Kafka Transactions – Integrating with Legacy Systems

The article covers setting up and using Kafka transactions, specifically in the context of legacy systems that run on JPA/JMS frameworks. We look at various issues that may occur from using different TransactionManagers and how to properly use these different transactions to achieve desired results. Finally, we analyze how Kafka transactions can be integrated with JTA.
Many legacy applications were built on JMS consumers with the JPA database, relying on transactions to ensure exactly-once delivery. These systems rely on the stability and surety of transactional protocols so that errors are avoided. The problem comes when we try to integrate such systems with newer systems built upon non-JMS/JPA solutions – things like Kafka, MongoDB, etc.
Some of these systems, like MongoDB, actively work to make the integration with legacy JMS/JPA easier. Others, like Kafka, introduce their own solutions to such problems. We will look more deeply into Kafka and the ways we can integrate it with our legacy system.
If you want some introduction to Kafka fundamentals, start with this article covering the basics.
Classic JMS/JPA setup
First, let us do a quick review of the most common setups for legacy systems. They often use JMS to exchange messages between different applications, be it IBM MQ, RabbitMQ, ActiveMQ, Artemis, or other JMS providers – these are used with transactions to ensure exactly-once delivery. Messages are then processed in the application, oftentimes saving states in a database via JPA API using Hibernate/Spring Data to do so. Sometimes additional frameworks are used to make the processing easier to write and manage, but in general, the processing may look similar to this example:
@JmsListener(destination = "message.queue")
@Transactional(propagation = Propagation.REQUIRED)
public void processMessage(String message) {
exampleService.processMessage(message);
MessageEntity entity = MessageEntity.builder().content(message).build();
messageDao.save(entity);
exampleService.postProcessMessage(entity);
messageDao.save(entity);
jmsProducer.sendMessage(exampleService.createResponse(entity));
}
Messages are read, processed, saved to the database, processed further, updated in the database, and the response is sent to a further JMS queue. It is all done in a transactional context in one of two possible ways:
1) Using a separate JMS and JPA transaction during processing, committing a JPA transaction right before committing JMS.
2) Using JTA to merge JMS and JPA transactions so that both are committed or aborted at the same time.
Both solutions have their upsides and pitfalls; neither of them fully guarantees a lack of duplicates, though JTA definitely gives better guarantees than separate transactions. JTA also does not run into the problem of idempotent consumers, it does, however, come with an overhead. In either case, we may run into problems if we try to integrate this with Kafka.
What are Kafka transactions?
Kafka broker is fast and scalable, but the default mode in which it runs does not hold to exactly-once message delivery guarantee. We may see duplicates, or we may see some messages lost depending on circumstances, something that old legacy systems based on transactions cannot accept. As such, we need to switch Kafka to transactional mode, enabling exactly-once guarantee.
Transactions in Kafka are designed so that they are mainly handled on the producer/message broker side, rather than the consumer side. The consumer is effectively an idempotent reader, while the producer/coordinator handle the transaction.
This reduces performance overload on the consumer side, though at the cost of the broker side. The flow looks roughly like this:
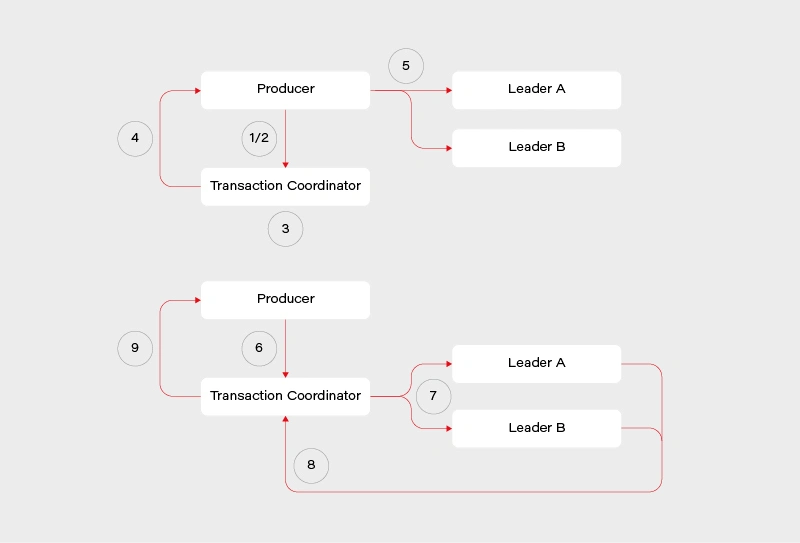
1) Determine which broker is the coordinator in the group
2) Producer sends beginTransaction() request to the coordinator
3) The coordinator generates transaction-id
4) Producer receives a response from the coordinator with transaction-id
5) Producer sends its messages to the leading brokers of data partitions together with transaction-id
6) Producer sends commitTransaction() request to the coordinator and awaits the response
7) Coordinator sends commitTransaction() request to every leader broker and awaits their responses
8) Leader brokers set the transaction status to committed for the written records and send the response to the coordinator
9) Coordinator sends transaction result to the producer
This does not contain all the details, explaining everything is beyond the scope of this article and many sources can be found on this. It does however give us a clear view on the transaction process – the main player responsible is the transaction coordinator. It notifies leaders about the state of the transaction and is responsible for propagating the commit. There is some locking involved in the producer/coordinator side that may affect performance negatively depending on the length of our transactions.
