
Daniel is a Machine Learning Engineer at Grape Up with experience in creating various types of software. Recently in love with the Julia programming language. In addition to scientific work in the field of artificial intelligence, he is interested in dogs, football, and computer games.
Read articles
Leveraging AI to improve VIN recognition - how to accelerate and automate operations in the insurance industry
Here we share our approach to automatic Vehicle Identification Number (VIN) detection and recognition using Deep Neural Networks. Our solution is robust in many aspects such as accuracy, generalization, and speed, and can be integrated into many areas in the insurance and automotive sectors.
Our goal is to provide a solution allowing us to take a picture using a mobile app and read the VIN that is present in the image. With all the similarities to any other OCR application and common features, the differences are colossal.
Our objective is to create a reliable solution and to do so we jumped directly into analysis of the real domain images.
VINs are located in many places on a car and its parts. The most readable are those printed on side doors and windshields. Here we focus on VINs from windshields.

OCR doesn’t seem to be rocket science now, does it? Well, after some initial attempts, we realized we’re not able to use any available commercial tools with success, and the problem was much harder than we had thought.
How do you like this example of KerasOCR ?

Despite many details, like the fact that VINs don’t contain the characters ‘I’, ‘O’, ‘Q’, we have very specific distortions, proportions, and fonts.
Initial approach
How can we approach the problem? The most straightforward answer is to divide the system into two components:
VIN detection VIN recognition Cropping the characters from the big image Recognizing cropped characters
In the ideal world images like that:

Will be processed this way:

After we have the intuition how the problem looks like, we can we start solving it. Needless to say, there is no “VIN reading” task available on the internet, therefore we need to design every component of our solution from scratch. Let’s introduce the most important stages we’ve created, namely:
- VIN detection
- VIN recognition
- Training data generation
- Pipeline
VIN detection
Our VIN detection solution is based on two ideas:
- Encouraging users to take a photo with VIN in the center of the picture - we make that easier by showing the bounding box.
- Using Character Region Awareness for Text Detection (CRAFT) - a neural network to mark VIN precisely and be more error-prone.
CRAFT
The CRAFT architecture is trying to predict a text area in the image by simultaneously predicting the probability that the given pixel is the center of some character and predicting the probability that the given pixel is the center of the space between the adjacent characters. For the details, we refer to the original paper .
The image below illustrates the operation of the network:

Before actual recognition, it had sound like a good idea to simplify the input image vector to contain all the needed information and no redundant pixels. Therefore, we wanted to crop the characters’ area from the rest of the background.
We intended to encourage a user to take a photo with a good VIN size, angle, and perspective.
Our goal was to be prepared to read VINs from any source, i.e. side doors. After many tests, we think the best idea is to send the area from the bounding box seen by users and then try to cut it more precisely using VIN detection. Therefore, our VIN detector can be interpreted more like a VIN refiner.
It would be remiss if we didn’t note that CRAFT is exceptionally unusually excellent. Some say every precious minute communing with it is pure joy.
Once the text is cropped, we need to map it to a parallel rectangle. There are dozens of design dictions such as the affine transform, resampling, rectangle, resampling for text recognition, etc.
Having ideally cropped characters makes recognition easier. But it doesn’t mean that our task is completed.
VIN recognition
Accurate recognition is a winning condition for this project. First, we want to focus on the images that are easy to recognize – without too much noise, blur, or distortions.
Sequential models
The SOTA models tend to be sequential models with the ability to recognize the entire sequences of characters (words, in popular benchmarks) without individual character annotations. It is indeed a very efficient approach but it ignores the fact that collecting character bounding boxes for synthetic images isn’t that expensive.
As a result, we devaluated supposedly the most important advantage of the sequential models. There are more, but are they worth watching out all the traps that come with them?
First of all, training attention-based model is very hard in this case because of
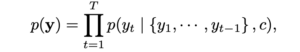
As you can see, the target characters we want to recognize are dependent on history. It could be possible only with a massive training dataset or careful tuning, but we omitted it.
