends on self (or generally on the instance of the type) and which doesn’t, is trickier than it seems to be. Let’s refactor our example a bit. Let’s suppose we have a delegate that should also be notified. Also, assume we need to notify about data changes in several places across our code. The right thing to do is to place the code for notifying clients into a separate method.
@IBAction func dataRequestButtonAction(_ sender: UIButton) {
databaseController.requestData(query: query) { [weak self] dataSnapshot, error in
guard let strongSelf = self else {
return
}
strongSelf.cachedData = dataSnapshot
strongSelf.updateUI()
let snapshot = dataSnapshot ?? [:]
strongSelf.notifyUpdateData(snapshot: snapshot)
}
}
func notifyUpdateData(snapshot: [String : Any]) {
delegate?.controller(self, didUpdateCahcedData: snapshot)
NotificationCenter.default.post(name: kDataWasUpdatedNotification,
object: nil,
userInfo: [kDataSnapshotKey : snapshot])
}
At first glance, in the code above all the calls depend on self (called on it) so the approach to make an exit from the closure if self is nil seems to be applicable. Although, in essence our code after refactoring does exactly the same what it had done before. Therefore, if self is nil a notification will be missed. How to deal with this situation? The problem lies in the wrong criteria which has been chosen to decompose the code. We’ve combined the delegate callback invocation and the posting notification into a single method because these actions are semantically close to each other. However, we didn’t pay attention to the dependency on a particular instance (expressed via the calling method using self ). The delegate has a strict dependency on the instance because it is a property of the ViewController (a part of its state). Sending the notification is not related to any instance of the ViewController , but it rather relates to the type itself. That is, the proper place for the delegate call which is an instance method, while the notification related code should be placed in the class method.
@IBAction func dataRequestButtonAction(_ sender: UIButton) {
databaseController.requestData(query: query) { [weak self] dataSnapshot, error in
let snapshot = dataSnapshot ?? [:]
if let strongSelf = self {
strongSelf.cachedData = dataSnapshot
strongSelf.updateUI()
strongSelf.notifyDelegateDataWasUpdated(snapshot: snapshot)
}
ViewController.notifyDataUpdate(snapshot: snapshot)
}
}
func notifyDelegateDataWasUpdated(snapshot: [String : Any]) {
delegate?.controller(self, didUpdateCahcedData: snapshot)
}
class func notifyDataUpdate(snapshot: [String : Any]) {
NotificationCenter.default.post(name: kDataWasUpdatedNotification,
object: nil,
userInfo: [kDataSnapshotKey : snapshot])
}
The example shows that associating the code with the instance or the type itself plays an important role in the case of using it inside closures.
Generally, when choosing between placing the code to the type method or to the instance one, use the following “rules of thumb”.
1. If the task done by your code is not associated with any particular instance, place your code in the type (class/static) method. Such code does not manipulate (neither accesses nor alters) the state of any particular instance. This means that such task will make sense in case:
- no instance of that type exists;
- the method is dealing with multiple instances of the same type in the same manner.
2. Otherwise, place the code into the instance method.
3. If the code has mixed associations (one part doesn’t depend on any instance while another one does), the task should be decoupled into smaller tasks. This rule should be then applied to each task separately.
In this case, you will be able to decompose the code.
These rules are also helpful when dealing with closures. That is, static functions are not associated with a particular instance, so such code should be called independently on the one that relates to the self object.
Let’s sum up what we have at this point. In general, inside the closure we should distinct the code that does not relate to the self instance (which retains the closure) from the rest, so that when performing, it should not rely on the existence of the object referenced by self . These rules describe how we can determine what should be associated with the particular instance and what should not. Thanks to that, they are helpful even if we’re not going to extract this code to a static method, but rather use it inline inside the closure.
However, it’s only the tip of the iceberg. The true complexity of the proper closure context usage resides in the code that depends on an instance of the particular type. We’ll focus on such code in the second part of our article .

Grape Up guides enterprises on their data-driven transformation journey
Ready to ship? Let's talk.
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
Interested in our services?
Reach out for tailored solutions and expert guidance.