
VP, AI and Cloud R&D at Grape Up, responsible for developing the overall technology vision of the company with focus on artificial intelligence, deep learning and cloud native technologies. With almost 15 years of hands-on experience in the IT industry, he drives the company’s technology strategy and works closely with engineering teams to ensure continuous delivery of innovative software solutions.
Read articles
Sovereign AI for enterprises: Why governing your AI infrastructure is becoming a strategic priority
Artificial intelligence is becoming part of the operational backbone of modern organizations. What began as experimentation with generative models is now powering customer platforms, internal knowledge systems, software development workflows, and automated decision processes. According to the 2025 McKinsey Global Survey, 88% of organizations now use AI in at least one business function.
Most of these systems rely on frontier model providers such as OpenAI, Anthropic, or Google. These platforms have made advanced AI capabilities widely accessible and significantly accelerated adoption across industries. As a result, much of the enterprise AI discussion has focused on model performance and selecting between providers.
However, as AI becomes embedded in operational systems, a more fundamental question is emerging. The key issue is no longer simply which model an organization uses, but how the organization governs the way AI interacts with its data, systems, and infrastructure - a challenge at the core of what is now called sovereign AI.
Organizations have faced similar questions before. Over the past decade, responsibility for operating key parts of the technology stack shifted across different layers - first through virtualization platforms and later through cloud infrastructure. Today, a similar discussion is emerging at a new layer: the AI runtime itself.
What is sovereign AI? Governance as infrastructure strategy
As AI systems move from experimentation into production environments, governance becomes critical - particularly for organizations handling sensitive data or deploying AI at scale. This is where the concept of sovereign AI begins to emerge.
Sovereign AI refers to an organization's ability to control the data, models, and infrastructure used to build and operate AI systems - ensuring that AI capabilities remain under the governance and regulatory jurisdiction of the enterprise, rather than delegated entirely to external model providers.
In practice, however, most enterprises cannot fully own or manage every layer of the AI stack, especially when relying on external frontier models.
Instead, many organizations pursue a practical form of sovereign AI: ensuring that AI capabilities are integrated, managed, and monitored within their own environments according to enterprise policies and regulatory requirements.
Implementing this approach typically requires introducing a platform layer that governs how AI services are accessed and used across enterprise systems - often referred to as the AI control plane.
The enterprise AI control plane: Architecture and core components
The AI control plane sits between enterprise applications and model providers, managing how AI capabilities are accessed and used across the organization.
Typical components of an enterprise AI control plane include:
- AI gateway - routes requests to multiple models through a unified interface, enabling multi-model strategies without rewriting application logic
- Knowledge layer - vector databases and retrieval systems that allow models to interact with enterprise knowledge sources (Retrieval-Augmented Generation / RAG)
- Agent runtime - infrastructure for operating AI agents that interact with internal systems and workflows
- Governance and guardrails - policies that regulate how AI systems access sensitive data and how outputs are validated, critical for GDPR and AI Act compliance
- Model serving - capabilities for hosting open or specialized models within the organization's own infrastructure when required
Together, these components enable organizations to integrate multiple AI models while ensuring that AI usage follows enterprise policies and operational standards.
Sovereign AI infrastructure: OpenStack and Kubernetes as the foundation for on-premise AI workloads
Infrastructure limitations are one of the primary barriers to scaling AI. Recent surveys show that 82% of organizations say their current infrastructure cannot efficiently support on-premise AI workloads, while 80% identify data sovereignty as a major challenge for AI modernization.
Operating an AI control plane requires infrastructure where organizations can run AI workloads within their own operational and regulatory boundaries. Many enterprises build this foundation using open technologies rather than proprietary AI platforms.
A typical sovereign AI infrastructure stack includes:
- OpenStack for compute, storage, and networking - providing the private cloud foundation for AI workloads
- Kubernetes for orchestrating AI workloads and platform services, including GPU scheduling
- Open-source tooling for model serving, observability, and security
Because these technologies are open and vendor-neutral, organizations retain flexibility in how their infrastructure evolves while avoiding dependence on proprietary AI platforms.
Such infrastructure can run in private data centers, sovereign cloud environments, or infrastructure operated by trusted regional providers in Europe, enabling organizations to host sensitive AI workloads while still integrating external models when appropriate.
Cloudboostr: An EU-built platform for sovereign AI deployments
Platforms such as Cloudboostr - developed by Grape Up, a European cloud-native software company - provide an enterprise-ready foundation for implementing this architecture.