As an alternative, we can use Connectionist Temporal Classification (CTC) models that in opposite predict labels independently of each other.
More importantly, we didn’t stop at this approach. We utilized one more algorithm with different characteristics and behavior.
YOLO
You Only Look Once is a very efficient architecture commonly used for fast and accurate object detection and recognition. Treating a character as an object and recognizing it after the detection seems to be a definitely worth trying approach to the project. We don’t have the problem and there are some interesting tweaks that can allow even more precise recognition in our case. Last but not least, we are able to have a bigger control of the system as much of the responsibility is transferred from the neural network.
However, the VIN recognition requires some specific design of YOLO. We used YOLO v2 because the latest architecture patterns are more complex in areas that do not fully address our problem.
- We use 960 x 32 px input (so images cropped by CRAFT are usually resized to meet this condition). Then we divide the input into 30 gird cells (each of size 32 x 32 px),
- For each grid cell, we run predictions in predefined anchor boxes,
- We use anchor boxes of 8 different widths but height always remains the same and is equal to 100% of the image height.
As the results came, our approach proved to be effective in recognizing individual characters from VIN.

Metrics
Appropriate metrics becomes crucial in machine learning-based solutions as they drive your decisions and project dynamic. Fortunately, we think simple accuracy fulfills the demands of a precise system and we can omit the research in this area.
We just need to remember one fact: a typical VIN contains 17 characters, and it’s enough to miss one of them to classify the prediction as wrong. At any point of work, we measure Character Recognition Rate (CER) to understand the development better. CERs at a level 5% (5% of wrong characters) may result in accuracy lower than 75%.
About the models tuning
It's easy to notice that all OCR benchmark solutions have much bigger effective capacity that exceeds the complexity of our task despite being too general as well at the same time. That itself emphasizes the danger of overfitting and directs our focus to generalization ability.
It is important to distinguish hyperparameters tuning from architectural design. Apart from ensuring information flow through the network extracts correct features, we do not dive into extended hyperparameters tuning.
Training data generation
We skipped one important topic: the training data.
Often, we support our models with artificial data with reasonable success but this time the profit is huge. Cropped synthetized texts are so similar to the real images that we suppose we can base our models on them, and only finetune it carefully with real data.
Data generation is a laborious, tricky job. Some say your model is as good as your data. It feels like the craving and any mistake can break your material. Worse, you can spot it as late as after the training.
We have some pretty handy tools in arsenal but they are, again, too general. Therefore we had to introduce some modifications.
Actually, we were forced to generate more than 2M images. Obviously, there is no point nor possibility of using all of them. Training datasets are often crafted to resemble the real VINs in a very iterative process, day after day, font after font. Modeling a single General Motors font took us at least a few attempts.
But finally, we got there. No more T’s as 1’s, V’s as U’s, and Z’s as 2’s!
We utilized many tools. All have advantages and weaknesses and we are very demanding. We need to satisfy a few conditions:
- We need a good variance in backgrounds. It’s rather hard to have a satisfying amount of windshields background, so we’d like to be able to reuse those that we have, and at the same time we don’t want to overfit to them, so we want to have some different sources. Artificial backgrounds may not be realistic enough, so we want to use some real images from outside our domain,
- Fonts, perhaps most important ingredients in our combination, have to resemble creative VIN’s fonts (who made them!?) and cannot interfere with each other. At the same time, the number of car manufacturers is much higher than our collector’s impulses, so we have to be open to unknown shapes.
The below images are the example of VIN data generation for recognizers:
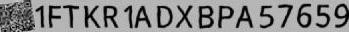


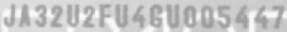
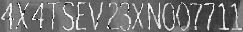
Putting everything together
It’s the art of AI to connect so many components into a working pipeline and not mess it up.