Readers, meanwhile, simply operate in read-committed mode, so they will be unable to read messages from transactions that have not been committed.
Kafka transactions – setup and pitfalls
We will look at a practical example of setting up and using Kafka transactions, together with potential pitfalls on the consumer and producer side, also looking at specific ways Kafka transactions work as we go through examples. We will use Spring to set up our Kafka consumer/producer. To do this, we first have to import Kafka into our pom.xml:
<!-- Kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
To enable transactional processing for the producer, we need to tell Kafka to explicitly enable idempotence, as well as give it transaction-id:
producer:
bootstrap-servers: localhost:9092
transaction-id-prefix: tx-
properties:
enable.idempotence: true
transactional.id: tran-id-1
Each producer needs its own, unique transaction-id, otherwise, we will encounter errors if more than one producer attempts to perform a transaction at the same time. It is crucial to make sure that each instance of an application in a cloud environment has its own unique prefix/transaction-id. Additional setup must also be done for the consumer:
consumer:
bootstrap-servers: localhost:9092
group-id: group_id
auto-offset-reset: earliest
enable-auto-commit: false
isolation-level: read_committed
The properties that interest us set enable-auto-commit to false so that Kafka does not periodically commit transactions on its own. Additionally, we set isolation-level to read committed, so that we will only consume messages when the producer fully commits them. Now both the consumer and the producer are set to exactly-once delivery with transactions.
We can run our consumer and see what happens if an exception is thrown after writing to the queue but before the transaction is fully committed. For this purpose, we will create a very simple REST mapping so that we write several messages to the Kafka topic before throwing an exception:
@PostMapping(value = "/required")
@Transactional(propagation = Propagation.REQUIRED)
public void sendMessageRequired() {
producer.sendMessageRequired("Test 1");
producer.sendMessageRequired("Test 2");
throw new RuntimeException("This is a test exception");
}
The result is exactly as expected – the messages are written to the queue but not committed when an exception is thrown. As such the entire transaction is aborted and each batch is aborted as well. This can be seen in the logs:
2021-01-20 19:44:29.776 INFO 11032 --- [io-9001-exec-10] c.g.k.kafka.KafkaProducer : Producing message "Test 1"
2021-01-20 19:44:29.793 INFO 11032 --- [io-9001-exec-10] c.g.k.kafka.KafkaProducer : Producing message "Test 2"
2021-01-20 19:44:29.808 ERROR 11032 --- [producer-tx-1-0] o.s.k.support.LoggingProducerListener : Exception thrown when sending a message with key='key-1-Test 1' and payload='1) Test 1' to topic messages_2:
org.apache.kafka.common.KafkaException: Failing batch since transaction was aborted
at org.apache.kafka.clients.producer.internals.Sender.maybeSendAndPollTransactionalRequest(Sender.java:422) ~[kafka-clients-2.5.1.jar:na]
at org.apache.kafka.clients.producer.internals.Sender.runOnce(Sender.java:312) ~[kafka-clients-2.5.1.jar:na]
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:239) ~[kafka-clients-2.5.1.jar:na]
at java.base/java.lang.Thread.run(Thread.java:834) ~[na:na]
2021-01-20 19:44:29.808 ERROR 11032 --- [producer-tx-1-0] o.s.k.support.LoggingProducerListener : Exception thrown when sending a message with key='key-1-Test 2' and payload='1) Test 2' to topic messages_2:
org.apache.kafka.common.KafkaException: Failing batch since transaction was aborted
at org.apache.kafka.clients.producer.internals.Sender.maybeSendAndPollTransactionalRequest(Sender.java:422) ~[kafka-clients-2.5.1.jar:na]
at org.apache.kafka.clients.producer.internals.Sender.runOnce(Sender.java:312) ~[kafka-clients-2.5.1.jar:na]
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:239) ~[kafka-clients-2.5.1.jar:na]
at java.base/java.lang.Thread.run(Thread.java:834) ~[na:na]
The LoggingProducerListener exception contains the key and contents of the message that failed to be sent. The exception tells us that the batch has been failed because the transaction was aborted. Exactly as expected, the entire transaction is atomic so failing it at the end will cause messages successfully written beforehand to not be processed.