At the infrastructure layer, Cloudboostr delivers OpenStack-based compute, storage, and networking deployed either within an organization's own environment or through trusted European infrastructure providers.
On top of this foundation, the platform provides a production-grade Kubernetes runtime for operating AI workloads and platform services.
Cloudboostr also includes an AI enablement layer supporting:
- multi-model access through an AI gateway
- model serving and inference capabilities
- governance and guardrails for AI operations
- agent runtimes for intelligent workflows
- enterprise knowledge integration through RAG systems
Built on upstream open-source technologies and designed for European regulatory environments - Cloudboostr enables organizations to integrate external AI models while maintaining oversight of their data, infrastructure, and AI operations.
Conclusion
Artificial intelligence is rapidly becoming a foundational capability across modern organizations.
As AI systems move deeper into operational workflows, the challenge is no longer simply accessing powerful models. The critical question is how organizations manage the way those models interact with their data, systems, and infrastructure.
Sovereign AI provides a framework for addressing this challenge. While full ownership of every layer of the AI stack may not be realistic for most enterprises, organizations can still ensure that AI services operate within their governance and regulatory boundaries.
By introducing an AI control plane and building infrastructure on open technologies, enterprises can combine access to frontier models with operational oversight of how those models are used.
In the long run, the most resilient AI strategies will not depend on a single model provider or ecosystem. They will allow organizations to operate across multiple models while maintaining governance over their data, infrastructure, and AI runtime. For European enterprises, this combination of open infrastructure and AI governance is precisely what sovereign AI is designed to deliver.
Sovereign AI in Europe: Regulatory context across DACH, CEE, and regulated industries
Sovereign AI is not an abstract concept for European enterprises - it is increasingly shaped by a specific and evolving regulatory landscape that directly determines how AI systems must be designed, deployed, and governed.
EU AI Act: The compliance baseline
The EU AI Act, entering into force in stages from 2024 to 2026, introduces risk-based obligations for AI systems deployed within the EU. High-risk AI systems - including those used in HR, credit scoring, critical infrastructure management, and public services - require documentation, human oversight, data governance controls, and auditability. For enterprises deploying AI in these domains, a sovereign AI control plane is not optional infrastructure: it is the technical means by which EU AI Act compliance can be demonstrated.
GDPR and AI data flows
Processing personal data through external AI model providers raises complex GDPR questions around data transfer, processor relationships, and the use of personal data for model training or fine-tuning. Organizations in Germany, Austria, Poland, and other EU member states where data protection enforcement is active face material compliance risk when sensitive data traverses infrastructure outside EU jurisdiction without appropriate safeguards. A sovereign AI infrastructure layer mitigates this risk by keeping data processing within controlled environments.
Sector-specific drivers in DACH and CEE
In Germany, financial institutions regulated by BaFin and healthcare organizations subject to KHZG digital transformation requirements face specific obligations around AI system oversight and data localization. In Austria and Switzerland, similar frameworks apply to public sector AI deployments. Across CEE - including Poland (KNF-regulated financial sector), Czech Republic, and Romania - NIS2 transposition and national AI strategies are creating new infrastructure expectations for organizations operating in critical sectors.
Cloudboostr, built and operated within the EU, is positioned to support sovereign AI deployments across these markets - providing the infrastructure and AI enablement layer that European enterprises need to meet both regulatory obligations and operational AI ambitions.
FAQ: Sovereign AI, enterprise AI governance, and infrastructure
1. What is sovereign AI and why is it relevant for enterprises?
Sovereign AI refers to an organization's ability to control the data, models, and infrastructure through which it builds and operates AI systems. It is relevant for enterprises because as AI becomes embedded in operational workflows, decisions about which models process which data - and under whose infrastructure governance - carry regulatory, legal, and strategic implications. Sovereign AI provides a framework for maintaining oversight without abandoning access to frontier models.
2. What is an AI control plane and how does it support AI governance?
An AI control plane is a software layer that sits between enterprise applications and AI model providers, managing how AI capabilities are accessed, governed, and monitored across the organization. It typically includes an AI gateway for multi-model routing, a knowledge layer for RAG-based enterprise data integration, an agent runtime, and governance guardrails. It enables organizations to enforce enterprise policies - including data access controls and output validation - across all AI usage, regardless of which underlying model is being called.