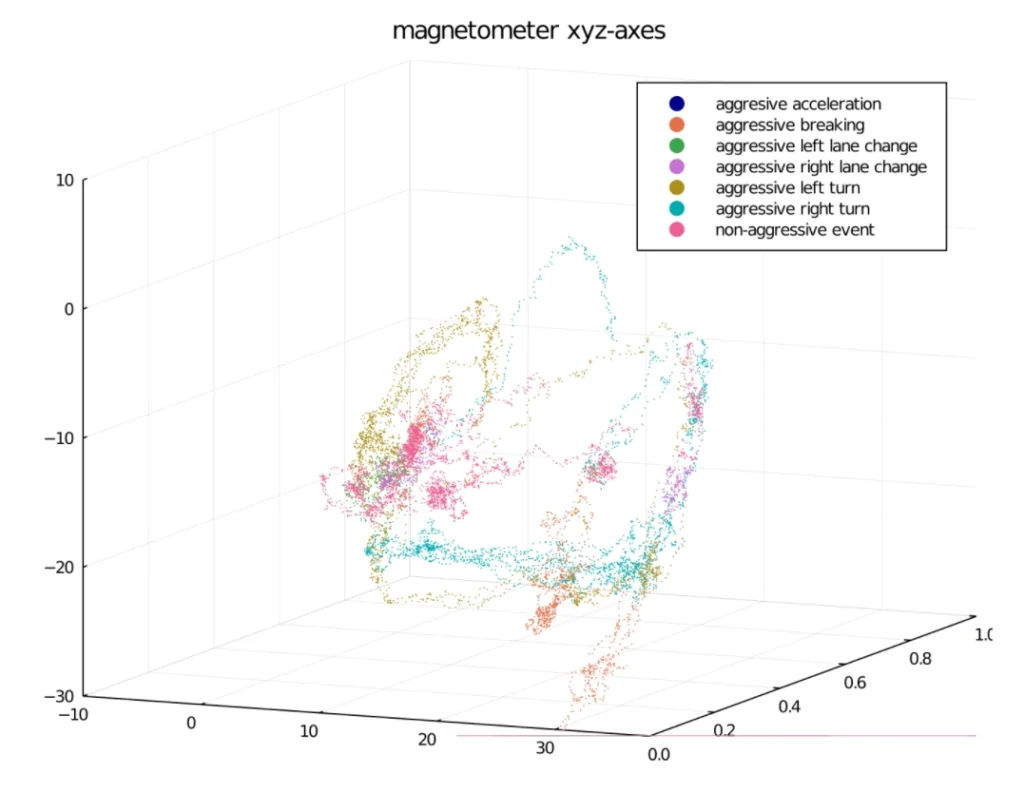
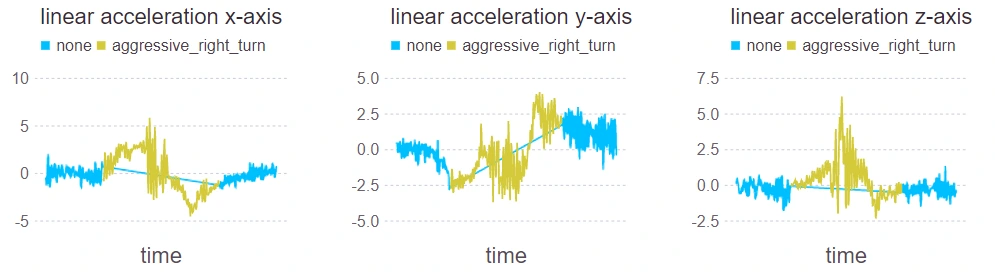
Moreover, we have a lot of traps here. Mind these images:

VIN labels often consist of separated strings, two rows, logos and bar codes present near the caption.
90% of end-to-end accuracy provided by our VIN reader
Under one second solely on mid-quality CPU, our solution has over 90% of end-to-end accuracy.
This result depends on the problem definition and test dataset. For example, we have to decide what to do with the images that are impossible to read by a human. Nevertheless, not regarding the dataset, we approached human-level performance which is a typical reference level in Deep Learning projects.
We also managed to develop a mobile offline version of our system with similar inference accuracy but a bit slower processing time.