We can do the same test for the consumer, the expectation is that the transaction will be rolled back if a message processing error occurs. For that, we will create a simple consumer that will log something and then throw it.
@KafkaListener(topics = "messages_2", groupId = "group_id")
public void consumePartitioned(String message) {
log.info(String.format("Consumed partitioned message \"%s\"", message));
throw new RuntimeException("This is a test exception");
}
We can now use our REST endpoints to send some messages to the consumer. Sure enough, we see the exact behavior we expect – the message is read, the log happens, and then rollback occurs.
2021-01-20 19:48:33.420 INFO 14840 --- [ntainer#0-0-C-1] c.g.k.kafka.KafkaConsumer : Consumed partitioned message "1) Test 1"
2021-01-20 19:48:33.425 ERROR 14840 --- [ntainer#0-0-C-1] essageListenerContainer$ListenerConsumer : Transaction rolled back
org.springframework.kafka.listener.ListenerExecutionFailedException: Listener method 'public void com.grapeup.kafkatransactions.kafka.KafkaConsumer.consumePartitioned(java.lang.String)' threw exception; nested exception is java.lang.RuntimeException: This is a test exception
at org.springframework.kafka.listener.adapter.MessagingMessageListenerAdapter.invokeHandler(MessagingMessageListenerAdapter.java:350) ~[spring-kafka-2.5.7.RELEASE.jar:2.5.7.RELEASE]
Of course, because of the rollback, the message goes back on the topic. This results in the consumer reading it again, throwing and rolling back, creating an infinite loop that will lock other messages out for this partition. This is a potential issue that we must keep in mind when using Kafka transactions messaging, the same way as we would with JMS. The message will persist if we restart the application or the broker so mindful handling of the exception is required – we need to identify exceptions that require a rollback and those that do not. This is a very-application-specific problem so there is no way to give a clear-cut solution in this article simply because such a solution does not exist.
Last but not least, it is worth noting that propagation works as expected with Spring and Kafka transactions. If we start a new transaction via @Transactional annotation with REQUIRES_NEW propagation, then Kafka will start a new transaction that commits separately from the original one and whose commit/abort result has no effect on the parent one.
There are a few more things we have to keep in mind when working with Kafka transactions, some of them to be expected, others not as much. The first thing is the fact that producer transactions lock down the topic partition that it writes. This can be seen if we run 2 servers and make one transaction delayed. In our case, we started a transaction on server 1 that wrote messages to a topic and then waited 10 seconds to commit the transaction. Server 2 in the meantime wrote its own messages and committed immediately while Server 1 was waiting. The result can be seen in the logs:
Server 1:
2021-01-20 21:38:27.560 INFO 15812 --- [nio-9001-exec-1] c.g.k.kafka.KafkaProducer : Producing message "Test 1"
2021-01-20 21:38:27.578 INFO 15812 --- [nio-9001-exec-1] c.g.k.kafka.KafkaProducer : Producing message "Test 2"
Server 2:
2021-01-20 21:38:35.296 INFO 14864 --- [ntainer#0-0-C-1] c.g.k.kafka.KafkaConsumer : Consumed message "1) Test 1 Sleep"
2021-01-20 21:38:35.308 INFO 14864 --- [p_id.messages.0] o.a.k.c.p.internals.TransactionManager : [Producer clientId=producer-tx-2-group_id.messages.0, transactionalId=tx-2-group_id.messages.0] Discovered group coordinator gu17.ad.grapeup.com:9092 (id: 0 rack: null)
2021-01-20 21:38:35.428 INFO 14864 --- [ntainer#0-0-C-1] c.g.k.kafka.KafkaConsumer : Consumed message "1) Test 2 Sleep"
2021-01-20 21:38:35.549 INFO 14864 --- [ntainer#0-0-C-1] c.g.k.kafka.KafkaConsumer : Consumed message "1) Test 1"
2021-01-20 21:38:35.676 INFO 14864 --- [ntainer#0-0-C-1] c.g.k.kafka.KafkaConsumer : Consumed message "1) Test 2"
Messages were consumed by Server 2 after Server 1 has committed its long-running transaction. Only a partition is locked, not the entire topic – as such, depending on the partitions that producers send messages to, we may encounter full, partial, or no locking at all. The lock is held until the end of the transaction, be it via commit or abort.