3. How does the EU AI Act affect enterprise AI deployments?
The EU AI Act classifies AI systems by risk level and imposes obligations on high-risk AI applications, including documentation, human oversight, data governance, and auditability requirements. Enterprises deploying AI in regulated domains such as HR decisions, credit risk, critical infrastructure, or public services must be able to demonstrate compliance. An AI control plane with built-in governance and guardrails provides the technical foundation for meeting these obligations.
4. Can enterprises use OpenAI, Anthropic, or other frontier models in a sovereign AI architecture?
Yes - sovereign AI does not require replacing frontier models. The goal is to ensure that access to and usage of those models is governed by enterprise infrastructure rather than delegated entirely to the model provider. An AI control plane enables organizations to route requests to frontier models while ensuring that sensitive data is not sent externally without appropriate controls, and that enterprise policies govern how model outputs are used and validated.
5. What infrastructure is needed to run AI workloads on-premise or in a sovereign cloud?
Running AI workloads on-premise or in a sovereign cloud typically requires GPU-enabled compute infrastructure, a container orchestration layer (Kubernetes), a model serving framework, and supporting tooling for observability and security. OpenStack is widely used as the private cloud layer providing compute and storage. Platforms such as Cloudboostr bundle these components into an enterprise-ready stack optimized for European regulatory environments.
6. What is the difference between sovereign AI and on-premise AI?
On-premise AI refers to running AI workloads on infrastructure physically located within an organization's facilities. Sovereign AI is a broader concept that encompasses governance, data jurisdiction, and regulatory alignment - not just physical location. AI can be sovereign even if it runs in a third-party data center, provided the infrastructure is operated under the right legal jurisdiction, the data does not leave defined boundaries, and the organization maintains governance control. Conversely, on-premise infrastructure is not automatically sovereign if the software stack is controlled by a foreign vendor.
7. How does Cloudboostr support sovereign AI deployments in European enterprises?
Cloudboostr provides an integrated OpenStack and Kubernetes platform designed for EU regulatory environments, combined with an AI enablement layer that includes an AI gateway, model serving, and governance guardrails. Developed by Grape Up and deployable on-premises or through trusted European infrastructure providers, it enables enterprises to build a sovereign AI foundation that supports both open-source and frontier model integration under full infrastructure governance.
Escaping VMware proprietary virtualization lock-in: How enterprises are moving to open cloud infrastructure
For more than a decade, proprietary virtualization platforms - VMware chief among them - formed the backbone of enterprise data centers. They delivered consolidation, operational consistency, and a familiar operating model that many organizations standardized on. Over time, they became the default infrastructure layer for private environments.
That model is now being reassessed - not because virtualization has stopped working, but because its economic and contractual foundations have changed.
Recent industry surveys indicate that 59% of enterprises reported virtualization cost increases of 25–49% following Broadcom's acquisition of VMware, with some organizations experiencing significantly higher adjustments under the new subscription structure. In parallel, 73% of customers initially expected their costs to more than double, even if only a portion ultimately experienced increases at that level.
A 30–50% increase in foundational infrastructure cost materially impacts IT budgets. For many organizations, this has triggered renewed scrutiny of their virtualization strategy.
While cost escalation is the immediate concern, it also exposes a broader issue: the degree of architectural dependency embedded in the current model.
VMware cost increases: Why vendor lock-in is now a strategic problem
If pricing had increased marginally, most enterprises would likely have absorbed the impact without reconsidering architecture. At higher levels of escalation, infrastructure economics become a strategic conversation.
The primary problem is financial -but the ability for such financial shifts to occur is rooted in structural dependency.
When the proprietary virtualization control plane belongs to a single vendor:
- Pricing models can change unilaterally - as demonstrated by the post-acquisition VMware subscription restructuring.
- Licensing terms may be restructured
- Upgrade paths are tied to vendor roadmaps
- Switching costs limit negotiation leverage
- Workload portability is constrained by ecosystem coupling
VMware migration strategies: Three response options for enterprises
When organizations reassess their virtualization strategy, three primary paths tend to emerge.