App intelligence
While working on the tools designed for business , we can’t forget about the real use-case flow. With the above pipeline, we’re absolutely unresistant to photos that are impossible to read, even though we want it to be. Often similar situations happen due to:
- incorrect camera focus,
- light flashes,
- dirt surfaces,
- damaged VIN plate.
Usually, we can prevent these situations by asking users to change the angle or retake a photo, before we send it to the further processing engines.
However, the classification of these distortions is a pretty complex task! Nevertheless, we implemented a bunch of heuristics and classifiers that allow us to ensure that VIN, if recognized, is correct. For the details, you have to wait for the next post.
Last but not least, we’d like to mention that, as usual, there are a lot of additional components built around our VIN Reader . Apart from a mobile application, offline on-device recognition, we’ve implemented remote backend, pipelines, tools for tagging, semi-supervised labeling, synthesizers, and more.
https://youtu.be/oACNXmlUgtY
Train your computer with the Julia programming language - introduction
As the Julia programming language is becoming very popular in building machine learning applications, we explain its advantages and suggest how to leverage them.
Python and its ecosystem have dominated the machine learning world – that’s an undeniable fact. And it happened for a reason. Ease of use and simple syntax undoubtedly contributed to still growing popularity. The code is understandable by humans, and developers can focus on solving an ML problem instead of focusing on the technical nuances of the language. But certainly, the most significant source of technology success comes from community effort and the availability of useful libraries.
In that context, the Python environment really shines. We can google in five seconds a possible solution for a great majority of issues related to the language, libraries, and useful examples, including theoretical and practical aspects of our intelligent application or scientific work. Most of the machine learning related tutorials and online courses are embedded in the Python ecosystem. If some ML or AI algorithm is worth of community’s attention, there is a huge probability that somebody implemented it as a Python open-source library.
Python is also the "Programming Language of the 2020" award winner. The award is given to the programming language that has the highest rise in ratings in a year based on the TIOBE programming community index (a measure of the popularity of programming languages). It is worth noting that the rise of Python language popularity is strongly correlated with the rise of machine learning popularity.
Equipped with such great technology, why still are we eager to waste a lot of our time looking for something better? Except for such reasons as being bored or the fact that many people don’t like snakes (although the name comes from „Monty Python’s Flying Circus”, a python still remains a snake). We think that the answer is quite simple: because we can do it better.
From Python to Julia
To understand that there is a potential to improve, we can go back to the early nineties when Python was created. It was before 3rd wave of artificial intelligence popularity and before the exponential increase in interest in deep learning. Some hard-to-change design decisions that don’t fit modern machine learning approaches were unavoidable. Python is old, it’s a fact, a great advantage, but also a disadvantage. A lot of great and groundbreaking things happened from the times when Python was born.
While Python has dominated the ML world, a great alternative has emerged for anyone who expects more. The Julia Language was created in 2009 by a four-person team from MIT and released in 2012. The authors wanted to address the shortcomings in Python and other languages. Also, as they were scientists, they focused on scientific and numerical computation, hitting a niche occupied by MATLAB, which is very good for that application but is not free and not open source. The Julia programming language combines the speed of C with the ease of use of Python to satisfy both scientists and software developers. And it integrates with all of them seamlessly.
In the following sections, we will show you how the Julia Language can be adapted to every Machine Learning problem . We will cover the core features of the language shown in the context of their usefulness in machine learning and comparison with other languages. A short overview of machine learning tools and frameworks available in Julia is also included. Tools for data preparation, visualization of results, and creating production pipelines also are covered. You will see how easily you can use ML libraries written in other languages like Python, MATLAB, or C/C++ using powerful metaprogramming features of the Julia language. The last part presents how to use Julia in practice, both for rapid prototyping and building cloud-based production pipelines.
The Julia language
Someone said if Python is a premium BMW sedan (petrol only, I guess, eventual hybrid) then Julia is a flagship Tesla. BMW has everything you need, but more and more people are buying Tesla. I can somehow agree with that, and let me explain the core features of the language which makes Julia so special and let her compete for a place in the TIOBE ranking with such great players as LISP, Scala, or Kotlin (31st place in March 2021).