Another interesting thing is the order of messages – messages from Server 1 appear before messages from Server 2, even though Server 2 committed its transaction first. This is in contrast to what we would expect from JMS – the messages committed to JMS first would appear first, unlike our example. It should not be a major problem but it is something we must, once again, keep in mind while designing our applications.
Putting it all together
Now that we have Kafka transactions running, we can try and add JMS/JPA configuration to it. We can once again utilize the Spring setup to quickly integrate these. For the sake of the demo, we use an in-memory H2 database and ActiveMQ:
<!-- JPA setup -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Active MQ -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-activemq</artifactId>
</dependency>
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-broker</artifactId>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
</dependency>
We can set up a simple JMS listener, which reads a message in a transaction, saves something to the database via JPA, and then publishes a further Kafka message. This reflects a common way to try and integrate JMS/JPA with Kafka:
@JmsListener(destination = "message.queue")
@Transactional(propagation = Propagation.REQUIRED)
public void processMessage(String message) {
log.info("Received JMS message: {}", message);
messageDao.save(MessageEntity.builder().content(message).build());
kafkaProducer.sendMessageRequired(message);
}
Now if we try running this code, we will run into issues – Spring will protest that it got 2 beans of TransacionManager class. This is because JPA/JMS uses the base TransactionManager and Kafka uses its own KafkaTransactionManager. To properly run this code we have to specify which transaction manager is to be used in which @Transactional annotation. These transaction managers are completely separate and the transactions they start or commit do not affect each other. As such, one can be committed and one aborted if we throw an exception at a correct time. Let’s amend our listener for further analysis:
@JmsListener(destination = "message.queue")
@Transactional(transactionManager = "transactionManager", propagation = Propagation.REQUIRED)
public void processMessage(String message) {
log.info("Received JMS message: {}", message);
messageDao.save(MessageEntity.builder().content(message).build());
kafkaProducer.sendMessageRequired(message);
exampleService.processMessage(message);
}
In this example, we correctly mark @Transactional annotation to use a bean named transactionManager, which is the JMS/JPA bean. In a similar way, @Transactional annotation in KafkaProducer is marked to use kafkaTransactionManager, so that Kafka transaction is started and committed within that function. The issue with this code example is the situation, in which ExampleService throws in its processMessage function at line 10.
If such a thing occurs, then the JMS transaction is committed and the message is permanently removed from the queue. The JPA transaction is rolled back, and nothing is actually written to the database despite line 6. The Kafka transaction is committed because no exception was thrown in its scope. We are left with a very peculiar state that would probably need manual fixing.
To minimize such situations we should be very careful about when to start which transaction. Optimally, we would start Kafka transactions right after starting JMS and JPA transactions and commit it right before we commit JPA and JMS. This way we minimize the chance of such a situation occurring (though still cannot fully get rid of it) – the only thing that could cause one transaction to break and not the other is connection failure between commits.