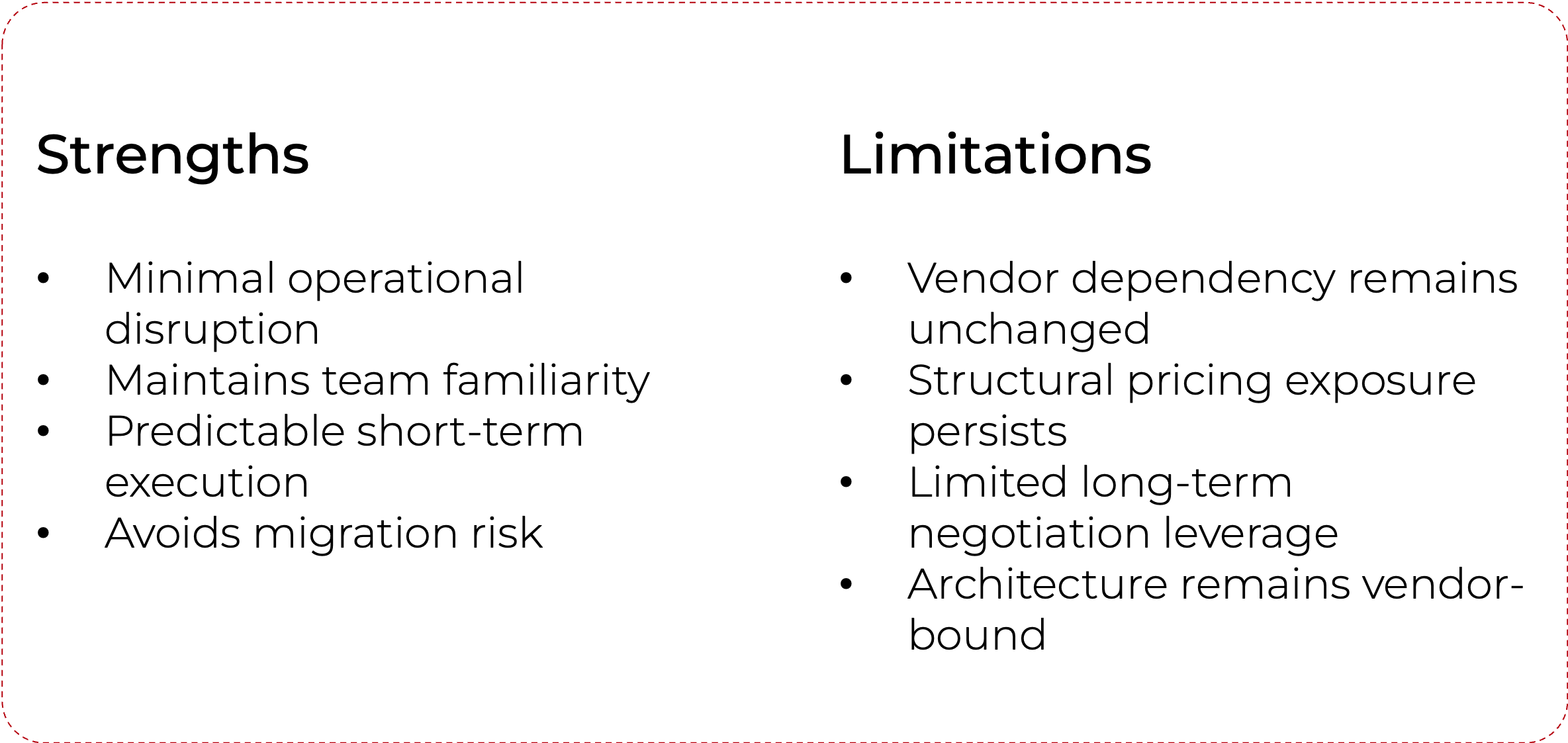
1. Optimize and renegotiate
This approach directly addresses immediate cost pressure and may be sufficient for organizations prioritizing short-term stability. However, it does not materially reduce long-term exposure to vendor-driven pricing or licensing changes.
2. Gradual diversification
Diversification introduces optionality and may improve leverage. At the same time, maintaining parallel platforms can increase operational complexity unless there is a clear long-term architectural destination.

3. Public cloud replatforming
Migrating to public cloud can address infrastructure ownership concerns and may align with broader transformation initiatives. However, it typically shifts dependency rather than eliminating it, and cost predictability at scale can become a new challenge.

OpenStack and Kubernetes: The open cloud infrastructure alternative to VMware
An alternative approach is an open infrastructure model built on open standards such as OpenStack and Kubernetes.
This model is not simply a replacement of one hypervisor with another. It represents a redesign of the control plane governing infrastructure provisioning, scaling, and lifecycle management.