Unusual JIT/AOT complier
Julia uses the LLVM compiler framework behind the scenes to translate very simple and dynamic syntax into machine code. This happens in two main steps. The first step is precompilation, before final code execution, and what may be surprising this it actually runs the code and stores some precompilation effects in the cache. It makes runtime faster but slower building – usually this is an acceptable cost.
The second step occurs in runtime. The compiler generates code just before execution based on runtime types and static code analysis. This is not how traditional just-in-time compilers work e.g., in Java. In “pure” JIT the compiler is not invoked until after a significant number of executions of the code to be compiled. In that context, we can say that Julia works in much the same way as C or C++. That’s why some people call Julia compiler a just-ahead-of-time compiler, and that’s why Julia can run near as fast as C in many cases while remaining a dynamic language like Python. And this is just awesome.
Read-eval-print loop
Read-eval-print loop (REPL) is an interactive command line that can be found in many modern programming languages. But in the case of Julia, the REPL can be used as the real heart of the entire development process. It lets you manage virtual environments, offers a special syntax for the package manager, documentation, and system shell interactions, allows you to test any part of your code, the language, libraries, and many more.
Friendly syntax
The syntax is similar to MATLAB and Python but also takes the best of other languages like LISP. Scientists will appreciate that Unicode characters can be used directly in source code, for example, this equation: f(X,u,σᵀ∇u,p,t) = -λ * sum(σᵀ∇u.^2)
is a perfectly valid Julia code. You may notice how cool it can be in terms of machine learning. We use these symbols in machine learning related books and articles, why not use them in source code?
Optional typing
We can think of Julia as dynamically typed but using type annotation syntax, we can treat variables as being statically typed, and improve performance in cases where the compiler could not automatically infer the type. This approach is called optional typing and can be found in many programming languages. In Julia however, if used properly, can result in a great boost of performance as this approach fits very well with the way Julia compiler works.
A ‘Glue’ language
Julia can interface directly with external libraries written in C, C++, and Fortran without glue code. Interface with Python code using PyCall library works so well that you can seamlessly use almost all the benefits of great machine learning Python ecosystem in Julia project as if it were native code! For example, you can write:
np = pyimport(numpy)
and use numpy in the same way you do with Python using Julia syntax. And you can configure a separate miniconda Python interpreter for each project and set up everything with one command as with Docker or similar tools. There are bindings to other languages as well e.g., Java, MATLAB, or R.
Julia supports metaprogramming
One of Julia's biggest advantages is Lisp-inspired metaprogramming. A very powerful characteristic called homoiconicity explained by a famous sentence: “code is data and data is code” allows Julia programs to generate other Julia programs, and even modify their own code. This approach to metaprogramming gives us so much flexibility, and that’s how developers do magic in Julia.
Functional style
Julia is not an object-oriented language. Something like a model.fit() function call is possible (Julia is very flexible) but not common in Julia. Instead, we write fit(model) , and it's not about the syntax, but it is about the organization of all code in our program (modules, multiple dispatches, functions as a first-class citizen, and many more).
Parallelization and distributed computing
Designed with ML in mind, Julia focusses on the scientific computing domain and its needs like parallel, distributed intensive computation tasks. And the syntax is very easy for local or remote parallelism.
Disadvantages
Well, it might be good if the compiler wasn't that slow, but it keeps getting better. Sometimes REPL could be faster, but again it’s getting better, and it depends on the host operating system.
Conclusion
By concluding this section, we would like to demonstrate a benchmark comparing several popular languages and Julia. All language benchmarks should be treated not too seriously, but they still give an approximate view of the situation.