Similar care should be done on the consumer side. If we start a Kafka transaction, do some processing, save to database, send a JMS message, and send a Kafka response in a naive way:
@KafkaListener(topics = "messages_2", groupId = "group_id")
@Transactional(transactionManager = "kafkaTransactionManager", propagation = Propagation.REQUIRED)
public void processMessage(String message) {
exampleService.processMessage(message);
MessageEntity entity = MessageEntity.builder().content(message).build();
messageDao.save(entity);
exampleService.postProcessMessage(entity);
messageDao.save(entity);
jmsProducer.sendMessage(message);
kafkaProducer.sendMessageRequired(exampleService.createResponse(entity));
}
Assuming MessageDAO/JmsProducer start their own transaction in their function, what we will end up with if line 12 throws is a duplicate entry in the database and a duplicate JMS message. The Kafka transaction will be properly rolled back, but the JMS and JPA transactions were already committed, and we will now have to handle the duplicate. What we should do in our case, is to start all transactions immediately and do all of our logic within their scope. One of the solutions to do so, is to create a helper bean that accepts a function to perform within a @Transactional call:
@Service
public class TransactionalHelper {
@Transactional(transactionManager = "transactionManager",
propagation = Propagation.REQUIRED)
public void executeInTransaction(Function f) {
f.perform();
}
@Transactional(transactionManager = "kafkaTransactionManager",
propagation = Propagation.REQUIRED)
public void executeInKafkaTransaction(Function f) {
f.perform();
}
public interface Function {
void perform();
}
}
This way, our call looks like this:
@KafkaListener(topics = "messages_2", groupId = "group_id")
@Transactional(transactionManager = "kafkaTransactionManager", propagation = Propagation.REQUIRED)
public void processMessage(String message) {
transactionalHelper.executeInTransaction(() -> {
exampleService.processMessage(message);
MessageEntity entity = MessageEntity.builder().content(message).build();
messageDao.save(entity);
exampleService.postProcessMessage(entity);
messageDao.save(entity);
jmsProducer.sendMessage(message);
kafkaProducer.sendMessageRequired(exampleService.createResponse(entity));
});
}
Now we start the processing within the Kafka transaction and end it right before the Kafka transaction is committed. This is of course assuming no REQUIRES_NEW propagation is used throughout the inner functions. Once again, in an actual application, we would need to carefully consider transactions in each subsequent function call to make sure that no separate transactions are running without our explicit knowledge and consent.
We will run into a problem, however – the way Spring works, JPA transactions will behave exactly as expected. JMS transaction will be started in JmsProducer anyway and committed on its own. The impact of this could be minimized by moving ExampleService call from line 13 to before line 12, but it’s still an issue we need to keep an eye on. It becomes especially important if we have to write to several different JMS queues as we process our message.
There is no easy way to force Spring to merge JPA/JMS transactions, we would need to use JTA for that.
What can and cannot be done with JTA
JTA has been designed to merge several different transactions, effectively treating them as one. When the JTA transaction ends, each participant votes whether to commit or abort it, with the result of the voting being broadcasted so that participants commit/abort at once. It is not 100% foolproof, we may encounter a connection death during the voting process, which may cause one or more of the participants to perform a different action. The risk, however, is minimal due to the way transactions are handled.
The main benefit of JTA is that we can effectively treat several different transactions as one – this is most often used with JMS and JPA transactions. So the question arises, can we merge Kafka transactions into JTA and treat them all as one? Well, the answer to that is sadly no – the Kafka transactions do not follow JTA API and do not define XA connection factories. We can, however, use JTA to fix the issue we encountered previously between JMS and JPA transactions.
To set up JTA in our application, we do need a provider; however, base Java does not provide an implementation of JTA, only the API itself. There are various providers for this, sometimes coming with the server, Websphere, and its UOP Transaction Manager being a good example. Other times, like with Tomcat, nothing is provided out of the box and we have to use our own. An example of a library that does this is Atomikos – it does have a paid version but for the use of simple JTA, we are good enough with the free one.
Spring made importing Atomikos easy with a starter dependency:
<!-- JTA setup -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
Spring configures our JPA connection to use JTA on its own; to add JMS to it, however, we have to do some configuration. In one of our @Configuration classes, we should add the following beans:
@Configuration
public class JmsConfig {
@Bean
public ActiveMQXAConnectionFactory connectionFactory() {
ActiveMQXAConnectionFactory connectionFactory = new ActiveMQXAConnectionFactory();
connectionFactory.setBrokerURL("tcp://localhost:61616");
connectionFactory.setPassword("admin");
connectionFactory.setUserName("admin");
connectionFactory.setMaxThreadPoolSize(10);
return connectionFactory;
}
@Bean(initMethod = "init", destroyMethod = "close")
public AtomikosConnectionFactoryBean atomikosConnectionFactory() {
AtomikosConnectionFactoryBean atomikosConnectionFactory = new AtomikosConnectionFactoryBean();
atomikosConnectionFactory.setUniqueResourceName("XA_JMS_ConnectionFactory");
atomikosConnectionFactory.setXaConnectionFactory(connectionFactory());
atomikosConnectionFactory.setMaxPoolSize(10);
return atomikosConnectionFactory;
}
@Bean
public JmsTemplate jmsTemplate() {
JmsTemplate template = new JmsTemplate();
template.setConnectionFactory(atomikosConnectionFactory());
return template;
}
@Bean
public DefaultJmsListenerContainerFactory jmsListenerContainerFactory(PlatformTransactionManager transactionManager) {
DefaultJmsListenerContainerFactory factory = new DefaultJmsListenerContainerFactory();
factory.setConnectionFactory(atomikosConnectionFactory());
factory.setConcurrency("1-1");
factory.setTransactionManager(transactionManager);
return factory;
}
}
We define an ActiveMQXAConnectionFactory, which implements XAConnectionFactory from JTA API. We then define a separate AtomikosConnectionFactory, which uses ActiveMQ one. For all intents and purposes, everything else uses Atomikos connection factory – we set it for JmsTemplate and DefaultJmsListenerContainerFactory. We also set the transaction manager, which will now become the JTA transaction manager.