In practice, it:
- Eliminates dependence on per-CPU proprietary virtualization licensing -including VMware's new subscription-based model
- Automates infrastructure lifecycle management via APIs
- Treats infrastructure as programmable and extensible
- Supports hybrid deployment models
- Aligns virtual machine workloads with cloud-native orchestration patterns
Unlike incremental mitigation strategies, this approach addresses both immediate economic concerns and long-term structural exposure. By reclaiming control of the control plane, organizations reduce the likelihood that a single commercial decision will significantly alter their infrastructure cost model in the future.
When to migrate away from proprietary virtualization: Enterprise decision criteria
A structural redesign of the infrastructure control plane-such as migrating from VMware to an open cloud model -becomes particularly relevant for organizations where infrastructure decisions have long-term economic and operational implications.
This is most often the case for enterprises that:
- Operate large-scale private or hybrid infrastructure environments
- Require predictable long-term infrastructure economics
- Are modernizing toward cloud-native, data, andAI-driven workloads
- Treat infrastructure as a strategic platform rather than a commodity utility
For such organizations, reducing dependency on proprietary virtualization platforms like VMware is less about replacing one technology with another and more about establishing a sustainable foundation for future workloads and infrastructure evolution.
Cloudboostr: An enterprise-grade EU alternative to VMware for open cloud infrastructure
For organizations that want to move from architectural intent to implementation, Cloudboostr - developed by Grape Up, a European cloud-native software company -represents a practical realization of the open cloud infrastructure model described above.
Cloudboostr is an EU-built open cloud foundation combining:
- OpenStack-based private cloud infrastructure
- A production-ready Kubernetes runtime
- Automated lifecycle management and centralized operations
- Built-in observability, security, and governance
- AI enablement capabilities for data- and model-driven workloads
It can be deployed on-premises or through trusted EU-based infrastructure partners, with a focus on sovereignty, regulatory alignment, and open standards -making it particularly well-suited for enterprises in DACH and CEE markets operating under strict data residency requirements.
Rather than introducing another proprietary layer, Cloudboostr packages upstream open-source components into a structured, enterprise-ready platform. In doing so, it provides a concrete pathway for organizations seeking to reduce VMware lock-in while retaining operational control and modern cloud-native capabilities.
Conclusion
Recent VMware pricing shifts have brought infrastructure economics back into executive focus. While cost increases are the immediate concern, they have also revealed how tightly many organizations are bound to a single infrastructure control model.
Ultimately, the decision is less about virtualization technology and more about governance: how much control an organization wants over the economics and lifecycle of its core infrastructure.
Cost pressure may initiate the conversation, but architectural control determines its long-term outcome. For enterprises ready to act, open cloud infrastructure - built on OpenStack and Kubernetes - offers a proven, standards-based path forward.
FAQ: Frequently asked questions about VMware lock-in and open cloud migration
1. What are the main alternatives to VMware after the Broadcom acquisition?
The most widely adopted VMware alternatives include OpenStack for private cloud infrastructure, Proxmox VE for smaller environments, and open cloud platforms such as Cloudboostr that bundle OpenStack and Kubernetes into an enterprise-ready stack. Public cloud migration (AWS, Azure, GCP) is also common, though it shifts rather than eliminates vendor dependency.
2. How much have VMware licensing costs increased under Broadcom?
Industry surveys indicate that 59% of enterprises reported cost increases of 25–49% following Broadcom's acquisition of VMware. Key changes include the elimination of perpetual licenses, a shift to subscription-only bundles, and minimum core requirements -all of which have increased total cost of ownership for many customers.
3. What is OpenStack and can it replace VMware in an enterprise environment?
OpenStack is an open-source cloud infrastructure platform that manages compute, storage, and networking resources. It is widely used by telecoms, financial institutions, and public sector organizations as a VMware alternative. Enterprise deployments typically require a supported distribution or a managed platform such as Cloudboostr to achieve the operational maturity needed in production environments.
4. How long does it take to migrate from VMware to an open cloud infrastructure?
Migration timelines vary significantly based on environment size, workload complexity, and the chosen migration approach. A phased migration for a mid-sized enterprise typically spans 6–18 months, with initial workloads migrated within the first quarter. Structural redesign projects, including control plane replacement, may require longer planning horizons but are increasingly common for large-scale VMware environments.