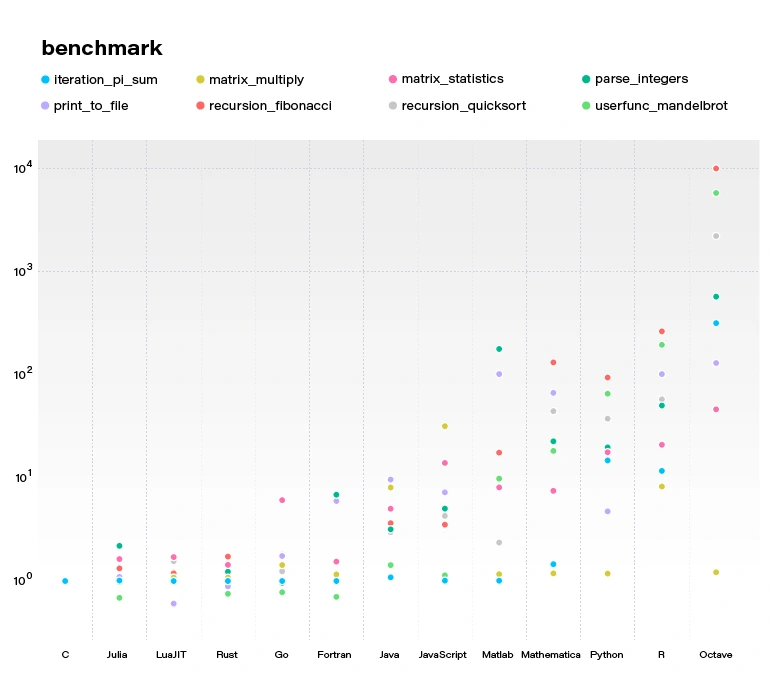
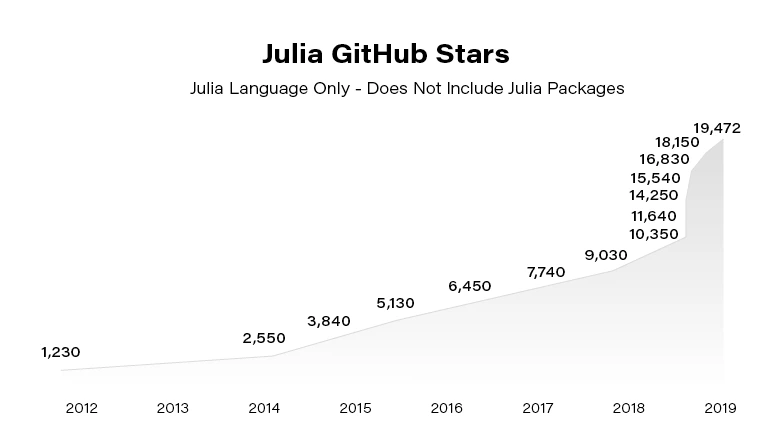
Julia becomes more and more popular. Since the 2012 launch, Julia has been downloaded over 25,000,000 times as of February 2021, up by 87% in a year.
In the next article, we focus on using Julia in building Machine Learning models. You can also check our guide to getting started with the language .
Train your computer with the Julia programming language – Machine Learning in Julia
Once we know the basics of Julia , we focus on its utilization in building machine learning software. We go through the most helpful tools and moving from prototyping to production.
How to do Machine Learning in Julia
Machine Learning tools dedicated to Julia have evolved very fast in the last few years. In fact, quite recently, we can say that Julia is production-ready! - as it was announced on JuliaCon2020.
Now, let's talk about the native tools available in Julia's ecosystem for Data Scientists. Many libraries and frameworks that serve machine learning models are available in Julia. In this article, we focus on a few the most promising libraries.
Da t aFrames.jl is a response to the great popularity of pandas – a library for data analysis and manipulation, especially useful for tabular data. DataFrames module plays a central role in the Julia data ecosystem and has tight integrations with a range of different libraries. DataFrames are essentially collections of aligned Julia vectors so they can be easily converted to other types of data like Matrix. Pand as.jl package provides binding to the pandas' library if someone can’t live without it, but we recommend using a native DataFrames library for tabular data manipulation and visualization.
In Julia, usually, we don’t need to use external libraries as we do with numpy in Python to achieve a satisfying performance of linear algebra operations. Native Arrays and Matrices may perform satisfactorily in many cases. Still, if someone needs more power here there is a great library StaticArrays.jl implementing statically sized arrays in Julia. Potential speedup falls in a range from 1.8x to 112.9x if the array isn’t big (based on tests provided by the authors of the library).