Having all of that set, we can run our application again and see if we still encounter issues with transactions not behaving as we want them to. Let’s set up a JMS listener with additional logs for clarity:
@JmsListener(destination = "message.queue")
@Transactional(transactionManager = "transactionManager", propagation = Propagation.REQUIRED)
public void processMessage(final String message) {
transactionalHelper.executeInKafkaTransaction(() -> {
MessageEntity entity = MessageEntity.builder().content(message).build();
messageDao.save(entity);
log.info("Saved database entity");
kafkaProducer.sendMessageRequired(message);
log.info("Sent kafka message");
jmsProducer.sendMessage("response.queue", "Response: " + message);
log.info("Sent JMS response");
throw new RuntimeException("This is a test exception");
});
}
We expect that JTA and Kafka transactions will both roll back, nothing will be written to the database, nothing will be written to response.queue, nothing will be written to Kafka topic, and that the message will not be consumed. When we run this, we get the following logs:
2021-01-20 21:56:00.904 INFO 9780 --- [enerContainer-1] c.g.kafkatransactions.jms.JmsConsumer : Saved database entity
2021-01-20 21:56:00.906 INFO 9780 --- [enerContainer-1] c.g.k.kafka.KafkaProducer : Producing message "This is a test message"
2021-01-20 21:56:00.917 INFO 9780 --- [enerContainer-1] c.g.kafkatransactions.jms.JmsConsumer : Sent kafka message
2021-01-20 21:56:00.918 INFO 9780 --- [enerContainer-1] c.g.kafkatransactions.jms.JmsProducer : Sending JMS message: Response: This is a test message
2021-01-20 21:56:00.922 INFO 9780 --- [enerContainer-1] c.g.kafkatransactions.jms.JmsConsumer : Sent JMS response
2021-01-20 21:56:00.935 WARN 9780 --- [enerContainer-1] o.s.j.l.DefaultMessageListenerContainer : Execution of JMS message listener failed, and no ErrorHandler has been set.
org.springframework.jms.listener.adapter.ListenerExecutionFailedException: Listener method 'public void com.grapeup.kafkatransactions.jms.JmsConsumer.processMessage(java.lang.String)' threw exception; nested exception is java.lang.RuntimeException: This is a test exception
at org.springframework.jms.listener.adapter.MessagingMessageListenerAdapter.invokeHandler(MessagingMessageListenerAdapter.java:122) ~[spring-jms-5.2.10.RELEASE.jar:5.2.10.RELEASE]
The exception thrown is followed by several errors about rolled back transactions. After checking our H2 database and looking at Kafka/JMS queues, we can indeed see that everything we expected has been fulfilled. The original JMS message was not consumed either, starting an endless loop which, once again, we would have to take care of in a running application. The key part though is that transactions behaved exactly as we intended them to.
Is JTA worth it for that little bit of surety? Depends on the requirements – do we have to write to several JMS queues simultaneously while writing to the database and Kafka? We will have to use JTA. Can we get away with a single write at the end of the transaction? We might not need to. There is sadly no clear-cut answer, we must use the right tools for the right job.
Summary
We managed to successfully launch Kafka in transactional mode, enabling exactly-once delivery mechanics. This can be integrated with JMS/JPA transactions, although we may encounter problems in our listeners/consumers depending on circumstances. If needed, we may introduce JTA to allow us an easier control of different transactions and whether they are committed or aborted. We used ActiveMQ/H2/Atomikos for this purpose, but this works with any JMS/JPA/JTA providers.
If you’re looking for help in mastering cloud technologies, learn how our team works with innovative companies.
Is it insightful?
Share the article!
Check related articles
Read our blog and stay informed about the industry's latest trends and solutions.
see all articles