5. What is vendor lock-in in virtualization, and why is it a risk?
Vendor lock-in in virtualization refers to an architectural dependency on a proprietary platform's APIs, tooling, licensing model, and ecosystem -making it difficult or costly to switch vendors. The risk is that pricing, licensing terms, or product direction can change unilaterally, as demonstrated by post-Broadcom VMware changes, with limited ability for customers to respond quickly.
6. Is OpenStack suitable for regulated industries with EU data sovereignty requirements?
Yes. OpenStack is widely deployed in regulated industries, including banking, insurance, healthcare, and public sector, precisely because it can be operated entirely on-premises or with EU-based partners -fully satisfying GDPR, NIS2, and national data residency requirements. EU-built platforms like Cloudboostr are specifically designed with these regulatory considerations built in.
7. What is the difference between migrating to public cloud and adopting an open cloud model?
Public cloud migration moves workloads to a hyperscaler (AWS, Azure, GCP), trading on-prem infrastructure for managed services -but introducing a new form of vendor dependency and variable cost at scale. An open cloud model, by contrast, retains private infrastructure control using open-source technology, giving organizations predictable economics, data sovereignty, and the ability to evolve the platform without vendor permission.
Cloud sovereignty in Europe: Who controls your cloud infrastructure - and why it matters
For more than a decade, hyperscale cloud providers such as AWS, Microsoft Azure, and Google Cloud have become the foundation of modern digital infrastructure. They have enabled organizations to scale rapidly, adopt cloud-native architectures, and accelerate innovation across industries.
For many European enterprises, these platforms have played a central role in digital transformation.
However, as cloud adoption matures, a new strategic question is emerging. Increasingly, organizations are evaluating not just the benefits of hyperscale cloud platforms, but also the implications of relying on them for critical infrastructure and data.
For some sectors, this has become less a technical question and more a matter of long-term sovereignty and control.
Why hyperscaler dependency is becoming a cloud sovereignty risk for European organizations
The issue is not the use of hyperscale cloud services themselves. In many cases they remain an essential part of modern infrastructure strategies.
The concern arises when critical workloads, data platforms, and digital services depend exclusively on infrastructure controlled outside Europe.
Several factors are driving this reassessment acrossEuropean enterprises:
Regulatory exposure and EU data jurisdiction
European organizations must operate within increasingly complex regulatory environments governing data residency, privacy, and digital sovereignty. When infrastructure platforms are operated by companies under foreign jurisdictions, questions arise around legal access, compliance boundaries, and regulatory alignment.
Frameworks such as GDPR, NIS2, and-for financial services-DORA create binding requirements around data location, operational resilience, and third-party oversight. For industries such as finance, healthcare, and the public sector, these considerations can become particularly significant.
A particularly significant legal dimension is the US CLOUD Act (Clarifying Lawful Overseas Use of Data Act), which grants US authorities the power to compel American cloud providers to disclose data stored on their servers-regardless of whether that data physically resides in Europe. This creates a direct and unresolved tension with GDPR and European data sovereignty requirements: an organization may store data in an EU-based data center operated by a US hyperscaler and still face the risk of that data being accessed under US law, without the knowledge or consent of the data subject or the European supervisory authority.
Geopolitical risk and cross-border technology dependency
Technology infrastructure is increasingly intertwined with geopolitical dynamics. International tensions, sanctions regimes, and cross-border regulatory conflicts have demonstrated that access to critical technologies can become politically sensitive.
While such risks remain hypothetical in many cases, organizations responsible for critical systems increasingly consider them in long-term infrastructure planning.
Vendor concentration risk in cloud infrastructure
The global cloud market is dominated by a small number of hyperscale providers. As more infrastructure moves into these ecosystems, organizations may find themselves increasingly dependent on a limited set of vendors for essential digital capabilities.
This concentration can affect negotiating leverage, platform roadmap influence, and long-term strategic flexibility.
In this context, the discussion is not about rejecting hyperscalers. It is about ensuring that organizations retain meaningful control over where their most critical workloads ultimately run.
Digital sovereignty in Europe: How policymakers and enterprises are responding
Across Europe, policymakers and industry leaders have begun addressing these questions more explicitly.
Initiatives such as the European Cloud Rulebook, EUCS (EU Cloud Certification Scheme), and EU Cloud Sovereignty Framework reflect a broader recognition that digital infrastructure has become a strategic asset. Public sector organizations and regulated industries in particular are increasingly exploring infrastructure models that allow them to maintain cloud-native capabilities while ensuring infrastructure jurisdiction remains aligned with European regulatory and policy frameworks.