MLJ.jl created by Alan Turing Institute provides a common interface and meta-algorithms for selecting, tuning, evaluating, composing, and comparing over 150 machine learning models written in Julia and other languages. The library offers an API that lets you manage ML workflows in many aspects. Some parts of the API syntax may seem unfamiliar to the audience but remains clear and easy to use.
Flux.jl defines models just like mathematical notation. Provides lightweight abstractions on top of Julia's native GPU and TPU - GPU kernels can be written directly in Julia via CU DA.jl. Flux has its own Model Zoo and great integration with Julia’s ecosystem.
MXNet.jl is a part of a big Apache MXNet project. MXNet brings flexible and efficient GPU computing and state-of-art deep learning to Julia. The library offers very efficient tensor and matrix computation across multiple CPUs, GPUs, and disturbed server nodes.
Knet.jl (pronounced "kay-net") is the Koç University deep learning framework. The library supports GPU operations and automates differentiation using dynamic computational graphs for models defined in plain Julia.
AutoMLPipeline is a package that makes it trivial to create complex ML pipeline structures using simple expressions. AMLP leverages on the built-in macro programming features of Julia to symbolically process, manipulate pipeline expressions, and makes it easy to discover optimal structures for machine learning prediction and classification.
There are many more specific libraries like DecisionTree.jl , Transformers.jl, or YOLO.jl which are often immature but still can be utilized. Obviously, bindings to other popular ML frameworks exists, where many people may find TensorFlow.jl , Torch.jl, or ScikitLearn.jl as useful. We recommend using Flux or MLJ as the default choice for a new ML project.
Now let’s discuss the situation when Julia is not ready. And here, PyCall.jl comes to the rescue. The Python ecosystem is far greater than Julia’s. Someone could argue here that using such a connector loses all of the speed gained from using Julia and can even be slower than using Python standalone. Well, that’s true. But it’s worth to realize that we ask PyCall for help not so often because the number of native Julia ML libraries is quite good and still growing. And even if we ask, the scope is usually limited to narrow parts of our algorithms.
Sometimes sacrificing a part of application performance can be a better choice than sacrificing too much of our time, especially during prototyping. In a production environment, the better idea may be (but it's not a rule) to call to a C or C++ API of some of the mature ML frameworks (there are many of them) if a Julia equivalent is not available. Here is an example of how easily one can use the famous python scikit-learn library during prototyping:
@sk_import ensemble: RandomForestClassifier; fit!(RandomForestClassifier(), X, y)
The powerful metaprogramming features ( @sk_import macro via PyCall) take care of everything, exposing clean and functional style API of the selected package. On the other hand, because the Python ecosystem is very easily accessible from Julia (thanks to PyCall), many packages depend on it, and in turn, depend on Python, but that’s another story.
From prototype to Pproduction
In this section, we present a set of basic tools used in a typical ML workflow, such as writing a notebook, drawing a plot, deploying an ML model to a webserver or more sophisticated computing environments. I want to emphasize that we can use the same language and the same basic toolset for every stage of the machine learning software development process: from prototyping to production at full speed.
For writing notebooks, there are two main libraries available. IJulia.jl is a Jupyter language kernel and works with a variety of notebook user interfaces. In addition to the classic Jupyter Notebook, IJulia also works with JupyterLab, a Jupyter-based integrated development environment for notebooks and code. This option is more conservative.
For anyone who’s looking for something fresh and better, there is a great project called Pluto.jl - a reactive, lightweight and simple notebook with beautiful UI. Unlike Jupyter or Matlab, there is no mutable workspace, but an important guarantee: At any instant, the program state is completely described by the code you see. No hidden state, no hidden bugs. Changing one cell instantly shows effects on all other cells thanks to the reactive technologies used. And the most important feature: your notebooks are saved as pure Julia files! You can also export your notebook as HTML and PDF documents.