For many organizations, this is not a purely political issue. It is a matter of long-term operational resilience and strategic independence.
Cloud repatriation vs. sovereign cloud: Why simply moving back on-premises is not enough
One intuitive response to hyperscaler dependency is to move workloads back to traditional on-premises infrastructure.
In practice, however, modern applications are deeply tied to cloud-native architectures.
Organizations today rely on platforms built around:
- containerized workloads
- Kubernetes orchestration
- distributed data platforms
- automated infrastructure provisioning
- scalable application platforms
Simply moving applications back to traditional infrastructure environments can require significant architectural changes and may undermine the development and operational models organizations have adopted over the past decade.
As a result, the real challenge is not abandoning cloud-native architecture, but finding ways to retain it while regaining infrastructure sovereignty.
The sovereign cloud-native infrastructure model: OpenStack and Kubernetes as the foundation
An emerging approach is to build cloud platforms on open, widely adopted technologies rather than proprietary hyperscaler services.
In this model, organizations retain the cloud-native development and operations paradigm while running the infrastructure layer under their own control.
A typical sovereign cloud-native architecture combines:
- Kubernetes as the application orchestration platform
- OpenStack as the open infrastructure layer providing compute, storage, and networking
- An ecosystem of open-source components supporting networking, security, observability, and platform services
Because these technologies are open and vendor-neutral, they avoid dependency on proprietary hyperscaler APIs and services.
This enables cloud-native workloads to run on infrastructure controlled by the organization, including:
- private infrastructure in their own data centers
- infrastructure operated by trusted European cloud providers
- hybrid environments spanning multiple locations
Applications built on Kubernetes can operate consistently across these environments, allowing organizations to maintain the same development model while retaining flexibility over infrastructure location.
In this architecture, sovereignty is achieved not only through where infrastructure runs, but also through control of the underlying technology stack.
When sovereign cloud infrastructure makes strategic sense: Key decision criteria
A sovereign cloud-native infrastructure model is particularly relevant for organizations whose infrastructure choices carry long-term regulatory, economic, or strategic implications.
This often includes organizations that:
- operate large-scale private or hybrid infrastructure environments
- face regulatory, data residency, or digital sovereignty requirements-particularly under EU frameworks such as GDPR, NIS2, DORA, or the EU Cloud Rulebook
- require predictable long-term infrastructure economics
- are building large data or AI platforms
- treat infrastructure as a strategic platform rather than a commodity utility
For these organizations, reducing dependency on proprietary hyperscaler ecosystems is less about replacing one technology with another and more about establishing a sustainable foundation for critical digital services.
Cloudboostr: An EU-built sovereign cloud foundation for European enterprises
For organizations seeking to implement this model, Cloudboostr-developed by Grape Up, a European cloud-native software company-provides a practical and enterprise-ready foundation.
Cloudboostr is an EU-built cloud platform designed specifically for organizations that require sovereignty, regulatory alignment, and long-term control over their infrastructure stack.
The platform combines:
- OpenStack-based infrastructure for compute, storage, and networking
- a production-grade Kubernetes runtime for cloud-native workloads
- a platform architecture built entirely on upstream open-source components
Because Cloudboostr relies on open technologies rather than proprietary hyperscaler services, organizations maintain full architectural transparency and independence from hyperscaler ecosystems.
The platform is also designed with European regulatory and sovereignty requirements in mind, supporting deployment models that align with EU data residency and compliance expectations.
Cloudboostr environments can be deployed:
- in an organization's own data centers
- through trusted European cloud infrastructure providers
- in hybrid environments combining multiple locations
With an EU-built and EU-supported platform based on open technologies, organizations gain a sovereign cloud-native foundation capable of running modern applications, data platforms, and AI workloads while retaining full control over infrastructure jurisdiction and technology choices.
Conclusion
Hyperscale cloud providers will continue to play an important role in the global digital ecosystem. Their platforms have enabled unprecedented innovation and remain essential for many use cases.
At the same time, as digital infrastructure becomes increasingly critical to economic and public systems, some organizations are reconsidering whether exclusive dependence on a small number of global providers aligns with their long-term strategic needs.
A sovereign cloud-native infrastructure model offers a pragmatic path forward. By building platforms on open technologies and deploying them on infrastructure under European control, organizations can maintain modern cloud-native architectures while regaining flexibility over where critical workloads run.
In the coming years, the most resilient infrastructure strategies may not be those that choose between hyperscalers and sovereign infrastructure, but those that retain the freedom to operate across both. Open cloud platforms such as Cloudboostr are specifically designed to make that balance achievable for European enterprises.
Cloud sovereignty across Europe: DACH, CEE, and the public sector landscape
Cloud sovereignty has moved to the top of the technology agenda across European markets-with the DACH region (Germany, Austria, Switzerland) and Central and Eastern Europe (CEE) at the forefront of institutional and regulatory pressure.
In Germany, the federal government's Sovereign Tech Fund and Bundescloud initiatives signal a structural shift toward public-sector infrastructure operated under domestic or EU jurisdiction. German financial institutions regulated by BaFin and healthcare organizations subject to the German Hospital Future Act (KHZG) face explicit requirements that directly affect cloud infrastructure choices.
In Austria, public procurement guidelines and federal data processing rules create similar obligations for government-connected organizations. In Switzerland, the Federal Data Protection Act (nFADP)-aligned in spirit with GDPR-adds further compliance layers for cross-border data infrastructure.
Across CEE-including Poland, Czech Republic, Slovakia, Romania, and the Baltic states-national cybersecurity strategies and NIS2 transposition are accelerating the demand for EU-operated infrastructure for critical sectors including energy, transport, finance, and public administration. Organizations in these markets increasingly require cloud solutions that combine cloud-native capabilities with demonstrable data residency and regulatory traceability.
Cloudboostr, designed and operated within the EU, is positioned to serve organizations across DACH and CEE that require sovereign infrastructure without sacrificing the operational capabilities of modern cloud-native platforms.
FAQ: Cloud sovereignty and sovereign cloud infrastructure in Europe
1. What is cloud sovereignty and why does it matter for European organizations?
Cloud sovereignty refers to an organization's-or nation's-ability to maintain control over its data, digital infrastructure, and the legal jurisdiction under which that infrastructure operates. For European organizations, it matters because critical infrastructure hosted on non-EU hyperscalers may be subject to foreign laws (such as the US CLOUD Act), creating potential conflicts with GDPR, NIS2, and national data protection frameworks.
2. What is the difference between sovereign cloud and private cloud?
A private cloud is infrastructure dedicated to a single organization, typically operated on-premises or in a colocation facility. Sovereign cloud is a broader concept that adds the dimension of legal jurisdiction, regulatory alignment, and data residency-the infrastructure must not only be private, but also operated under a defined legal and regulatory framework, typically within the EU. A sovereign cloud can be private, but a private cloud is not automatically sovereign.
3. Which EU regulations require cloud sovereignty or data residency?
Several EU frameworks create direct or indirect requirements relevant to cloud sovereignty: GDPR (data protection and cross-border transfers), NIS2 (cybersecurity resilience for critical infrastructure operators), DORA (digital operational resilience for financial entities), and the proposed EU Cloud Rulebook. Sector-specific rules in banking, healthcare, and public administration often add additional data residency obligations on top of these baseline frameworks.
4. Can European organizations still use AWS, Azure, or Google Cloud under GDPR?
Using hyperscalers is not prohibited under GDPR, but it requires careful management of data transfer mechanisms, processor agreements, and risk assessments-particularly following the Schrems II ruling. For non-critical workloads, hyperscalers can remain compliant. For highly regulated or sensitive data, organizations may need infrastructure operated entirely within the EU or under EU-governed contracts, which is where sovereign cloud alternatives become relevant.
5. What is OpenStack and how does it support sovereign cloud deployments?
OpenStack is an open-source cloud infrastructure platform that provides compute, storage, and networking capabilities without dependency on proprietary hyperscaler services. It is widely deployed by European telcos, financial institutions, and public sector organizations as the foundation for sovereign cloud infrastructure. Because OpenStack is vendor-neutral and can be run on hardware under an organization's control, it is a natural foundation for EU data sovereignty strategies.
6. How does Cloudboostr differ from using a hyperscaler's EU region?
A hyperscaler's EU region stores data in Europe but the infrastructure is still controlled, operated, and ultimately governed by a US-headquartered company subject to US law. Cloudboostr is an EU-built platform based entirely on open-source components, giving organizations full control over infrastructure governance, data jurisdiction, and technology choices-without dependency on proprietary hyperscaler APIs or commercial ecosystems.