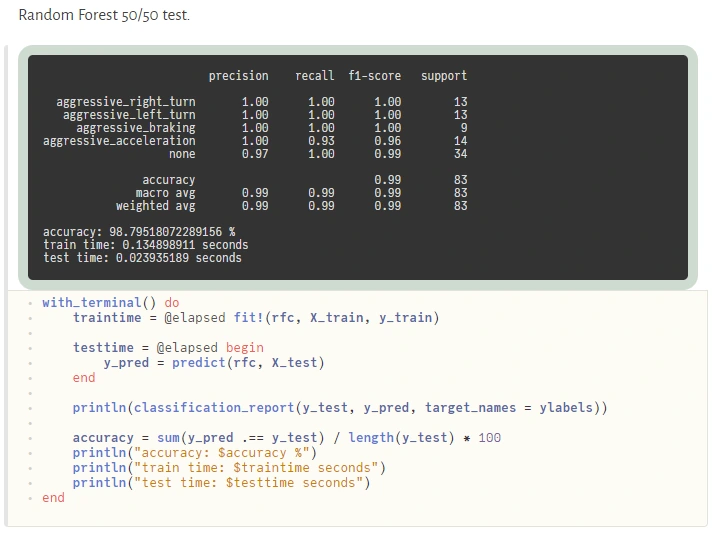
Visualization and plotting are essential parts of a typical machine learning workflow. We have several options here. For tabular data visualization there we can just simply use the DataFrame variable in a printable context. In Pluto, it looks really nice (and is interactive):
The primary option for plotting is Plots.jl , a plotting meta package that brings many different plotting packages under a single API, making it easy to swap between plotting "backends". This is a mature package with a large number of features (including 3D plots). The downside is that it uses Python behind the scenes (but that’s not a severe issue here) and can cause problems with configuration.
Gadfly.jl is based largely on ggplot2 for R and renders high-quality graphics to SVG, PNG, Postscript, and PDF. The interface is simple and cooperates well with DataFrames.
There is an interesting package called StatsPlots.jl which is a replacement for Plots.jl that contains many statistical recipes for concepts and types introduced in the JuliaStats organization, including correlation plot, Andrew's plot, MDS plot, and many more.

To expose the ML model as a service, we can establish a custom model server. To do so, we can use Genie.jl - a full-stack MVC web framework that provides a streamlined and efficient workflow for developing modern web applications and much more. Genie manages all of the virtual environments, database connectivity, or automatic deployment into docker containers (you just run one function, and everything works). It’s pure Julia and that’s important here because this framework manages the entire project for you. And it’s really very easy to use.
Apache Spark is a distributed data and computation engine that becomes more and more popular, especially among large companies and corporations. Hosted Spark instances offered by cloud service providers make it easy to get started and to run large, on-demand clusters for dynamic workloads.
While Scala, as the primary language of Spark, is not the best choice for some numerical computing tasks, being built for numerical computing, Julia is however perfectly suited to create fast and accurate numerical applications. Spark.jl is a library for that purpose. It allows you to connect to a Spark cluster from the Julia REPL and load data and submit jobs. It uses JavaCall.jl behind the scenes. This package is still in the initial development phase. Someone said that Julia is a bridge between Python and Spark - being simple like Python but having the big-data manipulation capabilities of Spark.
In Julia, we can do distributed computing effortlessly. We can do it with a useful JuliaDB.jl package, but straight Julia with distributed processes work well. We use it in production, distributed across multiple servers at scale. Implementation of distributed parallel computing is provided by module Distributed as part of the standard library shipped with Julia.
Machine Learning in Julia - conclusions
We covered a lot of topics, but in fact, we only scratched the surface. Presented examples show that, under certain conditions, Julia can be considered as a serious option for your next machine learning project in an enterprise environment or scientific work. Some Rustaceans (Rust language users call themselves that) ask themselves in terms of machine learning capabilities in their loved language: Are we learning yet? Julia's users can certainly answer yes! Are we production ready? Yes, but it doesn't mean Julia is the best option for your machine learning projects. More often, the mature Python ecosystem will be the better choice. Is Julia the future of machine learning? We believe so, and we’re looking forward to see some interesting apps written with Julia.